







目录
目录
朴素贝叶斯
朴素贝叶斯是一个常用的寻找决策面的算法。如下图所示:
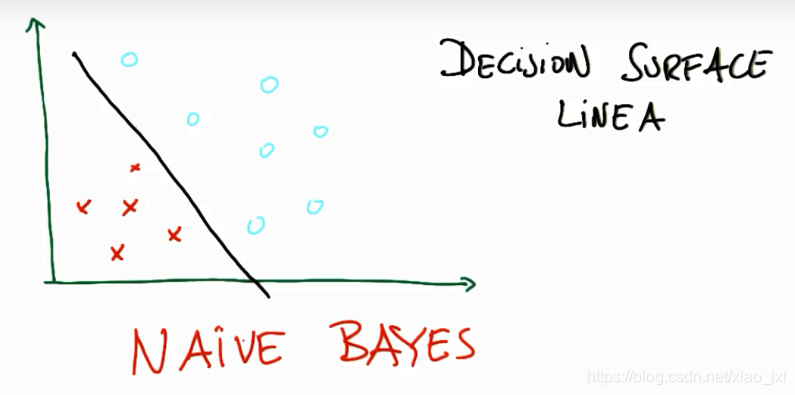
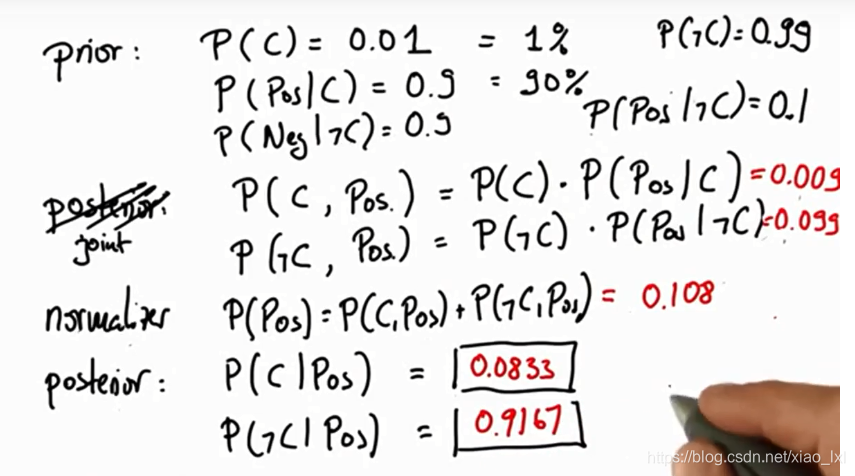
上图中,假设检测到癌症的概率为1%,没检测到癌症的概率为99%;
在检测到的癌症的人群中,其中有90%是真的患有癌症,10%为误诊;
在检测到没有癌症的人群中,有90%是没有癌症的,10%是误诊;
则先验概率 P(C) = 1%; P(-C) = 99%
P(pos|C) = 90%, P(neg|C) = 10%,
P(pos|-C) = 10%, P(neg|-C) = 90%,
之所以成为朴素,是因为它不考虑词的顺序
优点:
容易执行,效率高,特征空间非常大
缺点:
有时候会失败,没有词序(由多个单词组成且意义明显不同的短语)
贝叶斯定理
已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。
P(A|B) 表示事件B已发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式:
P(A|B) = P(AB)/P(B)
而贝叶斯定理为:
P(B|A) = P(A|B) P(B)/P(A)
朴素贝叶斯基本思想:对于给出的待分类项,求解在此项条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
分类算法之贝叶斯网络(Bayesian networks)
1、贝叶斯网络的解释和举例
朴素贝叶斯分类有一个限制条件,就是特征属性必须有条件独立或基本独立(实际上在现实应用中几乎不可能做到完全独立)。当这个条件成立时,朴素贝叶斯分类法的准确率是最高的,但不幸的是,现实中各个特征属性间往往并不条件独立,而是具有较强的相关性,这样就限制了朴素贝叶斯分类的能力。这一篇文章中,我们接着上一篇文章的例子,讨论贝叶斯分类中更高级、应用范围更广的一种算法——贝叶斯网络(又称贝叶斯信念网络或信念网络)。
EX1: 通过对训练数据集的统计,得到下表(R表示账号真实性,H表示头像真实性):
| R=0 | R=1 |
| 0.11 | 0.89 |
|
| H=0 | H=1 |
| R=0 | 0.9 | 0.1 |
| R=1 | 0.2 | 0.8 |
纵向表头表示条件变量,横向表头表示随机变量。上表为真实账号和非真实账号的概率,而下表为头像真实性对于账号真实性的概率。这两张表分别为“账号是否真实”和“头像是否真实”的条件概率表。有了这些数据,不但能顺向推断,还能通过贝叶斯定理进行逆向推断。例如,现随机抽取一个账户,已知其头像为假,求其账号也为假的概率:
P(R=0|H=0)=P(H=0|R=0)P(R=0)/P(H=0) = P(H=0|R=0)P(R=0)/(P(H=0|R=0)P(R=0) + P(H=0|R=1)P(R=1)) = 0.9*0.11/(0.9*0.11+0.2*0.89) = 0.3574
也就是说,在仅知道头像为假的情况下,有大约35.7%的概率此账户也为假。如果觉得阅读上述推导有困难,请复习概率论中的条件概率、贝叶斯定理及全概率公式。如果给出所有节点的条件概率表,则可以在观察值不完备的情况下对任意随机变量进行统计推断。上述方法就是使用了贝叶斯网络。
2、贝叶斯网络的定义及性质
一个贝叶斯网络定义包括一个有向无环图(DAG)和一个条件概率表组成。DAG中每一个节点表示一个随机变量,可以是直观观测变量或隐藏变量,而有向边表示随机变量间的条件依赖;条件概率表中的每一个元素对应DAG中唯一的节点,存储此节点对于其所有直接前驱节点的联合条件概率。
每一个节点在其直接前驱节点的值制定后,这个节点条件独立于其所有非直接前驱前辈节点。
贝叶斯网络可以看做是马尔科夫链(Markov)的非线性扩展。
一般情况下,多变量非独立联合条件概率分布有如下求取公式:
而在贝叶斯网络中,由于存在前述性质,任意随机变量组合的联合条件概率分布被化简成
其中Parents表示xi的直接前驱节点的联合,概率值可以从相应条件概率表中查到。
3、贝叶斯网络的构造和学习
构造和训练贝叶斯网络需要两步:
1) 确定随机变量间的拓扑关系,形成DAG。这一步通常需要领域专家完成,而想要建立一个好的拓扑结构,通常需要不断迭代和改进才可以。
2) 训练贝叶斯网络。需要完成条件概率表的构造,如果每个随机变量的值都是可以直接观察的,像上面的例子,这么这一步训练时直观的,方法类似于朴素贝叶斯分类。但是通常贝叶斯网络中存在隐藏变量节点,那么训练方法就比较复杂,例如梯度下降法。
4、贝叶斯网络的应用及示例
贝叶斯网络主要用于概率推理及决策,也就是在信息不完备的情况下通过可观察随机变量推断不可观察的随机变量,并且不可观察随机变量可以多余一个,一般初期将不可观察变量置为随机值,然后进行概率推理。
使用贝叶斯网络进行推理的步骤一般为:
1) 对所有可观察随机变量节点用观察值实例化,对不可观察节点实例化为随机值。
2) 对DAG进行遍历,对每一个不可观察点y,计算,其中wi表示除y以外的其他所有节点,a为正规化因子,sj表示y的第j个子节点。
3) 使用第二步计算出的各个y作为未知节点的新值进行实例化,重复第二步,知道结果充分收敛。
4) 将收敛结果作为推断值。
高斯朴素贝叶斯——python实现
def NBAccuracy(features_train, labels_train, features_test, labels_test):
""" compute the accuracy of your Naive Bayes classifier """
### import the sklearn module for GaussianNB
from sklearn.naive_bayes import GaussianNB
### create classifier
clf = GaussianNB()#TODO
