







BLIP-2
原文链接:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/blip-2
概述
BLIP-2 模型由 Junnan Li、Dongxu Li、Silvio Savarese、Steven Hoi 在BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models中提出。BLIP-2 利用冻结的预训练图像编码器和大型语言模型(LLMs),通过在它们之间训练一个轻量级的 12 层 Transformer 编码器,实现了各种视觉-语言任务的最先进性能。值得注意的是,BLIP-2 在零样本 VQAv2 上比Flamingo(一个 80 亿参数模型)提高了 8.7%,并且可训练参数数量减少了 54 倍。
论文摘要如下:
由于大规模模型的端到端训练,视觉-语言预训练的成本变得越来越高。本文提出了 BLIP-2,一种通用且高效的预训练策略,从现成的冻结预训练图像编码器和冻结大型语言模型中引导视觉-语言预训练。BLIP-2 通过轻量级的 Querying Transformer 消除了模态差异,该模型经过两个阶段的预训练。第一阶段从冻结图像编码器引导视觉-语言表示学习。第二阶段从冻结语言模型引导视觉-语言生成学习。尽管可训练参数数量明显少于现有方法,但 BLIP-2 在各种视觉-语言任务上实现了最先进的性能。例如,我们的模型在零样本 VQAv2 上比 Flamingo80B 提高了 8.7%,并且可训练参数数量减少了 54 倍。我们还展示了模型的新兴能力,即零样本图像到文本生成,可以遵循自然语言指令。
 BLIP-2 架构。摘自原始论文。
BLIP-2 架构。摘自原始论文。
使用提示
-
BLIP-2 可用于在给定图像和可选文本提示的情况下进行条件文本生成。在推理时,建议使用
generate方法。 -
可以使用 Blip2Processor 来为模型准备图像,并将预测的标记 ID 解码回文本。
资源
官方 Hugging Face 和社区(由🌎表示)资源列表,帮助您开始使用 BLIP-2。
- BLIP-2 的演示笔记本用于图像字幕、视觉问答(VQA)和类似对话的会话,可在此处找到。
如果您有兴趣提交资源以包含在此处,请随时提交拉取请求,我们将进行审查!资源应该理想地展示一些新内容,而不是重复现有资源。
Blip2Config
class transformers.Blip2Config
( vision_config = None qformer_config = None text_config = None num_query_tokens = 32 **kwargs )
参数
-
vision_config(dict, 可选) — 用于初始化 Blip2VisionConfig 的配置选项字典。 -
qformer_config(dict, 可选) — 用于初始化 Blip2QFormerConfig 的配置选项字典。 -
text_config(dict, 可选) — 用于初始化任何 PretrainedConfig 的配置选项字典。 -
num_query_tokens(int, optional, defaults to 32) — 通过 Transformer 传递的查询令牌数量。 -
kwargs(optional) — 关键字参数的字典。
Blip2Config 是用于存储 Blip2ForConditionalGeneration 配置的配置类。根据指定的参数实例化一个 BLIP-2 模型,定义视觉模型、Q-Former 模型和语言模型配置。使用默认配置实例化将产生类似于 BLIP-2 Salesforce/blip2-opt-2.7b 架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import (
... Blip2VisionConfig,
... Blip2QFormerConfig,
... OPTConfig,
... Blip2Config,
... Blip2ForConditionalGeneration,
... )
>>> # Initializing a Blip2Config with Salesforce/blip2-opt-2.7b style configuration
>>> configuration = Blip2Config()
>>> # Initializing a Blip2ForConditionalGeneration (with random weights) from the Salesforce/blip2-opt-2.7b style configuration
>>> model = Blip2ForConditionalGeneration(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
>>> # We can also initialize a Blip2Config from a Blip2VisionConfig, Blip2QFormerConfig and any PretrainedConfig
>>> # Initializing BLIP-2 vision, BLIP-2 Q-Former and language model configurations
>>> vision_config = Blip2VisionConfig()
>>> qformer_config = Blip2QFormerConfig()
>>> text_config = OPTConfig()
>>> config = Blip2Config.from_text_vision_configs(vision_config, qformer_config, text_config)
from_vision_qformer_text_configs
( vision_config: Blip2VisionConfig qformer_config: Blip2QFormerConfig text_config: PretrainedConfig **kwargs ) → export const metadata = 'undefined';Blip2Config
返回
Blip2Config
配置对象的实例
从 BLIP-2 视觉模型、Q-Former 和语言模型配置中实例化一个 Blip2Config(或派生类)。
Blip2VisionConfig
class transformers.Blip2VisionConfig
( hidden_size = 1408 intermediate_size = 6144 num_hidden_layers = 39 num_attention_heads = 16 image_size = 224 patch_size = 14 hidden_act = 'gelu' layer_norm_eps = 1e-06 attention_dropout = 0.0 initializer_range = 1e-10 qkv_bias = True **kwargs )
参数
-
hidden_size(int, optional, defaults to 1408) — 编码器层和池化层的维度。 -
intermediate_size(int, optional, defaults to 6144) — Transformer 编码器中“中间”(即前馈)层的维度。 -
num_hidden_layers(int, optional, defaults to 39) — Transformer 编码器中的隐藏层数量。 -
num_attention_heads(int, optional, defaults to 16) — Transformer 编码器中每个注意力层的注意力头数量。 -
image_size(int, optional, defaults to 224) — 每个图像的大小(分辨率)。 -
patch_size(int, optional, defaults to 14) — 每个补丁的大小(分辨率)。 -
hidden_act(strorfunction, optional, defaults to"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"和"gelu_new""gelu"。layer_norm_eps (float, optional, defaults to 1e-5): 层归一化层使用的 epsilon。 -
attention_dropout(float, optional, defaults to 0.0) — 注意力概率的丢失比率。 -
initializer_range(float, optional, defaults to 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
qkv_bias(bool, optional, defaults toTrue) — 是否在自注意力层中为查询和值添加偏置。
这是用于存储 Blip2VisionModel 配置的配置类。根据指定的参数实例化一个 BLIP-2 视觉编码器,定义模型架构。实例化默认配置将产生类似于 BLIP-2 Salesforce/blip2-opt-2.7b 架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import Blip2VisionConfig, Blip2VisionModel
>>> # Initializing a Blip2VisionConfig with Salesforce/blip2-opt-2.7b style configuration
>>> configuration = Blip2VisionConfig()
>>> # Initializing a Blip2VisionModel (with random weights) from the Salesforce/blip2-opt-2.7b style configuration
>>> model = Blip2VisionModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
Blip2QFormerConfig
class transformers.Blip2QFormerConfig
( vocab_size = 30522 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.1 attention_probs_dropout_prob = 0.1 max_position_embeddings = 512 initializer_range = 0.02 layer_norm_eps = 1e-12 pad_token_id = 0 position_embedding_type = 'absolute' cross_attention_frequency = 2 encoder_hidden_size = 1408 **kwargs )
参数
-
vocab_size(int, optional, defaults to 30522) — Q-Former 模型的词汇量。定义在调用模型时传递的inputs_ids可表示的不同标记数量。 -
hidden_size(int, optional, defaults to 768) — 编码器层和池化层的维度。 -
num_hidden_layers(int, optional, defaults to 12) — Transformer 编码器中的隐藏层数。 -
num_attention_heads(int, optional, defaults to 12) — 每个注意力层中的注意力头数。 -
intermediate_size(int, optional, defaults to 3072) — Transformer 编码器中“中间”(通常称为前馈)层的维度。 -
hidden_act(strorCallable, optional, defaults to"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"silu"和"gelu_new"。 -
hidden_dropout_prob(float, optional, defaults to 0.1) — 嵌入层、编码器和池化器中所有全连接层的 dropout 概率。 -
attention_probs_dropout_prob(float, optional, defaults to 0.1) — 注意力概率的 dropout 比率。 -
max_position_embeddings(int, optional, defaults to 512) — 此模型可能使用的最大序列长度。通常设置为较大的值以防万一(例如,512、1024 或 2048)。 -
initializer_range(float, optional, defaults to 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
layer_norm_eps(float, optional, defaults to 1e-12) — 层归一化层使用的 epsilon。 -
position_embedding_type(str, optional, defaults to"absolute") — 位置嵌入的类型。选择"absolute"、"relative_key"、"relative_key_query"中的一个。对于位置嵌入,请使用"absolute"。有关"relative_key"的更多信息,请参考Self-Attention with Relative Position Representations (Shaw et al.)。有关"relative_key_query"的更多信息,请参考Improve Transformer Models with Better Relative Position Embeddings (Huang et al.) 中的 Method 4。 -
cross_attention_frequency(int, optional, defaults to 2) — 向 Transformer 层添加交叉注意力的频率。 -
encoder_hidden_size(int, optional, defaults to 1408) — 交叉注意力中隐藏状态的隐藏大小。
这是一个配置类,用于存储 Blip2QFormerModel 的配置。根据指定的参数实例化一个 BLIP-2 Querying Transformer (Q-Former) 模型,定义模型架构。使用默认值实例化配置将产生类似于 BLIP-2 Salesforce/blip2-opt-2.7b 架构的配置。配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
请注意,Blip2QFormerModel 与 BertLMHeadModel 非常相似,具有交错的交叉注意力。
示例:
>>> from transformers import Blip2QFormerConfig, Blip2QFormerModel
>>> # Initializing a BLIP-2 Salesforce/blip2-opt-2.7b style configuration
>>> configuration = Blip2QFormerConfig()
>>> # Initializing a model (with random weights) from the Salesforce/blip2-opt-2.7b style configuration
>>> model = Blip2QFormerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
Blip2Processor
class transformers.Blip2Processor
( image_processor tokenizer )
参数
-
image_processor(BlipImageProcessor)— BlipImageProcessor 的一个实例。图像处理器是必需的输入。 -
tokenizer(AutoTokenizer)— [‘PreTrainedTokenizer’]的一个实例。分词器是必需的输入。
构建一个 BLIP-2 处理器,将 BLIP 图像处理器和 OPT/T5 分词器封装到一个处理器中。
BlipProcessor 提供了 BlipImageProcessor 和 AutoTokenizer 的所有功能。有关更多信息,请参阅__call__()和 decode()的文档字符串。
batch_decode
( *args **kwargs )
此方法将其所有参数转发到 PreTrainedTokenizer 的 batch_decode()。有关更多信息,请参阅此方法的文档字符串。
解码
( *args **kwargs )
此方法将其所有参数转发到 PreTrainedTokenizer 的 decode()。有关更多信息,请参阅此方法的文档字符串。
Blip2VisionModel
class transformers.Blip2VisionModel
( config: Blip2VisionConfig )
前进
( pixel_values: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
参数
-
pixel_values(形状为(batch_size, num_channels, height, width)的torch.FloatTensor)— 像素值。像素值可以使用 Blip2Processor 获得。有关详细信息,请参阅Blip2Processor.__call__()。 -
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回 ModelOutput 而不是普通元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPooling 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPooling 或一个torch.FloatTensor元组(如果传递了return_dict=False或当config.return_dict=False时)包含根据配置(<class 'transformers.models.blip_2.configuration_blip_2.Blip2VisionConfig'>)和输入的各种元素。
-
last_hidden_state(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size))- 模型最后一层的隐藏状态序列。 -
pooler_output(torch.FloatTensor,形状为(batch_size, hidden_size))- 经过用于辅助预训练任务的层进一步处理后,序列的第一个标记(分类标记)的最后一层隐藏状态。例如,对于 BERT 系列模型,这返回经过线性层和 tanh 激活函数处理后的分类标记。线性层的权重是在预训练期间从下一个句子预测(分类)目标中训练的。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回)- 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入的输出+每一层的输出)。模型在每一层输出处的隐藏状态以及可选的初始嵌入输出。
-
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回)- 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
Blip2VisionModel 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者负责运行前处理和后处理步骤,而后者会默默地忽略它们。
Blip2QFormerModel
class transformers.Blip2QFormerModel
( config: Blip2QFormerConfig )
查询变压器(Q-Former),用于 BLIP-2。
forward
( query_embeds: FloatTensor attention_mask: Optional = None head_mask: Optional = None encoder_hidden_states: Optional = None encoder_attention_mask: Optional = None past_key_values: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None )
encoder_hidden_states(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size),可选):编码器最后一层的输出的隐藏状态序列。如果模型配置为解码器,则在交叉注意力中使用。encoder_attention_mask(torch.FloatTensor,形状为(batch_size, sequence_length),可选):避免对编码器输入的填充标记索引执行注意力的掩码。如果模型配置为解码器,则在交叉注意力中使用。选择的掩码值在[0, 1]中:
-
对于未被“掩盖”的标记为 1,
-
对于被“掩盖”的标记为 0。past_key_values(长度为
config.n_layers的tuple(tuple(torch.FloatTensor)),每个元组有 4 个张量:形状为(batch_size, num_heads, sequence_length - 1, embed_size_per_head)):包含注意力块的预计算键和值隐藏状态。可用于加速解码。如果使用past_key_values,用户可以选择仅输入最后的decoder_input_ids(那些没有将其过去的键值状态提供给此模型的)的形状为(batch_size, 1),而不是所有形状为(batch_size, sequence_length)的decoder_input_ids。use_cache(bool,可选):如果设置为True,则返回past_key_values键值状态,并可用于加速解码(参见past_key_values)。
Blip2Model
class transformers.Blip2Model
( config: Blip2Config )
参数
config(Blip2Config)— 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
用于生成文本和图像特征的 BLIP-2 模型。该模型由视觉编码器、查询变换器(Q-Former)和语言模型组成。
此模型继承自 PreTrainedModel。查看超类文档以了解库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
此模型还是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( pixel_values: FloatTensor input_ids: FloatTensor attention_mask: Optional = None decoder_input_ids: Optional = None decoder_attention_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None labels: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.blip_2.modeling_blip_2.Blip2ForConditionalGenerationModelOutput or tuple(torch.FloatTensor)
参数
-
pixel_values(形状为(batch_size, num_channels, height, width)的torch.FloatTensor)— 像素值。可以使用 Blip2Processor 获取像素值。有关详细信息,请参阅Blip2Processor.__call__()。 -
input_ids(形状为(batch_size, sequence_length)的torch.LongTensor,可选)— 语言模型词汇表中输入序列标记的索引。输入标记可以选择性地提供作为文本提示,语言模型可以继续。可以使用 Blip2Processor 获取索引。有关详细信息,请参阅
Blip2Processor.__call__()。什么是输入 ID?
