






新春佳节,蛇年大吉!愿您在新的一年里,生活如蛇行般灵动自如,事业似蛇舞般活力四射。蛇年,愿您福运缠身,财源广进,家庭和睦,幸福安康!今天给大家推荐一些大模型(LLM)工程师相关的免费学习资料,先收藏起来哦
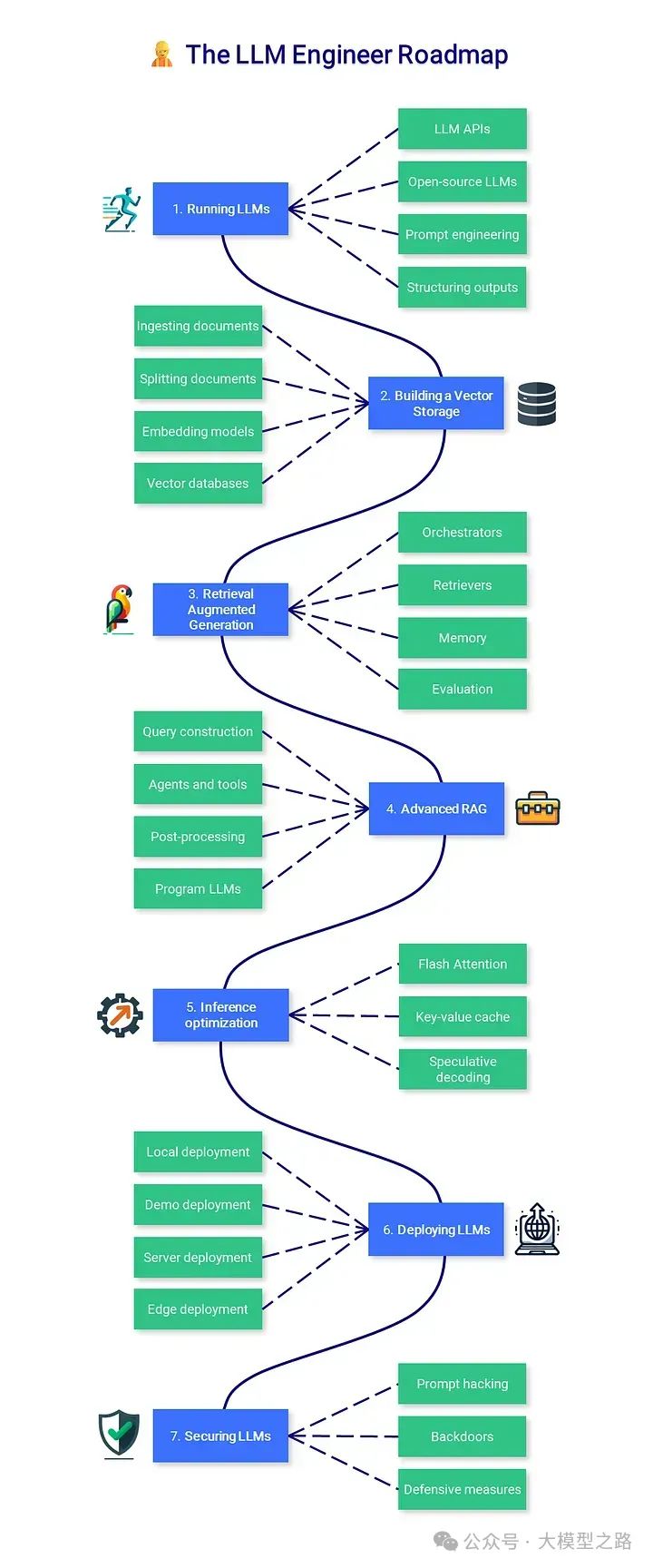
1. 运行LLM
运行LLM可能由于硬件要求较高而变得困难。根据你的使用场景,你可能希望通过API(如GPT-4)简单地调用模型,或者在本地运行模型。在任何情况下,额外的提示工程和引导技术都可以改善并约束模型的输出,以适应你的应用程序。
- LLM API:API是部署LLM的一种便捷方式。这一领域分为私人LLM(如OpenAI、Google、Anthropic、Cohere等)和开源LLM(如OpenRouter、Hugging Face、Together AI等)。
- 开源LLM:Hugging Face Hub是寻找LLM的好地方。你可以直接在Hugging Face Spaces中运行其中一些模型,或者下载并在本地应用中运行,例如通过LM Studio或使用llama.cpp或Ollama通过命令行运行。
- 提示工程:常见的技术包括零样本提示(zero-shot prompting)、少样本提示(few-shot prompting)、思维链(chain of thought)和ReAct。这些技术更适合大型模型,但也可以适应小型模型。
- 结构化输出:许多任务需要结构化的输出,例如严格的模板或JSON格式。像LMQL、Outlines、Guidance等库可以用来引导生成并遵循给定的结构。
推荐:
- Run an LLM locally with LM Studio by Nisha Arya: Short guide on how to use LM Studio.(https://www.kdnuggets.com/run-an-llm-locally-with-lm-studio)
- Prompt engineering guide by DAIR.AI: Exhaustive list of prompt techniques with examples(https://www.promptingguide.ai/)
- Outlines — Quickstart: List of guided generation techniques enabled by Outlines.(https://dottxt-ai.github.io/outlines/latest/quickstart/)
- LMQL — Overview: Introduction to the LMQL language.(https://lmql.ai/docs/language/overview.html)
2. 构建向量存储
创建向量存储(构建非英文RAG(Retrieval-Augmented Generation)系统时,embedding很重要)是构建检索增强生成(Retrieval-Augmented Generation, RAG)管道的第一步。文档被加载、拆分,相关的片段被用来生成向量表示(嵌入),这些嵌入会被存储起来,以便在推理时使用。
- 文档加载:文档加载器是方便的包装器,可以处理许多格式:PDF、JSON、HTML、Markdown等。它们还可以直接从一些数据库和API(如GitHub、Reddit、Google Drive等)中检索数据。
- 文档拆分:文本拆分器将文档分解为更小的、语义上有意义的片段。与其按字符数拆分文本,不如按标题或递归拆分,同时附带一些额外的元数据。
- 嵌入模型:嵌入模型将文本转换为向量表示。它允许更深入、更细致地理解语言,这对于执行语义搜索至关重要。
- 向量数据库:向量数据库(如Chroma、Pinecone、Milvus、FAISS、Annoy等)旨在存储嵌入向量。它们能够高效地检索与查询最相似的数据,基于向量相似性。
推荐:
- LangChain — Text splitters: List of different text splitters implemented in LangChain.(https://python.langchain.com/docs/modules/data_connection/document_transformers/)
- Sentence Transformers library: Popular library for embedding models.(https://www.sbert.net/)
- MTEB Leaderboard: Leaderboard for embedding models.(https://huggingface.co/spaces/mteb/leaderboard)
- The Top 5 Vector Databases by Moez Ali: A comparison of the best and most popular vector databases.(https://www.datacamp.com/blog/the-top-5-vector-databases)
3. 检索增强生成(RAG)
通过RAG,LLM可以从数据库中检索上下文文档,以提高其回答的准确性。RAG是一种流行的方法,可以在不进行微调的情况下增强模型的知识。
