







文章目录
一、Convolutional Social Pooling for Vehicle Trajectory Prediction
Convolutional Social Pooling for Vehicle Trajectory Prediction
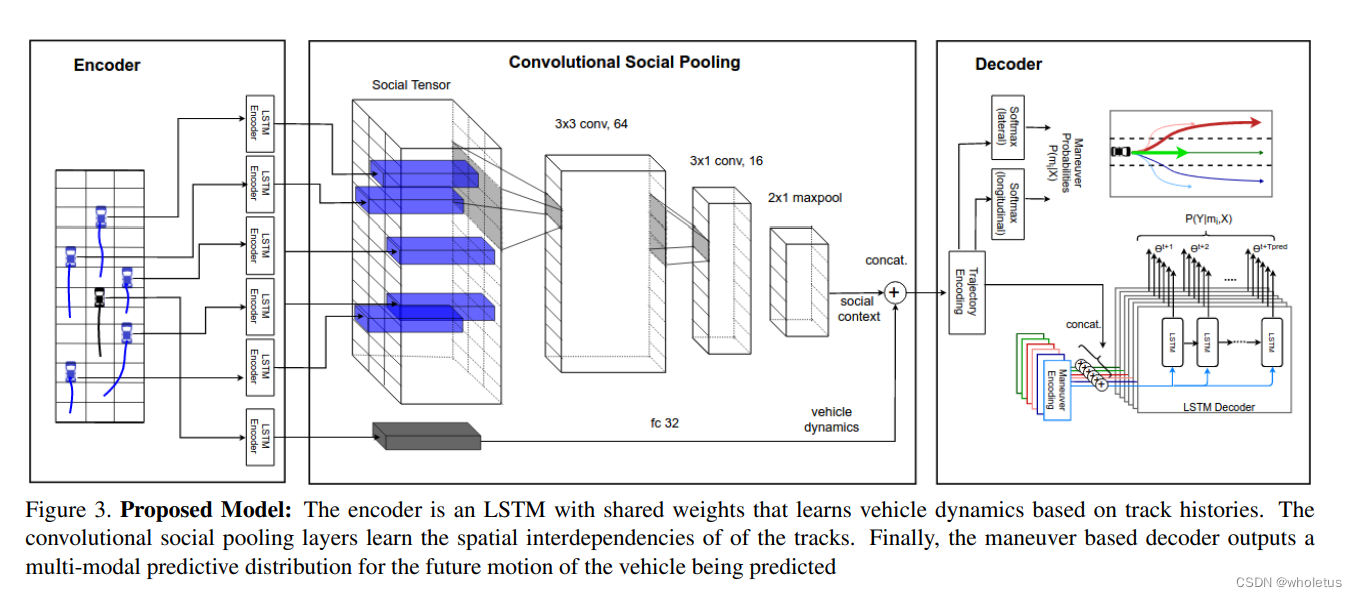
提出一个lstm的encoder和decoder,用cnn social pooling替换social pooling来更健壮的学习车辆运动过程中的相互依赖性,加cnn的好处是:cnn能感知局部车辆相对位置来弥补lstm不能感知相对位置的缺点。另外,模型基于机动类输出一个多模态的预测分布在未来轨迹上。
Convolutional social pooling:我们对于lstm隐藏状态的社会张量(social-tensor)(该状态编码相邻车辆的过去运动),应用cnn和最大池化层来代替一个全连接层
基于机动的解码器:我们的lstm解码器给生成6个机动类的概率分布在未来运动上,并且给每个类分配一个概率,这就是未来运动的多模态性质
二、QCNet:Query-Centric Trajectory Prediction
QCNet:Query-Centric Trajectory Prediction
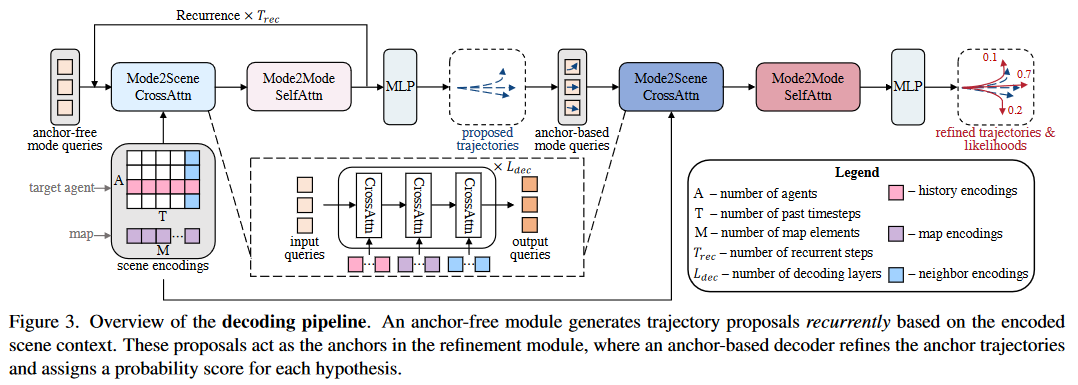
以查询为中心的场景编码范式,通过学习独立于全局时空坐标系的表示,可以重用过去的计算。在所有目标代理之间共享不变的场景特征进一步允许多代理轨迹解码的并行性。首先采用无锚查询以递归的方式生成轨迹建议,这允许模型在解码不同地平线上的路点时利用不同的场景上下文。然后,细化模块将轨迹建议作为锚点,并利用基于锚点的查询来进一步细化轨迹。通过向细化模块提供自适应和高质量的锚点,我们的基于查询的解码器可以更好地处理轨迹预测输出中的多模态。
三、VectorNet: Encoding HD Maps and Agent Dynamics from Vectorized Representation
VectorNet: Encoding HD Maps and Agent Dynamics from Vectorized Representation
