







 本文介绍了强化学习中的几个关键算法,包括多臂老虎机问题中的贪婪算法、UCB算法和汤普森采样,以及动态规划中的策略迭代和价值迭代。此外,还讨论了时序差分学习,如Sarsa和Q-learning,以及DynaQ的离线学习思想,强调了探索与利用之间的平衡以及不同算法的特点。
本文介绍了强化学习中的几个关键算法,包括多臂老虎机问题中的贪婪算法、UCB算法和汤普森采样,以及动态规划中的策略迭代和价值迭代。此外,还讨论了时序差分学习,如Sarsa和Q-learning,以及DynaQ的离线学习思想,强调了探索与利用之间的平衡以及不同算法的特点。
代码地址: 强化学习 简明教程 代码实战
下午无事,找个强化学习的教程回顾。这里是简要的一些笔记。
一、无状态问题
假设你进入一个赌场,面对一排老虎机(所以有多个臂),每个老虎机都有一定的概率获取奖励,你试验的总次数是一定的,这就是从经典的多臂老虎机问题。这里就有在线学习及更宽泛的强化学习中一个核心的权衡问题:Conlict between exploitation and exploring。即我们是应该探索(exploration)去尝试新的可能性,还是应该守成(exploitation)。
- 贪婪算法
比较保守,记录当前每个已玩老虎机的收益,选择收益期望最大的。但是需要给出一定的探索概率,即随机选择没玩过的老虎机。 - 递减的贪婪算法
对上面固定的探索概率挂钩,如玩的次数越少,则随机探索的概率越大,探索次数越多,即有很多的已知信息了,则减少随机选择的概率,转向选择已知期望收益最大的老虎机。 - UCB 上置信界算法
根据每个动作的期望奖励和不确定性来计算一个上界,然后选择上界最大的动作,这里有很多证明。通俗地理解的话,多探索玩的少的机器,少探索玩的多的机器,对每个机器的玩的次数都做一个记录。 如下:分子是总共玩了多少次,取根号后让他的增长速度变慢,分母是每台老虎机玩的次数,乘以2让他的增长速度变快,随着玩的次数增加,分母会很快超过分子的增长速度,导致分数越来越小,具体到每一台老虎机,则是玩的次数越多,分数就越小,也就是ucb的加权越小,所以ucb衡量了每一台老虎机的不确定性,不确定性越大,探索的价值越大。 最后两者相加,即综合考虑了探索和exploitation
核心代码:
def choose_one():
#求出每个老虎机各玩了多少次
played_count = [len(i) for i in rewards]
played_count = np.array(played_count)
#求出上置信界
fenzi = played_count.sum()**0.5
fenmu = played_count * 2
ucb = fenzi / fenmu
#ucb本身取根号
#大于1的数会被缩小,小于1的数会被放大,这样保持ucb恒定在一定的数值范围内
ucb = ucb**0.5
#计算每个老虎机的奖励平均
rewards_mean = [np.mean(i) for i in rewards]
rewards_mean = np.array(rewards_mean)
#ucb和期望求和
ucb += rewards_mean
return ucb.argmax()
- 汤普森采样算法
采用了beta 分布。Beta 分布是一种定义在 (0,1) 区间的连续概率分布,有两个形状参数 α 和 β,可以用来描述伯努利试验的成功概率的不确定性。可以参考,beta分布的理解 进行理解。
个人理解为,伯努利试验中,试验次数为n, 成功次数为X, X服从二项分布X~B(n,p) 。但是如果我们不知道概率p,那么,在多次重复进行n次伯努利试验,我们想要知道p的所有可能取值的概率,随机变量p就服从Beta分布。用一句话来说,Beta分布可以看作一个概率的概率分布,当你不知道一个东西的具体概率是多少时,它可以给出了所有概率出现的可能性大小。其中Beta分布的两个参数,可以看做先验信息中成功的次数&失败的次数。

