






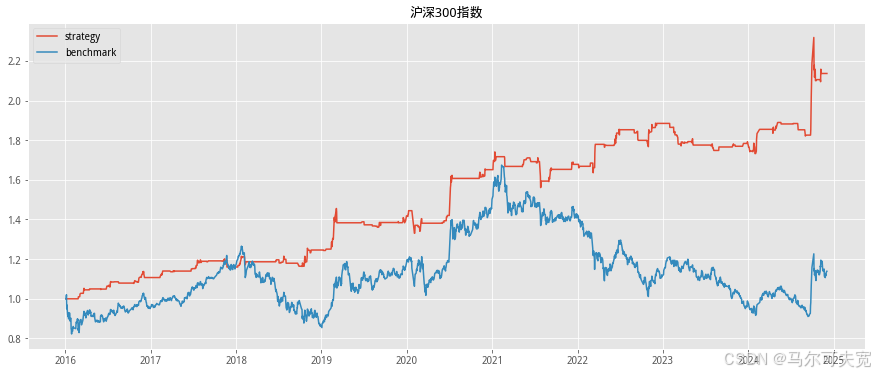
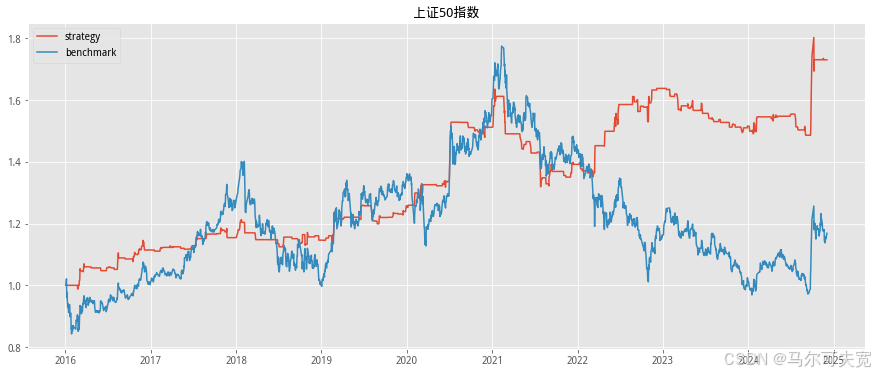
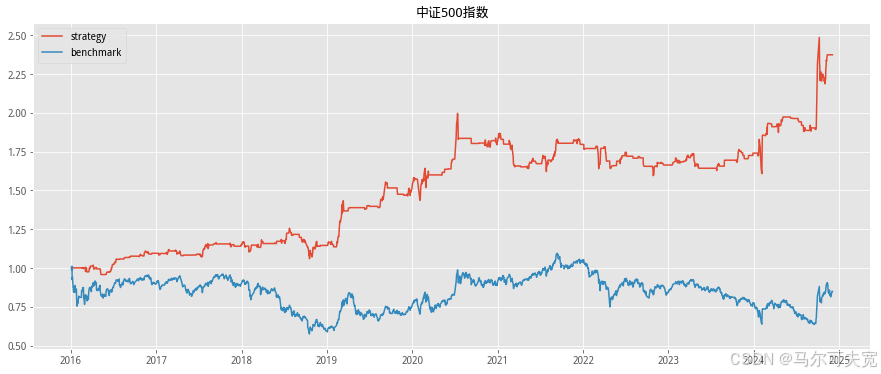
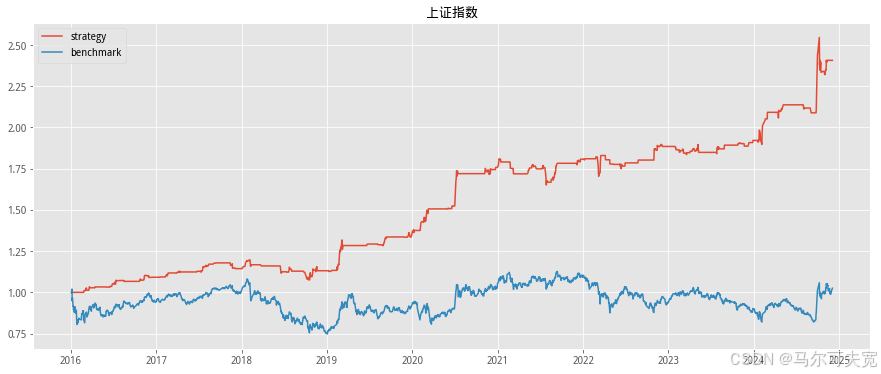
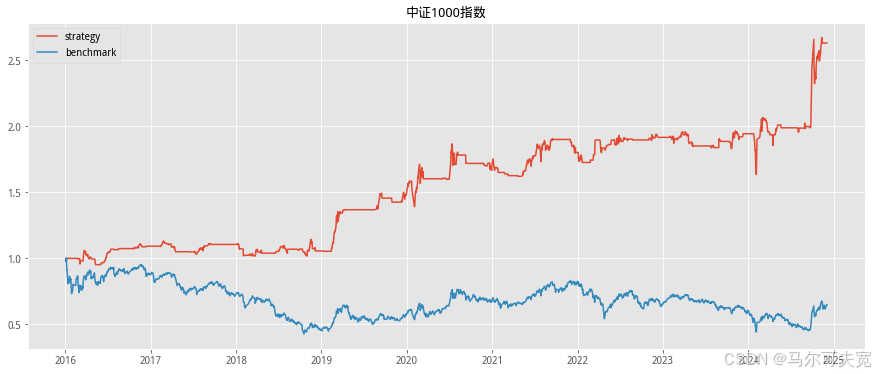
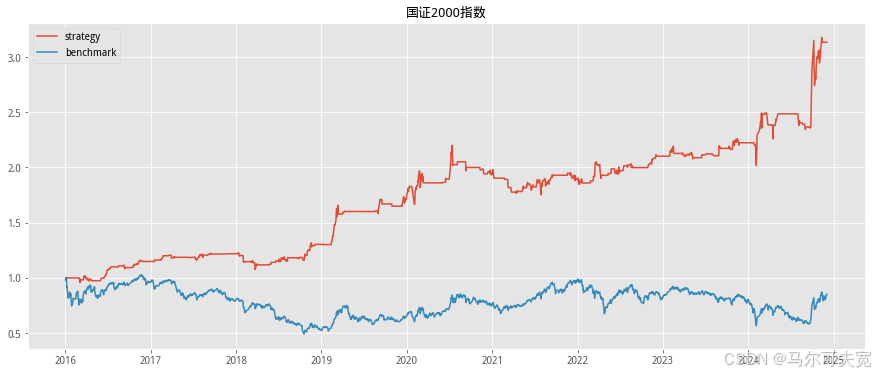
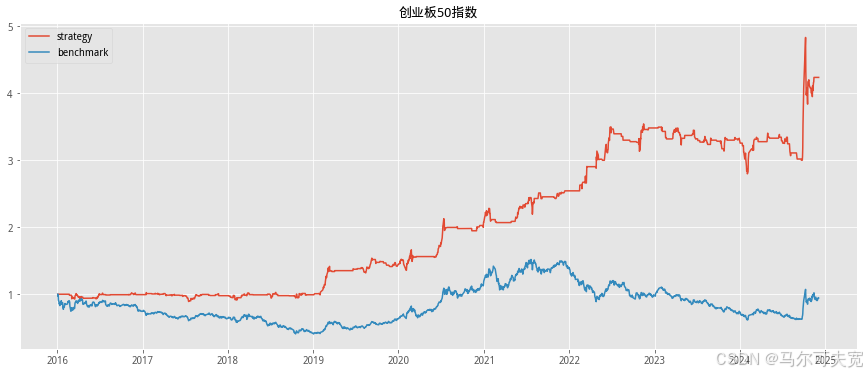
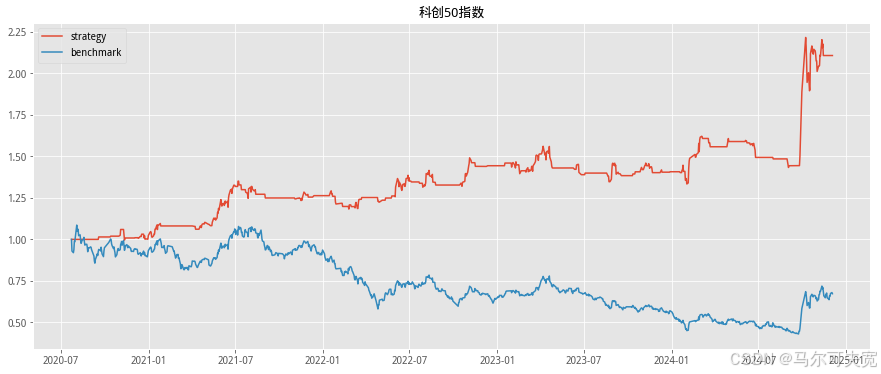
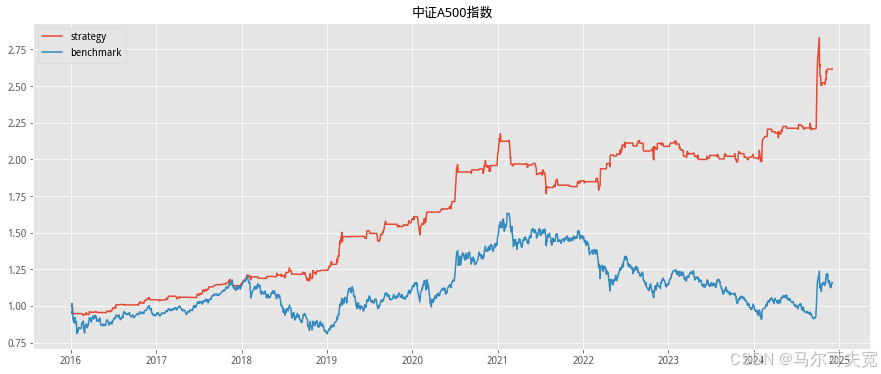