-
attention_mask(形状为(batch_size, sequence_length)的torch.Tensor,可选)— 避免在填充标记索引上执行注意力的掩码。选择的掩码值在[0, 1]中:-
1 用于“未掩码”标记的标记,
-
0 用于“掩码”标记的标记。
什么是注意力掩码?
-
-
decoder_input_ids(形状为(batch_size, target_sequence_length)的torch.LongTensor,可选)— 语言模型词汇表中解码器输入序列标记的索引。仅在使用编码器-解码器语言模型(如 T5)时相关。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.
call()。什么是解码器输入 ID? -
decoder_attention_mask(形状为(batch_size, target_sequence_length)的torch.BoolTensor,可选)— 默认行为:生成一个忽略decoder_input_ids中填充标记的张量。因果掩码也将默认使用。仅在使用编码器-解码器语言模型(如 T5)时相关。
-
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回的张量下的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回的张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回 ModelOutput 而不是普通元组。
返回
transformers.models.blip_2.modeling_blip_2.Blip2ForConditionalGenerationModelOutput 或 tuple(torch.FloatTensor)
transformers.models.blip_2.modeling_blip_2.Blip2ForConditionalGenerationModelOutput 或 torch.FloatTensor 元组(如果传递了 return_dict=False 或当 config.return_dict=False 时)包含各种元素,取决于配置(<class 'transformers.models.blip_2.configuration_blip_2.Blip2VisionConfig'>)和输入。
-
loss(torch.FloatTensor,可选,在提供labels时返回,形状为(1,)的torch.FloatTensor)— 语言模型的语言建模损失。 -
logits(形状为(batch_size, sequence_length, config.vocab_size)的torch.FloatTensor)— 语言模型的语言建模头的预测分数。 -
vision_outputs(BaseModelOutputWithPooling)— 视觉编码器的输出。 -
qformer_outputs(BaseModelOutputWithPoolingAndCrossAttentions)— Q-Former(Querying Transformer)的输出。 -
language_model_outputs(CausalLMOutputWithPast或Seq2SeqLMOutput)— 语言模型的输出。
Blip2Model 的前向方法,覆盖了 __call__ 特殊方法。
虽然前向传递的配方需要在此函数内定义,但应该在此之后调用 Module 实例,而不是在此处调用,因为前者会负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from PIL import Image
>>> import requests
>>> from transformers import Blip2Processor, Blip2Model
>>> import torch
>>> device = "cuda" if torch.cuda.is_available() else "cpu"
>>> processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
>>> model = Blip2Model.from_pretrained("Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16)
>>> model.to(device)
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> prompt = "Question: how many cats are there? Answer:"
>>> inputs = processor(images=image, text=prompt, return_tensors="pt").to(device, torch.float16)
>>> outputs = model(**inputs)
get_text_features
( input_ids: Optional = None attention_mask: Optional = None decoder_input_ids: Optional = None decoder_attention_mask: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';text_outputs (CausalLMOutputWithPast, or tuple(torch.FloatTensor) if return_dict=False)
参数
-
input_ids(形状为(batch_size, sequence_length)的torch.LongTensor)— 词汇表中输入序列标记的索引。默认情况下将忽略填充。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。什么是输入 ID? -
attention_mask(形状为(batch_size, sequence_length)的torch.Tensor,可选)— 用于避免在填充标记索引上执行注意力的掩码。掩码值选在[0, 1]:-
对于
未被掩盖的标记为 1, -
对于
被掩盖的标记为 0。什么是注意力掩码?
-
-
decoder_input_ids(形状为(batch_size, target_sequence_length)的torch.LongTensor,可选)— 词汇表中解码器输入序列标记的索引。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.
call()。什么是解码器输入 ID?
T5 使用
pad_token_id作为decoder_input_ids生成的起始标记。如果使用了past_key_values,则可选择仅输入最后的decoder_input_ids(参见past_key_values)。要了解有关如何为预训练准备
decoder_input_ids的更多信息,请查看 T5 Training。 -
decoder_attention_mask(形状为(batch_size, target_sequence_length)的torch.BoolTensor,可选)— 默认行为:生成一个忽略decoder_input_ids中填充标记的张量。因果掩码也将默认使用。 -
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量中的hidden_states。 -
return_dict(bool, optional) — 是否返回一个 ModelOutput 而不是一个普通的元组。
返回
text_outputs (CausalLMOutputWithPast,或者如果return_dict=False则为tuple(torch.FloatTensor))
语言模型输出。如果return_dict=True,则输出是一个包含语言模型 logits、过去的键值和隐藏状态(如果output_hidden_states=True)的CausalLMOutputWithPast。
Blip2Model 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> import torch
>>> from transformers import AutoTokenizer, Blip2Model
>>> model = Blip2Model.from_pretrained("Salesforce/blip2-opt-2.7b")
>>> tokenizer = AutoTokenizer.from_pretrained("Salesforce/blip2-opt-2.7b")
>>> inputs = tokenizer(["a photo of a cat"], padding=True, return_tensors="pt")
>>> text_features = model.get_text_features(**inputs)
get_image_features
( pixel_values: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';vision_outputs (BaseModelOutputWithPooling or tuple of torch.FloatTensor)
参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。可以使用 Blip2Processor 获取像素值。有关详细信息,请参阅Blip2Processor.__call__()。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量中的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量中的hidden_states。 -
return_dict(bool, optional) — 是否返回一个 ModelOutput 而不是一个普通的元组。
返回
vision_outputs (BaseModelOutputWithPooling或torch.FloatTensor的元组)
视觉模型输出。如果return_dict=True,则输出是一个包含图像特征、池化图像特征和隐藏状态(如果output_hidden_states=True)的BaseModelOutputWithPooling。
Blip2Model 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> import torch
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, Blip2Model
>>> model = Blip2Model.from_pretrained("Salesforce/blip2-opt-2.7b")
>>> processor = AutoProcessor.from_pretrained("Salesforce/blip2-opt-2.7b")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, return_tensors="pt")
>>> image_outputs = model.get_image_features(**inputs)
get_qformer_features
( pixel_values: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';vision_outputs (BaseModelOutputWithPooling or tuple of torch.FloatTensor)
参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。可以使用 Blip2Processor 获取像素值。有关详细信息,请参阅Blip2Processor.__call__()。 -
input_ids(torch.LongTensor,形状为(batch_size, sequence_length),optional) — 语言模型词汇中输入序列标记的索引。可以提供输入标记作为文本提示,语言模型可以继续生成。可以使用 Blip2Processor 获取索引。有关详细信息,请参阅
Blip2Processor.__call__()。什么是输入 ID?
-
attention_mask(torch.Tensor,形状为(batch_size, sequence_length),optional) — 避免在填充标记索引上执行注意力的掩码。选择的掩码值为[0, 1]:-
对于
not masked的标记为 1, -
对于
masked的标记为 0。
什么是注意力掩码?
-
-
decoder_input_ids(形状为(batch_size, target_sequence_length)的torch.LongTensor,可选)— 解码器输入序列标记在语言模型词汇中的索引。仅在使用编码器-解码器语言模型(如 T5)时相关。可以使用 AutoTokenizer 来获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.
call()。解码器输入 ID 是什么? -
decoder_attention_mask(形状为(batch_size, target_sequence_length)的torch.BoolTensor,可选)— 默认行为:生成一个张量,忽略decoder_input_ids中的填充标记。因果掩码也将默认使用。仅在使用编码器-解码器语言模型(如 T5)时相关。
-
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回一个 ModelOutput 而不是一个普通元组。
返回
vision_outputs(BaseModelOutputWithPooling或torch.FloatTensor元组)
视觉模型输出。如果return_dict=True,则输出是包含图像特征、池化图像特征和隐藏状态(如果output_hidden_states=True)的BaseModelOutputWithPooling。
Blip2Model 的前向方法,覆盖__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import torch
>>> from PIL import Image
>>> import requests
>>> from transformers import Blip2Processor, Blip2Model
>>> processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
>>> model = Blip2Model.from_pretrained("Salesforce/blip2-opt-2.7b")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, return_tensors="pt")
>>> qformer_outputs = model.get_qformer_features(**inputs)
Blip2ForConditionalGeneration
class transformers.Blip2ForConditionalGeneration
( config: Blip2Config )
参数
config(Blip2Config)— 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
用于根据图像和可选文本提示生成文本的 BLIP-2 模型。该模型由视觉编码器、查询变换器(Q-Former)和语言模型组成。
可以选择将input_ids传递给模型,作为文本提示,以使语言模型继续提示。否则,语言模型将从[BOS](序列开始)标记开始生成文本。
请注意,Flan-T5 检查点不能转换为 float16。它们是使用 bfloat16 进行预训练的。
此模型继承自 PreTrainedModel。查看超类文档以了解库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
此模型还是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( pixel_values: FloatTensor input_ids: FloatTensor attention_mask: Optional = None decoder_input_ids: Optional = None decoder_attention_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None labels: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.blip_2.modeling_blip_2.Blip2ForConditionalGenerationModelOutput or tuple(torch.FloatTensor)
参数
-
pixel_values(形状为(batch_size, num_channels, height, width)的torch.FloatTensor)- 像素值。可以使用 Blip2Processor 获取像素值。有关详细信息,请参见Blip2Processor.__call__()。 -
input_ids(形状为(batch_size, sequence_length)的torch.LongTensor,可选)- 语言模型词汇表中输入序列标记的索引。输入标记可以选择作为文本提示提供,语言模型可以继续。可以使用 Blip2Processor 获取索引。有关详细信息,请参见
Blip2Processor.__call__()。输入 ID 是什么?
