







推荐环境中的语义相似度
如何利用语义提高传统最大似然推荐算法的性能
相似性、距离和相关性是数据科学中的核心概念。它们对事物有多“近”或“远”这一基本问题给出了一个数字尺度。有许多不同的方法来计算相似性,如余弦相似性、皮尔逊相关系数等等。在本文中,我将讨论语义相似度及其在推荐算法中的应用。
经典的协作过滤(CF)推荐器是基于行为数据的。我们收集用户评级或使用行为,并创建一个“评级矩阵”,从中我们可以识别统计模式并计算行为相似性。基于这种相似性,推荐器预测用户行为->这就是推荐。
行为的相似性会产生令人惊讶而又令人耳目一新的推荐。零售商发现的一个真实行为模式的例子表明,购买尿布的人通常也会购买啤酒。现在我们需要问:我们是否要向一位刚刚订购了尿布的顾客推荐一种啤酒?它是否符合企业的最大利益?它“有意义”吗?
用行为相似性来补充语义相似性可以确保 CF 推荐器将产生与企业的最佳利益和策略一致的推荐。在某种程度上,我们可以将其视为基于特征的相似性的集合,它由基于内容的过滤推荐和我们在项目-项目协同过滤算法中计算的行为相似性使用,但具有更高的准确性。在基于内容的过滤中计算的相似度是基于一个扁平的长特征列表,而语义相似度是基于一个更加丰富的分层数据模型(即图形和本体),因此我们可以计算出一个更加复杂和精确的相似度,更好地与业务策略和兴趣保持一致。
在这篇文章中,我将展示如何在推荐的上下文中使用语义相似性,通过增加语义的行为相似性,使推荐更好地符合业务和客户的最佳利益。
什么是语义相似度
语义相似性解释起来很简单,但计算起来要困难得多。直觉上,人们用符号和概念来思考,所以当你问某人两个现实生活中的物体如何比较时,你得到的答案是概念上的语义相似。
语义相似有语境。当你问两个物体是否相似时,你必须定义你想看的物体的方面。例如,两种产品可能价格相似,但功能集却大不相同。邻居在他们家的地理上是相似的,但是在他们的文化背景方面可能是非常不同的。记住上下文,我们可以讨论“有效相似性”,它定义了对于特定问题的相似性度量最有效的上下文。为特定领域定义数据模型的本体是一个很好的工具,可以根据特定的上下文来查看对象。从包含我们感兴趣的两个对象并且基于领域本体设计的知识图中,我们可以计算特定用例的两个概念之间的有效距离/相似性。
如何计算语义相似度
在语义相似性领域有许多研究,且有许多不同方法来计算它。论文“提高知识图质量的语义相似性度量框架”总结了最流行的方法。为了在准确性和召回率方面获得最佳性能,最好结合多种资源特征,例如共享信息的层次结构、邻居、数据属性和特殊性。
GADES ,A neiGhborhood-bAseDgraphEentitySimilarity,是一种语义相似度计算方法,综合了知识图中实体的几种资源特征。

语义相似度是多种因素的综合。来自 GADES 的论文(见参考文献)
等级相似性
用于计算语义相似性的第一个也是最流行的资源特征是分级相似性,其测量对象在本体分级树中有多远以及它们的最低共同祖先(LCA)有多深。直觉是,相似的实体有一个深刻而密切的最低共同祖先。计算等级距离有两种常用方法。两者都使用 LCA 和距离“d ”,距离“d”是仅考虑 rdfs:subClassOf 和 rdf:type 关系(即边)的两个节点之间的跳数。
Dtax

二苯砜

使用一个或另一个没有明显的优势,两者在语义相似性框架中同样受欢迎。
相似度只是距离的倒数,或者换句话说:

邻域相似性
告诉我你的邻居,我会告诉你你是谁。邻域相似性基于定义其邻域的关系来测量两个实体之间的相似性。
邻域是关系实体对 N(e)的集合,其实体在源实体(e)的一跳距离处。

对于每个邻居,我们需要使用知识图(即本体)的关系和类层次中编码的知识来考虑邻居实体(e)和边的关系类型®
让我们称之为“邻居对”。p =(r;e)。由于实体的邻域是邻域对的集合,为了计算实体 e1 和 e2 的邻域的相似性,我们首先需要知道如何比较两个个体对的相似性:P1 =(R1;e1)和 p2 =(R2;e2)。

既然我们知道如何计算邻域对的相似性,我们就可以计算两个实体的整个邻域之间的相似性。
为了聚集两个邻域之间的相似性,GADES 使用度量来组合配对比较。

编写相同计算的另一种方法是:

共享信息的特殊性
这里的直觉是,两个实体共享的特定信息越多,我们就会认为它们越相似。同样,一个概念出现的次数越少,它就被认为越具体。如果两个实体在语料库中被类似地使用,则它们被认为共享大量信息。将知识图视为语料库,由两个实体 x 和 y 共享的信息与在它们的邻域中 x 和 y 在一起的实体的数量成正比,即,x 和 y 在实体的邻域中的同现。
让我们把它放入一个公式:
首先让我们定义:事件(e)为在其邻域中有 e 的实体的集合。

有了它,我们可以计算相似性:

该公式的分母有助于降低关于抽象或非信息实体的相似性,这些实体在语料库中是常见的,因此不被认为是特定的。
属性相似度
知识图中的实体不仅与其他实体相关,还通过数据类型属性与属性相关,例如温度、日期等。这些属性可以告诉我们很多关于给定上下文中实体的相似性。例如,查看出生日期属性可以在长期投资建议的上下文中驱动相似性计算。
GADES 只考虑共享属性,即通过相同的 datatype 属性连接到实体的属性(例如,DateOfBirth 是 rdfs:subClassOf 和 rdf:type human ) 实体的所有实例的共享属性)。
考虑到属性可以与领域相似性度量进行比较(例如,向量的余弦、曼哈顿、欧几里德距离),GADES 没有描述用于比较各种属性的特定度量。根据领域的不同,专家将为每种类型的属性选择一个相似性度量。
总体相似性
上面描述的每个相似性就其本身而言都是有价值的,但是 GADES 的力量来自于将所有的相似性组合成一个单一的度量α。
GADES 使用聚合函数的组合来组合个体相似性度量以产生相似性值。不同聚集函数β和γ的详细定义以及组合它们的三角范数 T 是特定于域的。

摘自论文:语义相似性度量框架
提高知识图质量
例如,在长期投资推荐用例的上下文中,领域专家可能决定放大属性相似性,因为客户的年龄是要考虑的首要因素,所以 T 的系数表达了这一点。
GADES 实施
GADES 是一篇学术论文,不幸的是没有商业实现。下面的存储库包含一个 java 实现。
推荐的相似性
协同过滤(CF)推荐算法使用某种相似性函数来预测用户行为,即推荐。这可以是用户行为之间的相似性,或者是项目之间的相似性,因为它们以相似的模式被喜欢或不喜欢。因为相似性是根据评级矩阵计算的,所以它是设计行为,并不反映所涉及项目的语义。有时,这正是业务对算法的期望,但在其他情况下,忽略语义会产生没有意义或没有反映业务最佳利益的结果。用语义相似性补充行为相似性并将其插入推荐引擎可以提高其性能,因为它将为企业和客户产生更有效的结果。
项目-项目协同过滤
Item-Item CF 查找与用户已经评分的项目相似的项目,并推荐最相似的项目。项目-项目 CR 相似性是行为性的,即人们如何根据喜欢和不喜欢来对待两个相同的项目。通过对目标用户在这些相似项目上的评级(V)进行加权平均来计算预测(即,推荐)。换句话说,为了计算用户 u 对项目 I 的预测,我们计算用户对类似于 I 的项目给出的评级的总和。每个评级由项目 I 和 j 之间的相应相似性 si,j 加权。

项目-项目协同过滤
为了学习更多关于算法的知识,我推荐阅读原始的论文,它清晰易懂。
该算法的一个好处是相似度计算是可插拔的。最初的论文建议使用皮尔逊-r 相关或余弦相似度,但它对任何其他有意义的相似度计算都是开放的。我们建议使用从评级矩阵中提取的行为相似性与使用 GADES 从知识图中提取的语义相似性的组合。
用户-用户
用户-用户协同过滤可能是最流行的 CF 推荐算法,可能是因为它很容易理解。
从评分矩阵中,我们找到在喜好和厌恶方面与目标用户行为相似的用户,然后我们对他们的评分进行加权平均,对他们进行排序,并使用最佳列表作为推荐。
这里关于语义的问题是,相似性是用户行为之间的,而不是属于目标领域的概念之间的,所以开箱即用,我们不能将语义相似性插入到算法中。为了解决这个问题,我们必须将评级矩阵映射到属于目标领域但仍然保留用户行为的东西。论文基于语义的协同过滤增强推荐提出了一种方法。从评分矩阵中,我们创建了一个基于语义相似度和传播激活算法的兴趣矩阵(IS)。
IS(C j,u)和 IS(C j,v)分别是用户 u 和 v 的简档中与概念 j 相关联的兴趣得分。现在,我们可以计算相似性(或距离)并将其插入用户-用户算法。

学术研究成果
我想强调几篇相关学术论文中的两个结果。
- 在精确度、召回率和 F1 指标方面,使用行为和语义相似性的组合,CF 算法的性能得到显著提高。

摘自论文:语义相似度度量框架增强知识
图质量
- GADES 在准确性方面表现出最佳的性能结果。

来自 GADES 的论文(见参考文献)
下表显示了在 CESSM 2008 和 2014 上采用黄金标准 ECC、Pfam 和 SeqSim 的最新相似性度量和 GADES 之间的皮尔逊系数。
我们观察到,在 2008 年和 2014 年两个版本的知识图中,GADES 是与三个金标准度量最相关的度量。
我们的实验
第一步是实现项目-项目 CF 算法的 python jupyter 记事本。我们用于健全性测试的数据集是来自 iMDB 数据库的电影用户评级的集合。我们基于流派、演员和导演实现了一个简单的语义相似度,并将其与上述权重为 20%的行为相似度相结合。
我们看到性能平均值精度提高了 0.935897,召回率提高了 0.941935,但最重要的是,我们看到推荐的结果共享了一个类别。在现实生活中,这可能不是企业想要的电影推荐引擎,但对于其他用例,如产品推荐,这样的行为是可取的。
结论
语义相似度可以使用 GADES 等方法从知识图中有效地计算出来。一旦计算出来,它就可以用于许多数据科学任务。在本文中,我们展示了如何在推荐的上下文中使用语义相似性,通过增加语义的行为相似性,使推荐更好地符合业务和客户的最佳利益。
参考
未标记数据的半监督分类(PU 学习)

布鲁诺·马丁斯在 Unsplash 上的照片
当你只有几个正样本时,如何对未标记数据进行分类
假设您有一个支付交易的数据集。一些交易被标记为欺诈,其余的被标记为真实,您需要设计一个模型来区分欺诈和真实的交易。假设您有足够的数据和良好的特征,这似乎是一个简单的分类任务。但是,假设只有 15%的数据被标记,并且被标记的样本仅属于一个类,因此您的训练集由 15%被标记为真实的样本组成,而其余的样本未被标记,并且可能是真实的或欺诈的。你将如何对它们进行分类?需求的这种扭曲是否只是将这项任务变成了一个无人监督的学习问题?嗯,不一定。
这个问题通常被称为 PU(阳性和未标记)分类问题,应该首先与两个类似的常见“标记问题”区分开来,这两个问题使许多分类任务变得复杂。第一个也是最常见的标签问题是小训练集的问题。虽然你有大量的数据,但实际上只有一小部分是有标签的。这个问题有很多种类,也有不少具体的训练方法。另一个常见的标记问题(经常与 PU 问题混淆)涉及我们的训练数据集被完全标记的情况,但是它只包含一个类。例如,假设我们只有一个非欺诈性交易的数据集,我们需要使用这个数据集来训练一个模型,以区分(类似的)非欺诈性交易和欺诈性交易。这也是一个常见的问题,通常被视为无监督的离群点检测问题,尽管在 ML 环境中也有相当多的工具广泛可用,专门用于处理这些场景(OneClassSVM 可能是最著名的)。
相比之下,PU 分类问题是一种涉及训练集的情况,其中只有部分数据被标记为正,而其余部分未被标记,可能是正的也可能是负的。例如,假设你的雇主是一家银行,它可以为你提供大量交易数据,但只能确认其中一部分是 100%真实的。我将在这里使用的例子涉及到一个关于假钞的类似场景。它包括 1200 张钞票的数据集,其中大部分没有标签,只有一部分被确认为真实的。虽然 PU 问题也很常见,但与前面提到的两个分类问题相比,它们通常很少被讨论,而且很少有实际操作的例子或库可以广泛使用。
这篇文章的目的是提出一种可能的方法来解决我最近在一个分类项目中使用的 PU 问题。它基于查尔斯·埃尔坎和基思·诺托写的论文“仅从正面和未标记的数据中学习分类器”(2008),以及由亚历山大·德鲁因写的一些代码。尽管在科学出版物中有更多的 PU 学习方法(我打算在以后的文章中讨论另一种相当流行的方法),Elkan 和 Noto 的(E & N)方法非常简单,可以很容易地用 Python 实现。
一点理论(请耐心听我说……)

E&N 本质上声称,给定一个数据集,其中我们有正的和未标记的数据,某个样本为正的概率[ P( y =1| x )]等于该样本被标记的概率[P( s =1| x )]除以在我们的数据集中正样本被标记的概率[P( s =1| y 【T19
如果这种说法是真的(我不打算证明或捍卫它——你可以阅读论文本身的证明,并用代码进行实验),那么它似乎相对容易实现。这是因为虽然我们没有足够的标记数据来训练分类器来告诉我们样本是阳性还是阴性,但在 PU 场景中,我们有足够的标记数据来告诉我们阳性样本是否可能被标记,并且根据 E & N,这足以估计它是阳性的可能性有多大。
更正式地说,给定一个只有一组标记为正的样本的未标记数据集,如果我们估计P(s= 1 |x)/P(s= 1 |y= 1),我们就可以估计出未标记样本 x 为正的概率。幸运的是,我们可以根据以下步骤使用几乎任何基于 sklearn 的分类器来估计这一点:

(1) 在使用无标签指示器作为目标的同时,在包含有标签和无标签数据的数据集上安装分类器 y 。以这种方式拟合分类器将训练它预测给定样本 x 被标记的概率— P( s =1| x )。
(2) 使用分类器预测数据集中已知阳性样本被标记的概率,从而预测结果将代表阳性样本被标记为—P(s= 1 |y= 1 |x)的概率**
计算这些预测概率的平均值,这就是我们的P(s= 1 |y= 1)。
已经估计了 P( s =1| y =1),为了根据 E & N 预测数据点 k 为正的概率,我们需要做的就是估计 P( s =1| k )或它被标记的概率,这正是我们训练的分类器(1)知道如何做的。
(3) 用我们在 (1) 上训练过的分类器来估计 k 被标注的概率或者P(s= 1 |k)。
(4) 一旦我们估算出了P(s= 1 |k),我们实际上就可以将 k 除以第P(s= 1 |y= 1)(已经在第(2)步估算过了)
现在让我们对此进行编码和测试
上述步骤 1-4 可以按如下方式实施:
****# prepare data**x_data = *the training set*
y_data = *target var (1 for the positives and not-1 for the rest)***# fit the classifier and estimate P(s=1|y=1)**classifier, ps1y1 =
fit_PU_estimator(x_data, y_data, 0.2, Estimator())**# estimate the prob that x_data is labeled P(s=1|X)**predicted_s = classifier.predict_proba(x_data)**# estimate the actual probabilities that X is positive
# by calculating P(s=1|X) / P(s=1|y=1)**predicted_y = estimated_s / ps1y1**
先说这里的主招: fit_PU_estimator() 方法。
fit_PU_estimator() 方法完成两个主要任务:它将您选择的分类器拟合到阳性和未标记训练集的样本上,然后估计阳性样本被标记的概率。相应地,它返回拟合的分类器(学会估计给定样本被标记的概率)和估计的概率P(s= 1 |y= 1)。之后我们要做的就是求 P( s =1| x )或者说 x 被标注的概率。因为这就是我们的分类器被训练要做的,我们只需要调用它的 predict_proba() 方法。最后,为了对样本 x 进行实际分类,我们只需要将结果除以我们已经找到的P(s= 1 |y= 1)。这可以用代码表示为:
fit_PU_estimator ()方法的实现本身是不言自明的:
为了测试这一点,我使用了钞票认证数据集,它基于从真钞和伪钞图像中提取的 4 个数据点。我首先在带标签的数据集上使用分类器,以便设置基线,然后移除 75%样本的标签,以便测试它在 P & U 数据集上的表现。正如输出所示,这个数据集确实不是最难分类的数据集之一,但是您可以看到,虽然 PU 分类器仅“知道”大约 153 个阳性样本,而所有其余的 1219 个样本都是未标记的,但是与具有所有可用标签的分类器相比,它表现得相当好。然而,它确实丢失了大约 17%的召回,因此丢失了相当多的真阳性。然而,当这是我们所拥有的一切时,我相信这些结果与其他选择相比是相当令人满意的。
****===>> load data set <<===**data size: (1372, 5)**Target variable (fraud or not)**:
0 762
1 610***===>> create baseline classification results <<===*****Classification results:**f1: 99.57%
roc: 99.57%
recall: 99.15%
precision: 100.00%***===>> classify on all the data set <<===*****Target variable (labeled or not)**:
-1 1219
1 153**Classification results**:f1: 90.24%
roc: 91.11%
recall: 82.62%
precision: 99.41%**
几个重要的笔记。首先,这种方法的性能很大程度上取决于数据集的大小。在这个例子中,我使用了大约 150 个阳性样本和大约 1200 个未标记的样本。这远远不是这种方法的理想数据集。例如,如果我们只有 100 个样本,我们的分类器就会表现很差。第二,如附件所示,有几个变量需要调整(例如要留出的样本大小、用于分类的概率阈值等),但最重要的可能是所选择的分类器及其参数。我选择使用 XGBoost,因为它在具有很少特性的小数据集上表现相对较好,但是需要注意的是,它不会在每个场景中都表现最佳,并且测试正确的分类器也很重要。
笔记本在这里有售。
尽情享受吧!
基于 GAN-BERT 的半监督意图分类
基于 GAN-BERT 的半监督学习方法在 CLINC150 数据集上的意图分类

