






文章题目:Strategies for tailoring functional microbial synthetic communities
期刊:The ISME Journal
影响因子:10.8
发表时间:2024
关键词:
合成群落、微生物生态学、微生物功能、生物信息学、高通量筛选参考文献:Jiayi Jing, Paolina Garbeva, Jos M Raaijmakers, Marnix H Medema, Strategies for tailoring functional microbial synthetic communities, The ISME Journal, Volume 18, Issue 1, January 2024, wrae049, https://doi.org/10.1093/ismejo/wrae049
研究背景:
土壤和植物是众多对生态系统服务至关重要的微生物的栖息地,包括污染物降解、生物地球化学循环以及支持植物生长与健康等。微生物组的研究得益于无培养测序技术和生物信息学工具的发展,但要揭示特定微生物组的功能及其与宿主间的复杂互动仍需结合实验方法进行验证。
研究目的:
该研究旨在回顾设计功能性微生物合成群落 (SynComs)的最新研究,揭示共同原则,并讨论多维度的设计策略。通过整合高通量实验分析与计算基因组分析的方法来提出一种基于微生物菌株的功能能力设计SynComs的新策略。
科学问题
1、如何选择代表性的微生物以简化自然微生物群落的复杂性,并根据其功能特性设计合成微生物群落?
2、如何利用计算和实验方法预测并验证这些合成群落在提供特定生态系统服务中的效能?
实验材料与方法
1、使用基于分类学或功能特征的方法设计简化的SynComs。
2、利用计算基因组学工具如antiSMASH、MacSyFinder等预测次生代谢产物生物合成能力。
3、应用基因组尺度代谢网络模型(GSMM)预测微生物间代谢交互作用。
4、结合机器学习算法优化SynCom设计,并通过实验室实验验证预测结果。
结果与讨论
1、SynComs 的设计策略
SynComs 的设计不再仅仅基于分类学,而是越来越多地涉及选择符合以下条件的微生物组成员:(i) 在体外或体内表现出积极或消极的相互作用,(ii) 具有特定的功能特征,和/或 (iii) 具有互补/相似的生态位偏好。然而,整合微生物相互作用、功能特性和生态位偏好等标准会带来复杂性,需要全面的实验验证和复杂的分析。尽管存在这些挑战,但这种多方面的方法可以增强 SynCom 的功能,使 SynCom 的定制设计具有更高的弹性。
2、SynCom 设计的生物活性微生物或功能基因的优先级
对于基于功能的 SynCom 设计策略,可以考虑各种基因组特征。此类性状包括 CAZymes、分泌系统、抗真菌代谢物、金属团、生物膜形成相关胞外多糖、植物免疫刺激代谢物、植物激素等。2018 年开发了一个采用功能数据进行 SynCom 设计的计算框架,通过自上而下的宏基因组、代谢组学和表型数据集集成来运行,从而能够更可靠地识别假定的机制关联。了解每个群落成员所占据的空间分布和生态位也是恢复后保持稳定群落结构的重要因素。不同的生态建模方法,包括Lotka-Volterra模型、消费者资源模型、基于性状的模型、基于个体的模型以及基因组规模的代谢网络模型,可用于生态位预测