-
attention_mask(形状为(batch_size, sequence_length)的torch.Tensor,可选)- 用于避免在填充标记索引上执行注意力的掩码。选择的掩码值在[0, 1]中:-
对于“未屏蔽”的标记,
-
对于“屏蔽”的标记为 0。
什么是注意力掩码?
-
-
decoder_input_ids(形状为(batch_size, target_sequence_length)的torch.LongTensor,可选)- 解码器输入序列标记在语言模型词汇表中的索引。仅在使用编码器-解码器语言模型(如 T5)时相关。可以使用 AutoTokenizer 获取索引。有关详细信息,请参见 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.
call()。解码器输入 ID 是什么? -
decoder_attention_mask(形状为(batch_size, target_sequence_length)的torch.BoolTensor,可选)- 默认行为:生成一个张量,忽略decoder_input_ids中的填充标记。因果掩码也将默认使用。仅在使用编码器-解码器语言模型(如 T5)时相关。
-
output_attentions(bool,可选)- 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 -
output_hidden_states(bool,可选)- 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 -
return_dict(bool,可选)- 是否返回 ModelOutput 而不是普通元组。
返回
transformers.models.blip_2.modeling_blip_2.Blip2ForConditionalGenerationModelOutput或tuple(torch.FloatTensor)
一个transformers.models.blip_2.modeling_blip_2.Blip2ForConditionalGenerationModelOutput或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False时)包含根据配置(<class 'transformers.models.blip_2.configuration_blip_2.Blip2VisionConfig'>)和输入的各种元素。
-
loss(torch.FloatTensor,可选,在提供labels时返回,形状为(1,)的torch.FloatTensor)- 语言模型的语言建模损失。 -
logits(形状为(batch_size, sequence_length, config.vocab_size)的torch.FloatTensor)- 语言模型头的预测分数。 -
vision_outputs(BaseModelOutputWithPooling)- 视觉编码器的输出。 -
qformer_outputs(BaseModelOutputWithPoolingAndCrossAttentions)- Q-Former(Querying Transformer)的输出。 -
language_model_outputs(CausalLMOutputWithPast或Seq2SeqLMOutput)- 语言模型的输出。
Blip2ForConditionalGeneration 的前向方法,覆盖了__call__特殊方法。
尽管前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
示例:
准备处理器、模型和图像输入
>>> from PIL import Image
>>> import requests
>>> from transformers import Blip2Processor, Blip2ForConditionalGeneration
>>> import torch
>>> device = "cuda" if torch.cuda.is_available() else "cpu"
>>> processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
>>> model = Blip2ForConditionalGeneration.from_pretrained(
... "Salesforce/blip2-opt-2.7b", load_in_8bit=True, device_map={"": 0}, torch_dtype=torch.float16
... ) # doctest: +IGNORE_RESULT
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
图像字幕(不提供文本提示):
>>> inputs = processor(images=image, return_tensors="pt").to(device, torch.float16)
>>> generated_ids = model.generate(**inputs)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
>>> print(generated_text)
two cats laying on a couch
视觉问答(提示=问题):
>>> prompt = "Question: how many cats are there? Answer:"
>>> inputs = processor(images=image, text=prompt, return_tensors="pt").to(device="cuda", dtype=torch.float16)
>>> generated_ids = model.generate(**inputs)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
>>> print(generated_text)
two
请注意,也支持通过bitsandbytes进行 int8 推理。这大大减少了模型使用的内存量,同时保持相同的性能。
>>> model = Blip2ForConditionalGeneration.from_pretrained(
... "Salesforce/blip2-opt-2.7b", load_in_8bit=True, device_map={"": 0}, torch_dtype=torch.bfloat16
... ) # doctest: +IGNORE_RESULT
>>> inputs = processor(images=image, text=prompt, return_tensors="pt").to(device="cuda", dtype=torch.bfloat16)
>>> generated_ids = model.generate(**inputs)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
>>> print(generated_text)
two
generate
( pixel_values: FloatTensor input_ids: Optional = None attention_mask: Optional = None **generate_kwargs ) → export const metadata = 'undefined';captions (list)
参数
-
pixel_values(形状为(batch_size, num_channels, height, width)的torch.FloatTensor)—要处理的输入图像。 -
input_ids(形状为(batch_size, sequence_length)的torch.LongTensor,可选)—用作生成提示的序列。 -
attention_mask(形状为(batch_size, sequence_length)的torch.LongTensor,可选)—避免在填充标记索引上执行注意力的掩码
返回
字幕(列表)
一个长度为 batch_size * num_captions 的字符串列表。
覆盖generate函数以能够将模型用作条件生成器。
BridgeTower
原文链接:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/bridgetower
概述
BridgeTower 模型是由 Xiao Xu、Chenfei Wu、Shachar Rosenman、Vasudev Lal、Wanxiang Che、Nan Duan 在《BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning》中提出的。该模型的目标是在每个交叉模态编码器的每一层之间建立桥梁,以实现全面和详细的交互,从而在各种下游任务中取得显著的性能,几乎没有额外的性能和计算成本。
本文已被AAAI’23会议接受。
论文摘要如下:
近年来,具有双塔架构的视觉语言(VL)模型在视觉语言表示学习中占据主导地位。当前的 VL 模型要么使用轻量级的单模编码器并学习同时提取、对齐和融合两种模态,要么将深度预训练的单模编码器的最后一层单模表示馈送到顶部交叉模态编码器中。这两种方法都可能限制视觉语言表示学习并限制模型性能。在本文中,我们提出了 BRIDGETOWER,它引入了多个桥接层,建立了单模编码器的顶层与交叉模态编码器的每一层之间的连接。这使得在交叉模态编码器中能够有效地进行自底向上的跨模态对齐和融合,从而实现不同语义级别的预训练单模编码器的视觉和文本表示之间的交叉模态对齐和融合。仅使用 4M 张图像进行预训练,BRIDGETOWER 在各种下游视觉语言任务上实现了最先进的性能。特别是在 VQAv2 测试集上,BRIDGETOWER 实现了 78.73%的准确率,比之前的最先进模型 METER 高出 1.09%,使用相同的预训练数据几乎没有额外的参数和计算成本。值得注意的是,当进一步扩展模型时,BRIDGETOWER 实现了 81.15%的准确率,超过了在数量级更大的数据集上进行预训练的模型。
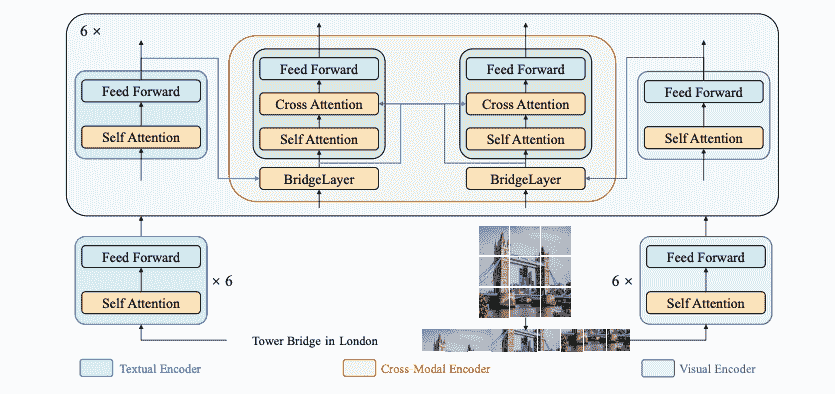 BridgeTower 架构。摘自原始论文。
BridgeTower 架构。摘自原始论文。
该模型由Anahita Bhiwandiwalla、Tiep Le和Shaoyen Tseng贡献。原始代码可以在这里找到。
使用提示和示例
BridgeTower 包括一个视觉编码器、一个文本编码器和一个带有多个轻量级桥接层的交叉模态编码器。该方法的目标是在每个交叉模态编码器的每一层之间建立桥梁,以实现全面和详细的交互。原则上,可以在提出的架构中应用任何视觉、文本或交叉模态编码器。
BridgeTowerProcessor 将 RobertaTokenizer 和 BridgeTowerImageProcessor 封装成一个单一实例,用于同时对文本进行编码和准备图像。
以下示例展示了如何使用 BridgeTowerProcessor 和 BridgeTowerForContrastiveLearning 来运行对比学习。
>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs
以下示例显示如何使用 BridgeTowerProcessor 和 BridgeTowerForImageAndTextRetrieval 运行图像文本检索。
>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs.logits[0, 1].item()
以下示例显示如何使用 BridgeTowerProcessor 和 BridgeTowerForMaskedLM 运行掩码语言建模。
>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> text = "a <mask> looking out of the window"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # prepare inputs
>>> encoding = processor(image, text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
>>> print(results)
.a cat looking out of the window.