甘伯特建筑。来源:" GAN-BERT:健壮文本分类的生成式对抗学习"
有没有可能对 150 个目标类别进行文本分类,每个类别只使用 10 个标记样本,但仍能获得良好的性能?
从那个简单的问题开始,我开始做研究,以便回答那个问题。花了几个小时后,我终于和甘伯特在一起了。甘伯特是什么?我用甘博特做了什么实验?在本文中,我将尝试简要介绍 GAN-BERT,并使用 CLINC150 数据集实现其意图分类。
在自然语言处理(NLP)领域, BERT 或来自 Transformers 的双向编码器表示是一种基于 Transformers 架构的众所周知的技术,用于执行广泛的任务,包括文本分类。然而,当有“足够”的标记训练数据要利用时,这种技术可以很好地执行,而获得标记数据是耗时且昂贵的过程。对此的潜在解决方案是使用半监督学习方法。
半监督学习是机器学习领域中的一种方法,它在训练过程中结合了标记数据和未标记数据。目标与监督学习方法相同,即在给定具有若干特征的数据的情况下预测目标变量。当我们没有这么多标记数据,而我们的模型需要大量训练数据才能表现良好时,这种方法是至关重要的。
最近在 2020 年 7 月,一篇名为“GAN-BERT:具有一堆标记示例的健壮文本分类的生成对抗学习”的论文,试图在生成对抗设置中扩展具有未标记数据的 BERT 类架构的微调。在高层,他们试图从 SS-GAN (半监督 GAN)的角度丰富 BERT 微调过程。
“在本文中,我们在生成性对抗设置中使用未标记数据来扩展 BERT 训练。特别是,我们在所谓的 GAN-BERT 模型中,从 SS-GAN 的角度丰富了 BERT 微调过程
甘伯特
这种体系结构结合了 BERT 和 SS-GAN 的能力来进行文本分类。生成器通过从高斯分布中提取 100 维噪声向量的输入来产生“假”示例。鉴别器是在 BERT 上的 MLP,它接收输入向量或者是由发生器产生的假向量或者是来自 BERT 产生的真实数据的向量。鉴别器的最后一层是 softmax 层,它输出 logits 的 k+1 维向量,其中 k 是数据集中类的数量。这里,真实数据被分成两部分,它们被标记为(L)和未标记的(U)数据。

甘伯特建筑。来源:" GAN-BERT:健壮文本分类的生成式对抗学习"
鉴别器旨在对输入是否为真实实例进行分类。如果它预测输入是真实的实例,那么它必须预测输入属于哪个类。
训练过程试图优化两个竞争损耗,它们是鉴别器损耗和发电机损耗。鉴别器损耗是另外两个损耗的总和:监督损耗和非监督损耗。监督损失测量将错误的类别分配给原始 k 个类别中的真实示例的误差,而非监督损失测量不正确地将真实(未标记的)示例识别为假的并且不识别假的示例的误差。发电机损耗也是另外两个损耗求和的结果:特征匹配和无监督损耗。特征匹配损失旨在确保生成器应该产生其在输入到鉴别器时提供的中间表示与真实表示非常相似的示例,而无监督损失测量由鉴别器正确识别的虚假示例引起的误差。

基思·约翰斯顿在 Unsplash 上拍摄的照片
在训练期间,每一类中的样本以 log (2|U|/|L|)的因子被复制,以保证在每一批中存在一些标记的实例,从而避免由于对抗训练的无监督成分而导致的发散。在推理过程中,生成器被从体系结构中丢弃,而保留其余部分。
这意味着相对于标准的 BERT 模型,在推断时没有额外的成本。
实验设置
在本实验中,使用了 CLINC150 数据集。该数据集由 10 个领域的 150 个意图类组成。提供的数据有 4 种变型:满、小、不平衡、 OOS+、这里用的是满变型*。*对于每个意图,有 100 个训练话语、20 个验证话语和 30 个测试话语。实际上,除了 150 个意向范围内类之外,该数据还提供了范围外类(OOS)。但是,在这个实验中,我只关注范围内的类预测。
由于实际的 CLINC150 数据集不是为半监督学习设置而构建的,因此在这里,我尝试用 6 种不同的训练数据进行实验。对于每个变体,训练数据被分成标记的和未标记的集合。第一个变体由 10%标记的和 90%未标记的数据集组成。因为训练数据中的话语总数是 100,所以对于第一种变型,有标记集合有 10 个话语,无标记集合有 90 个话语。

训练数据的变量。来源:作者的财产
我对所有训练数据变量使用完全相同的参数设置。唯一的区别是训练时期的数量。我使用 20、18、16、14、12、10 个历元数分别表示第一个到最后一个变量。
实验结果
CLINC150 论文上的结果表明,通过利用 BERT,他们在测试数据集上获得了 96.2%的准确率。这里使用相同的测试数据集是跨越 6 个训练数据变化的 GAN-BERT 的结果。

跨 6 个训练数据变量的测试数据集的准确性。来源:作者的财产
我们可以看到,在训练过程中,即使在每个意图中仅使用 10 个标记的话语,GAN-BERT 也能够给出合理的性能。甘伯特的性能随着标记话语数量的增加而增加。第四、第五和第六变型的性能彼此相似。这表明,即使仅使用 60%的标记训练数据,GAN-BERT 的性能也类似于使用 80%甚至 90%的标记训练数据训练的模型。
最后的话
GAN-BERT 在多文本分类任务的半监督学习中具有很大的潜力。仅给定有限的标记训练数据,它表现良好。然而,这只是在文本分类任务中处理有限标记训练数据的方法之一。还有另一种方法叫做少镜头文本分类。如果你有更多的兴趣,你可以阅读这篇论文,它也使用 CLINC150 作为他们的训练数据。
您可以在这里找到本文中使用的所有代码。
关于作者
Louis Owen 是一名数据科学爱好者,他总是渴望获得新知识。他获得了最后一年的全额奖学金,在印尼顶尖大学 的万隆技术学院 攻读数学专业。
Louis 曾在多个行业领域担任分析/机器学习实习生,包括 OTA ( Traveloka )、电子商务( Tokopedia )、fin tech(Do-it)、智慧城市 App ( Qlue 智慧城市 ),目前在世界银行担任数据科学顾问。
查看路易斯的网站,了解更多关于他的信息!最后,如果您有任何疑问或需要讨论的话题,请通过 LinkedIn 联系 Louis。
基于 K 均值聚类的半监督学习
机器学习
有限数据标签下 NBA 球员位置预测的半监督学习案例研究。

照片由бодьсанал·布吉在 Unsplash 拍摄
有监督学习和无监督学习是机器学习中的两大任务。当所有实例的输出可用时,使用监督学习模型,而当我们没有“真实标签”时,应用无监督学习。
尽管无监督学习的探索在未来的研究中具有巨大的潜力,但有监督学习仍然主导着该领域。然而,当我们的数据中没有足够的标记样本时,我们通常需要建立一个监督学习模型。
在这种情况下,可以考虑半监督学习。其思想是基于非监督学习过程的输出来构建监督学习模型。
我想举一个简单的例子。
问题:我们可以根据 NBA 球员的比赛数据来对他们的位置进行分类吗?
我收集了 2018-2019 赛季 NBA 球员的场均数据。球员的位置被定义为传统的篮球位置:控球后卫(PG)、得分后卫(SG)、小前锋(SF)、大前锋(PF)和中锋©。
在建模过程之前,我对数据集做了一些预处理。首先,去掉每场比赛上场时间不到 10 分钟的球员。然后,用 0 填充 NA 值(比如中锋球员从来不投三分球)。
df_used = df_num.loc[df.MP.astype('float32') >= 10]
df_used.fillna(0,inplace=True)
预处理后,数据如下所示:
df_used.head()

数据头
然后,我将数据分离到训练集和测试集。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df_used, labels_)
监督学习(给出所有玩家的位置)
如果所有标签(玩家位置)都给了,那就是一个简单的监督分类问题。我用一个简单的逻辑回归模型来拟合训练数据集。
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScalerpipeline = Pipeline([
("scaler", StandardScaler()),
("log_reg", LogisticRegression()),
])pipeline.fit(X_train, y_train)
我在测试数据集上评估了这个模型。
pipeline.score(X_test, y_test)
这个过程给出 0.644,这意味着 64.4%的预测是正确的。从这个结果中,我们知道分类器的改进空间非常大。然而,在本文中,我并不关注分类器的开发。
我将讨论数据标签仅部分可见的情况。
半监督学习(只给出 100 个玩家的位置)
如果只允许我看到训练数据中 100 个球员的位置信息,会对模型的性能产生怎样的变化?有许多策略可以用来选择 100 个玩家作为分类器的输入。
第一种策略是随机选择 100 个玩家,比如前 100 个玩家。我检查了只在这个子集上训练的逻辑回归模型的性能。
n_labeled = 100pipeline.fit(X_train[:n_labeled], y_train[:n_labeled])
pipeline.score(X_test, y_test)
这次我只得到 56.8%的准确率。这是意料之中的,因为我只看到了真实标签的一个子集。
然而,我们可以通过选择 100 个标签的不同子集来提高性能吗?答案是肯定的。
第二种策略是应用无监督学习过程来对整个训练数据集中的数据进行聚类,并暴露每个聚类的代表的标签。这样,我们可以假设在聚类空间中彼此接近的数据点应该有很高的机会拥有相同的标签。
换句话说,比赛数据相似的球员应该在场上打同样的位置。
from sklearn.cluster import KMeansk=100
kmeans = KMeans(n_clusters=k)
X_dist = kmeans.fit_transform(X_train)
representative_idx = np.argmin(X_dist, axis=0)
X_representative = X_train.values[representative_idx]
在代码中,X_dist 是到聚类质心的距离矩阵。representative_idx 是最接近每个聚类质心的数据点的索引。
在选择了特征空间中的代表之后,我们收集了这些数据点的真实标签。这里,我只需要从原始数据中提取标签。
y_representative = [list(y_train)[x] for x in representative_idx]
但是请注意,实际情况是我们不知道有什么真正的标签,所以需要手动标注这些选中的数据点。
让我们来检查在这个训练数据子集上训练的模型的性能。
pipeline.fit(X_representative, y_representative)
pipeline.score(X_test, y_test)
我得到了 59.6%的准确率!尽管它不能与在整个训练集上训练的模型相比,但它比随机选择的 100 个数据点要好。
讨论
随着篮球的发展,根据球员的比赛数据来判断他们的位置变得越来越困难。这就是为什么我们只有 60%左右的准确率。
尽管在聚类质心上训练的模型的性能比在随机数据点上训练的模型的性能好,但是改进是有限的。这可以解释为,在目前的 NBA 中,同一位置的球员的比赛数据可能会有很大的差异。
参考资料:
希望这篇短文对你有用!干杯!
数据科学的开创性论文:大型共享数据库的关系模型
50 年后,回顾了 e . f . Codd 1970 年论文中的一些主要概念,这些概念为关系数据库和 SQL 奠定了基础

弗兰基·查马基在 Unsplash 上拍摄的照片
即使 NoSQL越来越受欢迎,大多数公司仍然在使用某种形式的基于 SQL 的关系数据库管理系统。虽然 SQL(当时叫做 SEQUEL)是由 IBM 的 Donald D. Chamberlain 和 Raymond F. Boyce 在 1974 年首次引入的,但是他们的工作是建立在 Edgar F. Codd 的思想之上的。Codd 是另一位 IBM 计算机科学家,他在 1970 年提出了数据库管理的关系模型。在这篇文章中,我讨论了 Codd 有影响力的论文中的一些主要观点,以及他的观点如何与我们现代使用 SQL 相关联。
关系
Codd 使用术语关系来描述他的模型的基石。该关系正式描述如下:
给定集合 S1,S2,…,Sn(不一定不同),R 是这 n 个集合上的一个关系,如果它是一个 n 元组的集合,每个元组的第一个元素来自 S1,第二个元素来自 S2,等等。我们将 Sj 称为 R 的第 j 个域。如上所述,R 的阶数为 n。阶数为 1 的关系通常称为一元关系、阶数为 2 的关系、阶数为 3 的关系和阶数为 n 的关系。
-Codd (1970 年)
这个定义可能看起来完全陌生,但是如果您熟悉 SQL,那么 Codd 实际上是指一些非常熟悉的东西。Codd 建议可以基于以下条件将关系表示为数组:
代表 n 元关系 R 的数组具有以下属性:
(1)每行代表 r 的一个 n 元组。
(2)行的顺序并不重要。
(3)所有行都是不同的。
(4)列的排序是重要的——它对应于定义 R 的定义域的 S1,S2,…,Sn 的排序(然而,参见下面关于定义域有序和定义域无序关系的注释)。
(5)通过用相应域的名称对其进行标记,来部分传达每个列的意义。"
-Codd (1970 年)
Codd 还展示了下面图 1 中关系的数组表示示例。

Codd (1970 年)
乍一看,Codd 的关系数组表示与现代 SQL 表有许多相似之处。例如,上面的 4 度关系(或者,与四个域的关系)看起来类似于我们在 SQL 中称之为具有四列的表。这个表将被命名为 supply ,Codd 的域将对应于 SQL 列。SQL 表也类似于 Codd 的关系,因为行的顺序并不重要,行是不同的,每一列都有标签。
然而,Codd 的关系和 SQL 表之间有一个显著的区别:Codd 规定列的排序是重要的,而在 SQL 中肯定不是这样。这与 Codd 的断言是一致的,即关系的每一行都是一个n-元组——在 SQL 中,由于表的列顺序通常是不相关的,所以 SQL 表的每一行不需要都是元组。
那么,为什么 Codd 会提出在关系中需要列排序呢?他用论文中的图 2 给出了一个例子(见下文)。

Codd (1970 年)
在图 2 中的组件关系中,Codd 呈现了两个域(列)同名的情况——part。为了跟踪这两个零件列,为这些列分配一个固定的顺序是有意义的。虽然 Codd 在 1970 年的论文中认为这是一个合理的问题,但现在情况不同了,因为现代 SQL 数据库不允许同一个表中的两列具有相同的名称。
规范化集合
Codd 将规范化称为从关系中消除非简单域。但是 Codd 所说的非简单域是什么意思呢?
“非原子值可以在关系框架内讨论。因此,一些域可能具有作为元素的关系。反过来,这些关系可以在非简单域上定义,等等。”
-Codd (1970 年)
在下面的图 3(a) 中,Codd 通过绘制一组非规范化关系的树形图示例进一步阐述。员工关系由简单域男号、姓名、生日和非简单域工作历史和子女组成。这些非简单域本身可以被认为是关系,包含它们自己的简单和非简单域。
Codd 注意到,这种非规范化的关系集不能用一个二维数组来表示。但归一化后,这组关系可以表示为四个二维数组(见图 3(b) )。

Codd (1970 年)
但是,究竟应该如何执行这种规范化呢?Codd 阐述了:
从树顶部的关系开始,取其主键,并通过插入该主键域或域组合来展开每个直接的从属关系。每个扩展关系的主键由扩展前的主键和从父关系复制下来的主键组成。现在,从父关系中删除所有非简单域,删除树的顶部节点,并对每个剩余的子树重复相同的操作序列。”
-Codd (1970 年)
因此,图 3(a) 中基于树的关系被转换为图 3(b) 中的规范化形式,去掉了非简单域,并且定义了一个主键来唯一标识每个关系中的行。主键可以是单个域(对于雇员关系为人员# ),也可以是多个域(对于工作历史关系为人员#、工作日期)。此外,每个关系可以使用 man# 域相互交叉引用。这几乎类似于现代 SQL 模式中的一个基本概念——一个表的主键可以作为另一个表的外键,因此,当表保持独立的二维数组时,可以保留表之间的关系。
连接
Codd 概述了许多可以在关系(表)上执行的操作,其中之一是连接。
“假设我们有两个二元关系,它们有一些共同的领域。在什么情况下,我们可以将这些关系组合起来,形成一个三元关系,保留给定关系中的所有信息?”
-Codd (1970 年)
Codd 提供了两个关系 R 和 S 如何使用各自的 part 域连接的示例:

Codd (1970 年)
由于每个关系的零件域具有不唯一的值,由于相同的零件值可能导致供应商和项目的多个组合,因此 R 和 S 的“自然连接”包含的行(5)比两个表(3)中的任何一个都多。
如果我们假设 r 和 s 是 SQL 数据库中的表,下面的 SELECT 语句将产生与 Codd 的“自然连接”相同的结果:
从 s.part = r.part 上的 r JOIN s 中选择供应商、r.part、项目;
SELECT * FROM r 自然联接 s;
在 SQL 中,自然联接默认执行与内部联接相同的任务,但是每个表中同名的列只会出现一次。
关闭
Codd 1970 年的论文中还有很多我没有讨论的概念,但在这篇文章中我将把它们留在这里。如果您有兴趣进一步了解关系数据库和 SQL 的基础是如何形成的,请查阅下面参考资料中的文章。
参考
[## 2019 年数据库趋势- SQL 与 NoSQL、顶级数据库、单数据库与多数据库使用
想知道哪些数据库是 2019 年的趋势?我们询问了数百名开发人员、工程师、软件架构师、开发人员…
scalegrid.io](https://scalegrid.io/blog/2019-database-trends-sql-vs-nosql-top-databases-single-vs-multiple-database-use/)
向 BigQuery 发送 Google Analytics 点击量数据
如何发送标准的谷歌分析点击量数据到 BigQuery?