我们提出直接从它们的矢量形式中学习一个动态交通参与者和结构化场景的统一的表示(如图1的右图所示)。道路特征的地理延伸可以是一个点,多边形或是曲线。例如,车道边界包含可以构成样条曲线的多个控制点;人行横道是由几个点定义的多边形;停止标识通过一个点来表示。所有的地理实体都可以被近似为多个控制点定义的折线。同时,动态交通参与者也可以通过他们的运动轨迹被近似为折线。所有的这些折线都可以表示为矢量的集合。
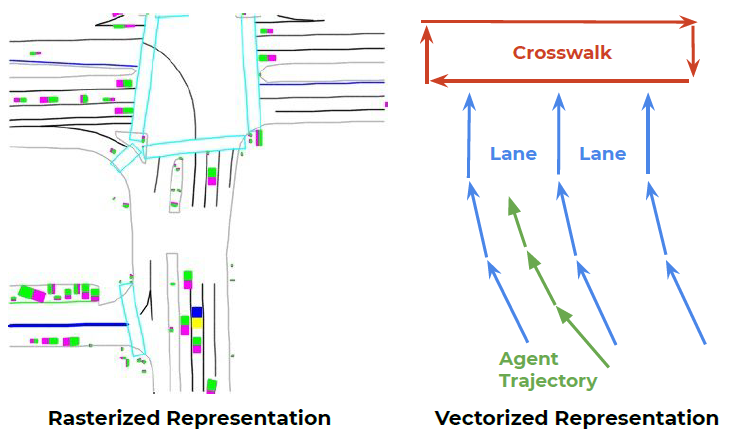 图1. 栅格化渲染方法(左)和矢量化方法(右)表示高精度地图与交通参与者运动轨迹
图1. 栅格化渲染方法(左)和矢量化方法(右)表示高精度地图与交通参与者运动轨迹
我们使用图神经网络来合并这些向量的集合。我们将每个向量视为图中的一个节点,并且定义节点的特征包含每个向量的起始位置和结束位置,以及其它属性,包括折线ID和语义标签。通过图神经网络,高精度地图的环境信息和其他交通参与者的运动轨迹被整合到目标交通参与者节点上。然后我们可以解码目标交通参与者输出的节点特征来预测它未来的运动轨迹。
特别地,为了学习图神经网络的竞争性表示,我们发现基于节点的空间和语义邻近性来约束图的连通性是很重要的。因此,我们提出了一个分层的图网络结构,首先把具有相同折线ID,并且具有相同语义标签的向量整合成折线特征,然后所有不同的折线特征互相连通交换信息。我们通过多层感知机实现局部图,通过自注意力机制[30]实现全局图。我们的方法如图2所示。
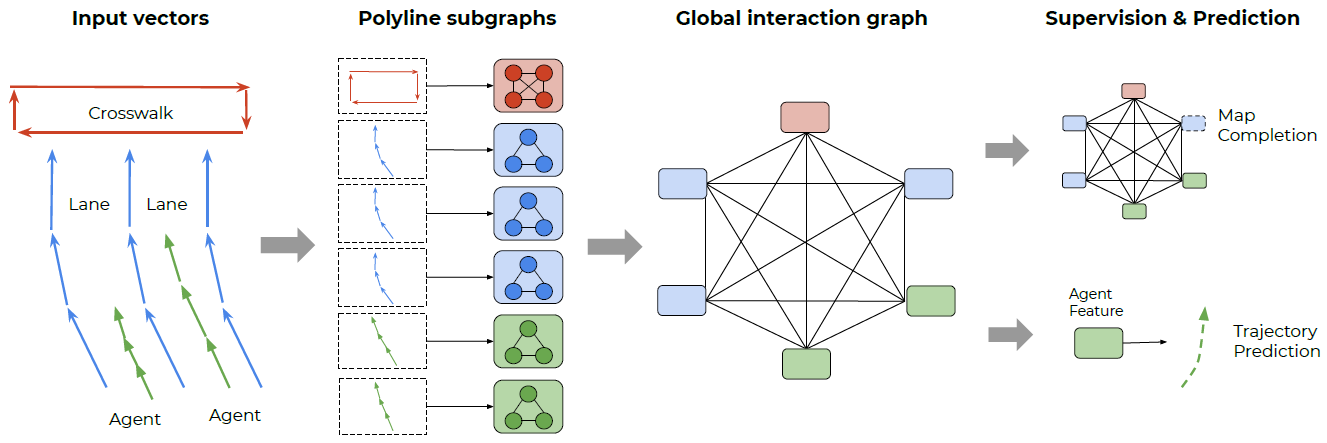
图2. 我们提出的VectorNet框架。观察到的交通参与者运动轨迹和地图特征被表示为矢量序列,然后传入局部图网络中获得折线级的特征。这些特征然后被传入一个全连接图网络中来建模高阶的交互。我们计算两类损失:从目标交通参与者对应的节点特征中预测其未来轨迹,以及预测图网络中被掩盖的节点特征。















 386
386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









