







文本到图像生成在扩散模型的出现下取得了显著进展。然而,基于文本生成街景图像仍然是一项困难的任务,主要是因为街景的道路拓扑复杂,交通状况多样,天气情况各异,这使得传统的文本到图像模型难以处理。为了解决这些挑战,今天给大家分享一个新颖的可控文本到图像框架,名为Text2Street。在该框架中,首先引入了基于车道的道路拓扑生成器,通过计数适配器实现文本到地图的生成,具有准确的道路结构和车道线,实现可控道路拓扑生成。然后,提出了基于位置的目标布局生成器,通过目标级边界框扩散策略获得文本到布局的生成,实现可控交通目标布局生成。最后,设计了多控制图像生成器,将道路拓扑、目标布局和天气描述集成在一起,实现可控街景图像生成。大量实验表明,所提出的方法实现了可控的街景文本到图像生成,并验证了Text2Street框架在街景中的有效性。
1. 介绍
文本到图像生成,作为计算机视觉的一个重要任务,旨在仅基于文本描述生成连贯的图像。近年来,针对常见场景(如人物和目标)的文本到图像生成已经付出了很多努力。特别是随着扩散模型的出现,取得了显著进展。然而,在专业领域生成图像同样具有重要价值,包括自动驾驶、医学图像分析、机器人感知等。对于街景的文本到图像生成在自动驾驶感知和地图构建的数据生成方面具有特殊重要性,但目前仍相对未被充分探索。
街景文本到图像生成作为一个尚未充分开发的任务,面临着几个严峻的挑战,可以分为三个主要方面。
首先,生成符合交通规则的道路拓扑结构是一个挑战。一方面,如下图1(a)所示,从文本-图像对中学习道路结构受限于图像中不完整的道路结构信息,这是由于有限的成像角度和频繁的遮挡所导致的。这种复杂性使得在nuScenes数据集上微调的稳定扩散模型难以生成预期的图像。另一方面,如下图1(b)所示,生成符合交通规则且与文本中指定的车道线数量相匹配的车道线也是一个极具挑战性的任务。
第二,交通状态的表示是街景图像中的一个关键元素,通常通过存在的交通目标数量来实现。然而,使用当前模型生成指定数量的交通目标并遵循运动规则经常无法达到预期。如下图1(c)所示,现有方法往往缺乏对精确数字要求的敏感性。例如,尽管我们的目标是生成一个有两辆车的道路场景,但稳定扩散模型的实际输出往往包括数量明显更多的车辆。
最后,天气条件通常取决于场景内容,基于这些条件直接生成图像往往会产生模糊或次优结果,如下图1(d)所示。由于存在这三个挑战,街景文本到图像生成是计算机视觉中一项具有挑战性的任务。

为了解决前面提到的挑战,本文提出了一种新颖的用于街景的可控文本到图像框架,称为Text2Street,如图2所示。
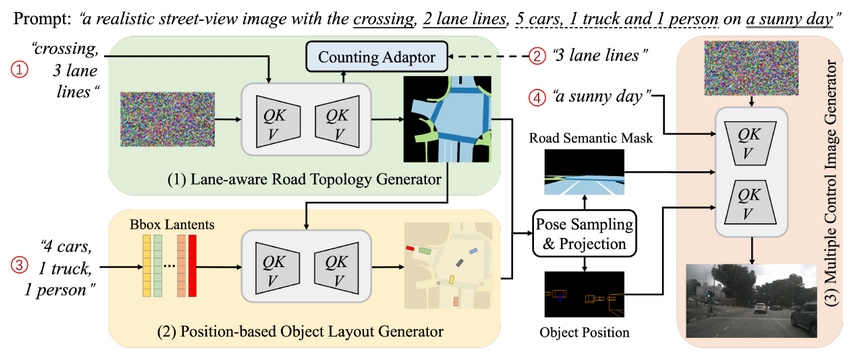
在这个框架内,首先引入了基于车道的道路拓扑生成器,利用文本描述创建表示复杂道路拓扑的局部语义地图。该生成器还通过计数适配器在语义地图内生成符合指定数量和交通规则的车道线。随后引入了基于位置的目标布局生成器,以捕获多样化的交通状态。通过采用目标级边界框扩散策略,它根据文本描述生成符合指定数量和交通规则的交通目标布局。最后,通过姿态采样,将道路拓扑和目标布局投影到相机的成像视角中。通过多控制图像生成器将投影的道路拓扑、目标布局和文本天气描述集成在一起,生成最终的街景图像。实验验证证实了我们提出的方法从文本输入生成街景图像的有效性。
本文的主要贡献如下:
-
提出了一种新颖的用于街景的可控文本到图像框架,仅基于文本描述实现了对道路拓扑、交通状态和天气条件的控制。
-
引入了基于车道的道路拓扑生成器,能够生成特定的道路结构以及车道拓扑。
-
提出了基于位置的目标布局生成器,能够生成符合交通规则的特定数量的交通目标。
-
提出了多控制图像生成器,能够整合道路拓扑、交通状态和天气条件,实现多条件图像生成。
2. 相关工作
2.1. 文本到图像生成
近年来,许多方法致力于处理通用的文本到图像生成任务。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