提示:
-
此 BridgeTower 的实现使用 RobertaTokenizer 生成文本嵌入,并使用 OpenAI 的 CLIP/ViT 模型计算视觉嵌入。
-
发布了预训练的bridgeTower-base和bridgetower masked language modeling and image text matching的检查点。
-
请参考Table 5了解 BridgeTower 在图像检索和其他下游任务上的性能。
-
此模型的 PyTorch 版本仅在 torch 1.10 及更高版本中可用。
BridgeTowerConfig
class transformers.BridgeTowerConfig
( share_cross_modal_transformer_layers = True hidden_act = 'gelu' hidden_size = 768 initializer_factor = 1 layer_norm_eps = 1e-05 share_link_tower_layers = False link_tower_type = 'add' num_attention_heads = 12 num_hidden_layers = 6 tie_word_embeddings = False init_layernorm_from_vision_encoder = False text_config = None vision_config = None **kwargs )
参数
-
share_cross_modal_transformer_layers(bool, optional, defaults toTrue) — 是否共享跨模态 transformer 层。 -
hidden_act(strorfunction, optional, defaults to"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。 -
hidden_size(int, optional, defaults to 768) — 编码器层和池化层的维度。 -
initializer_factor(float, optional, defaults to 1) — 用于初始化所有权重矩阵的因子(应保持为 1,用于内部初始化测试)。 -
layer_norm_eps(float, optional, defaults to 1e-05) — 层归一化层使用的 epsilon。 -
share_link_tower_layers(bool, optional, defaults toFalse) — 是否共享桥/链接塔层。 -
link_tower_type(str, optional, defaults to"add") — 桥/链接层的类型。 -
num_attention_heads(int, optional, defaults to 12) — Transformer 编码器中每个注意力层的注意力头数。 -
num_hidden_layers(int, optional, defaults to 6) — Transformer 编码器中的隐藏层数量。 -
tie_word_embeddings(bool, optional, defaults toFalse) — 是否绑定输入和输出嵌入。 -
init_layernorm_from_vision_encoder(bool, optional, defaults toFalse) — 是否从视觉编码器初始化 LayerNorm。 -
text_config(dict, optional) — 用于初始化 BridgeTowerTextConfig 的配置选项字典。 -
vision_config(dict, optional) — 用于初始化 BridgeTowerVisionConfig 的配置选项字典。
这是用于存储 BridgeTowerModel 配置的配置类。根据指定的参数实例化一个 BridgeTower 模型,定义模型架构。使用默认值实例化配置将产生与 bridgetower-base BridgeTower/bridgetower-base架构类似的配置。
配置对象继承自 PretrainedConfig 并可用于控制模型输出。阅读来自 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import BridgeTowerModel, BridgeTowerConfig
>>> # Initializing a BridgeTower BridgeTower/bridgetower-base style configuration
>>> configuration = BridgeTowerConfig()
>>> # Initializing a model from the BridgeTower/bridgetower-base style configuration
>>> model = BridgeTowerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
from_text_vision_configs
( text_config: BridgeTowerTextConfig vision_config: BridgeTowerVisionConfig **kwargs )
从 BridgeTower 文本模型配置中实例化一个 BridgeTowerConfig(或派生类)。返回: BridgeTowerConfig: 配置对象的实例
BridgeTowerTextConfig
class transformers.BridgeTowerTextConfig
( vocab_size = 50265 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 initializer_factor = 1 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.1 attention_probs_dropout_prob = 0.1 max_position_embeddings = 514 type_vocab_size = 1 layer_norm_eps = 1e-05 pad_token_id = 1 bos_token_id = 0 eos_token_id = 2 position_embedding_type = 'absolute' use_cache = True **kwargs )
参数
-
vocab_size(int, 可选, 默认为 50265) — 模型文本部分的词汇表大小。定义了在调用 BridgeTowerModel 时可以表示的不同标记数量。 -
hidden_size(int, 可选, 默认为 768) — 编码器层和池化器层的维度。 -
num_hidden_layers(int, 可选, 默认为 12) — Transformer 编码器中的隐藏层数量。 -
num_attention_heads(int, 可选, 默认为 12) — Transformer 编码器中每个注意力层的注意力头数。 -
intermediate_size(int, 可选, 默认为 3072) — Transformer 编码器中“中间”(通常称为前馈)层的维度。 -
hidden_act(str或Callable, 可选, 默认为"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"silu"和"gelu_new"。 -
hidden_dropout_prob(float, 可选, 默认为 0.1) — 嵌入层、编码器和池化器中所有全连接层的丢弃概率。 -
attention_probs_dropout_prob(float, 可选, 默认为 0.1) — 注意力概率的丢弃比率。 -
max_position_embeddings(int, 可选, 默认为 514) — 此模型可能使用的最大序列长度。通常将其设置为一个较大的值以防万一(例如 512、1024 或 2048)。 -
type_vocab_size(int, 可选, 默认为 2) —token_type_ids的词汇表大小。 -
initializer_factor(float, 可选, 默认为 1) — 用于初始化所有权重矩阵的因子(应保持为 1,用于内部初始化测试)。 -
layer_norm_eps(float, 可选, 默认为 1e-05) — 层归一化层使用的 epsilon。 -
position_embedding_type(str, 可选, 默认为"absolute") — 位置嵌入的类型。选择"absolute"、"relative_key"、"relative_key_query"中的一个。对于位置嵌入,请使用"absolute"。有关"relative_key"的更多信息,请参考Self-Attention with Relative Position Representations (Shaw et al.)。有关"relative_key_query"的更多信息,请参考Improve Transformer Models with Better Relative Position Embeddings (Huang et al.) 中的 Method 4。 -
is_decoder(bool, 可选, 默认为False) — 模型是否用作解码器。如果为False,则模型用作编码器。 -
use_cache(bool, 可选, 默认为True) — 模型是否应返回最后的键/值注意力(并非所有模型都使用)。仅在config.is_decoder=True时相关。
这是用于存储 BridgeTowerModel 的文本配置的配置类。这里的默认值是从 RoBERTa 复制的。使用默认值实例化配置将产生与 bridgetower-base BridegTower/bridgetower-base架构类似的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import BridgeTowerTextConfig
>>> # Initializing a BridgeTower BridgeTower/bridgetower-base style configuration for the text model
>>> configuration = BridgeTowerTextConfig()
>>> # Accessing the configuration
>>> configuration
BridgeTowerVisionConfig
class transformers.BridgeTowerVisionConfig
( hidden_size = 768 num_hidden_layers = 12 num_channels = 3 patch_size = 16 image_size = 288 initializer_factor = 1 layer_norm_eps = 1e-05 stop_gradient = False share_layernorm = True remove_last_layer = False **kwargs )
参数
-
hidden_size(int,可选,默认为 768) — 编码器层和池化层的维度。 -
num_hidden_layers(int,可选,默认为 12) — 视觉编码器模型中的隐藏层数量。 -
patch_size(int,可选,默认为 16) — 每个补丁的大小(分辨率)。 -
image_size(int,可选,默认为 288) — 每个图像的大小(分辨率)。 -
initializer_factor(float,可选,默认为 1) — 用于初始化所有权重矩阵的因子(应保持为 1,用于内部初始化测试)。 -
layer_norm_eps(float,可选,默认为 1e-05) — 层归一化层使用的 epsilon。 -
stop_gradient(bool,可选,默认为False) — 是否停止训练的梯度。 -
share_layernorm(bool,可选,默认为True) — 是否共享 LayerNorm 层。 -
remove_last_layer(bool,可选,默认为False) — 是否从视觉编码器中移除最后一层。
这是用于存储 BridgeTowerModel 的视觉配置的配置类。使用默认值实例化配置将产生与 bridgetower-base BridgeTower/bridgetower-base架构类似的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import BridgeTowerVisionConfig
>>> # Initializing a BridgeTower BridgeTower/bridgetower-base style configuration for the vision model
>>> configuration = BridgeTowerVisionConfig()
>>> # Accessing the configuration
>>> configuration
BridgeTowerImageProcessor
class transformers.BridgeTowerImageProcessor
( do_resize: bool = True size: Dict = 288 size_divisor: int = 32 resample: Resampling = <Resampling.BICUBIC: 3> do_rescale: bool = True rescale_factor: Union = 0.00392156862745098 do_normalize: bool = True image_mean: Union = None image_std: Union = None do_center_crop: bool = True do_pad: bool = True **kwargs )
参数
-
do_resize(bool,可选,默认为True) — 是否将图像的(高度,宽度)尺寸调整为指定的size。可以被preprocess方法中的do_resize参数覆盖。 -
size(Dict[str, int]可选,默认为 288) — 将输入的较短边调整为size["shortest_edge"]。较长边将受限于int((1333 / 800) * size["shortest_edge"]),同时保持纵横比。仅在do_resize设置为True时有效。可以被preprocess方法中的size参数覆盖。 -
size_divisor(int,可选,默认为 32) — 确保高度和宽度都可以被划分的大小。仅在do_resize设置为True时有效。可以被preprocess方法中的size_divisor参数覆盖。 -
resample(PILImageResampling, 可选, 默认为Resampling.BICUBIC) — 如果调整图像大小,则使用的重采样滤波器。仅在do_resize设置为True时有效。 -
do_rescale(bool, 可选, 默认为True) — 是否按照指定的比例rescale_factor对图像进行重新缩放。可以被preprocess方法中的do_rescale参数覆盖。 -
rescale_factor(int或float, 可选, 默认为1/255) — 如果重新缩放图像,则使用的缩放因子。仅在do_rescale设置为True时有效。 -
do_normalize(bool, 可选, 默认为True) — 是否对图像进行归一化。可以被preprocess方法中的do_normalize参数覆盖。 -
image_mean(float或List[float], 可选, 默认为IMAGENET_STANDARD_MEAN) — 如果归一化图像,则使用的均值。这是一个浮点数或与图像通道数相同长度的浮点数列表。可以被preprocess方法中的image_mean参数覆盖。 -
image_std(float或List[float], 可选, 默认为IMAGENET_STANDARD_STD) — 如果归一化图像,则使用的标准差。这是一个浮点数或与图像通道数相同长度的浮点数列表。可以被preprocess方法中的image_std参数覆盖。 -
do_center_crop(bool, 可选, 默认为True) — 是否对图像进行中心裁剪。可以被preprocess方法中的do_center_crop参数覆盖。 -
do_pad(bool, 可选, 默认为True) — 是否将图像填充到批次中图像的(max_height, max_width)。可以被preprocess方法中的do_pad参数覆盖。
构建一个 BridgeTower 图像处理器。
preprocess
( images: Union do_resize: Optional = None size: Optional = None size_divisor: Optional = None resample: Resampling = None do_rescale: Optional = None rescale_factor: Optional = None do_normalize: Optional = None image_mean: Union = None image_std: Union = None do_pad: Optional = None do_center_crop: Optional = None return_tensors: Union = None data_format: ChannelDimension = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None **kwargs )
参数
-
images(ImageInput) — 要预处理的图像。期望传入单个图像或图像批次,像素值范围为 0 到 255。如果传入像素值在 0 到 1 之间的图像,请设置do_rescale=False。 -
do_resize(bool, 可选, 默认为self.do_resize) — 是否调整图像大小。 -
size(Dict[str, int], 可选, 默认为self.size) — 控制resize后图像的大小。图像的最短边被调整为size["shortest_edge"],同时保持纵横比。如果调整后图像的最长边 >int(size["shortest_edge"] * (1333 / 800)),则再次调整图像大小,使最长边等于int(size["shortest_edge"] * (1333 / 800))。 -
size_divisor(int, 可选, 默认为self.size_divisor) — 将图像调整为此值的倍数。 -
resample(PILImageResampling, 可选, 默认为self.resample) — 如果调整图像大小,则使用的重采样滤波器。仅在do_resize设置为True时有效。 -
do_rescale(bool, 可选, 默认为self.do_rescale) — 是否将图像值重新缩放到 [0 - 1] 之间。 -
rescale_factor(float, 可选, 默认为self.rescale_factor) — 如果do_rescale设置为True,则用于重新缩放图像的缩放因子。 -
do_normalize(bool, 可选, 默认为self.do_normalize) — 是否对图像进行归一化。 -
image_mean(float或List[float], 可选, 默认为self.image_mean) — 如果do_normalize设置为True,则用于归一化图像的图像均值。 -
image_std(float或List[float],可选,默认为self.image_std)— 如果do_normalize设置为True,用于归一化图像的图像标准差。 -
do_pad(bool,可选,默认为self.do_pad)— 是否将图像填充到批处理中的(max_height, max_width)。如果为True,还会创建并返回像素掩码。 -
do_center_crop(bool,可选,默认为self.do_center_crop)— 是否对图像进行中心裁剪。如果输入尺寸小于任何边缘的crop_size,则图像将填充为 0,然后进行中心裁剪。 -
return_tensors(str或TensorType,可选)— 要返回的张量类型。可以是以下之一:-
未设置:返回一个
np.ndarray列表。 -
TensorType.TENSORFLOW或'tf':返回一个tf.Tensor类型的批处理。 -
TensorType.PYTORCH或'pt':返回一个torch.Tensor类型的批处理。 -
TensorType.NUMPY或'np':返回一个np.ndarray类型的批处理。 -
TensorType.JAX或'jax':返回一个jax.numpy.ndarray类型的批处理。
-
-
data_format(ChannelDimension或str,可选,默认为ChannelDimension.FIRST)— 输出图像的通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST:图像以(num_channels, height, width)格式。 -
"channels_last"或ChannelDimension.LAST:图像以(height, width, num_channels)格式。 -
未设置:使用输入图像的通道维度格式。
-
-
input_data_format(ChannelDimension或str,可选)— 输入图像的通道维度格式。如果未设置,将从输入图像中推断通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST:图像以(num_channels, height, width)格式。 -
"channels_last"或ChannelDimension.LAST:图像以(height, width, num_channels)格式。 -
"none"或ChannelDimension.NONE:图像以(height, width)格式。
-
预处理一张图片或一批图片。
BridgeTowerProcessor
class transformers.BridgeTowerProcessor
( image_processor tokenizer )
参数
-
image_processor(BridgeTowerImageProcessor)— 一个 BridgeTowerImageProcessor 的实例。图像处理器是必需的输入。 -
tokenizer(RobertaTokenizerFast)— 一个[‘RobertaTokenizerFast`]的实例。分词器是必需的输入。
构建一个 BridgeTower 处理器,将一个 Roberta 分词器和一个 BridgeTower 图像处理器包装成一个处理器。
BridgeTowerProcessor 提供了 BridgeTowerImageProcessor 和 RobertaTokenizerFast 的所有功能。查看call()和decode()的文档字符串以获取更多信息。
__call__
( images text: Union = None add_special_tokens: bool = True padding: Union = False truncation: Union = None max_length: Optional = None stride: int = 0 pad_to_multiple_of: Optional = None return_token_type_ids: Optional = None return_attention_mask: Optional = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True return_tensors: Union = None **kwargs )
此方法使用 BridgeTowerImageProcessor.call()方法准备模型的图像,并使用 RobertaTokenizerFast.call()准备模型的文本。
有关更多信息,请参考上述两种方法的文档字符串。
BridgeTowerModel
class transformers.BridgeTowerModel
( config )
参数
config(BridgeTowerConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的 BridgeTower 模型,输出 BridgeTowerModelOutput 对象,没有特定的头部在顶部。这个模型是 PyTorch torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>_ 的子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( input_ids: Optional = None attention_mask: Optional = None token_type_ids: Optional = None pixel_values: Optional = None pixel_mask: Optional = None head_mask: Optional = None inputs_embeds: Optional = None image_embeds: Optional = None image_token_type_idx: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None labels: Optional = None ) → export const metadata = 'undefined';transformers.models.bridgetower.modeling_bridgetower.BridgeTowerModelOutput or tuple(torch.FloatTensor)
参数
-
input_ids(torch.LongTensor,形状为({0})) — 词汇表中输入序列标记的索引。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。 -
attention_mask(torch.FloatTensor,形状为({0}),可选) — 避免在填充标记索引上执行注意力的掩码。掩码值在[0, 1]中选择:-
1 表示未被
掩码的标记, -
0 表示被
掩码的标记。什么是注意力掩码?
