







Abstract
LaneATT 是一个anchor-based深度车道线检测模型,它类似一般的深度目标检测器,使用anchors(锚点)进行特征池化步骤。由于车道线遵循规则(交通规则)并高度相关,因此我们假设在某些情况下,全局信息对于推断其位置可能至关重要,尤其是在诸如遮挡,缺少车道标记等情况下。因此,我们提出了一种新颖的基于anchor的注意力机制,该机制聚集了全局信息。
laneatt 的前半部分(anchor-based Feature Pooling),该部分包括: anchor的角度设置,生成anchor,anchor预计算,基于anchor的回归等,具体的解释查看论文 Line-CNN:End-to-End Traffic Line Detection With Line Proposal Unit. 该论文详细介绍了基于anchor的fasterRCNN和LineCNN的区别,而在laneatt中,论文主要重点在attention Mechanism机制.
Proposed method
LaneATT 是一种基于anchor的单级模型,类似YOLOv3或SSD。下图是方法的概述,模型输入的是RGB图像,输出的是车道的边界线。LaneATT 使用Resnet提取特征,生成一幅图的特征映射。将特征图汇集起来以提取每个anchor的特征(每个anchor被投影到特征映射上,然后reshape,生成局部特征)。这些特征与一组由注意力模块产生的全局特征相结合,通过结合局部和全局特征,这在遮挡或没有可见车道标记的情况下可以更容易地使用来自其他车道的信息。 最后,将组合特征传递给全连接层,以预测最终的输出车道。

车道线和锚点的表示
沿图片纵向做等分操作,得到的等分点记作![[公式]](https://img-blog.csdnimg.cn/0a62e2bd6dc6433788408d3723a3e05c.png) ,其中
,其中![[公式]](https://img-blog.csdnimg.cn/9844e3200bdb4e0291a83b8c8f2d8140.png) 。
。
对于每条车道线,令 Y 固定,因此![[公式]](https://img-blog.csdnimg.cn/77dbeaed0b1a4cdd987557f1afaca669.png) 决定了每条车道线的差异;每个 Xi 都与对应的
决定了每条车道线的差异;每个 Xi 都与对应的![[公式]](https://img-blog.csdnimg.cn/ff1e0461b8814f2dbe93f5052683f01c.png) 形成车道线上的一个点。
形成车道线上的一个点。
由于车道线不会贯穿整张图像,令 s 和 e 分别表示 X 的开始索引和结束索引,用于表示车道线的连续有效点。
使用线而不是方框进行基于锚点的检测。这意味着锚点是一条虚线,由 原点 和 方向 表示锚点
。原点总是位于图像的左、右、下三个边界上。
Backbone
使用诸如ResNet的通用网络作为LaneATT的backbone。这一阶段的输出是一个特征映射,记作![[公式]](https://img-blog.csdnimg.cn/714846c04b514021bc154c884ea44e5c.png) ,每个锚的特征将通过池化过程提取。为降维,通道缩减,减少后续模块计算量,对 Fback 做 1X1 卷积,将输出结果记作
,每个锚的特征将通过池化过程提取。为降维,通道缩减,减少后续模块计算量,对 Fback 做 1X1 卷积,将输出结果记作![[公式]](https://img-blog.csdnimg.cn/ed1f98403d084692b861a08950c6e6e0.png) 。
。
Anchor based feature pooling
对于每个anchor,都要从 F 中提取特征,使用坐标索引要从 F 中提取的特征点。先定义这些坐标点的 y 方向坐标: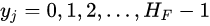 ,使用如下公式求它们对应的 x 坐标:
,使用如下公式求它们对应的 x 坐标: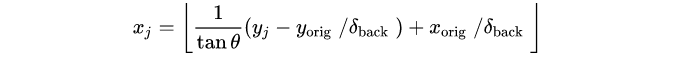

这里的池化不是使用池化操作,而是使用锚点本身实现单级检测器。并且ROI pooling也是不需要的。
Attention mechanism

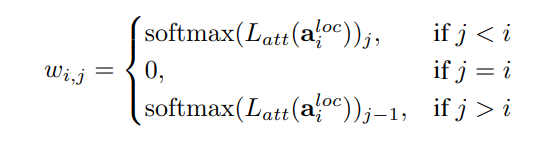
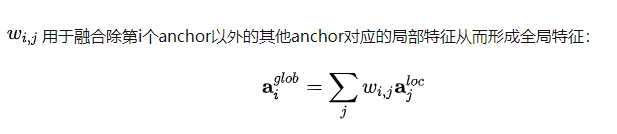

Proposal prediction

NMS

https://zhuanlan.zhihu.com/p/391366412















 2184
2184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