由 Graphicssc ,来源 pixabay
标准的谷歌分析不提供其点击量数据,我们必须购买 GA 360 来获得它,这是非常昂贵的。
在本指南中,我将帮助您建立一个数据管道,允许您在 BigQuery 中存储 GA 的数据。这将是一个命中水平的数据,不仅可以让你生成谷歌分析提供的所有报告,还可以应用先进的机器学习技术,将你的业务提升到一个新的水平。
为什么发送命中水平数据?
以下是存储 GA 命中水平数据的许多使用案例中的一些:
- **无数据抽样。**存储点击量数据让我们在不进行任何采样的情况下创建报告。对于那些每天流量都很大的网站来说,这是一个巨大的进步。
- 构建任何报告。GA 报告有限。点击级别数据允许您使用任何配置构建包含任何分段的任何报告。
- **机器学习。**应用先进的机器学习技术,获得对你的业务有用的细分和预测。
- 数据仓库将 GA 数据与其他营销活动数据联系起来,以便更全面地了解您的营销工作
- 可视化。在你喜欢的任何地方可视化数据(不仅仅是在谷歌数据工作室)
还有很多!
数据管道

由 Muffaddal 创建的 GTM 到 BigQuery 数据管道
这难道不是一个简单的数据管道吗?确实是!
我们的 ELT 数据管道使用 Google Tag Manager 来获取发送到 GA 的 hit,使用 Cloud 函数来获取和处理从 Tag Manager 收到的 hit,使用 BigQuery 来存储数据。我们还将使用 Bigquery 的查询调度器进行原始数据转换。
我从 Simo Ahava 在 tag monitor guide 上的帖子中获得了这个想法,并将其用于将 GA 的数据发送给 BigQuery。所以,如果你对监控你的标签感兴趣的话,一定要去看看
注 : 我将使用 GTM 发送和谷歌云平台处理和存储点击数据,但这些工具不是强制性的。一旦您理解了数据如何在这些组件之间移动,任何技术栈都可以用来实现这个数据管道。而且如果你有兴趣探索 GCP 这边的东西我会推荐 谷歌的 GCP 课程 。
谷歌标签管理器
测量协议是一个向 Google Analytics 发送数据的 API。我们发送到 GA 的任何调用,无论是使用代码片段还是使用标记管理器,都将被发送到测量协议。我们的想法是捕获相同的击中,这将是测量协议,并将其发送到我们的数据仓库。
但是怎么做呢?嗯,Google analytics 对象提供了一个回调函数,当调用被发送到 GA 时触发该函数。使用该功能,我们可以访问正在发送的命中级别数据。该功能被称为[customTask](https://www.simoahava.com/analytics/customtask-the-guide/?utm_source=medium&utm_medium=referral&utm_campaign=muffaddal.qutbuddin&utm_content=send_ga_hit_data_to_bigquery)

显示数据如何在自定义任务和其他工具之间移动的数据流图,由 Muffaddal
让我们使用自定义函数类型的变量在 Google 标签管理器中创建一个自定义任务句柄函数

通过 Muffaddal 为 customTask 选择自定义 JavaScript
并按原样粘贴下面的代码。
通过 Muffaddal 向云函数发送 hit 的自定义任务代码
你只需要在一个名为“云函数 URL”的常量变量中提供到云函数的链接,GTM 就会开始向云函数发送 GA 的数据。

与云函数链接的 GTM 常量变量,由 Muffaddal
将自定义函数变量命名为“自定义任务”。接下来,转到您的设置变量,在“要设置的字段”中添加 customTask,并为其提供我们的变量。

通过 Muffaddal 在设置变量中添加 customTask 字段
将 customTask 直接添加到 GA 设置变量可以确保我们的函数在每次命中 GA 时触发。
谷歌云功能
接下来,我们必须设置我们的云函数来接收来自 GTM 的点击,并将其发送给 BigQuery。我将在本指南中使用 Node.js,但它也可以用任何其他语言实现,比如 Python。首先让我们配置我们的云功能

云功能配置,由 muffaddal
我已经将分配的内存设置为 512 MB。您可能希望根据您预期收到的点击量来更新此信息。但大多数情况下,512 MB 应该就可以了。
将下面的代码复制到package.json文件中,告诉我们的云函数使用的节点依赖关系。我们将在 Node.js 代码中使用 BigQuery 和云存储。
为什么选择云存储?稍后会详细介绍。
云函数的 Package.json,由 Muffaddal
接下来,在您的index.js文件中添加下面的 Node.js 8 代码,并根据您的 GCP 环境设置‘projectId’、‘dataset’、‘tableName’和‘bucket name’。
用于处理 GA 命中的云函数代码,由 Muffaddal 编写
在上面的代码中,我们还在原始的 hit 对象中包含了时间戳(第 38 行)。这是为了在我们的数据集中有一个日期参数。这将允许我们对数据执行基于日期的操作。
此外,如果我们在向 BigQuery 插入原始命中时遇到任何错误,我们会将该命中存储到云存储中。这样做确保我们至少不会错过击中。一旦进入云存储,就可以根据错误进行处理并转发给 BigQuery。

有无错误的数据流,由 Muffaddal
我根据错误类型在 bucket 中创建了一个子文件夹。这将有助于区分点击,并允许我们相应地处理它们。
我已经在文章的最后提到了错误的可能原因。
谷歌大查询
用类型字符串创建一个包含两列hit_timestamp和payload的表。确保该表的名称与您在云函数中添加的名称相同。
这是它的样子。

BigQuery 中的原始数据表,由 Muffaddal
有效负载栏中长而怪异的字符串正是 Google analytics 从网站接收点击的方式,也是我们存储它的方式。它将所有数据点格式化为查询参数。在本节的后面,我们将把它转换成可读的格式。时间戳是我们在云函数代码中添加的列。
一旦表被创建,我们的数据管道接收谷歌分析点击量数据准备好了!
接下来,我们将把这些原始数据转换成可读的格式。
转换原始数据
想法是从有效负载列中提取参数值,并将它们存储在转换后的表中。为此,我们将使用 SQL 查询。查询将做的是每天从原始数据中提取我们需要的值,并将其附加到转换后的表中。
下面是一个从原始点击中提取数据的查询
通过 Muffaddal 转换原始数据的查询
我将 hit_timestamp 转换为纽约时间,因为我的 Google Analytics 时间设置为纽约。我希望我的 BigQuery 数据能够与谷歌分析的数据相媲美,我建议你也这样做。这有助于匹配事物。
您可能还会问为什么查询只从以前的数据中提取日期?这是有原因的。我将在下一节讨论这一点。
运行上述查询将获得以下转换格式的数据

由 Muffaddal 转换的 GA 数据表
BigQuery 查询调度程序
接下来,我们希望我们的转换查询能够每天获取格式数据,这样我们就不必在处理数据集时自己转换它。查询调度器可以帮助我们做到这一点。它将在每天的 00:30 运行,并提取前一天收到的数据,对其进行转换,并将其添加到我们转换后的数据表中。

数据转换流程,由 Muffaddal
下面是要使用的计划程序设置。

Muffaddal 的 BigQuery 查询调度程序设置
为什么我把它安排在 00:30?
调度程序的工作是运行 SQL 查询。该查询从运行时开始获取前一天的所有内容。因此,日期一改变,我就运行调度程序,这样我们就能得到前一天收到的所有信息。这确保我们获得前一天的所有用户活动,并将其存储在转换后的表中。
调度器还被设置为将查询结果追加到目标表中。因此,每天结束时,我们都会在 BigQuery 中获得转换后的数据。
下面是基于上述 SQL 查询的转换表的模式。
转换的数据表架构,bu Muffaddal
搞定了。
好了,我们的数据管道已经完成,可以捕获 GA hit,并将其发送到云功能。后者将其转发给 BigQuery。在 BigQuery 查询调度器中处理原始数据,对其进行格式化,并将其存储在我们的表中,以便能够构建报告并对其进行分析。
我们为什么不直接在云函数中转换命中数据?
在 BigQuery 中存储 Google analytics 的原始点击比只存储转换后的点击数据有很多优势。其中一些是:
- 变换过程中的任何错误都可能导致整个命中的丢失。这本身就是巨大的损失。
- 谷歌分析跟踪的变化可能会改变整个转型过程。
- 转换后的表模式中的任何变化都会导致转换过程在存储新的命中之前发生变化。
在 BigQuery 中直接存储原始命中数据的优势:
- 可以直接查询原始数据。
- 在转换后的数据或表格中出现任何错误的情况下,回溯变得更加容易。
- 您可以随时从原始数据中直接过滤数据点,以便在转换后的版本中包括(或排除)数据点。
- 您可以用类似的方式从原始数据中提取任何新的维度或值。
- 转换后的表可以随时从原始数据重建。
需要注意的几个要点
实现以上内容将使您能够在 BigQuery 中处理 GA 数据。然而,我想指出的是,在实现数据管道时,应该考虑几件事情。
Google Analytics 自定义维度
并不是所有的东西都通过它的 API 发送到 GA。因此,我建议在你的谷歌分析中实现以下自定义维度,这将丰富你的点击量数据。
- 地理定位:获取用户在你的数据集中的位置
- 设备类型:每次点击获取设备信息。
- 用户代理:这个维度可以让你得到多个其他维度,比如浏览器及其版本。它还可以帮助您过滤垃圾邮件流量,因为垃圾邮件发送者没有用户代理。
- 会话 Id :这将有助于按会话分组和过滤你的数据集。发送显式会话 id 有助于简化会话级分析过程。
如果你需要我的帮助来建立这个端到端的数据管道,请在 LinkedIn 上告诉我。
请注意,在 GA 中设置 session-id 维度的传统方式不起作用。与传统方式一样,我们将随机 id 发送给 GA,GA 将收到的最后一个 id 作为会话 id 存储在自定义维度中。在我们的例子中,您必须为整个会话发送相同的 id 值,以便在 BigQuery 中,您可以在会话的每次点击中看到相同的 id。
人口统计信息
由于人口统计信息是从 GA 的后端添加到 GA 中的,所以我们将无法在我们的点击量数据中获得人口统计信息。尽管您可以使用来自 hit 数据集的客户端 id 或用户 id 从 GA 的 API 中提取此类数据。
SQL 查询中的查询参数
上面转换原始数据的 SQL 查询涵盖了 GA hit 拥有的许多参数,但不是全部,比如增强的电子商务的参数。您可能需要根据您的 google analytics 实现来更新查询。
错误
如上所述,如果我们的云函数遇到错误,我们的管道会将命中结果存储在云存储中。云函数中可能会出现错误,原因有很多,其中包括:
- 已达到 BigQuery 报价限制。
- 云函数收到了不必要的点击(例如,由于垃圾邮件),这可能会导致我们的代码中出现错误。
- 由于不需要的架构命中架构,BigQuery 拒绝插入。
- 可能还有其他不可预见的运行时错误
在任何情况下,这个想法是至少存储 GA 命中,以便我们不会错过它。
云存储中的数据需要根据其存储在云存储中的错误进行处理。
时区
您将不得不更新 SQL 查询,以匹配您的谷歌分析的时间,使数字具有可比性。
GCP 组件限制
云函数和 BigQuery 都有限制,根据你的流量,你可能需要增加两个组件的配额限制。
- 云函数可以每 100 秒处理 1 亿次调用。
- BigQuery 接受每个项目每秒 100,000 行。
您还可以在将数据发送到 BigQuery 之前,使用一个中间组件临时批处理数据。
实时数据管道
还可以进行管道转换,并在 Bigquery 中实时存储数据,而不是由调度程序引起的延迟。这个想法是,你从云函数接收到的有效载荷中提取参数,直接发送给 BQ。
如果你使用实时管道,我会建议你仍然存储原始的点击,因为它有助于在事情发生时进行回溯。
结束了
尽管标准的谷歌分析并不提供其点击率数据。通过实现一个简单的数据管道,我们可以在我们的数据仓库中捕获谷歌分析点击。
我们使用 GTM 将 GA 命中结果发送给云函数,云函数将命中结果以原始格式转发给 BigQuery。其中我们利用了一个查询调度器来将原始数据转换成转换格式。这样做允许我们将 Google Analytics 的点击量数据存储在我们的数据仓库中。它可以用于执行任何类型的分析和/或创建我们喜欢的报告。
类似的读数
- 使用 GCP 自动将数据导入谷歌分析
- 使用 BigQuery ML 执行 RFM 分析
参考
Github 代码
[## muffaddal 52/Send-Google-Analytics-Hits-to-big query
这个回购有代码来帮助发送谷歌分析点击量数据到 BigQuery。它使用了 GTM,云函数,BigQuery 和…
github.com](https://github.com/muffaddal52/Send-Google-Analytics-Hits-to-BigQuery)
用 Python 发送股票数据到你的手机!
了解如何利用 Python 的力量在股票市场中取胜…

随着股市每天都在快速变化,许多初出茅庐的投资者使用 Robinhood 等移动应用进行交易,不断保持更新是必不可少的,否则就有被落在后面的风险。这正是为什么我创建了这个快速的~150 行 Python 程序,它可以将实时股票数据直接发送到我的手机上,以便于访问。既然对这样一个程序的需求已经很清楚了,那就让我们开始编写代码吧!
导入依赖项并设置参数
首先,我们必须导入将在代码中使用的依赖项,并设置程序正确执行所需的参数。如果有任何模块没有下载到您的机器上,您可以很容易地打开您的终端或命令提示符,并使用 pip 来安装软件包。stock_list 变量必须设置为股票列表,如上所示。开始和结束日期可以更改,但必须保持日期时间格式!
将消息直接发送到您的手机的功能!
为了让代码工作,我们必须用我们的电子邮件更新 email 变量,用相应电子邮件的密码更新 password 变量。对于 sms_gateway 变量,您可以直接进入这个链接,输入您的电话号码,然后复制 SMS 网关地址响应。SMS 网关地址的一个例子是 1234567890@tmomail.net。您也可以根据需要更改文本的主题,但我将它保留为股票数据。
**免责声明:您必须在 Gmail 帐户设置中将“允许不太安全的应用程序”设置为开! 这允许 Python 访问您的 Gmail 帐户来发送 SMS 文本消息。如果你有困惑,请按照这个 教程 !
现在我们已经设置了 sendMessage 函数,我们可以继续实际获取数据了!
收集股票数据并发送消息的功能!
上面的代码由 getData 函数组成,它计算每只股票的不同指标,然后回调 sendMessage 函数向您的手机发送 SMS 消息。
在这个特定的示例中,度量是使用模块 TaLib、NumPy 和 nltk 计算的。它们包括股票的当前价格、当前新闻情绪、beta 值和相对强弱指数(RSI)值。当然,这可以根据您想要接收的数据根据您的喜好进行更改。
程序的最后两行调用 getData 函数,该函数又调用我们不久前创建的 sendMessage 函数。
这就是这个项目的全部内容,如果您对代码的任何部分或任何指标的计算有任何疑问,请随时联系我们。整个程序的所有代码都在下面的 GitHub gist 中!
所有的代码!
请记住在您的 Gmail 帐户设置中将“允许不太安全的应用程序”设置为“开”,这样该程序才能运行!我希望这段代码在将来对你有用,非常感谢你的阅读!
免责声明:本文材料纯属教育性质,不应作为专业投资建议。自行决定投资。
如果你喜欢这篇文章,可以看看下面我写的其他一些 Python for Finance 文章!
了解如何在不到 3 分钟的时间内解析顶级分析师的数千条建议!
towardsdatascience.com](/parse-thousands-of-stock-recommendations-in-minutes-with-python-6e3e562f156d) [## 用 Python 制作股票筛选程序!
学习如何用 Python 制作一个基于 Mark Minervini 的趋势模板的强大的股票筛选工具。
towardsdatascience.com](/making-a-stock-screener-with-python-4f591b198261) [## 在 3 分钟内创建一个财务 Web 应用程序!
了解如何使用 Python 中的 Streamlit 创建技术分析应用程序!
towardsdatascience.com](/creating-a-finance-web-app-in-3-minutes-8273d56a39f8)
使用 Python 通过电子邮件和短信发送新年祝福

