









Stability AI发布了Stable Video 3D (SV3D),这是一种基于稳定视频扩散的生成模型,推动了3D技术领域的发展,并大大提高了质量和视图一致性。

该版本有两个版本:
-
SV3D_u:该变体基于单图像输入生成轨道视频,无需相机调节。
-
SV3D_p:扩展SVD3_u的功能,此变体可容纳单图像和轨道视图,允许沿着指定的相机路径创建3D视频。
Stable Video 3D现在可以用于商业目的与稳定的AI会员。对于非商业用途,可以在huggingface上下载模型权重并查看论文。
相关链接
目前模型和技术报告已经发布:
-
模型:https://huggingface.co/stabilityai/sv3d
-
技术报告:https://stability.ai/s/SV3D_rep
-
项目主页:https://stability.ai/news/introducing-stable-video-3d
论文阅读

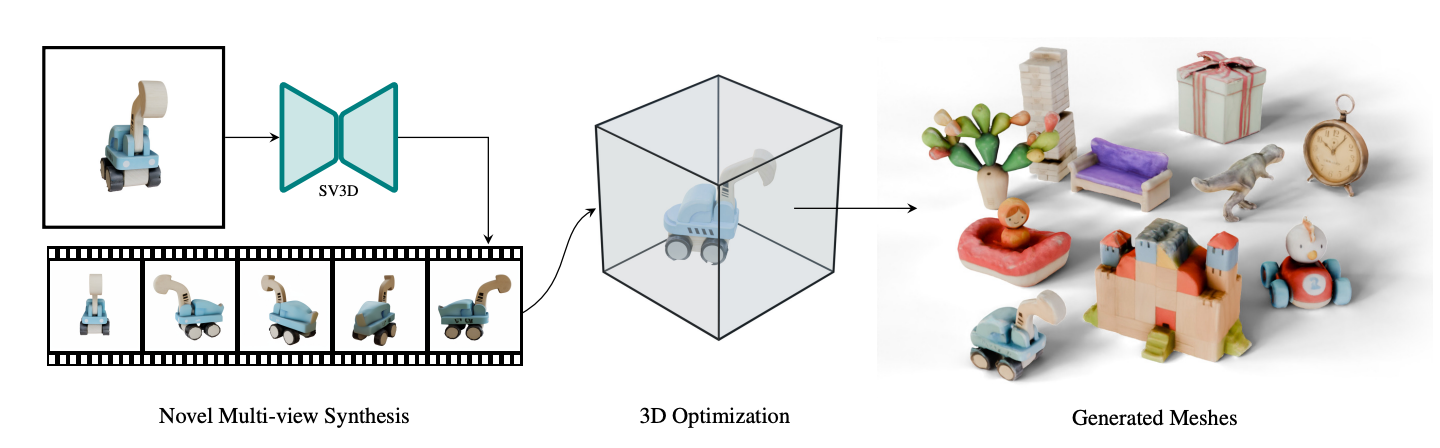
摘要
论文提出了稳定视频3D (SV3D),一种潜在的视频扩散模型,用于高分辨率,图像到多视图生成围绕3D物体的轨道视频。最近的工作三维生成方面,提出了将二维生成模型用于新视图合成(NVS)和三维优化的技术。
然而,这些方法有几个缺点由于有限的视角或不一致的NVS,从而影响了3D对象生成的性能。在这个 在本文中,我们提出了基于图像到视频扩散模型的SV3D,用于新的多视图合成和3D生成,从而利用了泛化和多视图视频模型的一致性,同时进一步为NVS添加显式摄像机控制。
我们还建议改进使用SV3D及其NVS输出进行图像到3D生成的3D优化技术。大量的实验在2D和3D指标的多个数据集上的结果用户研究证明了SV3D在NVS和3D重建方面的最先进性能。
方法
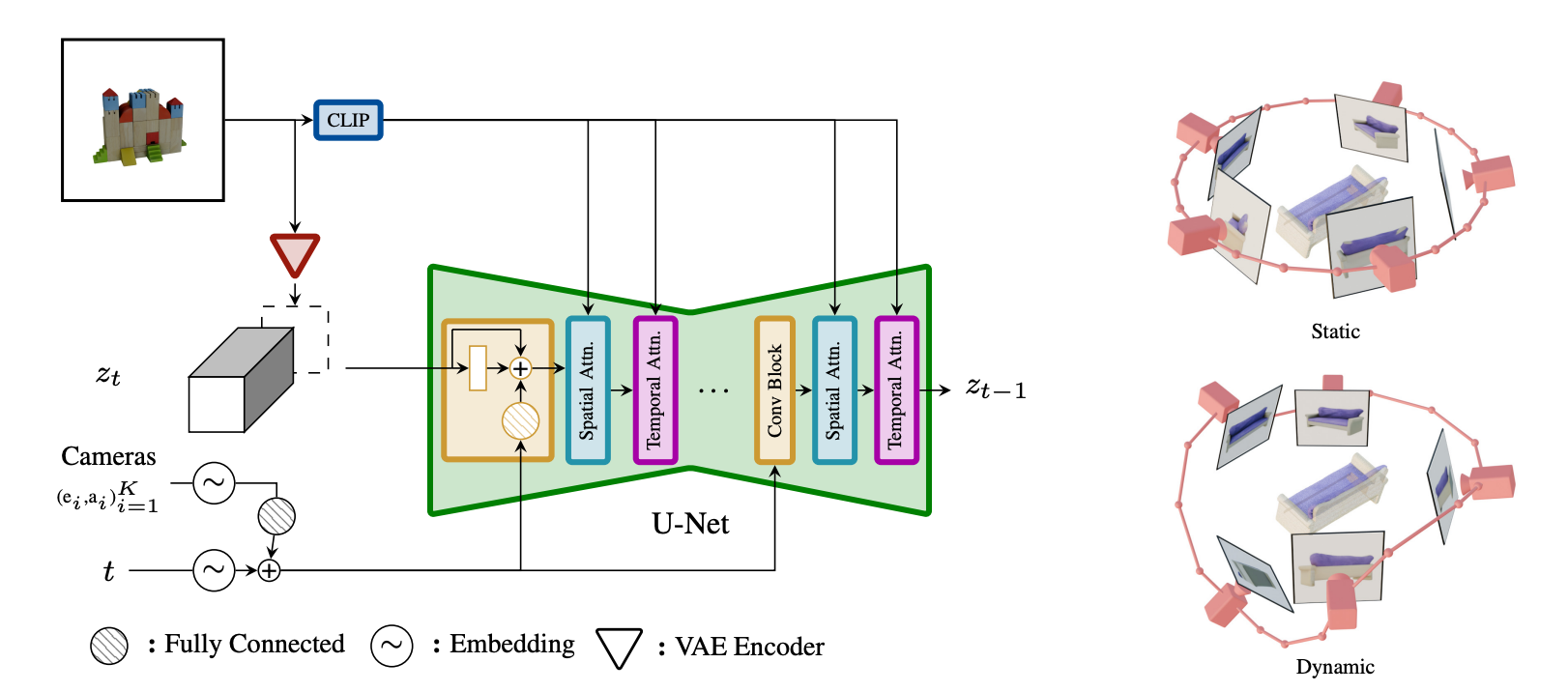
SV3D架构
SV3D建立在SVD的基础上,SVD由多层UNet组成,每层包含一个带有Conv3D层的残差块和两个变压器块的序列(空间和时间)有注意层。