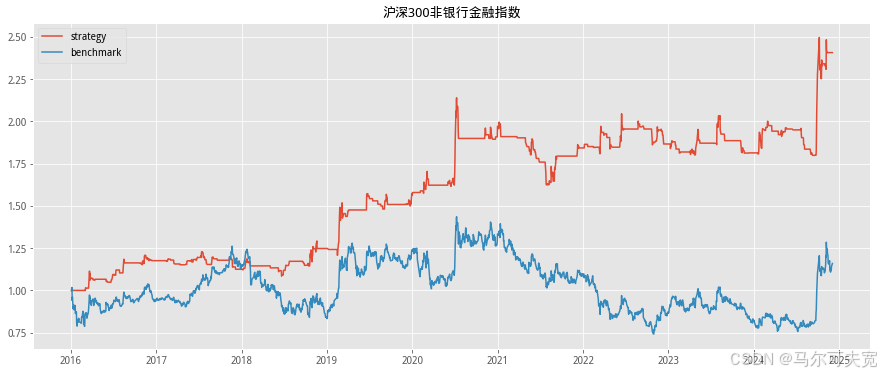
按照市场中常听到的俗语“价涨量先行”,往往成交量在逐渐扩大的时 候,市场有上涨的趋势。我们也尝试着在各个宽基指数上验证上述俗语在统 计意义上是否成立,以及能在多大程度上预测未来指数涨跌幅度。 从直观意义上说,放量即指成交量在逐日不断上升,而缩量则是成交量 逐日下降。但由于市场中影响成交量的因素太多,很容易混有一定程度的噪 音,因此成交量严格意义上的多日(超过连续三个交易日)单调递增或单调 递减并不常见。为了能较好的量化当日成交量大小在连续的一段交易日中的 地位,使得每一天的成交量都有一个数量来描述其处于放量或缩量中的位置, 我们构造成交量的时间序列排名指标。其构造方式如下:
 我们依据单日成交量时序排名来构造择时策略。具体的方式如下:
我们依据单日成交量时序排名来构造择时策略。具体的方式如下:
1. 计算当日指数的成交量时序排名并标准化为[-1,1]值域内的指标值。 (涉及参数选择 N,时序排名窗口长度)
2. 当成交量时序排名处于最大的一段范围内,或等价的,其标准化后 的值超过一定阈值 S(例如时序排名位于最大的前四分之一,或等 价的,标准化后的值超过 0.5),则开仓买入。(涉及参数选择 S, 开仓阈值)
3. 当成交量时序排名离开高位,或等价的,其标准化后的值低于一定 阈值 S,则平仓观望。
4. 不进行看空与卖空交易。



















 2631
2631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