安妮·斯普拉特在 Unsplash 上的照片
有时,开发人员喜欢通过编程解决常规任务来使事情复杂化。我选择使用 Python 编写一些代码来发送我的新年祝福。不是因为容易;这是因为它很难——在某种程度上。不管怎样,编码很有趣!
新年到了。虽然我们开发者一般不会费心维护友情(到底是不是开玩笑?),我们不介意把我们的问候发给我们的朋友,只要有一个程序化的方法来完成这件事!
在这里,我将分两部分向您展示如何使用 Python 通过电子邮件和文本消息发送问候。
第一部分:发送电子邮件问候
Python 有一个名为[smtplib](https://docs.python.org/3/library/smtplib.html)的内置库——一个可以用来创建 SMTP 客户端会话对象的模块,允许我们向任何实施 SMTP 或 ESMTP 的电子邮件服务提供商发送电子邮件。发送电子邮件的另一个有用的模块是email包,它提供了与电子邮件相关的功能,比如读和写。
首先导入相关模块: **smtplib** 和 **email** 。
为了当前教程的简单性,我们将只发送一封纯文本电子邮件。为此,我们只需要 MIMEText 来创建电子邮件正文。在后面的教程中,我可以向您展示如何发送更复杂的电子邮件(例如,图像附件)。
import smtplib
import email
from email.mime.text import MIMEText
其次,创建发送邮件所需的变量。
在本教程中,我将使用 gmail 帐户发送电子邮件。请注意,您需要更新您的 gmail 安全设置(https://myaccount.google.com/lesssecureapps),以允许您的电子邮件使用 Python 以编程方式发送。
email_host = "smtp.gmail.com"
email_port = 587
email_sender = "" # change it to your own gmail account
email_password = "" # change it to your gmail password
email_receivers = ["xxx@gmail.com", "yyy@gmail.com", "zzz@gmail.com"] # the list of recipient email addresses
第三,起草信息。
接下来,您可以撰写您的邮件。您可以将发件人指定为您自己的电子邮件帐户。对于打算发送的邮件列表,可以使用以下格式:首先,最后,这是邮件收件人的标准格式。
message = MIMEText("I wish you a great 2020.")
message["From"] = "" # your email account
message["To"] = "John Smith<xxxx@gmail.com>, Mike Dickson<yyyyy@hotmail.com>" # the list of email addresses
message["Subject"] = "Happy New Year"
第四,发送消息。
您使用主机和端口来创建所需的 SMTP 会话。在初始化期间,Python 将通过调用 connect 方法自动建立 SMTP 连接。然后,出于安全原因,我们启动 TLS。
您只需要使用电子邮件帐户和密码来验证您的身份。如前所述,对于 gmail,您必须先放松安全设置,然后才能使用此方法登录。
您可以简单地调用sendmail方法来发送消息并退出会话。
email_server = smtplib.SMTP(email_host, email_port)
email_server.starttls()
email_server.login(email_sender, email_password)
email_server.sendmail(email_sender, email_receivers, message.as_string())
email_server.quit()
第二部分。发送短信问候
实际上,有多种方法可以使用 Python 通过短信发送新年祝福。
方法一。电子邮件发送选项的调整。
你们很多人可能都知道,许多手机运营商允许你用电子邮件发送短信。以下是美国主要航空公司的简短列表。
- cell-phone-number@txt.att.net 美国电话电报公司
- 冲刺:cell-phone-number@messaging.sprintpcs.com
- t-Mobile:cell-phone-number@tmomail.net
- cell-phone-number@vtext.com 威瑞森
因此,您可以简单地使用 1234567890@txt.att.net 作为电子邮件收件人之一,而不是使用电子邮件地址作为email_receivers变量。
但是,有一个问题,你可能必须知道与该号码相关的运营商。如果你不知道,你可以写一些代码来创造所有可能的变化(如 1234567890@messaging.springtpcs.com,1234567890@tmomail.net),以涵盖所有的可能性。我还听说有付费的第三方服务可以让你查找某个电话号码的运营商。但是我想这对于我们想要完成的目标来说有点过头了。
方法二。通过 AWS 发送
您也可以使用 AWS SNS 发送短信。显然,您需要注册一个 AWS 帐户,这超出了当前教程的范围。可以参考官网(https://AWS . Amazon . com/premium support/knowledge-center/create-and-activate-AWS-account/)。
首先,安装 AWS boto3 模块。
在终端或命令行工具中运行代码(pip install boto3)。boto3 库是为 AWS 相关管理开发的 Python 模块。
其次,用 Python 创建一个 SNS 客户端。
SNS 是一款 AWS 产品,允许开发者向最终用户发送文本消息和其他通信(例如,电子邮件)。
import boto3
client = boto3.client(
"sns",
aws_access_key_id="", # your aws access key
aws_secret_access_key="", # your aws secrete access key
region_name="us-east-1"
)
第三,创建话题,添加订阅者。
要向多个电话号码发送问候语,您需要创建一个主题,该主题允许您向该主题添加订阅者。每个用户由一个电话号码指定,电话号码还应该包括国家代码(例如,美国为+1),即 E.164 格式。因为我们正在发送消息(即短消息服务或 sms),所以我们将协议指定为sms。
topic = client.create_topic(Name="new_year") # create a topic
topic_arn = topic['TopicArn'] # get its Amazon Resource Name# Add SMS Subscribers to this topic
phone_numbers = ["+1234567890"] for phone_number in phone_numbers:
client.subscribe(
TopicArn=topic_arn,
Protocol='sms',
Endpoint=phone_number
)
第四,发布消息给题目。
将订阅者添加到主题后,就可以向主题发布消息了。您只需要提供消息,并指定要发布该消息的主题。通过这样做,所有的用户都将收到文本消息。
client.publish(Message="Happy New Year!", TopicArn=topic_arn)
方法三。通过 Twilio 发送
您也可以选择使用 Twilio 发送短信。当然,它需要一个 Twilio 帐户,可以免费注册,类似于 AWS 帐户。一旦您创建了 Twilio 帐户,我们就可以开始玩游戏了!
首先,安装 Twilio 模块。
运行命令pip install twilio安装 Twilio 模块,这将使您能够访问 Twilio 提供的各种功能。短信只是其中之一。
其次,用 Python 创建一个 Twilio 客户机
Cilent方法将用于通过获取您的 Twilio 帐户 SID 和 AUTH Token 来创建 Twilio 客户端,这两者都可以在您的 Twilio 帐户的仪表板上找到。
from twilio.rest import Clientclient = Client(
"", # your Twilio Account SID
"", # your Twilio AUTH token
)
第三,创建和发送消息。
您创建了一个列表,列出了您要发送新年祝福的所有电话号码。请再次注意,电话号码使用 E.164 格式,类似于 AWS SNS 的使用。
一个问题是,使用免费的 Twilio 帐户,你只能向你验证过的电话号码发送短信,与 AWS SNS 相比,你的灵活性较低。但是,您可以升级您的 Twilio 帐户,这样您就可以选择以非常低的成本(每条消息不到 1 美分)向您选择的多个电话号码发送消息。
phone_numbers = ["+1234567890", "+1234567891"] # the list of phone numbers to receive the messagesfor phone_number in phone_numbers:
client.messages.create(
to=phone_number,
from_="", # your Twilio phone number
body="Happy New Year!"
)
结论
通过学习本教程,您应该已经为每个作业创建了多个 python 脚本。以后,你可以使用这些脚本非常方便地发送电子邮件和短信。
所以实际上,编程确实使某些事情变得更容易,不是吗?
通过串行蓝牙从 Raspberry Pi 传感器单元发送数据
一个关于如何使用蓝牙将信息从树莓派发送到手机、平板电脑或便携式笔记本电脑的教程。

塞缪尔·切纳德在 Unsplash 上的照片
介绍
在构建便携式传感器时,我们通常希望在允许它们远程记录数据之前校准并仔细检查它们的读数。在开发它们的时候,我们可以很容易地 SSH 到它们,并把任何结果写到屏幕上。然而,当我们在世界上一个非常偏远的地方,没有笔记本电脑,无线网络或信号,会发生什么?
在本教程中,我们将探讨如何利用 Raspberry Pi Zero(无 WiFi)的蓝牙功能将初始结果传输到我们选择的手持设备。在我们的情况下,将通过使用手机或 android 平板电脑,这样我们就可以比较传感器和 GPS 读数。
安装和设置
在我们开始之前,蓝牙需要做一些改变。这些概述如下。
配置设备蓝牙
我们从更改已安装的蓝牙库的配置开始:
sudo nano /etc/systemd/system/dbus-org.bluez.service
在这里,我们找到从ExecStart开始的行,并用以下内容替换它:
ExecStart=/usr/lib/bluetooth/bluetoothd --compat --noplugin=sap
ExecStartPost=/usr/bin/sdptool add SP
添加了“兼容性”标志后,我们现在必须重新启动 Pi 上的蓝牙服务:
sudo systemctl daemon-reload;
sudo systemctl restart bluetooth.service;
配对我们的监控设备
为了防止在野外配对蓝牙设备时出现问题,预先配对设备总是一个好主意——保存它们的配置。
为此,我们按照下面链接中描述的过程使用bluetoothctl:
在使用 raspberry pi zero 时,您会受到 USB 端口的限制。而不是总是有一个 USB 集线器连接到…
medium.com](https://medium.com/cemac/pairing-a-bluetooth-device-using-a-terminal-1bfe267db35)
- 找到我们的主机 MAC 地址
hcitool scan
这将产生以下格式的结果:
Scanning ...XX:XX:XX:XX:XX:XX device1XX:XX:XX:XX:XX:XX device2
2.选择我们想要的设备并复制其地址。
3.执行以下操作:
sudo bluetoothctl
4.在蓝牙控制台中运行以下 3 个命令(替换您复制的地址):
discoverable on# thenpair XX:XX:XX:XX:XX:XX# and trust XX:XX:XX:XX:XX:XX# where XX corresponds to the address copied from above
配对时,可能会要求您确认两台设备上的 pin。trust将设备地址保存到信任列表。
要使 PI 在启动时可被发现,您可以查看下面的代码:
如何从开机就启用蓝牙可见性和配对?
medium.com](https://medium.com/cemac/keep-bluetooth-discoverable-rpi-unix-bbe1c9ecbdb6)
启动时启用通信
最后,我们希望告诉设备在启动时注意蓝牙连接。为此,我们可以将以下文件添加到/etc/rc.local(在exit命令之前)。
sudo rfcomm watch hci0 &
注意在末尾加上&符号,否则,它会停止设备的启动过程。此外,如果您正在通过串行读取另一个设备,例如 GPS 接收器,您可能希望使用rfcomm1而不是hci0 (rfcomm0)。
从另一台设备连接到蓝牙串行接口
根据您使用的设备,读取串行监视器的方法会有所不同。在 android 设备上,您可以采用 node/javascript 方法(这应该适用于所有操作系统!).出于演示的目的,我将描述一种使用 python 来检查 MacBook Pro 上的工作情况的方法。
确定端口名称
如果你有一个终端,最简单的方法就是输入
ls /dev/tty.
然后点击 tab(自动完成)按钮。
假设你没有改变这一点,这应该是你的设备hostname后跟串行端口。新安装的 raspberry pi 的默认串行端口路径应该是
/dev/tty.raspberrypi-SerialPort
读取接收的数据
为了读取接收到的任何数据,我们可以使用 python serial库和下面的代码片段。
import serialser = serial.Serial('/dev/tty.raspberrypi-SerialPort', timeout=1, baudrate=115000)serial.flushInput();serial.flushOutput()
while True:
out = serial.readline().decode()
if out!='' : print (out)
请注意,这是一个无限循环,不断打印它接收到的任何内容。要在收到“退出”消息时取消它,我们可以使用:
if out == 'exit': break
从传感器发送数据
从壳里
测试时,发送数据最简单的方法是从 raspberry pi shell 将数据回显到/dev/rgcomm0。这允许我们在编写更复杂的东西之前,手动测试端口上的通信。
echo "hello!" > /dev/rfcomm0
来自 python 脚本
如果从 raspberry pi 读取数据并对其进行预处理,我们很可能会使用 python 来完成繁重的工作。从这里我们可以将rfcomm0 通道视为一个文件,并按如下方式写入:
with open(‘/dev/rfcomm0’,’w’,1) as f:
f.write(‘hello from python!’)
结论
如果我们想快速检查传感器在野外的表现,我们可以利用 Raspberry Pi 的蓝牙功能。这是通过创建一个蓝牙串行端口并通过它发送数据来实现的。如果我们不想携带笨重的笔记本电脑,或者在 WiFi 网络被占用或不可用的情况下,这些方法特别有用。
更复杂的任务,比如向 Raspberry Pi 发送命令,甚至通过蓝牙进入它也是可能的,但是超出了本教程的范围。
敏感性、特异性和有意义的分类器
解释冠状病毒检测时有时会混淆的概念

我们如何评估机器学习分类器或测试模型的表现?我们如何知道一项医学测试是否足够可靠,可以用于临床?
虽然高度准确的冠状病毒检测在发病率较高的地方可能有用,但为什么它在发病率较低的人群中信息较少?这听起来违反直觉,令人困惑,但确实可以应用于确定您自己的二元分类器的效用!
我们通过测量测试的特异性和敏感性来定义测试的有效性。很简单,我们想知道该测试多久识别一次真阳性和真阴性。
我们的灵敏度描述了我们的测试捕捉所有阳性病例的能力。灵敏度的计算方法是将真阳性结果的数量除以阳性总数(包括假阳性)。
我们的特异性描述了我们的测试如何将阴性病例归类为阴性。特异性的计算方法是将真阴性结果的数量除以阴性总数(包括假阴性)。

费安多/CC BY-SA(https://creativecommons.org/licenses/by-sa/4.0)
重要的问题是一个模型是否有意义?仅仅依靠敏感性和特异性是不够的!为了确定一项检测对一个人群的意义或临床用途,我们需要关于疾病的预期发病率或流行率的基础信息。我们使用贝叶斯定理来理解这一点:
我们有 1 00 万人口,其中 10%的人患有某种疾病。我们使用一种非常可靠的测试,具有 98%的特异性和敏感性。在这里,事件 A 描述了这种疾病在人群中的无条件概率。 P(A) = 0.10 。
事件 B 是我们测试结果为阳性的无条件概率。我们可以通过查看我们将得到的总阳性数来计算 P(B) 。在该人群中,我们预计有 98 000 例真阳性,通过将发病率乘以总人群和敏感性计算得出。对于假阳性,我们取不患这种疾病的概率 (0.90) ,乘以人群和**(1-特异性)**。所以在这种情况下我们得到了 18 000 个误报。我们的总阳性率是 11.6%。
现在事情变得有点复杂了。所有这些值描述了该测试对于该人群的准确性。但是它没有告诉我们一个检测呈阳性的人患这种疾病的几率。我们需要应用贝叶斯定理,使用这些无条件值作为我们的先验假设。

由你友好的邻居作者创作
那么,如果有人检测结果呈阳性,那么这种疾病存在的概率是多少?
这里我们可以开始定义我们的变量。
- P(A) = 0.10
- P(B) = 0.116
- P(B|A) 描述得到阳性结果的概率,不管它是否是真阳性,而 P(A)是疾病的存在。因此 P(B|A)是我们的灵敏度。 P(B|A) = 0.98。
- P(A | B)= 0.98 * 0.1/0.116 =84.5%
因此,我们在这里看到,即使有很高的灵敏度和特异性,该测试在某些人群中可能不准确。使用贝叶斯定理,我们可以很容易地计算出来。
如果这种疾病在我们的人口中不那么常见,会发生什么呢?回想一下,灵敏度和特异性保持在 98%。
- P(A) = 0.01
- P(B) =(真阳性+真阴性)/总人口=(0.01 * 0.98+0.02 * 0.99)/10000000 =(9800+19800)/1000000 = 0.0296
- P(A | B)= 0.98 * 0.01/0.296 =33.1%
由于这种疾病现在越来越少,当你患病时,获得阳性检测结果的后验概率更低。随着人群中疾病患病率的下降,我们的阳性预测值也在下降!
生成生物医学测试或另一个二元分类模型时,请记住它可能有用的时间。看看我们的测试对我们的特定人群有多有效,因为疾病的患病率足够低——这可能不是很有用!
因此,如果您正在为一般人群中可能罕见的事物生成分类器,您需要非常高的灵敏度和特异性,以获得高阳性预测值!
基于传感器的物联网预测性维护——为什么数字信号处理是机器学习的必备条件

DSP+AI 工作流程。@版权
工厂由几种类型的资产组成。基于传感器的物联网用于资产诊断和预测。机器资产的旋转部件经常遭受机械磨损。如果没有对这种磨损进行监控,可能会导致机器故障和工厂意外停机。除了机械故障,机器也可能出现电气故障。因此,这些机器的状态监控对于早期故障检测非常重要,以避免计划外维修,最大限度地减少停机时间,从而保证机器的可靠性、正常运行时间和可持续性。几种非侵入式机器状态监控技术使用传感器。大多数是基于感应电流、振动、机器的声发射[2]。为了获得这些信号,需要传感器。远程监控需要物联网管道到位。
设备(电气和非电气)的状态监控是工业物联网工业 4.0 的主要要求之一。虽然基于传感器的数据驱动解决方案看起来像一个机器学习问题,但它不可能用 ML 解决组件级诊断。例如,感官数据可能有噪声;并且根据 SNR,传统的 ML 方法将训练噪声而不是所需的信号本身。另一个问题是,如果没有像傅立叶、小波、时间-频率、希尔伯特等的信号变换,时域数据签名不能区分、隔离或理解机器的下划线问题。

