






我们将多个样本的测序数据构建成一个数据集合(List of Dataset Pairs)用于流程分析,但有可能个别样本的测序数据有问题,这时候我们如何从集合中删除该问题样本呢?
比如有这样一个数据集合:
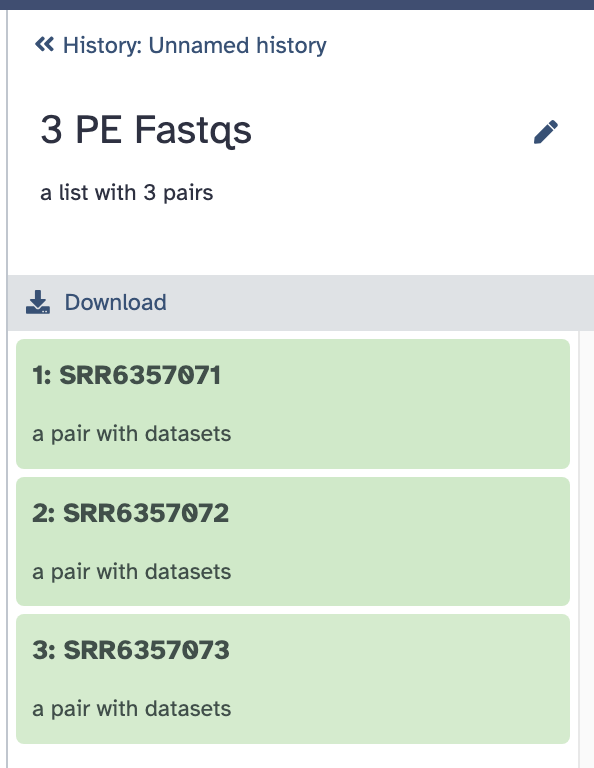
现在想过滤掉第1个样本:SRR6357071,可以这样操作:
1. 将样本信息存入一个文件
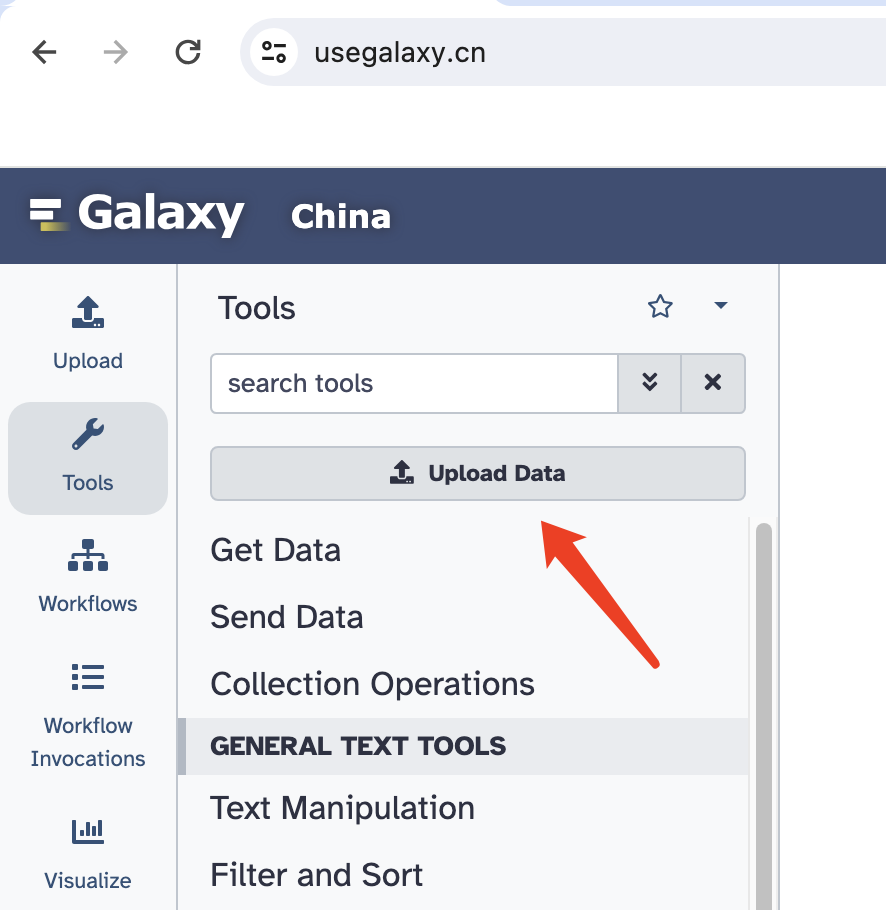
点击 Upload Data:
在弹出的界面中:
点击 粘贴数据或链接
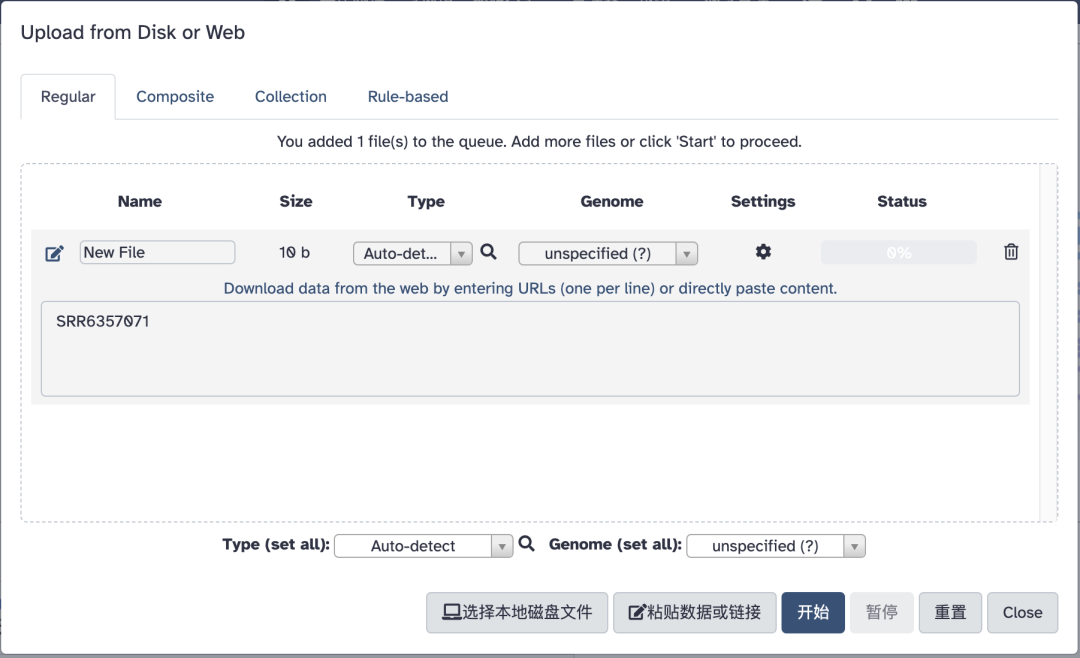
粘贴 SRR6357071