-
-
token_type_ids(torch.LongTensor,形状为({0}),可选) — 段标记索引,用于指示输入的第一部分和第二部分。索引在[0, 1]中选择:-
0 对应于一个 句子 A 标记,
-
1 对应于一个 句子 B 标记。什么是标记类型 ID?
-
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。可以使用 BridgeTowerImageProcessor 获取像素值。有关详细信息,请参阅 BridgeTowerImageProcessor.call()。 -
pixel_mask(torch.LongTensor,形状为(batch_size, height, width),可选) — 避免在填充像素值上执行注意力的掩码。掩码值在[0, 1]中选择:-
1 表示真实的像素(即未被
掩码), -
0 表示填充的像素(即被
掩码)。什么是注意力掩码? <../glossary.html#attention-mask>__
-
-
head_mask(torch.FloatTensor,形状为(num_heads,)或(num_layers, num_heads),可选) — 用于使自注意力模块中选择的头部失效的掩码。掩码值在[0, 1]中选择:-
1 表示头部未被
掩码, -
0 表示头部被
掩码。
-
-
inputs_embeds(torch.FloatTensor,形状为({0}, hidden_size),可选) — 可选地,可以直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,而不是模型的内部嵌入查找矩阵。 -
image_embeds(torch.FloatTensor,形状为(batch_size, num_patches, hidden_size),可选) — 可选地,可以直接传递嵌入表示,而不是传递pixel_values。如果您想要更多控制如何将pixel_values转换为补丁嵌入,这将非常有用。 -
image_token_type_idx(int,可选) —- 图像的标记类型 ID。
-
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选) — 是否返回一个 ModelOutput 而不是一个普通元组。 -
output_hidden_states(bool, optional) — 如果设置为True,则返回隐藏状态作为一个列表,分别包含文本、图像和跨模态组件的隐藏状态。即(hidden_states_text, hidden_states_image, hidden_states_cross_modal),其中每个元素都是对应模态的隐藏状态列表。hidden_states_txt/img是对应单模态隐藏状态的张量列表,hidden_states_cross_modal是一个包含每个桥接层的cross_modal_text_hidden_states和cross_modal_image_hidden_states的元组列表。 -
labels(torch.LongTensor,形状为(batch_size,),可选) — 目前不支持标签。
返回
transformers.models.bridgetower.modeling_bridgetower.BridgeTowerModelOutput或tuple(torch.FloatTensor)
一个transformers.models.bridgetower.modeling_bridgetower.BridgeTowerModelOutput或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False时)包含根据配置(BridgeTowerConfig)和输入的不同元素。
-
text_features(torch.FloatTensor,形状为(batch_size, text_sequence_length, hidden_size)) — 模型最后一层文本输出的隐藏状态序列。 -
image_features(torch.FloatTensor,形状为(batch_size, image_sequence_length, hidden_size)) — 模型最后一层图像输出的隐藏状态序列。 -
pooler_output(torch.FloatTensor,形状为(batch_size, hidden_size x 2)) — 文本和图像序列的第一个标记(分类标记)的最后一层隐藏状态的连接,分别经过用于辅助预训练任务的层进一步处理。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入的输出加上每层的输出)。模型在每一层输出的隐藏状态以及可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
BridgeTowerModel 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
示例:
>>> from transformers import BridgeTowerProcessor, BridgeTowerModel
>>> from PIL import Image
>>> import requests
>>> # prepare image and text
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> text = "hello world"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base")
>>> model = BridgeTowerModel.from_pretrained("BridgeTower/bridgetower-base")
>>> inputs = processor(image, text, return_tensors="pt")
>>> outputs = model(**inputs)
>>> outputs.keys()
odict_keys(['text_features', 'image_features', 'pooler_output'])
BridgeTowerForContrastiveLearning
class transformers.BridgeTowerForContrastiveLearning
( config )
参数
config(BridgeTowerConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
在顶部具有图像文本对比头部的 BridgeTower 模型,计算图像文本对比损失。
这个模型是 PyTorch 的torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>_ 子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( input_ids: Optional = None attention_mask: Optional = None token_type_ids: Optional = None pixel_values: Optional = None pixel_mask: Optional = None head_mask: Optional = None inputs_embeds: Optional = None image_embeds: Optional = None output_attentions: Optional = None output_hidden_states: Optional = True return_dict: Optional = None return_loss: Optional = None ) → export const metadata = 'undefined';transformers.models.bridgetower.modeling_bridgetower.BridgeTowerContrastiveOutput or tuple(torch.FloatTensor)
参数
-
input_ids(torch.LongTensor,形状为({0})) — 词汇表中输入序列标记的索引。可以使用 AutoTokenizer 获取索引。查看 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()获取详细信息。什么是输入 ID? -
attention_mask(torch.FloatTensor,形状为({0}),optional) — 用于避免在填充标记索引上执行注意力的掩码。掩码值选择在[0, 1]之间:-
1 表示
未被遮罩的标记, -
0 表示
被遮罩的标记。什么是注意力掩码?
-
-
token_type_ids(torch.LongTensor,形状为({0}),optional) — 段标记索引,指示输入的第一部分和第二部分。索引选择在[0, 1]之间:-
0 对应于句子 A标记,
-
1 对应于句子 B标记。什么是标记类型 ID?
-
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。可以使用 BridgeTowerImageProcessor 获取像素值。查看 BridgeTowerImageProcessor.call()获取详细信息。 -
pixel_mask(torch.LongTensor,形状为(batch_size, height, width),optional) — 用于避免在填充像素值上执行注意力的掩码。掩码值选择在[0, 1]之间:-
1 表示真实像素(即
未被遮罩), -
0 表示填充像素(即
被遮罩)。什么是注意力掩码?<../glossary.html#attention-mask>__
-
-
head_mask(torch.FloatTensor,形状为(num_heads,)或(num_layers, num_heads),optional) — 用于使自注意力模块中选择的头部失效的掩码。掩码值选择在[0, 1]之间:-
1 表示头部
未被遮罩, -
0 表示头部
被遮罩。
-
-
inputs_embeds(torch.FloatTensor,形状为({0}, hidden_size),optional) — 可选地,可以直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为与模型内部嵌入查找矩阵相关联的向量,则这很有用。 -
image_embeds(torch.FloatTensor,形状为(batch_size, num_patches, hidden_size),optional) — 可选地,可以直接传递嵌入表示,而不是传递pixel_values。如果您想要更多控制如何将pixel_values转换为补丁嵌入,则这很有用。 -
image_token_type_idx(int, optional) —- 图像的标记类型 ID。
-
output_attentions(bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量中的attentions。 -
output_hidden_states(bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量中的hidden_states。 -
return_dict(bool, 可选) — 是否返回 ModelOutput 而不是普通元组。 -
return_loss(bool, 可选) — 是否返回对比损失。
返回
transformers.models.bridgetower.modeling_bridgetower.BridgeTowerContrastiveOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.bridgetower.modeling_bridgetower.BridgeTowerContrastiveOutput 或一个 torch.FloatTensor 元组(如果传递 return_dict=False 或 config.return_dict=False 或 config.return_dict=False)包含根据配置(BridgeTowerConfig)和输入的各种元素。
-
loss(torch.FloatTensor,形状为(1,),可选,当return_loss为True时返回) — 图像-文本对比损失。 -
logits(torch.FloatTensor,形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 前每个词汇标记的分数)。 -
text_embeds(torch.FloatTensor),可选,当使用with_projection=True初始化模型时返回) — 通过将投影层应用于 pooler_output 获得的文本嵌入。 -
image_embeds(torch.FloatTensor),可选,当使用with_projection=True初始化模型时返回) — 通过将投影层应用于 pooler_output 获得的图像嵌入。 -
cross_embeds(torch.FloatTensor),可选,当使用with_projection=True初始化模型时返回) — 通过将投影层应用于 pooler_output 获得的文本-图像跨模态嵌入。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组。模型在每个层的输出的隐藏状态加上可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。
BridgeTowerForContrastiveLearning 的前向方法,覆盖了 __call__ 特殊方法。
虽然前向传递的方法需要在此函数内定义,但应该在之后调用 Module 实例而不是这个,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
>>> import requests
>>> from PIL import Image
>>> import torch
>>> image_urls = [
... "https://farm4.staticflickr.com/3395/3428278415_81c3e27f15_z.jpg",
... "http://images.cocodataset.org/val2017/000000039769.jpg",
... ]
>>> texts = ["two dogs in a car", "two cats sleeping on a couch"]
>>> images = [Image.open(requests.get(url, stream=True).raw) for url in image_urls]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> inputs = processor(images, texts, padding=True, return_tensors="pt")
>>> loss = model(**inputs, return_loss=True).loss
>>> inputs = processor(images, texts[::-1], padding=True, return_tensors="pt")
>>> loss_swapped = model(**inputs, return_loss=True).loss
>>> print("Loss", round(loss.item(), 4))
Loss 0.0019
>>> print("Loss with swapped images", round(loss_swapped.item(), 4))
Loss with swapped images 2.126
BridgeTowerForMaskedLM
class transformers.BridgeTowerForMaskedLM
( config )
参数
config(BridgeTowerConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained() 方法以加载模型权重。
BridgeTower 模型在预训练期间在顶部具有语言建模头。
这个模型是 PyTorch 的 torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>_ 子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( input_ids: Optional = None attention_mask: Optional = None token_type_ids: Optional = None pixel_values: Optional = None pixel_mask: Optional = None head_mask: Optional = None inputs_embeds: Optional = None image_embeds: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None labels: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.MaskedLMOutput or tuple(torch.FloatTensor)
参数
-
input_ids(torch.LongTensorof shape(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。什么是输入 ID? -
attention_mask(torch.FloatTensorof shape(batch_size, sequence_length), optional) — 用于避免在填充标记索引上执行注意力的掩码。掩码值在[0, 1]中选择:-
1 表示未被遮蔽的标记,
-
0 表示被遮蔽的标记。什么是注意力掩码?