小齿轮故障电机的时域振动特征(时间序列)
在上面的例子中,小齿轮故障数据显示在时域中。当在 ML 上训练时,信号将很难推断出任何东西,因为它不能区分噪声和异常。在动态负载和噪声下,阈值方法也不是一个好主意。
通过对信号进行傅立叶变换,我们可以绘制出指向机器中特定异常的许多特征。由于模式具有不同的特征,这种方法是无监督的并且不需要大量历史数据来创建推断。

时域签名的频谱能够识别带有互调的小齿轮问题
让我们看看电梯系统振动的另一个例子。正常操作和异常模式特征之间的差异在谱域中清晰可见。

正常和异常操作的频谱@版权所有
该系统的时域特征不能区分正常和异常模式。低频谐波尖峰在频谱域中清晰可见。
另一个例子是门操作的声学频谱图。该信号包含门的各种操作,并且可以使用信号处理来识别某些操作并创建退化模型。

不同签名的时域门操作及其谱图@版权所有
什么是数字信号处理
看完上面的例子,让我们先来识别什么不是 DSP。嗯,数字 信号处理不是 关于傅里叶变换(FFT)或者 FFT 不是 DSP 在数据科学界被广泛误解。数字信号处理领域有数百种算法。另一个趋势是统计学和信号处理的融合——统计信号处理。它应用 ML 和信号处理来推导推论。
下表显示了一些选定的算法

表 1-信号处理的几种算法@版权所有
在下面的示例中,数字滤波器应用于 ISO 规范定义的特定截止频率,以滤除特定频率成分的噪声信号。否则使用移动平均线是不可能实现的。数据是电梯在 100 赫兹时的 3 个轴向加速度曲线。

ISO 标准巴特沃兹低通滤波器应用于振动信号@版权所有
数字信号处理和模拟信号处理是工程中处理传感器信号的两个分支。DSP 应用包括音频和语音处理、声纳、雷达和其它传感器阵列处理、频谱密度估计、统计信号处理、数字图像处理、数据压缩、视频编码、音频编码、图像压缩、电信信号处理、控制系统、生物医学工程和地震学等。
DSP 可能涉及线性或非线性运算。非线性信号处理与非线性系统识别密切相关,可以在时域、频域和时空域中实现。[1]
如何使用 DSP 进行 AI/ML
DSP 有两种应用方式。
基于 DSP 的数据转换—
在这种方法中,DSP 被简单地用作 ETL 工具。转换后的数据用作数据集的另一个要素。ML/AI 的下游块在统计意义上消耗数据,并学习下划线模式以得出推断。大多数数据科学家都使用这种方法,但是在许多用例中,由于缺少领域推理和对转换理解,这种方法并不理想。
基于 DSP 的设计和推理-
在这种方法中,使用 DSP 对数据进行预处理/转换到其他域,但是使用 DSP 的域知识来导出进一步用于增强下游 AI/ML 算法的推理。在这里,对信号和系统的深刻理解是创建最佳 ML 模型的先决条件。
在用例中,需要对资产的内部组件进行诊断——不仅仅是趋势——那么这种方法是强制性的。如图 1 所示,原始 ML 或 DSP 无法将齿轮-小齿轮问题检测为 ETL + ML。我们需要了解谐波的含义、频带中能量的含义、噪声水平、衰减、相位关系、区分信号和噪声的能力等。这适用于几乎所有的资产类别——电机、泵、压缩机、发电机、输送机、发动机等。
物联网传感器应用的 DSP 和 AI 工作流程

DSP+AI 工作流程。@版权
基于 DSP 的人工智能应用的工作流程如上图所示。
数据采集过程
这个过程对于任何应用都是最关键的。选择传感器类型、传感器规格、采样频率、模数转换、传感器接口的决策对诊断和预测性维护最终目标的成功起着至关重要的作用。
我在下图中强调了传感器接口的一些关键组件。在这个过程中,我分析了一些供应商,所以他们的名字是可见的。然而,市场上有许多具有不同规格的参与者,特定组件的选择取决于感兴趣的机器/源的许多领域相关规格和最终目标。
许多现成的智能传感器提供商已经集成了 ADC、接口和连接。

传感器接口规范@版权所有
接下来是 DSP 的关键模块,如前所述,该模块执行信号处理操作,从滤波、变换到多个域,如表 1 所示
DSP 之后是特征工程部分,从转换后的数据中提取特征。这些要素是对数据集中原始要素的补充,提供了对数据的深刻见解,否则这是不可能的。
接下来我们分成两个分支。在**领域特定路径中,**我们从领域角度推断通过多重转换得到的签名,并从中导出诊断模型。进一步向下,具有诊断特征的高级模型训练可用于训练 AI 模型,以导出 RUL 和其他预测性维护相关的度量。
另一条路径是基于统计推断的方法,用于为模型构建提供额外信息,但本质上是纯统计的。
结论
我们了解了什么是数字信号处理,以及它对基于物联网传感器的用例有何意义。
我们看到了传统的基于统计的人工智能建模和基于信号处理的方法之间的差异。
我们看到传感器接口规格涉及上游和下游集成、ADC、采样速率、连接性。
我们讨论了基于 DSP 的人工智能工作流。
参考
- https://en.wikipedia.org/wiki/Digital_signal_processing
- 使用压缩信号处理、Meenu Rani、Sanjay Dhok 和 Raghavendra Deshmukh 传感器的机器状态监控框架。
- 数字信号处理:原理、算法和应用,J.Proakis,2007。
- 统计信号处理基础,第三卷:实用算法开发。
- 智能传感器与系统— 2015,林永龙,等人,施普林格。
基于迁移学习的句子正确性分类器
学习简单地使用 huggingface 构建生产级 NLP 应用程序

下面是 链接直播仪表盘
在本文中,我们将利用自然语言处理领域的最新突破,构建一个接近艺术水平的句子分类器。我们将重点关注迁移学习在 NLP 中的应用,以在一系列 NLP 任务中以最小的努力创建高性能模型。
介绍
在过去两年左右的时间里,与应用深度学习的其他领域相比,NLP 的研究一直非常迅速。Allen AI 的 ELMO、OpenAI 的开放 GPT 和谷歌的 BERT 等模型允许研究人员在特定任务中以最小的微调打破多个基准。因此,NLP 研究复制和实验变得更加容易。
伯特
谷歌研究人员在 2018 年底发布的 BERT(来自变压器的双向编码器表示)是我们将用来训练句子分类器的模型。
我们将在预训练的 BERT 模型上使用迁移学习。这种方法比从零开始训练像 GRU 或 LSTM 这样的深度模型要好,因为:
- 预先训练的 BERT 模型权重已经编码了许多关于我们语言的信息。因此,训练我们的微调模型所需的时间要少得多。我们将使用超参数扫描来训练我们的模型,以便在 colab 上在一个小时内找到最佳组合,而在 GPU 上从头训练单个深度 RNN 模型将需要数百个小时以上!
- 因为我们本质上是在进行迁移学习,所以我们需要少得多的数据来建立一个精确的系统。与从头开始训练一个模型所需的数百万个数据点相比,我们只需要几千个数据点就可以完成同样的任务。

基于 transformer network 的 BERT 是一个双向网络,它为建模、分类等各种任务生成语言编码。
谷歌表示,BERT 有助于更好地理解搜索中单词的细微差别和上下文,并更好地将这些查询与更相关的结果匹配起来。它也用于特色片段。这里有一个例子。

图片来源——blog.google.com
让我们看看这个模型的另一个令人兴奋的应用,即句子分类。
正在安装 Huggingface 库
现在,我们将快速进入培训和实验,但如果你想了解更多关于环境和数据集的细节,请查看克里斯·麦考密克的本教程。
让我们首先在 colab 上安装 huggingface 库:
!pip install transformers
这个库带有各种预先训练的艺术模型。对于我们的句子分类,我们将使用BertForSequenceClassification模型。
可乐数据集
我们将使用语言可接受性语料库(CoLA) 数据集进行单句分类。它是一组被标记为语法正确或不正确的句子。它于 2018 年 5 月首次发布,是“GLUE Benchmark”中包括的测试之一,BERT 等模型正在进行竞争。
让我们下载并解压缩数据集
如果一切执行无误,您将获得以下文件:
如你所见,我们已经有了数据集的标记化版本,但我们需要再次标记它,因为为了应用预训练的 BERT,我们必须使用模型提供的标记化器。这是因为:
- 该模型具有特定的、固定的词汇表,并且
- BERT 记号赋予器有一种特殊的方式来处理词汇表之外的单词。
解析数据集
让我们通过使用 pandas 解析数据集来看看数据集的格式

这里需要注意一些事情:
- 我们只有 8551 个数据点,通过使用迁移学习来训练 SOTA 深度模型。
- 我们关心的属性是句子和 it 标签。
- 可接受性判断,其中 0 =不可接受,1 =可接受。
最后,我们来列出这些句子。
标记化
如前所述,要输入到 BERT 模型中的句子必须使用 BERT 记号化器进行记号化。让我们看一个例子。
Using this tokenizer on a sentence would result into something like this:Original: Our friends won't buy this analysis, let alone the next one we propose.Tokenized: ['our', 'friends', 'won', "'", 't', 'buy', 'this', 'analysis', ',', 'let', 'alone', 'the', 'next', 'one', 'we', 'propose', '.']Token IDs: [2256, 2814, 2180, 1005, 1056, 4965, 2023, 4106, 1010, 2292, 2894, 1996, 2279, 2028, 2057, 16599, 1012]
在我们使用这个记号赋予器处理整个数据集之前,我们需要满足几个条件,以便为 BERT 设置训练数据:
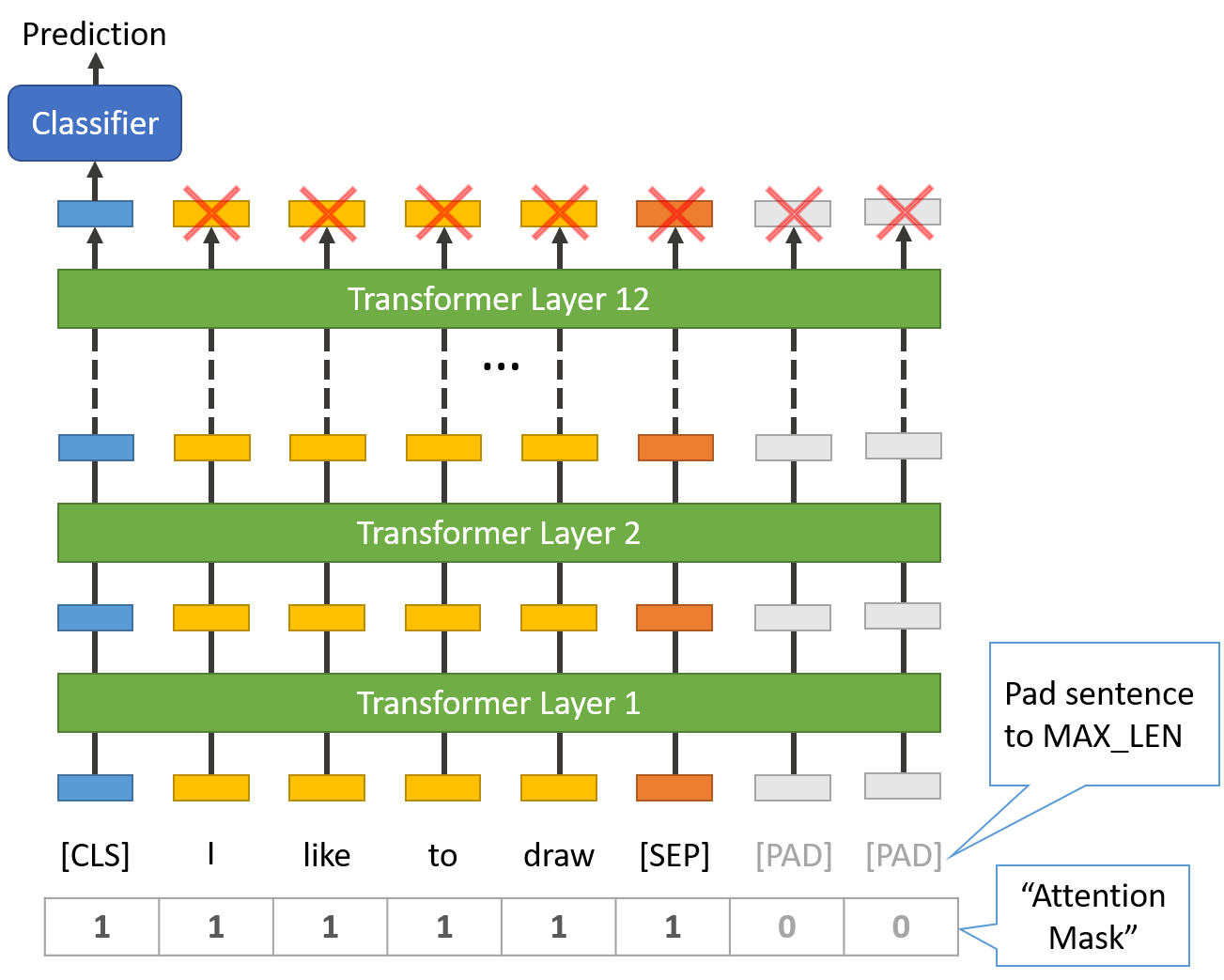
- 在每句话的开头和结尾添加特殊标记。在每句话的末尾,我们需要添加特殊的[SEP]标记,对于分类任务,我们必须在每句话的开头添加特殊的[CLS]标记。
- 填充和截断所有句子,使其长度保持不变
- 明确区分真实标记和带有“注意掩码”的填充标记。“注意屏蔽”只是一个由 1 和 0 组成的数组,表示哪些标记是填充的,哪些不是
以下是经过所有预处理后,网络架构如何对特定输入进行操作。

图片来源—http://www.mccormickml.com/assets/BERT/padding_and_mask.png
第一个任务是决定一个句子的最大长度。
输出
Max sentence length: 47
为了遵循大小应该是 2 的幂的一般惯例,我们将选择最接近的 2 的幂的数字,即 64。
现在,我们准备执行真正的标记化。但是当我们使用变压器时,我们可以使用一个内置函数 tokenizer.encode_plus ,它可以自动完成以下所有任务:
- 把句子分成几个标记。
- 添加特殊的[CLS]和[SEP]标记。
- 将令牌映射到它们的 id。
- 将所有句子填充或截短至相同长度。
- 创建注意屏蔽,明确区分真实令牌和[PAD]令牌。
我们将把数据分成训练集和测试集。将我们的训练集划分为 90%用于训练,10%用于验证。
加载数据
接下来的步骤需要我们猜测各种超参数值。我们将通过扫描所有参数的所有值组合来自动完成这项任务。为此,我们将在开始训练循环之前初始化一个 wandb 对象。当前运行的超参数值保存在 wandb.config.parameter_name 中。
这里,我们使用 RandomSampler 对训练集进行采样,使用 SequentialSampler 对验证集进行采样。
建立培训模型
我们将使用经过预先训练的机器人进行序列分类。我们将添加单个密集或全连接图层来执行二进制分类任务。我们将把程序的每个部分作为一个独立的功能块。
num_labels 参数描述了最终输出神经元的数量。
我们将使用由 huggingface 提供的内置权重衰减机制的 Adam 优化器的实现。学习率将由 wandb.config 提供
我们还将初始化一个学习率调度程序来执行学习率衰减。训练时期也是一个超参数,所以我们将使用 wandb.config 来初始化它。
初始化权重和偏差
在我们训练我们的模型之前只剩下一步了。我们将设置一个配置文件,列出一个超参数可以取的所有值。然后,我们将初始化我们的 wandb sweep 代理,以记录、比较和可视化每个组合的性能。
我们希望最大化的指标是 val_accuracy ,我们将在训练循环中记录它。
在 BERT 论文中,作者描述了执行迁移学习的最佳超参数集,我们对超参数使用了相同的值集。
现在我们有了运行扫描所需的扫描 id。我们现在只需要一个 train 函数,它将在每次扫描中被重复调用。
训练模型
选择最佳模型超参数
在运行 wandb 扫描时,除了我们手动记录的图像之外,您还会获得一些自动可视化图像。现在是做扣除的时候了。
关于模型性能的一些最重要的信息可以直接从参数相关图中推导出来。

Wandb 的平行坐标图-报告中的链接
在这里,我们可以看到在最大化验证准确性的任务中所有运行是如何执行的。我们可以推断出最佳的超参数组合是批量为 16,学习率为 3e-5,训练 3 个时期,这将导致大约 84%的准确率。
如果您想要一个更简单的可视化,只比较每次运行所用的时间以及它在优化所需指标方面的表现,您可以参考仪表板中的另一个有用的可视化,它比较验证准确性与特定运行的时间。

现在,让我们看看我们记录的指标的可视化效果。

扫描中每次运行的分批列车损失

扫描中每次运行的平均验证损失

扫描中运行的平均训练损失比较

多次运行记录的验证准确度的比较
现在,您已经有了在最佳超参数值集上训练的 BERT,用于执行句子分类以及支持参数选择的各种统计可视化。
这篇文章演示了使用预训练的 BERT 模型,您可以根据您感兴趣的特定 NLP 任务,使用 huggingface 界面通过最小的微调和数据快速创建模型。
我希望这是一本好书。本文中的所有结果都可以使用这个 colab 笔记本重现,并且可以在这个 wandb 扫描页面中查看比较各种运行的可视化效果。
句子嵌入与 CoreNLP 的递归情感模型
入门
理解并实现 CoreNLP 的情感模型。
你好。几周前,我发布了关于库 coreNLP和更具体的情感分析模型的系列文章** **的第一篇。第一篇文章是对 Java 包及其主要特性的介绍,特别针对像我这样习惯于使用 Python 的人。正如所承诺的,本系列的第二篇文章将更深入地探讨 CoreNLP 的情感注释器:为什么它不是你常用的情感分类器,它背后的递归模型,以及如何用一些简单的 Java 脚本来实现它(你可以在我的 github 上找到它!).
我想,在我开始之前,我应该警告读者:⛔️这篇文章很少谈到情感分析和很多关于句子嵌入的⛔️.不要害怕,希望在你阅读的时候这对你有意义!

