





ChatTTS 一夜爆火, 极速出圈, 3 天就斩获 9k 的 Star 量, 截止 2024.06.04, 已经 19.3k 的 star, 极速接近 GPT-soVITs 当天的 26.2k 的 star 数。
什么是ChatTTS?
TTS全称:Text To Speech(也就是文本转语音模型)。ChatTTS是专为对话场景设计的语音生成模型,特别适用于大型语言模型(LLM)助手的对话任务,以及诸如对话式音频和视频介绍等应用。它支持中文和英文,通过使用大约100,000小时的中文和英文数据进行训练,ChatTTS在语音合成中表现出高质量和自然度。
现在ChatTTS正式上线了官网,所有用户都可以直接在线体验了。
相关链接
ChatTTS中文官网:https://chattts.com/zh
GitHub项目地址:https://github.com/2noise/ChatTTS
Hugging Face模型地址:https://huggingface.co/2Noise/ChatTTS
使用页面
ChatTTS Web_UI链接:https://github.com/jianchang512/ChatTTS-ui
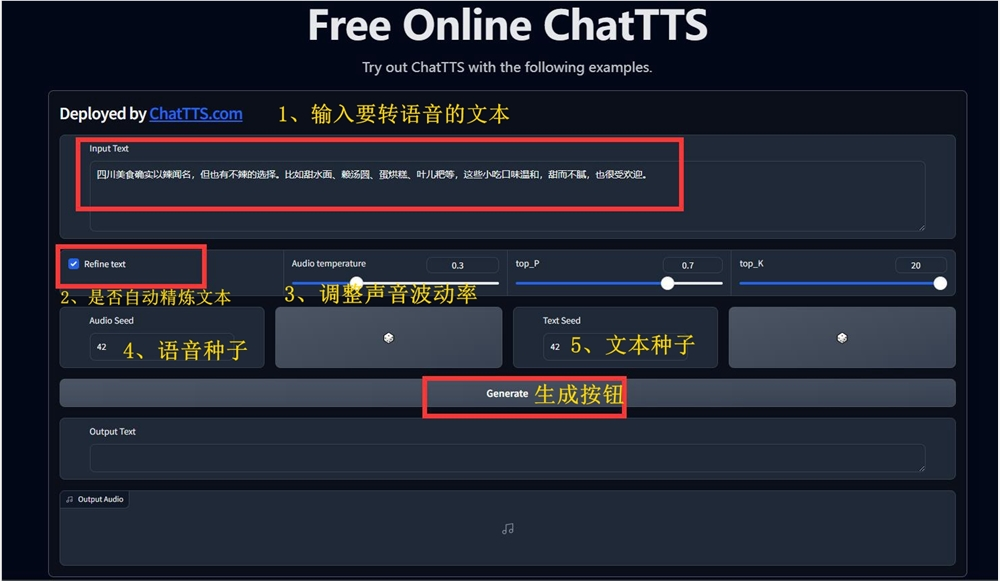
-
text:指的是需要转换成语音的文字内容。
-
Refine text:选择是否自动对输入的文本进行优化处理。
-
随机度:一个控制输出随机性的参数,数值越大,生成的语音随机性越高,这可能导致生成的语音质量有时更好,有时更差。
-
声音选择:默认值为2222,这是一个数字参数,用于选择声音的类型。可选的数字有2222、7869、6653、4099、5099,可以任选其一,或者输入其他数字以随机选择声音。
-
定制声音:这是一个正整数参数,用于定制声音的音调和音色。如果设置了此值,将优先使用,而忽略声音选择参数。
-
提示设置:用于添加笑声、停顿等效果。例如,可以设置为[oral_2][laugh_0][break_6]。
ChatTTS介绍
什么是ChatTTS?
TTS全称:Text To Speech(也就是文本转语音模型)
而ChatTTS是专为对话场景设计的语音生成模型,特别适用于大型语言模型(LLM)助手的对话任务,以及诸如对话式音频和视频介绍等应用。它支持中文和英文,通过使用大约100,000小时的中文和英文数据进行训练,ChatTTS在语音合成中表现出高质量和自然度。

ChatTTS亮点
-
对话式 TTS: ChatTTS针对对话式任务进行了优化,实现了自然流畅的语音合成,同时支持多说话人。
-
细粒度控制: 该模型能够预测和控制细粒度的韵律特征,包括笑声、停顿和插入词等。
-
更好的韵律: ChatTTS在韵律方面超越了大部分开源TTS模型。同时提供预训练模型,支持进一步的研究。
计划路线
-
开源4w小时基础模型和spk_stats文件
-
开源VQ encoder和Lora 训练代码
-
在非refine text情况下, 流式生成音频
-
开源多情感可控的4w小时版本
-
ChatTTS.cpp

使用建议
对于30s的音频, 至少需要4G的显存. 对于4090, 1s生成约7个字所对应的音频. RTF约0.3.
模型稳定性不够好, 会出现其他说话人或音质很差的现象是由于自回归模型,说话人可能会在中间变化, 可能会采样到音质非常差的结果, 这通常难以避免。可以多采样几次来找到合适的结果。
除了笑声还能控制什么吗? 还能控制其他情感吗? 在现在放出的模型版本中, 只有[laugh]和[uv_break], [lbreak]作为字级别的控制单元. 在未来的版本中我们可能会开源其他情感控制的版本.
免责声明
此repo仅用于学术目的。它旨在用于教育和研究用途,不得用于任何商业或法律目的。作者不保证信息的准确性、完整性或可靠性。此 repo 中使用的信息和数据仅用于学术和研究目的。数据来自公开来源,作者不对数据主张任何所有权或版权。
ChatTTS 是一款功能强大的文本转语音系统。然而,负责任且合乎道德地使用这项技术非常重要。为了限制 ChatTTS 的使用,我们在 40,000 小时模型的训练过程中添加了少量高频噪音,并使用 MP3 格式尽可能压缩音频质量,以防止恶意行为者将其用于犯罪目的。同时,我们内部训练了一个检测模型,并计划在未来将其开源。



















 1465
1465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