点击 开始
完成上述操作后,会在右侧历史记录 Panel 看到一个新的文件:Pasted Entry
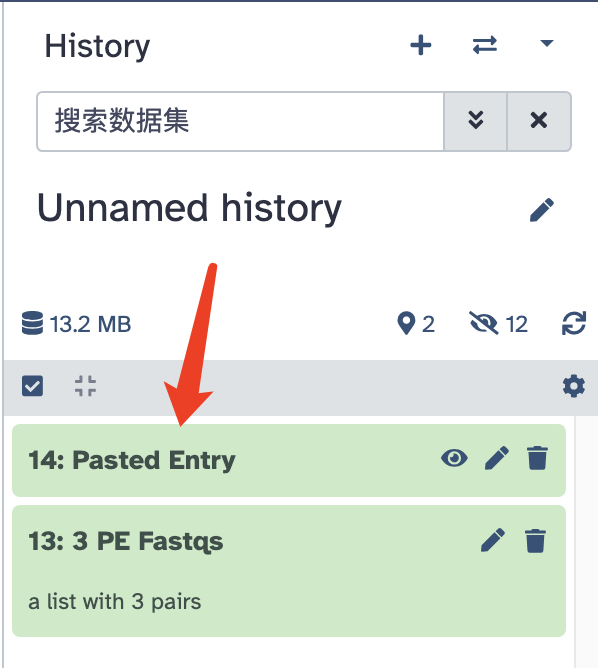
其内容为:SRR6357071
2. 过滤数据集合
左侧工具 Panel,搜索工具:Filter collection
参数设置:
Input Collection *:3 PE Fastqs
How should the elements to remove be determined?:Remove if identifiers are PRESENT in file
Filter out identifiers absent from *: Pasted Entry