让我们从…谷歌一下 CoreNLP 情绪模型开始!当点击进入 coreNLP 情感分类器的官方页面时,我们发现了以下描述
大多数情绪预测系统的工作原理只是孤立地看单词,对正面单词给出正面分,对负面单词给出负面分,然后将这些分相加。那样的话,单词的顺序会被忽略,重要的信息也会丢失。相比之下,我们新的深度学习模型实际上基于句子结构建立了整个句子的表示。它根据单词如何组成更长短语的意思来计算情感。这样模型就不像以前的模型那么容易被忽悠了。
看完这一段,我们已经可以分辨出两件事:
- 这不是一个普通的情绪预测器,而是更有趣的东西(可能更有效!)
- 这个模型和其他情感模型之间的核心区别似乎不是分类器本身,而是输入文本的表示(T2)。
第二点已经揭示了这篇文章的中心主题:文本表示。为了深入了解为什么 CoreNLP 的情感模型如此强大和有效,我们首先需要理解**恰当地表示输入文本的重要性。**而这就是我们下面要讲的!
我先介绍一下文本表示的复杂性(我称之为语义建模)是什么,以及 word2vec 等知名单词嵌入模型的局限性 。然后我将谈论语义组合性的概念以及 coreNLP 如何使用它来创建一个非常强大的递归情感分析模型。最后,我将给出一个 Java 中的简单实现的例子。我们走吧!****
文本表示或语义建模
我喜欢把语义建模想成这样:人类可以阅读和理解一系列字母和符号(就像这句话),然而,ML 算法只能理解数字序列。为了让情感分类器或任何其他模型处理文本,必须将文本从人类可读形式翻译成计算机可读形式。
原来有许多方法来表示文本:作为一个单词包,一个热编码,基于逻辑的框架,嵌入空间上的语义向量…并且重要的是选择最好的一个,因为这将直接影响你的模型的性能。想想看:如果模型连输入的文本都不能理解,我们怎么能指望它去分类呢!
在我上面提到的所有语义建模技术中,语义向量的使用被认为是 NLP 文献中首选文本表示选项之一。特别是,近年来,单词嵌入已经成为一种非常流行的方法并引起了很多关注。想想 word2vec , GloVe , FastText …
- 单词嵌入及其局限性
单词嵌入是建立在这样一个理念上的:从语境中推断出一个给定单词的意思是可能的**(Mitchell and la pata,2010)。**
在这个框架中,单词 基本上由向量来表示,这些向量携带特定单词的潜在语义信息(Socher,2013)。图 1 表示简单的语义二维空间**。请注意,相似的单词看起来更接近。**

图 1 (Mitchell 和 Lapata,2010 年,图 1,第 1390 页)语义向量空间中表示的单词。它们之间的接近表明语义相似。
然而,尽管它们被广泛使用,当我们对计算一个短语或句子的表示感兴趣时,这些模型的局限性变得非常明显。单词嵌入模型只能孤立地表示单词并且不能说明它们之间的句法和语法关联。
当我们想要表示一个句子,但是我们只有它的单词的嵌入时,更常用的解决方案之一是平均它的单词向量以获得一个句子向量。这种方法已经被证明在某些情况下足够有效,但是我个人认为它非常简单,因为句子的特定句法、语法和依赖性都被忽略了。
- 复合性
作为一个有语言学和文学背景的人,在做文本分析时考虑句法、语法和词序是我甚至不会质疑的事情!!在亲身经历了单词嵌入的局限性之后,我偶然发现了语义组合的原则,并开始思考将它应用到语义建模任务中会有多酷。这项原则规定:
“一个(句法上复杂的)整体的意义只是它的(句法)部分的意义以及这些部分组合的方法的函数”(Pelletier,1994 年,第 11 页)。
在 NLP 文献中,弗雷格原理最常见的解释和使用是作为一个理论基础它规定一个人应该能够根据短语来解释一个完整句子的意思,同样,也应该能够根据单词来解释这些短语。****
因此,当涉及到语言的表示时,建模者应该意识到每个句法操作额外隐含了一个语义操作** (Mitchell and Lapata,2010)。Partee (1995,第 313 页)正式提出了表达两个元素 u 和 v 的组合的公式 1 ,其中 f 是作用于两个成分的组合函数和 R 说明了 u 和 v 之间的句法关系(Mitchell and Lapata**

公式 1 (Mitchell 和 Lapata,2010 年,第 1393 页)
在单词嵌入的基础上,一些作者试图包含不同的组合方法,目的是嵌入语言的各个方面,如词序和句法(Socher,2013)。这方面的一个例子是理查德·索赫尔和他的递归模型。
用于句子嵌入的递归神经网络
当我了解到 Socher 的工作时,我变得非常兴奋,因为他基本上是在试图将这种作曲的想法融入到他的模型中,以构建一种更完整的嵌入句子的形式。为此,他提出了一种基于递归神经网络(RecNN)的新方法。****
该模型基于这样的思想:从更简单的元素(即单词)开始计算句子嵌入,然后以自下而上的方式递归使用相同的合成函数。这种分解句子然后以递归的、自下而上的方式构建句子的方式将允许最终输出更好地捕捉关于句子的语义、句法和情感的复杂信息。我觉得这太酷了!****
- 型号概述
现在,我将概述一下 Socher 等人(2013) 提出的方法背后的直觉。图 2 展示了构建递归模型的组合思想的简化版本。在本节中,我将使用这个三元组作为例子。
图 2 将句子及其内部元素描述为解析树的节点。这种解析树被称为二进制**,因为每个父节点只有两个子节点。RecNN 模型的基本元素是树的叶子,因此处理从将句子分割成单词和计算每个单词的单词嵌入量开始。在上面的例子中,第一步是分别计算单词“not”、“very”和“good”的表示法 a 、 b 和 c 。**

图 2 (Socher 等人,2013 年,图 4,第 4 页)
随后,这些单词表示中的两个将被配对**,以便计算一个更高级别的短语表示。计算将由合成函数完成。在图 2 中, p 1 是通过将组合函数 g 应用于单词嵌入 b 和 c 来计算的。**
这种用于配对节点的组合方法将自底向上递归重复,直到到达树的根。在图 2 中,根节点是 p 2,它是通过将组合应用于单词嵌入 a 和短语嵌入 p 1 来计算的。根节点是树中最高的节点,通常代表完整的句子**。**
值得注意的是,在本例中,组合函数 g 对于两个组合是相同的。类似地,对于更长的句子,合成函数将始终保持不变**,并将始终将任何一对向量作为输入。这些向量可以表示任何级别的任何节点(例如,单词、子短语、短语),但是它们必须总是具有相同的大小。当组合向量 b 和 c 时,组合 p 1 的输出也将具有与 b 和 c 相同的维数。同样的,组合 a 和 p 1 的输出 p 2 也将具有相同的大小。为了允许递归使用相同的复合函数,这是基本的。**
- Sooo,感情在哪里?
你可能想知道这其中的情绪在哪里!
使用 softmax 分类器在每个节点实际预测情感,该分类器使用节点向量作为输入特征。这在图 2 中由从节点 c 、 p1 和 p2 出现的彩色圆圈表示。
此外,情感分类是多标签**,因此情感得分将在 0-4 之间变化:0 表示非常负面,1 表示负面,2 表示中性,3 表示正面,4 表示非常正面。**
在树的根节点预测的情感将是分配给特定句子的最终情感。在图 2 的例子中,我们可以看到根节点被归类为否定,因此整个句子将是否定的。****
实施
我现在将呈现一个非常简短的前一篇文章的脚本扩展,以便通过情感分类器运行一些输入文本,并获得一些关于预测输出的指标。
第一步是将解析和情感包含在我们的注释器列表中(我们需要解析来运行情感分析)。
// set the list of annotators to run
props.**setProperty**("annotators", "tokenize,ssplit,pos,lemma,ner,depparse,parse,sentiment");
这样,我们知道输入文本现在将通过情感预测器,因此我们只需检索结果。我们首先想知道特定句子的最终情感得分是多少(在根节点的预测)。
**Tree** tree = sentence.**sentimentTree**();//get overall score
**int** sentimentScore = RNNCoreAnnotations.**getPredictedClass**(tree);//print score to terminal
System.out.println("Final score " + sentimentScore );
我们这样做是为了将最终得分保存在一个名为 sentimentScore 的变量中。这个数字总是 0、1、2、3 或 4。
此外,我们想知道预测者分配一个句子属于每个类别的概率是多少。我们通过以下方式获得此类信息:
**SimpleMatrix** simpleMatrix = RNNCoreAnnotations.**getPredictions**(tree);//Gets probability for each sentiment using the elements of the sentiment matrix**float** veryneg = (float)Math.round((simpleMatrix.**get**(0)*100d));
**float** neg = (float)Math.round((simpleMatrix.**get**(1)*100d));
**float** neutral = (float)Math.round((simpleMatrix.**get**(2)*100d));
**float** pos = (float)Math.round((simpleMatrix.**get**(3)*100d));
**float** verypos = (float)Math.round((simpleMatrix.**get**(4)*100d));
概率将存储在变量 veryneg 、 neg 、neary、 pos 和 verypos 中。
现在让我们运行整个文件coreNLP _ pipeline 3 _ LBP . Java来获得一个示例输出。我们将使用以下文本作为输入,以便观察预测中的变化:“这是一个可怕的句子。我太喜欢这句话了!这是正常的一句话”。该文本保存为 coreNLPinput_2.txt 。使用以下命令运行脚本:
java -cp "*" coreNLP_pipeline3_LBP.java
一手牌的结果将打印在终端上,如下图所示。我们可以观察到分配的分数(“最终分数”)对句子有意义:否定、肯定和中性。我们也看到概率是一致的,加起来是 100。

终端输出
此外,所有结果都被打印到一个. txt 文档 coreNLP_output2.txt 中,使用下面的命令可以很容易地将该文档作为 DataFrame 导入 python。结果数据帧将有 13 列:’ par_id ‘,’ sent_id ‘,’ words ‘,’ lemmas ‘,’ posTags ‘,’ nerTags ‘,’ depParse ‘,’ perspective ‘,’ veryneg ‘,’ neg ‘,’ neu ‘,’ pos ‘和’ verypos '。
import pandas as pd
df = pd.read_csv('coreNLP_output.txt', delimiter=';',header=0)

从输出创建的数据帧。txt 文件
下次……
暂时就这样吧!希望您喜欢它,并且像我第一次看到这个模型时一样,对在句子向量中包含语法感到兴奋!我觉得对于像我这样的文学专业学生来说,这是一个非常令人满意的模式,因为它建立在实际的语言学基础上。
****下次我们将继续讨论句子嵌入!我们将介绍如何从 coreNLP 注释对象中提取它们,将它们与其他更基本的句子嵌入进行比较,并使用一些特征约简和可视化方法探索它们的信息性。我们还将进一步使用这些向量来计算更全面的文档嵌入,以便在文档级别执行情感分析!✌🏻
**GitHub:【https://github.com/laurabravopriegue/coreNLP_tutorial **
文献学
弗雷格,g .,1980 年。算术的基础:对数字概念的逻辑数学探究。西北大学出版社。
米切尔,j .和拉帕塔,m .,2010 年。语义分布模型中的合成。认知科学, 34 (8),第 1388–1429 页。可从以下网址获得:https://online library . Wiley . com/doi/full/10.1111/j . 1551-6709 . 2010 . 01106 . x
帕蒂,b,1995 年。词汇语义和组合性。认知科学的邀请:语言, 1 ,第 311–360 页。
罗瑟尔,曼宁,C.D .和 ng,纽约,2010 年 12 月。用递归神经网络学习连续短语表示和句法分析。在NIPS-2010 深度学习和无监督特征学习研讨会的会议录(2010 卷,第 1–9 页)。可在:https://nlp.stanford.edu/pubs/2010SocherManningNg.pdf
Socher,Lin c . c .,Manning c .和 ng,A.Y .,2011 年。用递归神经网络解析自然场景和自然语言。在第 28 届机器学习国际会议(ICML-11)的会议记录中(第 129-136 页)。可在:https://NLP . Stanford . edu/pubs/SocherLinNgManning _ icml 2011 . pdf查阅
Socher,b . Hu val,c . d . Manning 和 a . y . Ng,2012 年 7 月。通过递归矩阵向量空间的语义合成。在2012 年自然语言处理和计算自然语言学习经验方法联合会议记录(第 1201-1211 页)。计算语言学协会。
Socher,r .,Perelygin,a .,Wu,j .,Chuang,j .,Manning,C.D .,ng,a .,Potts,c .,2013 年 10 月。情感树库语义合成的递归深度模型。在2013 年自然语言处理经验方法会议记录(第 1631-1642 页)。可在:https://www.aclweb.org/anthology/D13-1170
高性能人类语言分析工具,现在带有 Python 中的原生深度学习模块,可用于许多…
stanfordnlp.github.io](https://stanfordnlp.github.io/CoreNLP/) [## 单词嵌入和 Word2Vec 简介
单词嵌入是最流行的文档词汇表示之一。它能够捕捉…的上下文
towardsdatascience.com](/introduction-to-word-embedding-and-word2vec-652d0c2060fa) [## 感人至深:用于情感分析的深度学习
这个网站提供了预测电影评论情绪的现场演示。大多数情绪预测系统都有效…
nlp.stanford.edu](https://nlp.stanford.edu/sentiment/)**
基于名词和数值的句子评分

在处理文本数据时,句子评分是自然语言处理(NLP)领域中最常用的过程之一。这是一个根据所用算法的优先级将数值与句子相关联的过程。
这个过程尤其在文本摘要中被高度使用。有许多流行的句子评分方法,如 TF-IDF、TextRank 等。在这里,我们将检查一种新的方法,根据名词、数值和 word2vec 的相似性对句子进行评分。
步骤 1:导入库
步骤 2:文本处理和方法
从 BBC 的一篇随机新闻文章中随机选取了一段进行研究。处理步骤如下所述:
- 使用 NLTK sent_tokenize 中的句子标记器拆分每个句子。

2.诸如%、$、#、@等特殊字符已被删除。
3.每个句子的所有单词都被标记了。
4.停用字词列表中包含的停用字词(如 and、but、or)已被删除。
5.确保一个句子中的所有单词只出现一次。
6.词汇化已经被用来寻找词根
加工
方法
步骤 3: Gensim Word2Vec
使用 Gensim Word2Vec skip-gram 方法创建一个词汇化文本列表的向量列表。
第四步:句子评分
为了给一个句子打分,使用了两种方法:meanOfWord()和 checkNum()。这个方法有两个 pos 值列表,包括名词和数字。但问题是像“234”、“34.5”(数字前的空格)这样的数字在 NLTK pos_tag()中被视为名词。因此,使用了另一种方法 checkNum()来确认它是否是一个数字。meanOfWord()中使用的程序已经在下面提到:
- 从 word2vec 模型中找出每个单词的相似度,并计算平均相似度
- 检查这个单词是否是一个数字
- 如果是数字,则平均相似度加 1,如果是名词,则平均相似度加 0.25
- 返回更新后的平均值
对于词汇化列表中的每个句子,已经计算了平均分数并将其推入分数列表中。分数的输出将是该句子的索引号和该句子的数值分数。
我的输出是:
[[0, 2.875715106488629], [1, 3.3718763930364872], [2,2.117822954338044], [3, 4.115576311542342]]
这表明:
'China remains the main area of concern for BMW after sales there fell 16% last year.' got 2.875715106488629 score.'However, BMW is hopeful of a much better year in 2005 as its direct investment in China begins to pay dividends.' got 3.3718763930364872 score.'The company only began assembling luxury high-powered sedans in China in 2003.' got 2.117822954338044 score.'2004 was generally a good year for BMW, which saw revenues from its core car-making operations rise 11%.' got 4.115576311542342 score.
第四个句子得分最高,因为它比其他句子包含更多的名词和数值。它可能会有所不同,因为 word2vec 模型可能会为不同的迭代生成不同的向量。
完整代码如下:
注意:
在名词和数值数量非常多的情况下,这种方法会提供更好的性能。
如果你觉得这个方法有用,你可以使用它并与他人分享。欢迎在评论区写下你的建议。
谢谢你!
亚马逊电子数据集评论的情感分析和产品推荐——第一部分
第 1 部分:探索性数据分析(EDA)
介绍
互联网彻底改变了我们购买产品的方式。在在线市场的零售电子商务世界中,体验产品是不可行的。还有,在今天的零售营销世界里,每天都有如此多的新产品涌现出来。因此,客户需要在很大程度上依靠产品评论来做出更好的购买决策。然而,搜索和比较文本评论可能会让用户感到沮丧。因此,我们需要更好的数字评级系统的基础上审查,这将使客户购买决策容易。
在他们的决策过程中,消费者希望使用评级系统尽快找到有用的评论。因此,能够从文本评论中预测用户评级的模型至关重要。获得文本评论的整体感觉反过来可以改善消费者体验。此外,它可以帮助企业增加销售,并通过了解客户的需求来改进产品。
考虑了电子产品的亚马逊评论数据集。还考虑了用户对不同产品给出的评论和评级,以及关于用户对产品的体验的评论。