-
-
token_type_ids(torch.LongTensorof shape(batch_size, sequence_length), optional) — 段落标记索引,用于指示输入的第一部分和第二部分。索引在[0, 1]中选择:-
0 对应于 句子 A 的标记,
-
1 对应于 句子 B 的标记。什么是标记类型 ID?
-
-
pixel_values(torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。可以使用 BridgeTowerImageProcessor 获取像素值。有关详细信息,请参阅 BridgeTowerImageProcessor.call()。 -
pixel_mask(torch.LongTensorof shape(batch_size, height, width), optional) — 用于避免在填充像素值上执行注意力的掩码。掩码值在[0, 1]中选择:-
1 表示真实的像素(即未被遮蔽),
-
0 表示填充的像素(即
masked)。什么是注意力掩码?<../glossary.html#attention-mask>__
-
-
head_mask(torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — 用于使自注意力模块的选定头部失效的掩码。掩码值在[0, 1]中选择:-
1 表示头部未被遮蔽,
-
0 表示头部被遮蔽。
-
-
inputs_embeds(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,而不是模型的内部嵌入查找矩阵,这将非常有用。 -
image_embeds(torch.FloatTensorof shape(batch_size, num_patches, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递pixel_values。如果您想要更多控制如何将pixel_values转换为补丁嵌入,这将非常有用。 -
image_token_type_idx(int, optional) —- 图像的标记类型 ID。
-
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回的张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回的张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回一个 ModelOutput 而不是一个普通的元组。 -
labels(形状为(batch_size, sequence_length)的torch.LongTensor,可选)— 用于计算掩码语言建模损失的标签。索引应在[-100, 0, ..., config.vocab_size]内(参见input_ids文档字符串)。索引设置为-100的标记将被忽略(掩码),损失仅计算具有标签在[0, ..., config.vocab_size]中的标记。
返回
transformers.modeling_outputs.MaskedLMOutput 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.MaskedLMOutput 或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False时)包括各种元素,取决于配置(BridgeTowerConfig)和输入。
-
loss(形状为(1,)的torch.FloatTensor,可选,当提供labels时返回)— 掩码语言建模(MLM)损失。 -
logits(形状为(batch_size, sequence_length, config.vocab_size)的torch.FloatTensor)— 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)— 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入的输出,如果模型有一个嵌入层,+ 一个用于每一层的输出)。模型在每一层输出的隐藏状态以及可选的初始嵌入输出。
-
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)— 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
BridgeTowerForMaskedLM 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> text = "a <mask> looking out of the window"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # prepare inputs
>>> encoding = processor(image, text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
>>> print(results)
.a cat looking out of the window.
BridgeTowerForImageAndTextRetrieval
class transformers.BridgeTowerForImageAndTextRetrieval
( config )
参数
config(BridgeTowerConfig)— 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
BridgeTower 模型变压器,顶部带有分类器头(在[CLS]标记的最终隐藏状态之上的线性层),用于图像到文本匹配。
这个模型是一个 PyTorch torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>_ 子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有内容。
forward
( input_ids: Optional = None attention_mask: Optional = None token_type_ids: Optional = None pixel_values: Optional = None pixel_mask: Optional = None head_mask: Optional = None inputs_embeds: Optional = None image_embeds: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None labels: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
参数
-
input_ids(torch.LongTensorof shape({0})) — 词汇表中输入序列标记的索引。 可以使用 AutoTokenizer 获取索引。 有关详细信息,请参见 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。 什么是输入 ID? -
attention_mask(torch.FloatTensorof shape({0}), optional) — 用于避免在填充标记索引上执行注意力的掩码。 选择的掩码值在[0, 1]之间:-
值为 1 的标记是
not masked, -
值为 0 的标记是
masked。 什么是注意力掩码?
-
-
token_type_ids(torch.LongTensorof shape({0}), optional) — 段标记索引,指示输入的第一部分和第二部分。 索引在[0, 1]中选择:-
值为 0 对应于 句子 A 标记,
-
1 对应于 句子 B 标记。 什么是标记类型 ID?
-
-
pixel_values(torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。 可以使用 BridgeTowerImageProcessor 获取像素值。 有关详细信息,请参见 BridgeTowerImageProcessor.call()。 -
pixel_mask(torch.LongTensorof shape(batch_size, height, width), optional) — 用于避免在填充像素值上执行注意力的掩码。 选择的掩码值在[0, 1]之间:-
值为 1 的像素是真实的(即
not masked), -
填充像素的值为 0(即
masked)。什么是注意力掩码? <../glossary.html#attention-mask>__
-
-
head_mask(torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — 用于使自注意力模块的选定头部失效的掩码。 选择的掩码值在[0, 1]之间:-
值为 1 表示头部未被
masked, -
值为 0 表示头部被
masked。
-
-
inputs_embeds(torch.FloatTensorof shape({0}, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。 如果您想要更多控制如何将input_ids索引转换为相关向量,而不是模型的内部嵌入查找矩阵,这将非常有用。 -
image_embeds(torch.FloatTensorof shape(batch_size, num_patches, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递pixel_values。 如果您想要更多控制如何将pixel_values转换为补丁嵌入,这将非常有用。 -
image_token_type_idx(int, optional) —- 图像的标记类型 ID。
-
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。 有关更多详细信息,请参见返回张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。 有关更多详细信息,请参见返回张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。 -
labels(torch.LongTensorof shape(batch_size, 1), optional) — 用于计算图像文本匹配损失的标签。 0 表示配对不匹配,1 表示匹配。 标签为 0 的配对将被跳过计算。
返回
transformers.modeling_outputs.SequenceClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.SequenceClassifierOutput 或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False时)包含各种元素,取决于配置(BridgeTowerConfig)和输入。
-
loss(形状为(1,)的torch.FloatTensor,可选,当提供labels时返回) - 分类(如果 config.num_labels==1 则为回归)损失。 -
logits(形状为(batch_size, config.num_labels)的torch.FloatTensor) - 分类(如果 config.num_labels==1 则为回归)得分(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) - 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入的输出+每一层的输出)。模型在每一层输出的隐藏状态加上可选的初始嵌入输出。
-
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) - 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。注意力权重在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
BridgeTowerForImageAndTextRetrieval 的前向方法覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs.logits[0, 1].item()
BROS
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/bros
概述
BROS 模型是由 Teakgyu Hong、Donghyun Kim、Mingi Ji、Wonseok Hwang、Daehyun Nam、Sungrae Park 在BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents中提出的。
BROS 代表BERT 依赖空间性。它是一个仅编码器的 Transformer 模型,接受一系列标记和它们的边界框作为输入,并输出一系列隐藏状态。BROS 编码相对空间信息而不是使用绝对空间信息。
它通过两个目标进行预训练:BERT 中使用的标记掩码语言建模目标(TMLM)和一种新颖的区域掩码语言建模目标(AMLM)。在 TMLM 中,标记被随机掩码,模型使用空间信息和其他未掩码的标记来预测掩码的标记。AMLM 是 TMLM 的二维版本。它随机掩码文本标记,并使用与 TMLM 相同的信息进行预测,但它掩码文本块(区域)。
BrosForTokenClassification在 BrosModel 之上有一个简单的线性层。它预测每个标记的标签。BrosSpadeEEForTokenClassification在 BrosModel 之上有一个initial_token_classifier和subsequent_token_classifier。initial_token_classifier用于预测每个实体的第一个标记,subsequent_token_classifier用于预测实体内的下一个标记。BrosSpadeELForTokenClassification在 BrosModel 之上有一个entity_linker。entity_linker用于预测两个实体之间的关系。
BrosForTokenClassification和BrosSpadeEEForTokenClassification本质上执行相同的任务。然而,BrosForTokenClassification假设输入标记是完全串行化的(这是一个非常具有挑战性的任务,因为它们存在于二维空间),而BrosSpadeEEForTokenClassification允许更灵活地处理串行化错误,因为它从一个标记预测下一个连接标记。
BrosSpadeELForTokenClassification执行实体内链接任务。如果这两个实体共享某种关系,则它预测一个标记(一个实体)到另一个标记(另一个实体)的关系。
BROS 在关键信息提取(KIE)基准测试中取得了可比较或更好的结果,如 FUNSD、SROIE、CORD 和 SciTSR,而不依赖于显式的视觉特征。
论文摘要如下:
从文档图像中提取关键信息(KIE)需要理解二维空间中文本的上下文和空间语义。许多最近的研究尝试通过开发专注于将文档图像的视觉特征与文本及其布局结合的预训练语言模型来解决该任务。另一方面,本文通过回归基本问题来解决问题:文本和布局的有效组合。具体而言,我们提出了一个名为 BROS(BERT 依赖空间性)的预训练语言模型,它编码了二维空间中文本的相对位置,并通过区域掩码策略从未标记的文档中学习。通过这种针对理解二维空间中文本的优化训练方案,BROS 在四个 KIE 基准测试(FUNSD、SROIE、CORD 和 SciTSR)上显示出与先前方法相当或更好的性能,而不依赖于视觉特征。本文还揭示了 KIE 任务中的两个现实挑战-(1)减少由于不正确的文本排序而产生的错误和(2)有效地从更少的下游示例中学习-并展示了 BROS 相对于先前方法的优越性。
这个模型是由jinho8345贡献的。原始代码可以在这里找到。
用法提示和示例
- forward() 需要
input_ids和bbox(边界框)。每个边界框应该以 (x0, y0, x1, y1) 格式(左上角,右下角)表示。边界框的获取取决于外部 OCR 系统。x坐标应该通过文档图像宽度进行归一化,y坐标应该通过文档图像高度进行归一化。
def expand_and_normalize_bbox(bboxes, doc_width, doc_height):
# here, bboxes are numpy array
# Normalize bbox -> 0 ~ 1
bboxes[:, [0, 2]] = bboxes[:, [0, 2]] / width
bboxes[:, [1, 3]] = bboxes[:, [1, 3]] / height
- [
~transformers.BrosForTokenClassification.forward,~transformers.BrosSpadeEEForTokenClassification.forward,~transformers.BrosSpadeEEForTokenClassification.forward] 需要不仅input_ids和bbox,还需要box_first_token_mask用于损失计算。这是一个用于过滤每个框的非第一个标记的掩码。您可以通过保存从单词创建input_ids时的边界框的起始标记索引来获得此掩码。您可以使用以下代码生成box_first_token_mask,
def make_box_first_token_mask(bboxes, words, tokenizer, max_seq_length=512):
box_first_token_mask = np.zeros(max_seq_length, dtype=np.bool_)
# encode(tokenize) each word from words (List[str])
input_ids_list: List[List[int]] = [tokenizer.encode(e, add_special_tokens=False) for e in words]
# get the length of each box
tokens_length_list: List[int] = [len(l) for l in input_ids_list]
box_end_token_indices = np.array(list(itertools.accumulate(tokens_length_list)))
box_start_token_indices = box_end_token_indices - np.array(tokens_length_list)
# filter out the indices that are out of max_seq_length
box_end_token_indices = box_end_token_indices[box_end_token_indices < max_seq_length - 1]