- 协调器:协调器(如LangChain、LlamaIndex、FastRAG等)是流行的框架,用于将LLM与工具、数据库、记忆等连接起来,增强它们的能力。
- 检索器:用户指令并不适合检索。不同的技术(例如多查询检索器、HyDE等)可以用来改写/扩展它们,以提高性能。
- 记忆:为了记住之前的指令和回答,LLM和聊天机器人(如ChatGPT)会将其历史记录添加到上下文窗口中。这个缓冲区可以通过总结(例如使用较小的LLM)、向量存储+RAG等方式进行改进。
- 评估:我们需要评估文档检索(上下文精确度和召回率)和生成阶段(忠实度和答案相关性)。可以使用Ragas和DeepEval等工具简化评估。
推荐:
- Llamaindex — High-level concepts: Main concepts to know when building RAG pipelines.(https://docs.llamaindex.ai/en/stable/getting_started/concepts.html)
- Pinecone — Retrieval Augmentation: Overview of the retrieval augmentation process.(https://www.pinecone.io/learn/series/langchain/langchain-retrieval-augmentation/)
- LangChain — Q&A with RAG: Step-by-step tutorial to build a typical RAG pipeline.(https://python.langchain.com/docs/use_cases/question_answering/quickstart)
- LangChain — Memory types: List of different types of memories with relevant usage.(https://python.langchain.com/docs/modules/memory/types/)
- RAG pipeline — Metrics: Overview of the main metrics used to evaluate RAG pipelines.(https://docs.ragas.io/en/stable/concepts/metrics/index.html)
4. 高级RAG
现实世界的应用可能需要复杂的管道,包括SQL或图数据库,以及自动选择相关的工具和API。这些高级RAG技术可以改进基础解决方案,并提供额外的功能。
- 查询构建:存储在传统数据库中的结构化数据需要特定的查询语言,如SQL、Cypher、元数据等。我们可以直接将用户指令翻译成查询语句,以便访问数据。
- 代理和工具:代理通过自动选择最相关的工具来增强LLM,以提供答案。这些工具可以简单到使用Google或Wikipedia,也可以复杂到使用Python解释器或Jira。
- 后处理:最后一步是对输入到LLM的内容进行处理。它通过重新排序、RAG融合和分类等技术增强检索文档的相关性和多样性。
- 程序化LLM:像DSPy这样的框架允许基于自动化评估优化提示和权重,以程序化的方式进行。
推荐:
- LangChain — Query Construction: Blog post about different types of query construction.(https://blog.langchain.dev/query-construction/)
- LangChain — SQL: Tutorial on how to interact with SQL databases with LLMs, involving Text-to-SQL and an optional SQL agent.(https://python.langchain.com/docs/use_cases/qa_structured/sql)
- Pinecone — LLM agents: Introduction to agents and tools with different types.(https://www.pinecone.io/learn/series/langchain/langchain-agents/)
- LLM Powered Autonomous Agents by Lilian Weng: A more theoretical article about LLM agents.(https://lilianweng.github.io/posts/2023-06-23-agent/)
- LangChain — OpenAI’s RAG: Overview of the RAG strategies employed by OpenAI, including post-processing.(https://blog.langchain.dev/applying-openai-rag/)
- DSPy in 8 Steps: General-purpose guide to DSPy introducing modules, signatures, and optimizers.(https://dspy-docs.vercel.app/docs/building-blocks/solving_your_task)
