








我们都是穷尽自己仅有的一点天赋,来表达我们内心深处的感受。–乔布斯
闲谈
对问题/知识理解的深度和广度,哪个更重要?
如果一定要选一个,我会选深度。但是我常常做不到对某一东西的深刻专研,总是会被新的东西吸引,而后又忘记了原本的计划。对问题/知识的大概了解,也让我做什么都没有底气,有时又有一点不屑。嗯,我已经知道这个了。其实我只是了解了一点点东西,从此往复,我还是那个小菜鸟。我想让自己改变。钻研一件事并从头到尾的从计划到交付的一段经历,可以让你之后的旅程,尤其是你陷入一些困境的时候,给你去完成那些困住你的事情,走出泥沼的信心。了解很多事情的表面,是很难给你这样的底气的。然后,从深度到广度,可能比从广度到深度要相对容易。
不是说广度不重要,保持开放的视野,可以迅速的连接不同的资源也很有用。但能给予自己不断向前的信心的,更多的还是要靠你对这件事情的理解和对事情的掌控力。
我总是很在意别人怎样了,而自己呢?
这里借助人民日报夜读里的一句话,给自己一缕阳光,也给有同样困惑的小可爱们一点动力。每个人都有属于自己的‘时区’,有些人走在你前面,也有人跟在你后面,其实没有成败之分,在属于自己的‘时区’里,只要今天的你总是优于过去的你,何尝不是成功?
SINet
Camouflaged Object Detection
代码
他们在推出其COD10K数据集同时提出了一种简单但是有效的解决COD的网络SINet。COD10K同时具有大类和子类的分类,包含了大量全高清1080p图片,与此同时,检测目标的全局和局部对比度更加广,意味着对模型的泛化性要求更高,更难检测,是一不错的COD数据集。他们也将COD10K与已有的COD任务数据集做了对比,以此来佐证COD10K的优势。
SINET网络整体的架构还是属于encoder-decoder的,其特点,结尾输出的loss有两个。第一个loss是用来衡量原图中有没有伪装物的,第二个loss是用来衡量模型预测的伪装物的位置准不准的,也是一个不错的想法。
伪装检测系统 (CDS) 具有多种可能的应用。
- 医学图像分割。如果医学图像分割方法配备了针对特定对象(例如息肉)训练的CDS,则它可以用于自动分割息肉。在自然界中寻找和保护稀有物种,甚至在灾区进行搜救。
- 搜索引擎。搜索引擎无法检测到隐藏的蝴蝶,因此只能提供具有相似背景的图像。当搜索引擎配备了CDS(这里,我们只是简单地更改关键字)时,引擎可以识别出伪装对象,然后反馈几张蝴蝶图像。

COD与当前数据集有所不同:
- 它包含10K图像,涵盖78个被伪装的对象类别,例如水生,飞行,两栖动物和陆生等。
- 所有被伪装的图像均按类别,范围和等级进行注释。框,对象级别和实例级别的标签,从而促进了许多视觉任务,例如本地化,对象提议,语义边缘检测,任务转移学习等。
- 每个伪装的图像都被赋予了挑战性,可以在现实世界和消光等级标签中找到属性(每张图像大约需要60分钟)。
结构可分为Search Module和Identification Module两部分,即先对图片中的伪装目标对象进行搜索(Search),然后对所有搜集到的的目标对象进行身份确(Identification)。
SINet可分为两个部分:
感受野组件(Receptive Field)和部分解码器组件(PDC)。
在人类视觉中,存在一组有各种大小的感受野,有助于突出靠近视网膜中央凹的区域,该区域对微小的空间位移十分敏感。借鉴于此,该论文设计了RF模块在搜索阶段获得更多更具区分性的特征。首先,我们通过ResNet-50从输入图像中获取5个特征。
SINet利用密集连接的来保存来自不同层的更多信息,然后使用RF组件来扩大感受野。
由于注意力机制可以有效地消除无关特征的干扰。
本文又引入了搜索注意(Search Attention,SA)模块来增强X2的中层特征并获得增强的伪装图。
SINetV2–改进版
这篇文章是SINet的改进版,网络结构变化改进了很多,效果提升还不错。