if len(box_start_token_indices) > len(box_end_token_indices):
box_start_token_indices = box_start_token_indices[: len(box_end_token_indices)]
# set box_start_token_indices to True
box_first_token_mask[box_start_token_indices] = True
return box_first_token_mask
资源
- 演示脚本可以在 这里 找到。
BrosConfig
class transformers.BrosConfig
( vocab_size = 30522 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.1 attention_probs_dropout_prob = 0.1 max_position_embeddings = 512 type_vocab_size = 2 initializer_range = 0.02 layer_norm_eps = 1e-12 pad_token_id = 0 dim_bbox = 8 bbox_scale = 100.0 n_relations = 1 classifier_dropout_prob = 0.1 **kwargs )
参数
-
vocab_size(int, optional, defaults to 30522) — Bros 模型的词汇表大小。定义了在调用 BrosModel 或TFBrosModel时可以由inputs_ids表示的不同标记数量。 -
hidden_size(int, optional, defaults to 768) — 编码器层和池化层的维度。 -
num_hidden_layers(int, optional, defaults to 12) — Transformer 编码器中的隐藏层数量。 -
num_attention_heads(int, optional, defaults to 12) — Transformer 编码器中每个注意力层的注意力头数量。 -
intermediate_size(int, optional, defaults to 3072) — Transformer 编码器中“中间”(通常称为前馈)层的维度。 -
hidden_act(strorCallable, optional, defaults to"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu","relu","silu"和"gelu_new"。 -
hidden_dropout_prob(float, optional, defaults to 0.1) — 嵌入层、编码器和池化器中所有全连接层的丢失概率。 -
attention_probs_dropout_prob(float, optional, defaults to 0.1) — 注意力概率的丢失比率。 -
max_position_embeddings(int, optional, defaults to 512) — 此模型可能使用的最大序列长度。通常将其设置为较大的值以防万一(例如,512、1024 或 2048)。 -
type_vocab_size(int, optional, defaults to 2) — 在调用 BrosModel 或TFBrosModel时传递的token_type_ids的词汇表大小。 -
initializer_range(float, optional, defaults to 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
layer_norm_eps(float, optional, defaults to 1e-12) — 层归一化层使用的 epsilon。 -
pad_token_id(int, optional, defaults to 0) — 令牌词汇表中填充令牌的索引。 -
dim_bbox(int, optional, defaults to 8) — 边界框坐标的维度。 (x0, y1, x1, y0, x1, y1, x0, y1) -
bbox_scale(float, optional, defaults to 100.0) — 边界框坐标的缩放因子。 -
n_relations(int, optional, defaults to 1) — SpadeEE(实体提取)、SpadeEL(实体链接)头部的关系数量。 -
classifier_dropout_prob(float, optional, defaults to 0.1) — 分类器头部的丢失比率。
这是用于存储 BrosModel 或TFBrosModel配置的配置类。根据指定的参数实例化一个 Bros 模型,定义模型架构。使用默认值实例化配置将产生类似于 Bros jinho8345/bros-base-uncased架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import BrosConfig, BrosModel
>>> # Initializing a BROS jinho8345/bros-base-uncased style configuration
>>> configuration = BrosConfig()
>>> # Initializing a model from the jinho8345/bros-base-uncased style configuration
>>> model = BrosModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
BrosProcessor
class transformers.BrosProcessor
( tokenizer = None **kwargs )
参数
tokenizer(BertTokenizerFast, 可选) — 一个[‘BertTokenizerFast`]的实例。这是一个必需的输入。
构建一个包装了 BERT tokenizer 的 Bros 处理器。
BrosProcessor 提供了 BertTokenizerFast 的所有功能。查看call()和decode()的文档字符串获取更多信息。
__call__
( text: Union = None add_special_tokens: bool = True padding: Union = False truncation: Union = None max_length: Optional = None stride: int = 0 pad_to_multiple_of: Optional = None return_token_type_ids: Optional = None return_attention_mask: Optional = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True return_tensors: Union = None **kwargs )
此方法使用 BertTokenizerFast.call()准备文本以供模型使用。
请参考上述两种方法的文档字符串获取更多信息。
BrosModel
class transformers.BrosModel
( config add_pooling_layer = True )
参数
config(BrosConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
裸 Bros 模型变换器输出原始隐藏状态,没有特定的头部。这个模型也是一个 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有信息。
forward
( input_ids: Optional = None bbox: Optional = None attention_mask: Optional = None token_type_ids: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None encoder_hidden_states: Optional = None encoder_attention_mask: Optional = None past_key_values: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions or tuple(torch.FloatTensor)
参数
-
input_ids(torch.LongTensor,形状为(batch_size, sequence_length)) — 输入序列标记在词汇表中的索引。可以使用 BrosProcessor 获取索引。查看 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.
call()获取详细信息。什么是输入 ID?
-
bbox(形状为(batch_size, num_boxes, 4)的‘torch.FloatTensor’) — 输入序列中每个标记的边界框坐标。每个边界框是四个值的列表(x1, y1, x2, y2),其中(x1, y1)是左上角,(x2, y2)是右下角的边界框。 -
attention_mask(形状为(batch_size, sequence_length)的torch.FloatTensor,可选)- 用于避免在填充令牌索引上执行注意力的掩码。选择的掩码值为[0, 1]:-
1 表示未被“掩盖”的令牌,
-
对于被“掩盖”的令牌为 0。
什么是注意力掩码?
-
-
bbox_first_token_mask(形状为(batch_size, sequence_length)的torch.FloatTensor,可选)- 用于指示每个边界框的第一个令牌的掩码。选择的掩码值为[0, 1]:-
1 表示未被“掩盖”的令牌,
-
0 表示被“掩盖”的令牌。
-
-
token_type_ids(形状为(batch_size, sequence_length)的torch.LongTensor,可选)- 段令牌索引,指示输入的第一部分和第二部分。索引选择在[0, 1]中:-
0 对应于句子 A令牌,
-
1 对应于句子 B令牌。
什么是令牌类型 ID?
-
-
position_ids(形状为(batch_size, sequence_length)的torch.LongTensor,可选)- 每个输入序列令牌在位置嵌入中的位置索引。在范围[0, config.max_position_embeddings - 1]中选择。什么是位置 ID?
-
head_mask(形状为(num_heads,)或(num_layers, num_heads)的torch.FloatTensor,可选)- 用于使自注意力模块的选定头部失效的掩码。选择的掩码值为[0, 1]:-
1 表示头部未被“掩盖”。
-
0 表示头部被“掩盖”。
-
-
inputs_embeds(形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor,可选)- 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,这是很有用的,而不是使用模型的内部嵌入查找矩阵。 -
output_attentions(bool,可选)- 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 -
output_hidden_states(bool,可选)- 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 -
return_dict(bool,可选)- 是否返回一个 ModelOutput 而不是一个普通元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions 或一个torch.FloatTensor元组(如果传递了return_dict=False或当config.return_dict=False时)包括根据配置(BrosConfig)和输入的不同元素。
-
last_hidden_state(形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor)- 模型最后一层的隐藏状态序列的输出。 -
pooler_output(形状为(batch_size, hidden_size)的torch.FloatTensor)- 经过用于辅助预训练任务的层进一步处理后,序列的第一个令牌(分类令牌)的最后一层隐藏状态。例如,对于 BERT 系列模型,这将返回通过线性层和 tanh 激活函数处理后的分类令牌。线性层的权重是在预训练期间从下一个句子预测(分类)目标中训练的。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每个层的输出)。每层模型的隐藏状态以及可选的初始嵌入输出。
-
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
-
cross_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True和config.add_cross_attention=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。解码器的交叉注意力层的注意力权重,在注意力 softmax 之后,用于计算交叉注意力头中的加权平均值。
-
past_key_values(tuple(tuple(torch.FloatTensor)),可选,当传递use_cache=True或config.use_cache=True时返回) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组有 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量,如果config.is_encoder_decoder=True,还有 2 个额外的形状为(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)的张量。包含预先计算的隐藏状态(自注意力块中的键和值,以及在交叉注意力块中,如果
config.is_encoder_decoder=True,还可以使用)可用(见past_key_values输入)以加速顺序解码。
BrosModel 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
示例:
>>> import torch
>>> from transformers import BrosProcessor, BrosModel
>>> processor = BrosProcessor.from_pretrained("jinho8345/bros-base-uncased")
>>> model = BrosModel.from_pretrained("jinho8345/bros-base-uncased")
>>> encoding = processor("Hello, my dog is cute", add_special_tokens=False, return_tensors="pt")
>>> bbox = torch.tensor([[[0, 0, 1, 1]]]).repeat(1, encoding["input_ids"].shape[-1], 1)
>>> encoding["bbox"] = bbox
>>> outputs = model(**encoding)
>>> last_hidden_states = outputs.last_hidden_state
BrosForTokenClassification
class transformers.BrosForTokenClassification
( config )
参数
config(BrosConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
在顶部带有标记分类头的 Bros 模型(隐藏状态输出的线性层),例如用于命名实体识别(NER)任务。
该模型也是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有信息。
forward
( input_ids: Optional = None bbox: Optional = None attention_mask: Optional = None bbox_first_token_mask: Optional = None token_type_ids: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)
参数
-
input_ids(形状为(batch_size, sequence_length)的torch.LongTensor) — 词汇表中输入序列标记的索引。可以使用 BrosProcessor 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.
call()。什么是输入 ID?
-
bbox(‘torch.FloatTensor’ of shape ‘(batch_size, num_boxes, 4)’) — 输入序列中每个标记的边界框坐标。每个边界框都是四个值的列表(x1, y1, x2, y2),其中 (x1, y1) 是左上角,(x2, y2) 是右下角的边界框。 -
attention_mask(torch.FloatTensorof shape(batch_size, sequence_length), optional) — 用于避免在填充标记索引上执行注意力的掩码。掩码值在[0, 1]中选择:-
1 表示未被
masked的标记, -
0 表示被
masked的标记。
什么是注意力掩码?
-
-
bbox_first_token_mask(torch.FloatTensorof shape(batch_size, sequence_length), optional) — 用于指示每个边界框的第一个标记的掩码。掩码值在[0, 1]中选择:-
1 表示未被
masked的标记, -
0 表示被
masked的标记。
-
-
token_type_ids(torch.LongTensorof shape(batch_size, sequence_length), optional) — 段标记索引,用于指示输入的第一部分和第二部分。索引在[0, 1]中选择:-
0 对应于 句子 A 标记,
-
1 对应于 句子 B 标记。
什么是标记类型 ID?
-
-
position_ids(torch.LongTensorof shape(batch_size, sequence_length), optional) — 每个输入序列标记的位置嵌入的位置索引。在范围[0, config.max_position_embeddings - 1]中选择。什么是位置 ID?