-
我们删除了"fps id"和"motion bucket id "的向量条件,因为它们与SV3D无关。
-
条件反射图像通过SVD的VAE编码器嵌入到隐空间后,与UNet在噪声时间步长t处的噪声潜状态输入z t连接。
-
将条件图像的CLIPembedding矩阵作为其键和值提供给每个transformer块的交叉注意力层。
-
将摄像机轨迹连同扩散噪声时间步长一起输入到残差块中。首先,将摄像机姿态角度ei和ai以及噪声时间步长t嵌入到正弦位置嵌入中。然后,将相机姿态嵌入连接在一起,进行线性变换,并将其添加到噪声时间步嵌入中。这被馈送到每个残差块,在那里它们被添加到块的输出特征中。
实验结果
Stable Video 3D引入了3D生成的重大进步,特别是在新视图合成(NVS)方面。不像以前的方法,往往与有限的视角和输出不一致,稳定的视频3D能够提供连贯的观点,从任何给定的角度与熟练的泛化。这种能力不仅增强了姿态可控性,而且确保了跨多个视图的一致对象外观,进一步提高了逼真和准确的3D生成的关键方面。
新视图合成

多视点合成
SV3D能够生成更详细、更真实的新颖多视图。以调理图像为主,与前人作品的多视角比较一致。

3D生成
SV3D利用其多视图一致性来优化3D神经辐射场(NeRF)和网格表示,以提高从新视图直接生成的3D网格的质量。为此论文设计了一个掩蔽分数蒸馏采样损失,以进一步提高在预测视图中不可见区域的3D质量。此外为了减少嵌入式照明问题,SV 3D采用了与3D形状和纹理共同优化的解纠缠照明模型。


感谢你看到这里,也欢迎点击关注下方公众号,一个有趣有AI的AIGC公众号:关注AI、深度学习、计算机视觉、AIGC、Stable Diffusion、Sora等相关技术,欢迎一起交流学习💗~



















 384
384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











