









5月14日,腾讯宣布旗下的混元文生图大模型升级并对外开源。升级后的模型采用了与 Sora 一致的 DiT 架构,不仅可支持文生图,也可作为视频等多模态视觉生成的基础。
特别是对与中文的理解和生图效果非常不错!这也是业内首个中文原生的 DiT 架构文生图开源模型,支持中英文双语输入及理解,参数量15亿。下面展示一些中文生图的效果~



该模型已在Hugging Face平台及Github上发布,包含模型权重、推理代码、模型算法等完整模型,与腾讯混元文生图产品最新版本完全一致,基于腾讯海量应用场景训练,可供企业与个人开发者免费商用。
相关链接
技术报告:https://tencent.github.io/HunyuanDiT/asset/Hunyuan_DiT_Tech_Report_05140553.pdf
Huggingface:https://huggingface.co/Tencent-Hunyuan/HunyuanDiT
GitHub:https://github.com/Tencent/HunyuanDiT
官网体验:https://image.hunyuan.tencent.com/authorize(已经开放注册)

模型介绍

摘要
我们提出了Hunyuan-DiT,一种文本到图像的扩散转换器,可以对英语和中文进行细粒度的理解。为了构建Hunyuan-DiT,我们精心设计了变压器结构、文本编码器和位置编码。我们还从头开始构建整个数据管道来更新和评估数据以进行迭代模型优化。为了细粒度的语言理解,我们训练了多模态大语言模型来细化图像的标题。最后,Hunyuan-DiT可以与用户进行多轮多模态对话,根据上下文生成和细化图像。通过我们与 50 多名专业人类评估人员精心设计的整体人类评估协议,与其他开源模型相比,Hunyuan-DiT 在中文到图像生成方面树立了新的最先进水平。
混元-DiT 主要特点
中英双语DiT架构
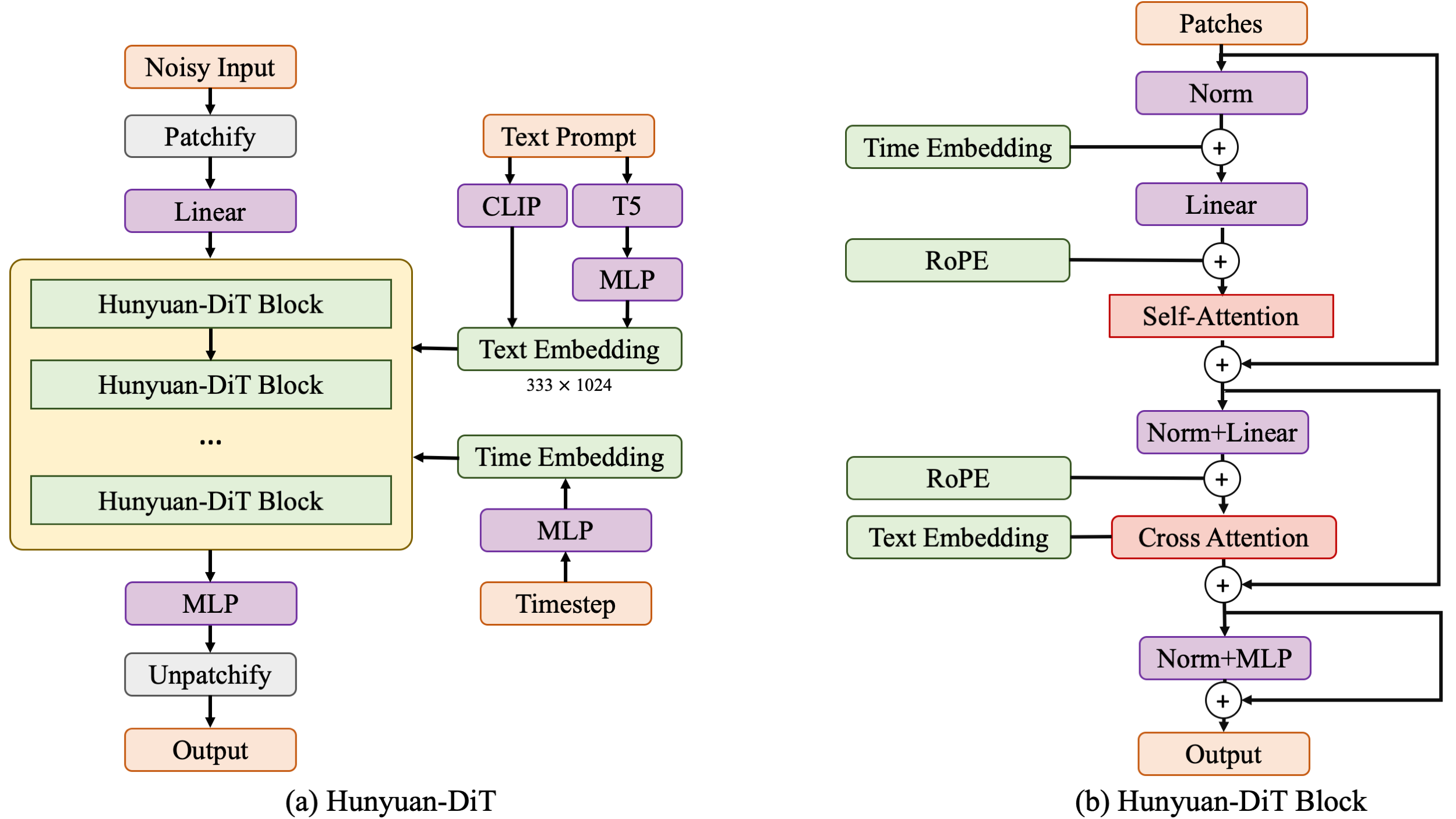
Hunyuan-DiT是潜在空间中的扩散模型,如下图所示。遵循潜在扩散模型,我们使用预先训练的变分自动编码器(VAE)将图像压缩到低维潜在空间并训练扩散模型以通过扩散模型学习数据分布。我们的扩散模型通过变压器进行参数化。为了对文本提示进行编码,我们结合了预先训练的双语(英语和中文)CLIP 和多语言 T5 编码器。
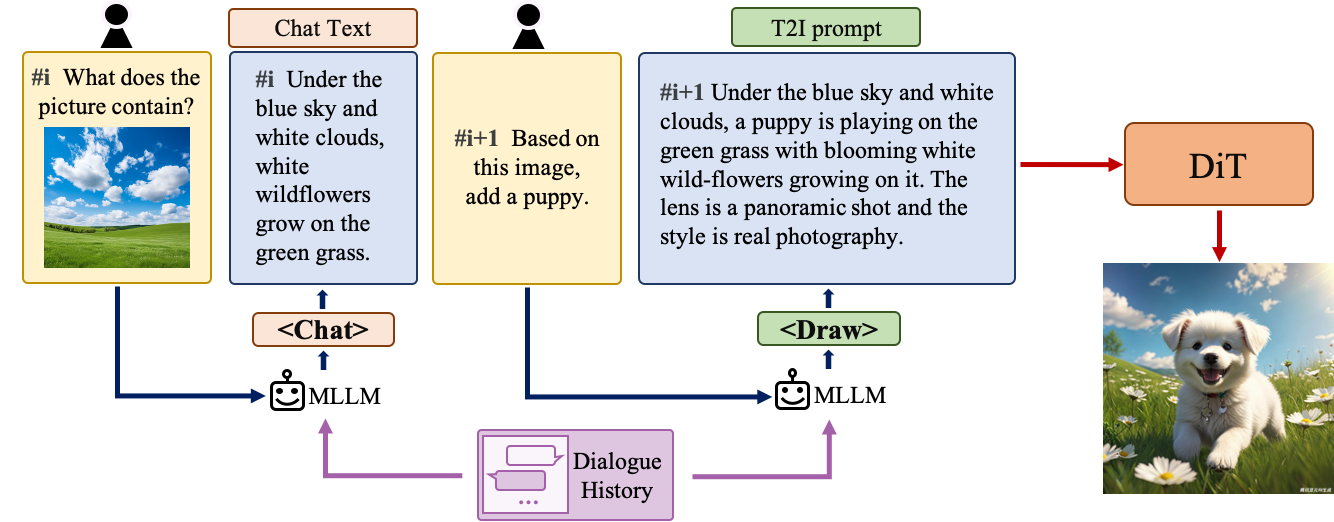