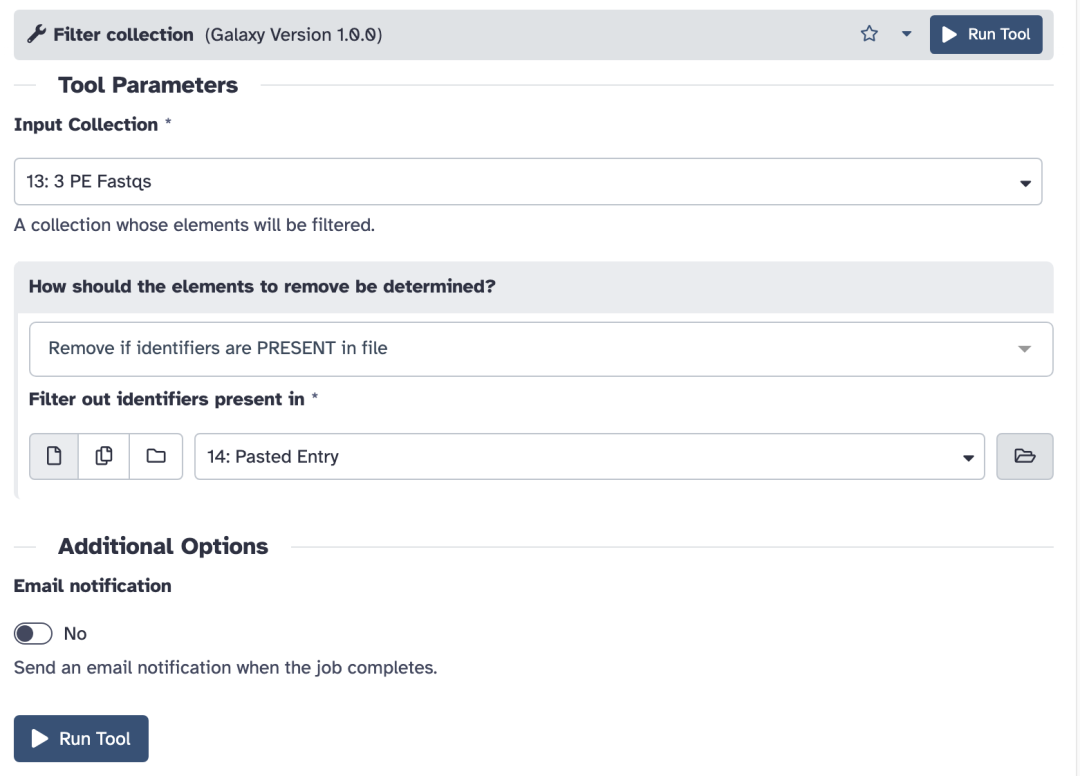
原集合将会被拆分成2个新的集合:
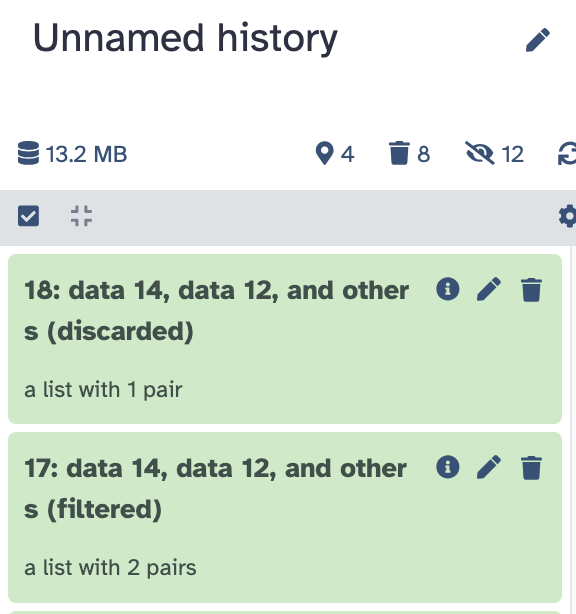
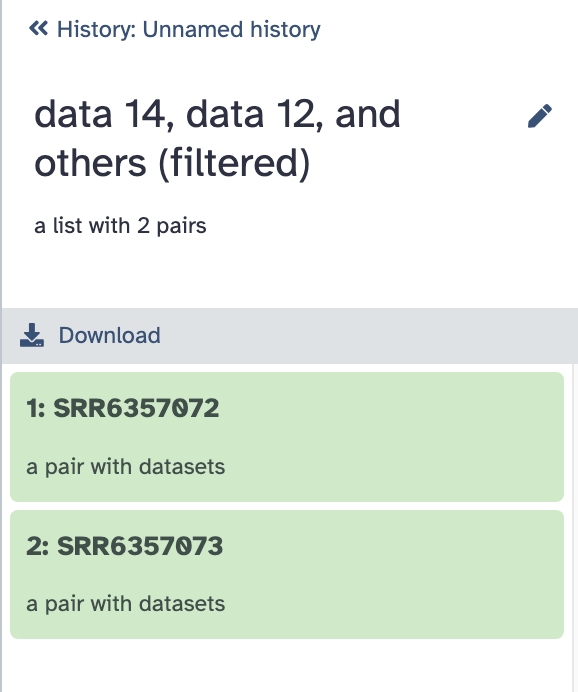
filtered:包含过滤后剩下的样本。
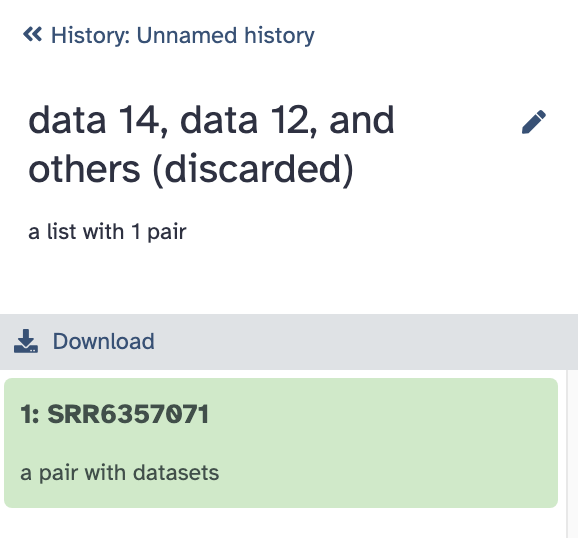
discarded:包含过滤掉的样本。
后续就可以对集合中剩下的样本进行数据分析了。
关于简说基因
生信平台
Galaxy中国(UseGalaxy.cn)致力于打造中国人的云上生物信息基础设施。大量在线工具免费使用。无需安装,用完即走。活跃的用户社区,随时交流使用心得。
生信分析
我们能够承接所有 NGS 组学数据分析业务,包括但不限于 WGS / WES / RNA-seq 等。基因组组装、注释,以及各种重测序业务都可以与简说基因合作。
生信培训
简说基因的生信培训班,荣获学员的一致好评。如果你也对生物信息学感兴趣,欢迎来跟简说基因,学真生信。
联系方式
QQ交流群(免费):925694514
微信交流群(免费):加微信好友,邀请入群
客服微信:usegalaxy














 1710
1710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