问题陈述
目标是开发一个模型来预测用户评级、评论的有用性,并基于协同过滤向用户推荐最相似的项目。
数据收集
电子数据集由来自亚马逊的评论和产品信息组成。该数据集包括评论(评级、文本、有用性投票)和产品元数据(描述、类别信息、价格、品牌和图像特征)。
产品完整点评数据
该数据集包括电子产品评论,如评级、文本、有用性投票。这个数据集是从http://jmcauley.ucsd.edu/data/amazon/获得的。原始数据是 json 格式的。json 被导入并解码,以将 json 格式转换为 csv 格式。样本数据集如下所示:

示例产品评论数据集
每行对应一个客户评论,包括以下变量:

产品元数据
该数据集包括电子产品元数据,例如描述、类别信息、价格、品牌和图像特征。这个数据集是从http://jmcauley.ucsd.edu/data/amazon/获得的。json 被导入并解码,以将 json 格式转换为 csv 格式。示例产品元数据数据集如下所示:

示例产品元数据集
每一行对应于产品,包括以下变量:

数据争论
合并数据帧
json 文件中的产品评论和元数据集保存在不同的数据框架中。使用左连接将两个数据帧合并在一起,并将“asin”保留为普通合并。最终合并的数据框描述如下所示:

合并数据帧信息
为了减少运行模型的时间消耗,只选择了耳机产品,并采用了以下方法。
- 在 1689188 行中,45502 行在产品标题中为空值。这些行被删除。
- 从合并的数据帧中提取产品名称为“耳机”、“头戴式耳机”、“头戴式耳机”的数据集。最终的耳机数据集是 64305 行(观察值)。
处理重复项、缺失值
- brand 列中有 22699 行被视为空值。为了解决这个问题,从标题中提取品牌名称,并替换品牌中的空值。
- 已删除“审阅者姓名”、“价格”、“描述”和“相关”中缺少的值。
- “审查文本”和“总结”连接在一起,并保存在“审查文本”功能下
- 有益的功能被分为正面和负面反馈。
- 大于或等于 3 的评级被归类为“好”,小于 3 的评级被归类为“差”。
- 有用性比率是基于该评论发布反馈/总反馈来计算的
- 已删除基于“asin”、“reviewerName”、“unixReviewTime”的重复项。删除重复项后,数据集由 61129 行和 18 个要素组成。
- ReviewTime 已转换为 datetime“% m % d % Y”格式。
- 为清楚起见,对列进行了重命名。

耳机数据集的描述
描述统计学
获得了以下汇总统计数据

耳机数据集的汇总统计如下所示:

汇总统计数据
预处理文本
因为文本是所有可用数据中最不结构化的形式,所以文本中存在各种类型的噪声,并且在没有任何预处理的情况下,数据不容易分析。对文本进行清理和标准化,使其无噪声并可供分析的整个过程称为文本预处理。在本节中,应用了以下文本预处理。
移除 HTML 标签
HTML 标签,它通常不会为理解和分析文本增加多少价值。HTML 单词已从文本中删除。
去除重音字符
重音字符/字母被转换并标准化为 ASCII 字符。
扩张收缩
缩写是单词或音节的缩写。它们以书面或口头的形式存在。现有单词的缩短版本是通过删除特定的字母和声音创建的。在英语缩写的情况下,它们通常是通过从单词中去掉一个元音而产生的。
本质上,缩写确实给 NLP 和文本分析带来了问题,因为首先,我们在单词中有一个特殊的撇号字符。理想情况下,我们可以为缩写和它们相应的展开建立一个适当的映射,然后用它来展开文本中的所有缩写。
删除特殊字符
文本规范化的一个重要任务是去除不必要的和特殊的字符。这些可能是出现在句子中的特殊符号,甚至是标点符号。该步骤通常在标记化之前或之后执行。这样做的主要原因是因为当我们分析文本并利用它来提取基于 NLP 和 ML 的特征或信息时,标点符号或特殊字符通常没有多大意义。
词汇化
词汇化的过程是去除词缀以获得单词的基本形式。基本形式也被称为词根,或引理,将始终存在于字典中。
删除停用词
停用词是意义不大或没有意义的词。它们通常在处理过程中从文本中删除,以保留具有最大意义和上下文的单词。停用词通常是在你根据单数标记聚合任何文本语料库并检查它们的频率时出现次数最多的词。像 a、the、me 等词是停用词。
构建文本规范化器
基于我们上面写的函数和附加的文本校正技术(例如小写文本,并删除多余的换行符、空格、撇号),我们构建了一个文本规范化器,以帮助我们预处理 new_text 文档。
在对“review_text”文档应用文本规范化器之后,我们应用标记化器为干净的文本创建标记。结果,我们总共有 3070479 个单词。清洗后,我们有 25276 个观察值。
干净的数据集将允许模型学习有意义的特征,而不会过度适应不相关的噪声。在完成这些步骤并检查其他错误之后,我们可以开始使用干净的、带标签的数据在建模部分训练模型。
探索性数据分析
收集数据后,对数据进行辩论,然后进行探索性分析。通过探索性分析探讨了以下见解。
- 根据评论预测评分
- 对大量评论有用
- 评分与评论数量
- 评级与评论比例
- 有用比例与评论数量
- 评级与有用性比率
- 最受欢迎的 20 种产品
- 垫底的 20 种受评产品
- 积极和消极的话
- 不同评级、品牌等的世界云
20 大最受关注品牌

评论最多的 20 大品牌
20 大最少评论品牌

前 20 个评论最少的品牌
20 大最受关注产品

20 大最受关注的产品
评论最积极的耳机
亚马逊在耳机类别下评价最高的产品是“松下 ErgoFit 入耳式耳塞耳机 RP-HJE120-D(橙色)动态晶莹剔透的声音,符合人体工程学的舒适贴合”。该产品总体优良率超过 3。
以上产品几年后会怎么样?
从 2010 年起,松下耳塞耳机获得了总体正面评价。评级在一段时间内的分布如下所示。该产品的总体良好均值评级超过 4。

松下耳塞耳机的年平均额定值对比
这个词来自对上述产品的良好评级评论。从卖家的角度来看,它显示了主要的洞察力。**表示大部分积极的客户同意“非常合适”、“价格合理”,最不同意“音质”。**同样,该词来源于对上述产品的不良评级评论。表示大部分客户认可“质量差”和“声音太差”。 从卖家的角度来看,本产品需要更新“更好的声音”和“质量”,以获得客户的积极反馈。

来自松下耳机良好评级评论的真知灼见

来自松下耳机不良评级评论的真知灼见
评论最负面的耳机
亚马逊耳机类别中评论最负面的产品是“我的区域无线耳机”。该产品的整体不良评级低于 3。
以上产品几年后会怎么样?
除 2012 年外,从 2010 年起,我的 zone 无线耳机受到了全面的负面评价。评级在一段时间内的分布如下所示。该产品的总体不良均值评级约为 2.5。

My zone 无线耳机的年度与平均等级对比
下面显示了来自上述产品的良好评级评论的词云。从卖家的角度来看,它显示了主要的洞察力。**表示大部分积极的客户同意“轻松设置”、“配合电视工作”,而不太同意“工作出色”。**同样,上述产品的不良评级引发的“云”一词也显示如下。表示大部分客户认同“电池问题”、“糟糕的接收”、“静电干扰”。 从卖家角度看,本产品需要更新“优质电池”、“收货问题”、“静态问题”,以获得客户的积极反馈。

我的区域无线耳机好评中的真知灼见

我的区域无线耳机差评中的真知灼见
哪个评分获得的评论数最高?
顾客对他们在 2000 年至 2014 年期间从亚马逊购买的耳机写了评论,评级从 1 到 5。评级与评论数量的分布和百分比如下所示。与其他评级相比,评级为 5 的评论数量较高。总的来说,顾客对他们购买的产品很满意。大约 50%的顾客给他们购买的产品打了 5 分。只有 15%的顾客给出了低于 3 分的评价。

评分与评论数量

评分分布与评论数量
评级分为两类。低于 3 的评级被分类为“差”,其余的评级被分类为“好”。评级类别与评论数量的分布如下所示。它表明,约有 50000 条评论被评为良好评级。

每个评级类别的审核总数
评级与有用性比率的分布如下所示。这表明所有评级都具有相同的有用性比率。

评级中的有用性
哪个评分获得了最高数量的评论长度?

评分与评论长度
哪一年的评论数最高?
每年的审查总数如下所示。2000 年至 2010 年期间,审查数量较少。2013 年评论数最高。

评分与评论长度
哪一年的客户数量最多?
每年的独立客户总数如下所示。在 2000 年至 2010 年期间,独立客户数量较低。2013 年的客户数量最多。

每年的独特客户
哪一年的产品数量最多?
每年的独特产品总数如下所示。2000 年至 2010 年期间,独特产品的数量很少。2013 年产品数量最多。

每年独特的产品
哪一年的产品数量最高?
除了 2001 年,“良好评级”的百分比超过了 80%。2001 年的整体满意度最低,为 69%。在 2000 年,良好评级的百分比是 90%。从图表中可以看出,耳机产品的总体好评率在 81%到 90%之间。

一段时间内良好评级等级的分布
产品的平均有用性

每个产品的平均有用性分布
评审长度分布

评论长度的分布
哪个评论长度 bin 的好评率最高?
如下图所示,96 %的好评在 0-1000 字之间,而 80%的好评在 1700-1800 字之间。随着审查时间的延长,良好评级会增加。一般来说,写了较长评论(超过 1900 字)的客户往往会给出好的评价。

评论长度与良好评级的分布
哪个评论长度 bin 的有用性比率最高?
从下面可以看出,最高的帮助率在 0-1200 个单词之间,0.8,而最低的帮助率在 1200-1300 个单词之间,0.6。随着审查时间的延长,有用性比率趋于增加。一般来说,写了较长评论(超过 1300 字)的客户往往有较高的有用性比率。

综述长度与有用性比率的分布
有益和无益的审查长度的频率如下所示。它表明,总的有益和无益的比例是相同的较长的审查长度。在小篇幅评论情况下,无用比率较高。

评论长度与有益和无益的分布
获得好评的热门词汇?
下面列出了最常见的 50 个单词,这些单词属于良好评级类别。它展示了顾客对产品的所有好评。

好的评价词
差评热门词汇?
同样,最常见的单词,属于差评类,如下所示。它显示了顾客对产品的所有负面评价。

不良评价词
代码:
数据争论:
EDA:
[## umaraju18/Capstone_project_2
permalink dissolve GitHub 是超过 5000 万开发人员的家园,他们一起工作来托管和审查代码,管理…
github.com](https://github.com/umaraju18/Capstone_project_2/blob/master/code/Amazon-headphones_EDA.ipynb)
第二部分:情感分析和产品推荐
亚马逊电子数据集评论的情感分析和产品推荐——第二部分
第 2 部分:情感分析和产品推荐
情感分析
机器学习模型以数值作为输入。评论是由句子组成的,所以为了从数据中提取模式;我们需要找到一种方法,以机器学习算法可以理解的方式来表示它,即作为一系列数字。
特征抽出
特征工程是使用数据的领域知识来创建使机器学习算法工作的特征的过程。要素本质上通常是数字,可以是绝对数值或分类要素,可以使用一种称为“一键编码”的过程将这些要素编码为列表中每个类别的二进制要素。提取和选择特征的过程既是艺术又是科学,这个过程称为特征提取或特征工程。
作为其中的一部分,单词包模型、TF-IDF、哈希矢量器、Word2Vec 以及将最常见的单词添加到停用词列表、SMOTE、PCA 和截断 SVD 技术作为特征工程和选择的一部分添加到以下部分中的分类模型中。
数据预处理
出于计算方面的考虑,2010 年早些时候评论的 good_rating_class_reviews 超过 150 个单词的功能被删除。最终的数据集由 15000 个观察值组成。从数据集中,“干净文本”和“评级类别”分别被视为“X”(特征)和“Y”(变量)。数据集被分成 75%作为训练,25%作为测试。
机器学习模型
该模型需要根据从亚马逊购买耳机的客户撰写的评论来预测情绪。这是一个有监督的二元分类问题。Python 的 Scikit 库被用来解决这个问题。实现了以下机器学习算法。
逻辑回归
逻辑回归,尽管它的名字,是一个线性模型的分类,而不是回归。逻辑回归在文献中也称为 logit 回归、最大熵分类(MaxEnt)或对数线性分类器。在这个模型中,描述单个试验的可能结果的概率使用逻辑函数建模。
朴素贝叶斯
朴素贝叶斯为多项式分布数据实现了朴素贝叶斯算法,并且是文本分类中使用的两种经典朴素贝叶斯变体之一(其中数据通常表示为词向量计数)。该算法是流行的朴素贝叶斯算法的一个特例,它专门用于我们有两个以上类的预测和分类任务。
随机森林分类器
随机森林是一种元估计器,它在数据集的各个子样本上拟合多个决策树分类器,并使用平均来提高预测精度和控制过拟合。子样本大小始终与原始输入样本大小相同,但如果 bootstrap=True(默认),则使用替换来绘制样本。
XGBoost 分类器
XGBoost 的意思是极端的梯度增强。XGBoost 是一个基于决策树的集成机器学习算法,它使用了一个梯度推进框架。在涉及非结构化数据(图像、文本等)的预测问题中。)人工神经网络往往优于所有其他算法或框架。然而,当涉及到中小型结构化/表格数据时,基于决策树的算法目前被认为是同类最佳的。
CatBoost 分类器
CatBoost 是一种在决策树上进行梯度提升的算法。“CatBoost”名字来源于两个词“Category”和“Boosting”。该库适用于多种类别的数据,如音频、文本、图像,包括历史数据。
评估指标
由于我们的案例中存在数据不平衡,因此必须使用适当的度量来评估分类器的性能,以便考虑类别分布并更多地关注少数类别。基于这一思想,使用 f1 分数作为我的评估标准,f1 分数是精确度和召回率的调和平均值。
理解我们的模型产生的错误类型是很重要的。可视化信息的一个好方法是使用混淆矩阵,它将我们的模型做出的预测与真实标签进行比较。考虑到这一点,除了我们的评估指标(f1 分数)之外,还使用了混淆矩阵。
建模
由于评论的等级不是正态分布的,等级 1-2 被归类为“差”,等级 3-4-5 被归类为“好”。在特征选择方面,使用了最小/最大方向图、主成分分析和奇异值分解的单词出现阈值。对于特征工程,将计数矢量器、TF-IDF、散列矢量器和 Word2Vec 应用于文本数据,以便将文本文档集合转化为数字特征向量。
袋字模型
单词袋模型可能是从文本文档中提取特征的最简单也是最强大的技术之一。这种特定的策略(标记化、计数和规范化)被称为单词袋或“n-grams 袋”表示法。该模型的本质是将文本文档转换成向量,使得每个文档都被转换成表示该特定文档的文档向量空间中存在的所有不同单词的频率的向量。下图显示逻辑回归以 0.896267 胜出。


F1 平均分数
TF-IDF 型号
TF-IDF 代表术语频率-逆文档频率,这是两个指标的组合:术语频率和逆文档频率。为了更多地关注有意义的单词,TF-IDF 得分(术语频率-逆文档频率)被用于我们的单词袋模型之上。TF-IDF 根据单词在我们的数据集中的稀有程度来衡量单词,忽略那些过于频繁并且只会增加噪音的单词。-IDF 的工作方式是通过为这些常用词分配较低的权重来惩罚它们,同时对出现在特定文档的子集中的词给予重视。下图显示 CatBoosting 以 0.896533 分胜出。


F1 平均分数
哈希矢量器
哈希矢量器被设计成尽可能地节省内存。矢量器不是将记号存储为字符串,而是应用哈希技巧将它们编码为数字索引。这种方法的缺点是,一旦矢量化,就无法再检索要素的名称。下图显示 CatBoosting 以 0.894133 分胜出。