3、基于特征的 SynCom 设计的计算方法
最近开发了许多创新的计算方法,以解决基于海量(元)基因组学数据定制 SynCom 设计的挑战,包括优先考虑最相关的微生物相互作用、识别关键(生态)功能特征以及优化计算机功能群落组成。如antiSMASH、MacSyFinder、PHI-base等工具,用于预测次生代谢物生物合成能力、检测大分子系统和病原性。基因组尺度代谢网络模型(GSMM)有助于预测微生物间代谢交互作用,并支持通过计算机模拟优化SynCom的设计。
4、用于 SynCom 设计的人工智能
机器学习 (ML) 和人工智能 (AI) 越来越多地用于 SynCom 的(迭代)实验优化,因为它们可以帮助导航分类群和函数的高维组合空间。例如,BacterAI 是一种新颖的自动化科学平台,它允许设计和使用实验平台生成生长数据作为“奖励”数据集,以进一步优化模型以改进实验设计。微生物代谢活性预测是通过主动学习迭代设计而有效地生成的,无需先验知识
5、影响SynComs重组的方面
在重构过程的不同阶段通过低通宏基因组测序、qPCR 数据或荧光标记物监测群落组成和结构稳定性的必要性。不同的生态模型如Lotka–Volterra模型、消费者资源模型、基于性状的模型以及个体基础模型被用于预测各成员在群落中的生态位。这有助于设计能够稳定存在的SynCom。例如,利用环境相关底物的利用情况来预测潜在的代谢生态位,可以用来推断微生物间的竞争或合TbasCO等新型工具专注于表达代谢基因,提供了增强的时间分辨率,从而更准确地捕捉随时间变化的生态位分化特征。 6、Syncom 设计的协同生物信息学和高通量验证
未来,为 SynCom 相关数据集构建数据库并基于与不同宿主和表型相关的大量 SynCom 数据集探索相关性以识别跨实验室的基因型-表型模式可能是可行的。总体而言,我们提出的概念工作流程通过整合来自体外和体内分析的多维数据信息以及计算预测,为 SynComs 的设计提供了不同的视角。我们预计这将加速 SynComs 在即将到来的微生物生态学研究时代作为有力实验工具的采用。
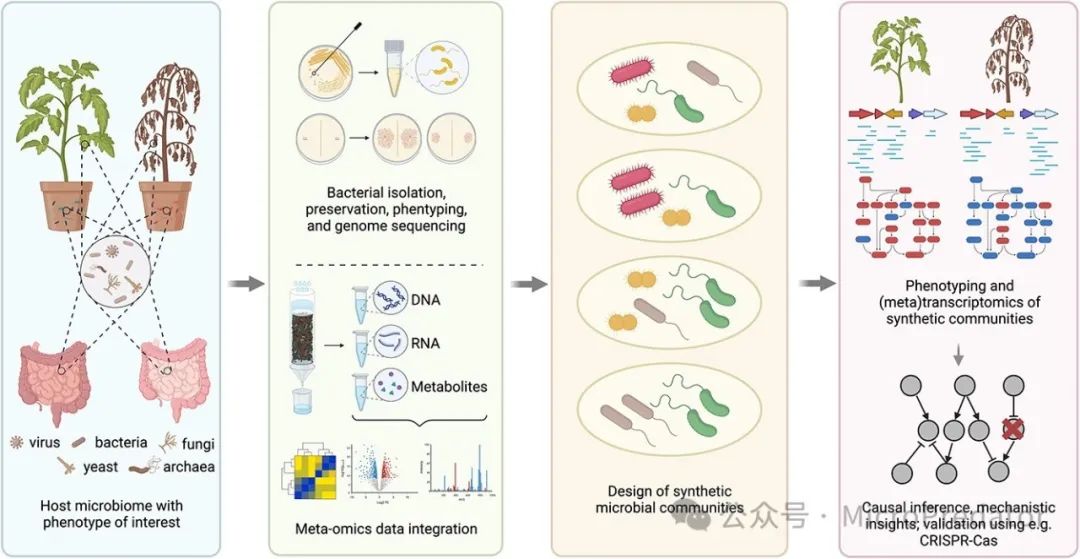
图1:设计合成微生物群落以揭示微生物组相关表型的重要性。通常从具有目标表型的宿主开始,使用组学数据和/或表型测定分离和表征细菌菌株。基于分类学或功能特性,设计了群落复杂性降低的合成微生物群落,可用于研究所研究表型的机制决定因素。
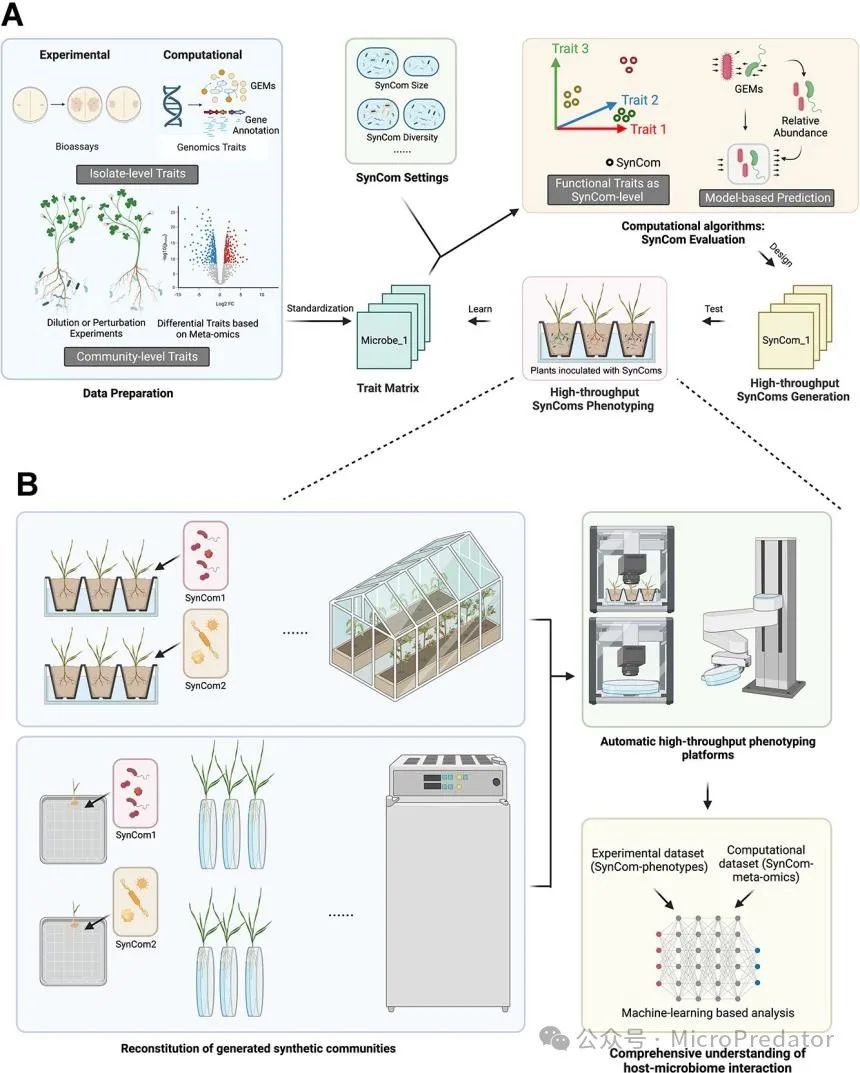
图2:SynCom 设计的概念性工作流程。(a) 计算高通量 SynCom 设计和验证。分离株和群落水平的功能性状将首先通过实验/计算策略来识别。然后,生成的特征矩阵将用于高吞吐量 SynCom 生成和验证,使用迭代设计-测试-学习循环。(b) 高通量 SynCom 筛选和基于 ML 的分析。生成的 SynComs 将使用自动化高通量表型平台进行重组和表型筛选。观察到的表型数据集以及相关的元组学,即根际元转录组学数据,可用作基于 ML 的分析的(扩展)训练数据,以增强对宿主-微生物组相互作用的理解,并设计越来越有效和稳定的 SynComs。

















 985
985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