SINet模型包括搜索的前两个阶段,即搜索(负责搜索隐藏对象)和识别(用于以级联方式精确检测隐藏对象)。
与上个版本相比,通过两个精心设计的子模块在COD领域实现了新的SOTA,包括邻居连接解码器(NCD)和组反转注意(GRA)。
三个主要模块:
- 纹理增强模块(TEM),用于捕获具有放大上下文线索的细粒度纹理;
- 邻居连接解码器(NCD),能够提供位置信息;
- 级联组反转注意(GRA)块,它们协同工作以改进来自更深层的粗略预测。
纹理增强模块(TEM)
在人类视觉系统中,一组不同大小的人群感受野有助于突出靠近视网膜中央凹的区域,该区域对小空间位移敏感。这促使我们在搜索阶段(通常在小/局部空间中)使用TEM来合并更具辨别力的特征表示。
第一个卷积层利用1×1卷积操作(Conv1×1)将通道大小减少到32。接下来是另外两个层:一个(2i-1)×(2i-1)卷积层和一个3×3卷积层,当i >1时具有特定的膨胀率(2i-1)。
然后,将前四个分支{bi,i=1,2,3,4}连接起来,并通过3×3卷积操作将通道大小减小到C。网络的默认设置C =32。最后,加入恒等shortcut分支,然后将整个模块馈送到ReLU函数以获得输出特征f’k。此外,一些工作(例如,Inception-V3)已经表明,大小为(2i-1)×(2i-1)的标准卷积运算可以分解为两个步骤的序列,其中(2i-1)×1和1×(2i-1),在不降低表示能力的情况下加快推理效率。
邻居连接解码器(NCD)
仅聚合前三个最高级别的特征{fk∈RW /2k×H/2k×C,k=3,4,5})以获得更有效的学习能力,而不是考虑所有特征金字塔。具体来说,在获得前三个TEMs的候选特征后,在搜索阶段,我们需要定位隐藏物体。
使用邻居连接解码器(NCD),解决聚合多个特征金字塔时仍然存在两个关键问题;即,如何保持层内的语义一致性以及如何跨层桥接上下文。
Group-Reversal Attention(GRA)

组合多个GRA块(例如,Gki,i∈{1,2,3},k∈{3,4,5})以通过不同的特征金字塔逐步细化粗略预测。总体而言,每个GRA块都有三个残差学习过程。详细请看论文。
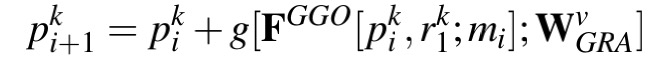


实验效果
直接上图,就不多说了


应用:医学(息肉分割和肺部感染分割)、制造业(表面缺陷检测)、农业(有害生物检测和水果成熟度检测)、艺术(休闲艺术和从隐蔽的物体到显眼的物体)、日常生活(透明物品/物体检测、搜索引擎)
潜在的研究方向:
1、弱/半监督学习
现有的基于深度的方法以完全监督的方式从带有对象级标签的图像中提取特征。但是,像素级标注通常由LabelMe或Adobe Photoshop工具手动标记,具有密集的专业交互,要耗费大量的精力。因此,必须利用弱/半(部分)标注数据进行训练,以避免巨大的标注成本。
2、自监督学习
3、其他模态的伪装目标检测
现有的伪装数据仅基于静态图像或动态视频。然而,其他形式的伪装对象检测可能与诸如黑夜害虫监测、机器人和艺术家设计等领域密切相关。与RGB-D SOD、RGB-T SOD和VSOD中的类似,这些模式可以是音频、热或深度数据,在特定场景下提出了新的挑战。
4、伪装目标分类
通用目标分类是计算机视觉中的一项基本任务。因此,隐蔽对象分类在未来也可能获得关注。利用COD10K提供的类和子类标签,可以构建大规模、细粒度的分类任务。
5、伪装目标跟踪
6、伪装对象排序
目前,伪装目标检测算法都是建立在二值化的基础上,生成伪装目标的掩模,而不分析伪装程度。然而,了解伪装的程度有助于更好地探索模型背后的机制,提供对它们的更深层次的洞察力。
7、伪装对象实例分割
8、多任务通用网络
不同的视觉任务之间有很强的联系。因此,它们的监管可以在一个通用系统中重用,而不会增加复杂性。考虑设计一个通用网络来同时定位、分割和排序隐藏对象是很自然的。
9、神经网络搜索
无论是传统算法还是基于深度学习的隐蔽目标检测模型,都需要具有强大先验知识或熟练专业知识的人类专家。有时,由算法工程师设计的手工制作的功能和体系结构可能不是最优的。因此,神经结构搜索技术,如流行的自动机器学习,提供了一个潜在的方向。
10、将突出对象转换为隐藏对象
将显著对象转换为隐藏对象以增加训练数据,以及在SOD和COD任务之间引入生成性对抗机制以提高网络的特征提取能力。
这让我想到了ResNext是ResNet的改进版,但感觉用得ResNext没有ResNet多呢?
这是因为RestNet太经典了,大家都都知道它,人们都以它为标准(属于它类型的),一般来说如果任何人弄一个网络算法出来不以那些经典算法比较是难被认可的。即使后来的人改进ResNet且针对其不足有了很大的突破也无济于事。所以对于初学者,要将那些经典算法弄通能跑出来,今后开发的算法也要做这些比较。
所以要多读文章,从一好文章找它的经典读然后再读它近期的改进文章,但要多重现好文章的算法实验。

















 1679
1679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