F1 平均分数
将最常用和最不常用的词添加到停用词表(计数矢量器)
因为在不同的类中没有太多不同的词,所以应用添加到停用词列表和模型中的最常见和最不常见的 70 个词,以便查看评估度量中的任何变化。下图显示 CatBoosting 以 0.890133 分胜出。将最常用和最不常用的单词添加到停用词表中对模型的性能没有影响。


F1 平均分数
应用 Word2Vec 和简单神经网络
我们使用 Word2Vec 创建了单词向量,该模型有 26548 个唯一的单词,其中每个单词的向量长度为 100。然后我们在一个简单的神经网络中使用这些密集的向量——单词嵌入——来进行预测。在训练和验证准确度图中,模型在第一个时期后开始过度拟合。这个简单神经网络的精度是 0.7992。


上面给出了在用 t-SNE 将感兴趣的单词和它们的相似单词的维数减少到 2-D 空间之后,使用它们的嵌入向量对它们进行可视化。也可以查看基于 gensim 模型的类似单词。
产品推荐
直到最近,人们通常倾向于购买朋友或信任的人推荐给他们的产品。这曾经是对产品有任何疑问时的主要购买方法。但随着数字时代的到来,这个圈子已经扩大到包括利用某种推荐引擎的在线网站。
推荐引擎使用不同的算法过滤数据,并向用户推荐最相关的项目。它首先捕捉客户过去的行为,并在此基础上推荐用户可能会购买的产品。
如果我们能够根据客户的需求和兴趣向他们推荐一些商品,这将对用户体验产生积极的影响,并导致频繁的访问。因此,现在的企业正在通过研究用户过去的行为来构建智能的推荐引擎。使用项目-项目协同过滤。
数据处理
在将电子评级数据集与产品元数据合并后,空值将从数据集中删除。总特征是 7530925。最终数据集如下所示。

产品推荐的最终数据集
项目-项目协同过滤
当用户数量多于推荐的项目时,这种协作过滤是有用的。用户数(4053964)大于项目数(469625)。
在该过滤中,计算每个项目对之间的相似度,并基于该相似度推荐用户过去喜欢的相似项目。采用“项目用户”评级的加权总和。基于项目的过滤过程如下所示。

作者绘图。来自 Unsplash 的免费图片
用户评分总和排名前十的热门产品

按用户评分总和列出的十大热门产品
产品推荐

产品推荐
结论
使用计数向量、TF-IDF、散列向量、Word2Vec、分类模型和简单神经网络,并向 CountVect 添加最常用和最不常用的词,来预测基于顾客留下的评论的评级分数。从分析中发现,具有 TF-IDF 的 CatBoosting 得分为 0.890586)或具有计数矢量化的 Logistic 回归(f1 得分为 0.899891)是最佳模型。将最常用和最不常用的单词添加到停用词表中并不会对模型的性能产生影响。
代码:
情感分析:
推荐系统:
第一部分:探索性数据分析
情绪分析和股票市场:一个新的巴西故事?
尽管规模很小,但巴西 Fintwit 增长迅速,引发了人们对巴西股市泡沫的担忧。

来自《走向数据科学》编辑的提示: 虽然我们允许独立作者根据我们的 规则和指导方针 发表文章,但我们并不认可每个作者的贡献。你不应该在没有寻求专业建议的情况下依赖一个作者的作品。详见我们的 读者术语 。
巴西经济最近的周期性变化导致大量个人进入股票市场。由于该国的历史高利率,这些投资者习惯于将资金投资于政府债券或储蓄账户,但是,一旦通胀自 2016 年以来似乎得到控制,随着央行降低基本利率(即 SELIC),低风险投资的回报开始受到影响。
正如我们在下图中看到的,LTN 债券的年回报率曾经超过 10%,但目前的名义收益率不超过 6%。

LTN 自 2002 年起放弃申办
随着巴西投资者开始寻找新的替代投资方式,Ibovespa(巴西市场的主要指数)开始无情地上涨,直到最近冠状病毒爆发。正如我们在下图中看到的,在冠状病毒爆发后,巴西股市跟随世界其他市场的趋势,恢复得非常快。

Ibovespa 指数(2016–2020)
尽管目前尚不清楚价格是否会回到 2019 年 12 月的水平,但许多基金经理已经提出了资产价格可能已经过高的可能性,因为这一运动涉及巴西投资者资源的重新分配。无论如何,其中一位经理最近提出了一种可能性,即巴西的 fintwit 社区可能会引发查尔斯·金德尔伯格(Charles Kindleberger)所说的“欣快症”——为股市泡沫铺平道路。这真的会发生吗?
本文的目标是评估这种可能性,首先提供该社区规模的概述。最后,应用情感分析算法,了解这些推文中的观点是否在总体上保持平衡趋势。重要提示:我们不打算分析这些观点最终是推动市场,还是受市场影响。而仅仅是为了了解这些观点是否过于积极,以这种方式营造出一种欣快的氛围。这样,我不仅会使用 tweets,还会使用 retweets,因为这让我们更清楚地知道有多少人可能会查看这些信息。
当然,我们的第一步是收集推文。我不打算对此进行过多的探讨,因为这里有无数的文本在讨论不同的程序和技术。对于这个分析,我将使用 R 和 twitteR 包。这个包有一个限制:我们不能收集超过七天的推文。尽管有这个限制,让我们看看这个短时间范围能告诉我们什么。我搜索的术语是:
- IBOVESPA
- 投资
- Ibov
- Ibovespa 指数中的所有资产(76 项资产)
因此,我们的时间范围和搜索的术语如下所示:
setup_twitter_oauth(consumerKey, consumerSecret,
access_token = accessToken,
access_secret = accessTokenSecret)#Collect the tweets into lists
list1 <- searchTwitter('Ibovespa',n=10000, lang="pt",
since='2020-08-26', until ='2020-09-03')
list2 <- searchTwitter('Investimento', n=10000, lang="pt",
since='2020-08-26', until ='2020-09-03')
list3 <- searchTwitter('Ibov', n=10000, lang="pt",
since='2020-08-26', until ='2020-09-03')
list4 <- searchTwitter(list_of_assets, n=10000, lang="pt",
since='2020-08-26', until ='2020-09-03')#Concatenate them
list_ <- c(list1, list2, list3, list4)#Create a df from the list_assets
df_assets <- twListToDF(list_assets)
df_assets <- df_ativos[, order(names(df_assets))]
df_assets$created <- strftime(df_assets$created, '%Y-%m-%d')
有了我们的 df,我们可以看到每天有多少 tweets 是用搜索词生成的。首先,我不会考虑 RTs,正如我们在下图中看到的,图表显示,每天人们可以在 Twitter 上找到至少 1400 条关于这些术语的推文,我认为这是很重要的,因为尽管巴西股市最近有所扩张,但它仍然高度集中。因此,能够在 Twitter 上生成内容或单独发表观点的用户数量非常少。
#Df with number of tweets each day
df_q <- data.frame(df_assets %>% count(created))
ggplot(df_q, aes(created, n)) +
geom_bar(stat = "identity", color="black", fill=rgb(0.1,0.4,0.5,0.7)) +
labs(y="# of Tweets", x = "Date of the Tweets")

每天的推文
所有这 22,000 条推文都是由大约 5,000 名用户创建的,这意味着在此期间,每个用户都发了 4 次关于这些主题的推文。但是我们忽略了一些东西:有多少用户真正加入了这个社区。虽然不可能说有多少其他用户看到了这些推文,但我们可以评估他们的参与度。我们可以很容易地看到波纹管。“favoriteCount”变量的平均值为 14,547,retweetCount 的平均值为 1,437。这就是为什么我们可以说,参与度并不真正重要:每天 1400 条推文中的每一条,平均来说,都不会超过 10 个 Favs 和 1 个 Rt。
#Df with sum of favs and rts for each tweet per day
df_favs <- aggregate(favoriteCount ~ created, df_assets, sum)
df_rts <- aggregate(retweetCount ~ created, df_assets, sum)
df_interac <- merge(df_favs, df_rts)df_interac2 <- melt(df_interac)ggplot(df_interac2, aes(x=created, y=value, fill=variable)) +
geom_bar(stat='identity', position='dodge') +
labs(y="#", x = "Date of the Tweets")

每天的交互(Favs 和 Rts)
在我们的样本中,这种参与是由 11,700 个独立用户产生的,仅占当前投资者总数的 0.44%。这并不真正具有代表性,但我们至少可以说,在这个社交网络中真的有一种欣快感,最终可能会影响股票市场吗?为了进行分析,我们需要一个函数,它能够根据之前选择的正面和负面单词来确定每个文本的得分。
#Positive and Negative Word
pos <- scan('positive_words.txt', what='character', comment.char=';')
neg <- scan('negative_words.txt', what='character', comment.char=';')#Sentiment score model
score.sentiment <- function(sentences, pos.words, neg.words){
scores <- laply(sentences, function(sentence, pos, neg){
sentence <- gsub('[[:punct:]]', "", sentence)
sentence <- gsub('[[:cntrl:]]', "", sentence)
sentence <- gsub('\\d+', "", sentence)
sentence <- str_replace_all(sentence, "[^[:alnum:]]", " ")
sentence <- tolower(sentence)
word.list <- str_split(sentence, '\\s+')
words <- unlist(word.list)
pos.matches <- match(words, pos.words)
neg.matches <- match(words, neg.words)
pos.matches <- !is.na(pos.matches)
neg.matches <- !is.na(neg.matches)
score <- sum(pos.matches) - sum(neg.matches)
return(score)
}, pos.words, neg.words)
scores.df <- data.frame(score=scores, text=sentences)
return(scores.df)
}#Applying the model to the dataset
Dataset <- df_assets
Dataset$text <- as.factor(Dataset$stripped_text)
scores <- score.sentiment(Dataset$stripped_text, pos.words, neg.words)stat <- scores
stat$created <- stripped_text$created
stat$created <- as.Date(stat$created)
stat <- mutate(stat, tweet=ifelse(stat$score > 0, 'positive',
ifelse(stat$score < 0, 'negative', 'neutral')))
by.tweet <- group_by(stat, tweet, created)
by.tweet <- summarise(by.tweet, number=n())ggplot(by.tweet, aes(created, number)) + geom_line(aes(group=tweet, color=tweet), size=1) +
geom_point(aes(group=tweet, color=tweet), size=4) +
labs(y="# of Tweets", x = "Date of the Tweets")
theme(text = element_text(size=10), axis.text.x = element_text(angle=90, vjust=1)) +
ggtitle('cted tweets: FintwitBr')
该图向我们展示了 3 种类型的类别,它们是正面的(得分> 1),负面的(得分<1) and neutral. At least in our sample, there is clear evidence that tweets are likely to be more positive than negative. And the proportion changed significantly on August 28th and September 1st. But, since the community is not representative in relation to the market as a whole, it would be an exaggeration to claim that the euphoria on Twitter is impacting the market.

Sentiment Analysis
That doesn’t mean that there isn’t something happening in the Brazilian stock market; I really think it is. It just means that, for the moment, there is a little bit of alarmism — and with some reason. Especially because, when Robert Shiller warned the market about the irrational exuberance that could bring the financial market to a breakdown in his 2005 book, nobody took him seriously. I mean, nowadays you can find several profiles, either on Twitter, YouTube or Instagram talking about investments, for an audience that until the last few years used to see this as something no more than obscurantism.
¹ You can find Charles Kindleberger’s book in Portuguese ( Manias,p nicos e Crises:Uma históRIA das catástrofes econ micas mundiais)或英文( Manias,Panics,and Crashes:A History of Financial crisis)。
AWS 理解的情感分析和实体提取
在 Python 中使用 AWS Lambda、Boto3 和 understand 执行高级 NLP 任务的快速概述

图片来自 Unsplash
介绍
亚马逊网络服务(AWS)一直在不断扩展其在各个领域的机器学习服务。 AWS 领悟是自然语言处理的 AWS 发电站( NLP )。NLP 中常见的两个项目有情感分析和实体提取。我们经常使用 NLTK、Spacy、Transformers 等库从头开始构建定制模型**。虽然定制模型肯定有它们的用途,并且当你对你要解决的问题有领域知识时表现得特别好,但是从头开始构建它们也是非常耗时的。这就是 AWS intensive 的用武之地,它为情感分析和其他 NLP 任务提供高级服务。对于本文,我们将使用理解进行情感分析和实体检测。为了通过 AWS understand 访问这些服务,我们使用了另一个名为 AWS Lambda 的 AWS 服务。Lambda 是一个无服务器的计算平台,允许你通过 Boto3 、Python**T21 的 AWS SDK 调用这些服务。我将提供一个我们将要使用的服务列表,并在此广告之后提供更深入的定义,但是如果您已经熟悉这些服务,可以随意跳到情感分析&实体提取的代码演示。****
目录
- AWS 服务
- 带有 AWS 理解的情感分析
- AWS 综合实体检测
- 代码和结论
AWS 服务
AWS 领悟 : AWS NLP 服务,使用 ML 来执行诸如情感分析、实体提取、主题建模等任务。对于这个例子,我们只探索其中的两个任务。
[## 亚马逊理解-自然语言处理(NLP)和机器学习(ML)
发现文本中的见解和关系亚马逊理解是一种自然语言处理(NLP)服务,使用…
aws.amazon.com](https://aws.amazon.com/comprehend/)
AWS Lambda:一种无服务器计算服务,允许开发人员在不管理或供应服务器的情况下运行代码。
[## AWS Lambda -无服务器计算-亚马逊网络服务
运行代码时不考虑服务器。只为您消耗的计算时间付费。AWS Lambda 让你运行代码…
aws.amazon.com](https://aws.amazon.com/lambda/)
Boto3 :针对 Python 开发者的 AWS 软件开发工具包(SDK),可以在你的 Lambda 函数中使用这个来调用领悟 API 及其特定服务。
[## Boto3 文档- Boto3 文档 1.16.6 文档
Boto 是 Python 的 Amazon Web Services (AWS) SDK。它使 Python 开发人员能够创建、配置和管理 AWS…
boto3.amazonaws.com](https://boto3.amazonaws.com/v1/documentation/api/latest/index.html)
AWS SageMaker :允许构建、培训和部署定制的 ML 模型。还包括各种预训练的 AWS 模型,可用于特定任务。
Amazon SageMaker 是一个完全托管的服务,为每个开发人员和数据科学家提供构建…
aws.amazon.com](https://aws.amazon.com/sagemaker/)
带有 AWS 理解的情感分析
数据
您可以通过多种方式在 AWS 中访问数据。 S3 是大多数开发人员最受欢迎的数据存储选择,它最常用于实时项目或大型数据集。然而,由于我们所拥有的只是一个基本的例子,我们将使用几个 JSON 格式的文本句子供我们的 AWS Lambda 函数访问。
例如数据
情感分析的代码和解释
一旦您通过 JSON、S3 或您正在使用的任何存储格式提取了数据,就该见识一下 understand 的魔力了。在将近 5 行代码中,定制模型构建和调优中所做的脏工作被处理掉了。您必须输入的两个参数是您正在分析的文本和您的文本所在的语言**。正如您在下面的结果中看到的,返回了一个总体情绪正面、负面或中性,以及这些情绪各自的百分比**。****
从 JSON 和情感分析中提取数据

情感分析呼叫的结果(作者截图)。
使用detect _ 情操调用需要注意的一个关键点是文本字符串不能大于 UTF-8 编码字符的 5000 字节**。当处理较大的文档或字符串时,可以使用batch _ detect _ perspection调用来解决这个问题,这允许最多 25 个字符串/文档都以 5000 字节为上限。批处理调用中的过程也非常相似,但是根据您的具体用例,您可以弄清楚如何为批处理调用预处理/分割数据。**
基于 AWS 理解的实体提取
与情感分析调用类似,detect_entities 调用接受文本输入和文本语言中的两个参数。定制模型还有第三个参数,使用端点 ARN 来访问您为实体提取创建的模型,而不是默认的理解模型。正如您在下面的结果中看到的,调用返回了它在检测中的置信度、实体的类型、被识别为实体的文本以及文本的位置。例如,我们在实体的位置类型中看到纽约和弗吉尼亚。****
代码和解释实体提取
实体检测代码

实体检测调用的结果(作者截图)。
与 detect _ opposition 类似,detect_entities 不能接受大于 5000 字节的 UTF-8 编码字符的字符串。幸运的是,我们还有一个 batch_detect_entities 调用,它也允许最多 25 个字符串/文档都限制在 5000 字节。
整个代码和结论
** [## RamVegiraju/comprehende demo
使用 AWS 理解进行情感分析和实体提取的代码演示 GitHub 拥有超过 5000 万…
github.com](https://github.com/RamVegiraju/ComprehendDemo)
Boto3 与 AWS intensive 配合使用,可以让非 ML 工程师或数据科学家轻松完成许多通常需要几个小时的任务。当然,如果给定领域知识和分析问题的时间,定制模型将执行得更准确,但是 understand 消除了预处理、清理、构建和训练您自己的模型所花费的大量时间。对于那些对在 NLP 或 ML 的任何其他领域中构建定制模型感兴趣的人来说, AWS SageMaker 允许您在 Jupyter 笔记本环境和更加传统的 ML 工作流中构建、训练和部署您自己的模型。
我希望这篇文章对试图使用 AWS 服务和 NLP 的人有用。如果您对 ML &数据科学感兴趣,请随时在评论中留下任何反馈或通过 Linkedln 与我联系。感谢您的阅读!**

















 874
874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}