-
head_mask(torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — 用于使自注意力模块的选定头部失效的掩码。掩码值在[0, 1]中选择:-
1 表示头部未被
masked, -
0 表示头部被
masked。
-
-
inputs_embeds(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以直接传递嵌入表示而不是传递input_ids。如果您想要更多控制权来将input_ids索引转换为相关向量,这将非常有用,而不是使用模型的内部嵌入查找矩阵。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.modeling_outputs.TokenClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.TokenClassifierOutput 或一个 torch.FloatTensor 元组(如果传递了 return_dict=False 或当 config.return_dict=False 时)包含根据配置(BrosConfig)和输入的各种元素。
-
loss(torch.FloatTensorof shape(1,), optional, 当提供labels时返回) — 分类损失。 -
logits(torch.FloatTensorof shape(batch_size, sequence_length, config.num_labels)) — 分类分数(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)- 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层的输出,则为一个,+ 每一层的输出一个)。模型在每一层输出的隐藏状态以及可选的初始嵌入输出。
-
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)- 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
BrosForTokenClassification 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> import torch
>>> from transformers import BrosProcessor, BrosForTokenClassification
>>> processor = BrosProcessor.from_pretrained("jinho8345/bros-base-uncased")
>>> model = BrosForTokenClassification.from_pretrained("jinho8345/bros-base-uncased")
>>> encoding = processor("Hello, my dog is cute", add_special_tokens=False, return_tensors="pt")
>>> bbox = torch.tensor([[[0, 0, 1, 1]]]).repeat(1, encoding["input_ids"].shape[-1], 1)
>>> encoding["bbox"] = bbox
>>> outputs = model(**encoding)
BrosSpadeEEForTokenClassification
class transformers.BrosSpadeEEForTokenClassification
( config )
参数
config(BrosConfig)- 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
Bros 模型在顶部带有一个标记分类头(在隐藏状态输出的顶部有初始标记层和后续标记层),例如用于命名实体识别(NER)任务。初始标记分类器用于预测每个实体的第一个标记,后续标记分类器用于预测实体内的后续标记。与 BrosForTokenClassification 相比,该模型对序列化错误更加稳健,因为它从一个标记预测下一个标记。
该模型也是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( input_ids: Optional = None bbox: Optional = None attention_mask: Optional = None bbox_first_token_mask: Optional = None token_type_ids: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None initial_token_labels: Optional = None subsequent_token_labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.bros.modeling_bros.BrosSpadeOutput or tuple(torch.FloatTensor)
参数
-
input_ids(形状为(batch_size, sequence_length)的torch.LongTensor)- 词汇表中输入序列标记的索引。可以使用 BrosProcessor 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.
call()。什么是输入 ID?
-
bbox(形状为(batch_size, num_boxes, 4)的torch.FloatTensor)- 输入序列中每个标记的边界框坐标。每个边界框是四个值的列表(x1,y1,x2,y2),其中(x1,y1)是左上角,(x2,y2)是边界框的右下角。 -
attention_mask(形状为(batch_size, sequence_length)的torch.FloatTensor,可选)- 用于避免在填充标记索引上执行注意力的掩码。掩码值选在[0, 1]之间:-
对于
未屏蔽的标记为 1, -
对于
已屏蔽的标记为 0。
什么是注意力掩码?
-
-
bbox_first_token_mask(torch.FloatTensor,形状为(batch_size, sequence_length),optional) — 用于指示每个边界框的第一个标记的掩码。掩码值选在[0, 1]:-
1 表示未被
masked的标记, -
0 表示被
masked的标记。
-
-
token_type_ids(torch.LongTensor,形状为(batch_size, sequence_length),optional) — 段标记索引,用于指示输入的第一部分和第二部分。索引选在[0, 1]:-
0 对应于 句子 A 标记,
-
1 对应于 句子 B 标记。
什么是标记类型 ID?
-
-
position_ids(torch.LongTensor,形状为(batch_size, sequence_length),optional) — 每个输入序列标记在位置嵌入中的位置索引。选在范围[0, config.max_position_embeddings - 1]。什么是位置 ID?
-
head_mask(torch.FloatTensor,形状为(num_heads,)或(num_layers, num_heads),optional) — 用于使自注意力模块的选定头部失效的掩码。掩码值选在[0, 1]:-
1 表示头部未被
masked, -
0 表示头部被
masked。
-
-
inputs_embeds(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size),optional) — 可选地,可以直接传递嵌入表示而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,而不是使用模型的内部嵌入查找矩阵,则这很有用。 -
output_attentions(bool,optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量中的attentions。 -
output_hidden_states(bool,optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量中的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.models.bros.modeling_bros.BrosSpadeOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.bros.modeling_bros.BrosSpadeOutput 或一个 torch.FloatTensor 元组(如果传递 return_dict=False 或 config.return_dict=False 时)包含根据配置(BrosConfig)和输入不同元素。
-
loss(torch.FloatTensor,形状为(1,),optional,当提供labels时返回) — 分类损失。 -
initial_token_logits(torch.FloatTensor,形状为(batch_size, sequence_length, config.num_labels)) — 实体初始标记的分类分数(SoftMax 之前)。 -
subsequent_token_logits(torch.FloatTensor,形状为(batch_size, sequence_length, sequence_length+1)) — 实体序列标记的分类分数(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor),optional,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入的输出,如果模型有一个嵌入层,+ 一个用于每个层的输出)。每层模型的隐藏状态加上可选的初始嵌入输出。
-
attentions(tuple(torch.FloatTensor),optional,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
BrosSpadeEEForTokenClassification 的前向方法,覆盖了 __call__ 特殊方法。
虽然前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
示例:
>>> import torch
>>> from transformers import BrosProcessor, BrosSpadeEEForTokenClassification
>>> processor = BrosProcessor.from_pretrained("jinho8345/bros-base-uncased")
>>> model = BrosSpadeEEForTokenClassification.from_pretrained("jinho8345/bros-base-uncased")
>>> encoding = processor("Hello, my dog is cute", add_special_tokens=False, return_tensors="pt")
>>> bbox = torch.tensor([[[0, 0, 1, 1]]]).repeat(1, encoding["input_ids"].shape[-1], 1)
>>> encoding["bbox"] = bbox
>>> outputs = model(**encoding)
BrosSpadeELForTokenClassification
class transformers.BrosSpadeELForTokenClassification
( config )
参数
config(BrosConfig)- 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
在隐藏状态输出的顶部有一个标记分类头的 Bros 模型(在隐藏状态输出的顶部有一个实体链接层),例如用于实体链接。实体链接器用于预测实体之间的内部实体链接(一个实体到另一个实体)。
这个模型也是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有事项。
forward
( input_ids: Optional = None bbox: Optional = None attention_mask: Optional = None bbox_first_token_mask: Optional = None token_type_ids: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)
参数
-
input_ids(形状为(batch_size, sequence_length)的torch.LongTensor)- 词汇表中输入序列标记的索引。可以使用 BrosProcessor 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.
call()。输入 ID 是什么?
-
bbox(形状为(batch_size, num_boxes, 4)的‘torch.FloatTensor’)- 输入序列中每个标记的边界框坐标。每个边界框是一个包含四个值(x1,y1,x2,y2)的列表,其中(x1,y1)是左上角,(x2,y2)是边界框的右下角。 -
attention_mask(形状为(batch_size, sequence_length)的torch.FloatTensor,可选)- 用于避免在填充标记索引上执行注意力的掩码。掩码值选择在[0, 1]中:-
对于未被屏蔽的标记为 1,
-
对于被屏蔽的标记为 0。
注意掩码是什么?
-
-
bbox_first_token_mask(形状为(batch_size, sequence_length)的torch.FloatTensor,可选)- 用于指示每个边界框的第一个标记的掩码。掩码值选择在[0, 1]中:-
对于未被屏蔽的标记为 1,
-
对于被屏蔽的标记为 0。
-
-
token_type_ids(形状为(batch_size, sequence_length)的torch.LongTensor,可选)- 段标记索引,指示输入的第一部分和第二部分。索引选择在[0, 1]中:-
0 对应于句子 A标记,
-
1 对应于句子 B标记。
令牌类型 ID 是什么?
-
-
position_ids(形状为(batch_size, sequence_length)的torch.LongTensor,可选)- 位置嵌入中每个输入序列标记的位置索引。在范围[0, config.max_position_embeddings - 1]中选择。位置 ID 是什么?
-
head_mask(形状为(num_heads,)或(num_layers, num_heads)的torch.FloatTensor,可选)- 用于使自注意力模块的选定头部失效的掩码。掩码值选择在[0, 1]中:-
1 表示头部未被屏蔽。
-
0 表示头部被屏蔽。
-
-
inputs_embeds(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size),optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,而不是模型的内部嵌入查找矩阵,则这很有用。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.modeling_outputs.TokenClassifierOutput 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.TokenClassifierOutput 或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False)包含根据配置(BrosConfig)和输入不同元素。
-
loss(torch.FloatTensor,形状为(1,),optional,当提供labels时返回) — 分类损失。 -
logits(torch.FloatTensor,形状为(batch_size, sequence_length, config.num_labels)) — 分类得分(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor),optional,当传递output_hidden_states=True或config.output_hidden_states=True时返回) —torch.FloatTensor元组(如果模型有嵌入层,则为嵌入的输出+每层的输出)的形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出的隐藏状态以及可选的初始嵌入输出。
-
attentions(tuple(torch.FloatTensor),optional,当传递output_attentions=True或config.output_attentions=True时返回) —torch.FloatTensor元组(每层一个)的形状为(batch_size, num_heads, sequence_length, sequence_length)。在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
BrosSpadeELForTokenClassification 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的方法需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import torch
>>> from transformers import BrosProcessor, BrosSpadeELForTokenClassification
>>> processor = BrosProcessor.from_pretrained("jinho8345/bros-base-uncased")
>>> model = BrosSpadeELForTokenClassification.from_pretrained("jinho8345/bros-base-uncased")
>>> encoding = processor("Hello, my dog is cute", add_special_tokens=False, return_tensors="pt")
>>> bbox = torch.tensor([[[0, 0, 1, 1]]]).repeat(1, encoding["input_ids"].shape[-1], 1)
>>> encoding["bbox"] = bbox
>>> outputs = model(**encoding)
-
head_mask(形状为(num_heads,)或(num_layers, num_heads)的torch.FloatTensor,可选)- 用于使自注意力模块的选定头部失效的掩码。掩码值选择在[0, 1]中:-
1 表示头部未被屏蔽。
-
0 表示头部被屏蔽。
-
-
inputs_embeds(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size),optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,而不是模型的内部嵌入查找矩阵,则这很有用。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.modeling_outputs.TokenClassifierOutput 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.TokenClassifierOutput 或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False)包含根据配置(BrosConfig)和输入不同元素。
-
loss(torch.FloatTensor,形状为(1,),optional,当提供labels时返回) — 分类损失。 -
logits(torch.FloatTensor,形状为(batch_size, sequence_length, config.num_labels)) — 分类得分(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor),optional,当传递output_hidden_states=True或config.output_hidden_states=True时返回) —torch.FloatTensor元组(如果模型有嵌入层,则为嵌入的输出+每层的输出)的形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出的隐藏状态以及可选的初始嵌入输出。
-
attentions(tuple(torch.FloatTensor),optional,当传递output_attentions=True或config.output_attentions=True时返回) —torch.FloatTensor元组(每层一个)的形状为(batch_size, num_heads, sequence_length, sequence_length)。在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
BrosSpadeELForTokenClassification 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的方法需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import torch
>>> from transformers import BrosProcessor, BrosSpadeELForTokenClassification
>>> processor = BrosProcessor.from_pretrained("jinho8345/bros-base-uncased")
>>> model = BrosSpadeELForTokenClassification.from_pretrained("jinho8345/bros-base-uncased")
>>> encoding = processor("Hello, my dog is cute", add_special_tokens=False, return_tensors="pt")
>>> bbox = torch.tensor([[[0, 0, 1, 1]]]).repeat(1, encoding["input_ids"].shape[-1], 1)
>>> encoding["bbox"] = bbox
>>> outputs = model(**encoding)

















 1077
1077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