在本问题中,这个概率,就是我们估计的每个老虎机的收益的期望。
设每个老虎机收益服从beta分布,那么我们记录每个老虎机出1的次数+1, 出0的次数+1。这样就有了这个收益的分布,那么我们就对每个老虎机采样得到一个它的概率,找出最大的值对应的老虎机即可。(想想这里一般的做法是用出1次数/总次数认为是老虎机的期望,但这个是不准确的,因为次数少的时候,随机性很强。)
三、动态规划法
动态规划算法是对环境完全已知的,有模型的算法。
下图游戏,机器人会在左侧第0列随机一个格子出现。灰色格子是陷阱,绿色格子是终点。机器人的动作空间是上下左右。
所谓对环境已知,是指能完整确定地推演,我在选择动作时候,已经知道下个状态,下下个动作空间,我能做完整推演,不用探索。
所谓有模型,是指选择一个动作后,我知道我会100%到什么状态,我的reward的值是多少也是确定已知的。
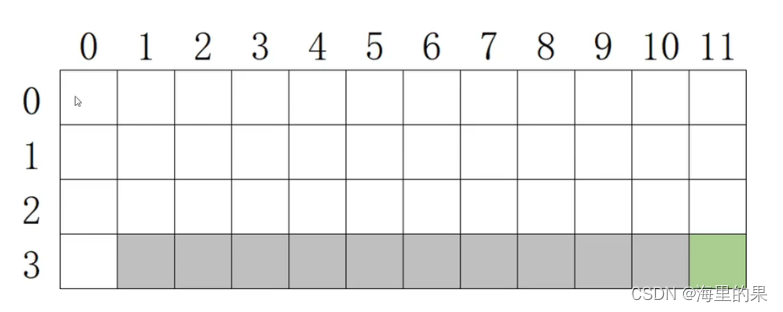
- 策略迭代算法
策略迭代算法思想就是计算每个状态的价值,它借助于动态规划基本方程,交替使用“求值计算”和“策略改进”两个步骤,求出逐次改进的、最终达到或收敛于最优策略的策略序列。(1)以某种策略 开始,计算此策略下的状态值函数(2)根据此值函数,找到最好的策略 (3)用新策略继续前行,不断迭代。
策略迭代算法需要设计 策略评估函数 和 策略提升函数。 策略评估函数,评估每个格子的价值,格子的价值用它采取 action的reward 和action后到达下一个状态的价值综合加权评价。走一步,就用这个函数刷新一遍整个位置的values价值矩阵。
策略提升函数,根据每一个格子的价值,更新策略,简单地就是,如果对每一个格子,扫描其上下左右,如果某个分数最高,则该动作概率是100%,并列最高的平分概率。
- 价值迭代算法
这个相对于之前的策略迭代算法,其实就是策略评估里面,每个格子的价值,用当前action空间采取动作之后,能达到的最大的价值,作为当前格子的价值。前面一个是和action概率加权平均而已。
价值迭代算法不需要考虑每个动作的概率
四、 时序差分算法
是无模型,在线学习的算法,区别于前面的动态规划算法。(有模型是开天眼,无模型,在线学习,就是走一步看一步算一步)
根据时序差分算法, 当前state, action的分数 = 下一个state, action的分数*gamma + reward, 立意在于,到下一个状态时候,由于往前走了一步,对未来的估计应当更加准确。
- Sarsa算法 根据S-A-R-S-A 计算更新量。
同样针对上面的游戏,需要准备一个Q矩阵,这个矩阵为 4124 大小,412是格子,4是动作,代表每个格子采取每个动作的分数。
get_action 函数,即策略函数,由状态选择一个动作。这个动作可以是按Q最高的动作选择。
get_update函数,由当前state, action的分数, 下一个state, 某action的分数gamma + reward,计算出差值,用这个差值更新Q。 sarsa的含义就是,用当前状态,当前动作,reward, 下个状态,下个动作更新价值矩阵。
总结:Sarsa算法里,策略是根据Q价值矩阵选择行动,因此训练的目标是一个好的Q。更新方式是用时序差分的公式计算一个更新量,计算中用的变量是sarsa
训练过程:
#训练
def train():
for epoch in range(1500):
#初始化当前位置
row = random.choice(range(4))
col = 0
#初始化第一个动作
action = get_action(row, col)
reward_sum = 0
#循环直到到达终点或者掉进陷阱
while get_state(row, col) not in ['terminal', 'trap']:
#执行动作
next_row, next_col, reward = move(row, col, action)
reward_sum += reward
#求新位置的动作
next_action = get_action(next_row, next_col)
#更新分数
update = get_update(row, col, action, reward, next_row, next_col,
next_action)
Q[row, col, action] += update
#更新当前位置
row = next_row
col = next_col
action = next_action
- Q learning
Q learning 和sarsa 算法 仅仅区别在Q-target 上,算是对sarsa 算法的改进。
区别就在于在确定下一个状态的价值时候,一个是从Q矩阵直接找最大的那个,而sarsa 不一定选的是Q值最大的动作,而是按照自己的get_action函数选择。
Qlearning
#target为下一个格子的最高分数,这里的计算和下一步的动作无关
target = 0.9 * Q[next_row, next_col].max()
sarsa
#计算target
target = 0.9 * Q[next_row, next_col, next_action]
Q learning是off-policy , sarsa是on-policy的。
-
N 步 sarsa
思想,玩N步之后在考虑更新第一步的参数。先玩,探索够了,在返回去更新参数。
例如玩了5步,记录每一步的action reward state。然后以最新的这一步(第五步)的state+action 计算target5, 由 target5*gamma +reward5 反算 target4,target3… 这样得到的target无疑会更精确。再计算出每一步所在状态的value_list()Q矩阵查表即可)这样就得到一个系列的update 值,最终只更新第一步的分数。 -
DynaQ
数据反刍,温故而知新,有一定的离线学习的成分。前面的算法对数据利用率不高,数据用一次就丢了。
这个是Qlearning的优化版。
需要保存历史数据, #保存历史数据,history,键是(row,col,action),值是(next_row,next_col,reward),
核心代码如下:
def q_planning():
#Q planning循环,相当于是在反刍历史数据,随机取N个历史数据再进行离线学习
for _ in range(20):
#随机选择曾经遇到过的状态动作对
row, col, action = random.choice(list(history.keys()))
#再获取下一个状态和反馈
next_row, next_col, reward = history[(row, col, action)]
#计算分数
update = get_update(row, col, action, reward, next_row, next_col)
#更新分数
Q[row, col, action] += update
思想:记录下之前的数据,待后面Q更新差不多了,再随机选老数据update一遍,确实很像反刍

















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