### fit the classifier on the training features and labels
#TODO
clf.fit(features_train, labels_train)
### use the trained classifier to predict labels for the test features
pred =clf.predict(features_test) #TODO
### calculate and return the accuracy on the test data
### this is slightly different than the example,
### where we just print the accuracy
### you might need to import an sklearn module
#####method 1. #############################
from sklearn.metrics import accuracy_score
acc = accuracy_score(pred, labels_test)
#####method 2. #############################
#accuracy = clf.score(features_test, labels_test)
return accuracy小项目——识别作者:
几年前,J.K. 罗琳(凭借《哈利波特》出名)试着做了件有趣的事。她以 Robert Galbraith 的化名写了本名叫《The Cuckoo’s Calling》的书。尽管该书得到一些不错的评论,但是大家都不太重视它,直到 Twitter 上一个匿名的知情人士说那是 J.K. Rowling 写的。《伦敦周日泰晤士报》找来两名专家对《杜鹃在呼唤》和 Rowling 的《偶发空缺》以及其他几名作者的书进行了比较。分析结果强有力地指出罗琳就是作者,《泰晤士报》直接询问出版商情况是否属实,而出版商也证实了这一说法,该书在此后一夜成名。
我们也将在此项目中做类似的事。我们有一组邮件,分别由同一家公司的两个人撰写其中半数的邮件。我们的目标是仅根据邮件正文区分每个人写的邮件。在这个迷你项目一开始,我们将使用朴素贝叶斯,并在之后的项目中扩展至其他算法。
我们会先给你一个字符串列表。每个字符串代表一封经过预处理的邮件的正文;然后,我们会提供代码,用来将数据集分解为训练集和测试集。
朴素贝叶斯特殊的一点在于,这种算法非常适合文本分类。在处理文本时,常见的做法是将每个单词看作一个特征,这样就会有大量的特征。此算法的相对简单性和朴素贝叶斯独立特征的这一假设,使其能够出色完成文本的分类。在这个迷你项目中,你将在计算机中下载并安装 sklearn,然后使用朴素贝叶斯根据作者对邮件进行分类。
在 naive_bayes/nb_author_id.py 中创建和训练朴素贝叶斯分类器,用其为测试集进行预测。准确率是多少?
#!/usr/bin/python
"""
This is the code to accompany the Lesson 1 (Naive Bayes) mini-project.
Use a Naive Bayes Classifier to identify emails by their authors
authors and labels:
Sara has label 0
Chris has label 1
"""
import sys
from time import time
sys.path.append("../tools/")
from email_preprocess import preprocess
### features_train and features_test are the features for the training
### and testing datasets, respectively
### labels_train and labels_test are the corresponding item labels
features_train, features_test, labels_train, labels_test = preprocess()
#########################################################
### your code goes here ###
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB()
t0 = time()
clf.fit(features_train, labels_train)
print "training time:", round(time()-t0, 3), "s"
t1 = time()
pred = clf.predict(features_test)
print "testing time:", round(time()-t1, 3), "s"
from sklearn.metrics import accuracy_score
acc = accuracy_score(pred, labels_test)
print acc
print clf.score(features_test, labels_test)
#########################################################
运行准确率为 0.973265073948
training time: 1.204 s
testing time: 0.221 s

















 161
161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