多轮 Text2Image 生成
理解自然语言指令并与用户进行多轮交互对于文本到图像系统非常重要。它可以帮助构建一个动态的、迭代的创作流程,将用户的想法一步步变为现实。在本节中,我们将详细介绍如何赋予Hunyuan-DiT执行多轮对话和图像生成的能力。我们训练 MLLM 来理解多轮用户对话并输出用于图像生成的新文本提示。
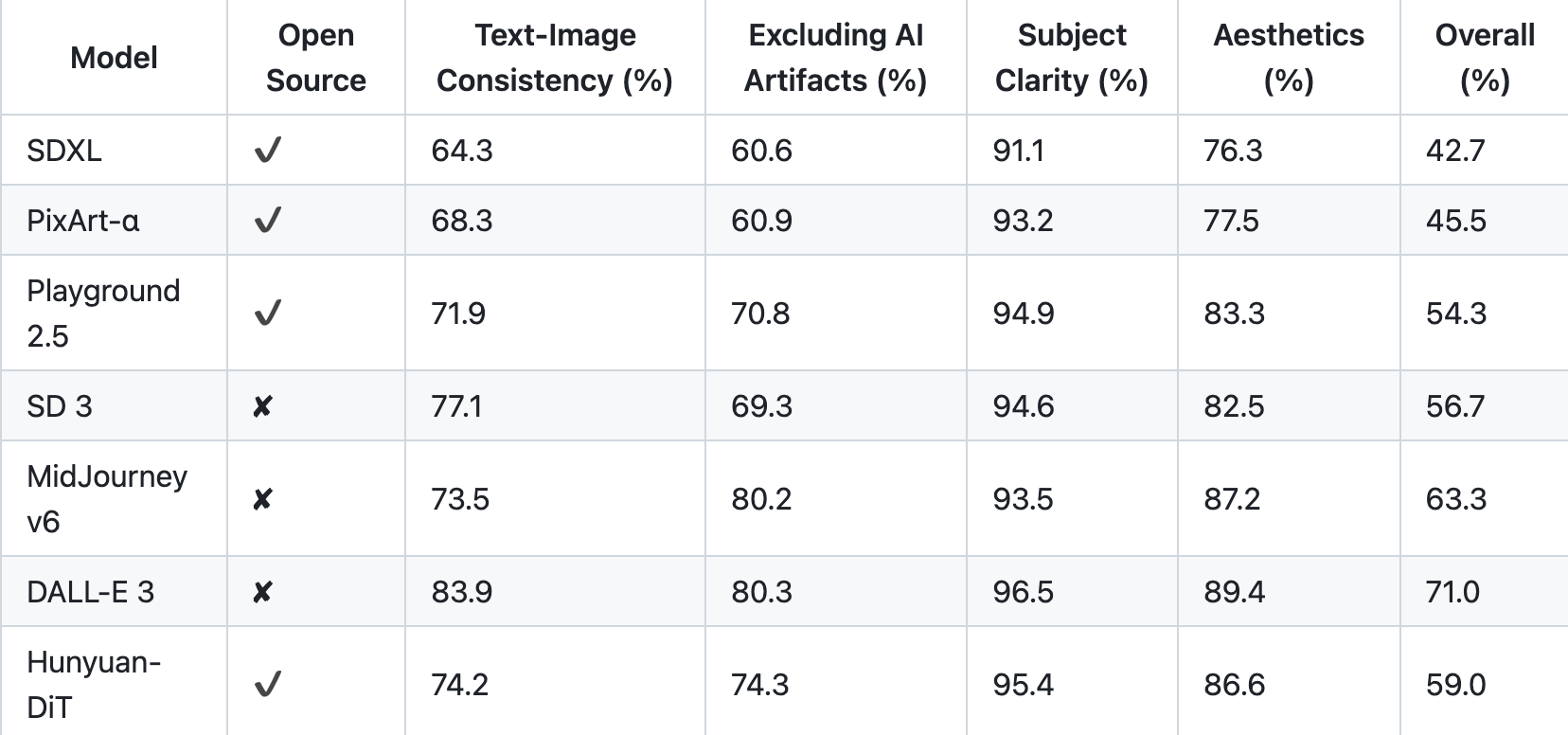
实验比较
为了全面比较HunyuanDiT与其他模型的生成能力,我们构建了4个维度的测试集,包括文本图像一致性、排除AI伪影、主题清晰度、审美。超过50名专业评估人员进行评估。
可视化结果
中国元素



长文本输入


部署建议
测试了 V100 和 A100 GPU。
-
需要支持 CUDA 的 NVIDIA GPU。
-
最低:所需的最低 GPU 内存为 11GB。
-
推荐:使用具有32GB内存的 GPU,以获得更好的生成质量。
-
测试操作系统:Linux


















 1952
1952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