5. 推理优化
文本生成是一个成本高昂的过程,需要昂贵的硬件支持。除了量化技术外,还提出了多种方法来最大化吞吐量并降低推理成本。
- Flash Attention:对注意力机制的优化,将其复杂度从二次方降低到线性,从而加速训练和推理过程。
- 键值缓存:了解键值缓存以及在多查询注意力(MQA)和分组查询注意力(GQA)中引入的改进。
- 推测性解码:使用小型模型生成草稿,然后由大型模型进行审核,从而加速文本生成。
推荐:
- GPU Inference by Hugging Face: Explain how to optimize inference on GPUs.(https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one)
- LLM Inference by Databricks: Best practices for how to optimize LLM inference in production.(https://www.databricks.com/blog/llm-inference-performance-engineering-best-practices)
- Optimizing LLMs for Speed and Memory by Hugging Face: Explain three main techniques to optimize speed and memory, namely quantization, Flash Attention, and architectural innovations.(https://huggingface.co/docs/transformers/main/en/llm_tutorial_optimization)
- Assisted Generation by Hugging Face: HF’s version of speculative decoding, it’s an interesting blog post about how it works with code to implement it.(https://huggingface.co/blog/assisted-generation)
6. 部署LLM
大规模部署LLM是一项工程壮举,可能需要多个GPU集群。在其他情况下,演示和本地应用可以通过更低的复杂性实现。
- 本地部署:隐私是开源LLM相对于私有LLM的重要优势。本地LLM服务器(如LM Studio、Ollama、oobabooga、kobold.cpp等)利用这一优势为本地应用提供支持。
- 演示部署:像Gradio和Streamlit这样的框架有助于快速构建应用并分享演示。你还可以轻松地将它们托管在线上,例如使用Hugging Face Spaces。
- 服务器部署:大规模部署LLM需要云(参见SkyPilot)或本地基础设施,并且通常会利用优化的文本生成框架,如TGI(Text Generation Inference)、vLLM等。
- 边缘部署:在资源受限的环境中,高性能框架(如MLC LLM和mnn-llm)可以在网页浏览器、Android和iOS上部署LLM。
推荐:
- Streamlit — Build a basic LLM app: Tutorial to make a basic ChatGPT-like app using Streamlit.(https://docs.streamlit.io/knowledge-base/tutorials/build-conversational-apps)
- HF LLM Inference Container: Deploy LLMs on Amazon SageMaker using Hugging Face’s inference container.(https://huggingface.co/blog/sagemaker-huggingface-llm)
- Philschmid blog by Philipp Schmid: Collection of high-quality articles about LLM deployment using Amazon SageMaker.(https://www.philschmid.de/)
- Optimizing latency by Hamel Husain: Comparison of TGI, vLLM, CTranslate2, and mlc in terms of throughput and latency.(https://hamel.dev/notes/llm/inference/03_inference.html)
7. 保障LLM的安全
除了传统软件相关的安全问题外,LLM由于其训练和提示的方式,还存在独特的弱点。
- 提示攻击:与提示工程相关的不同技术,包括提示注入(附加指令以劫持模型的回答)、数据/提示泄露(检索其原始数据/提示)和越狱(精心设计提示以绕过安全功能)。
- 后门攻击:攻击向量可以针对训练数据本身,通过污染训练数据(例如,加入虚假信息)或创建后门(秘密触发器以在推理时改变模型行为)。
- 防御措施:保护LLM应用的最佳方法是对其进行漏洞测试(例如,使用红队测试和garak等工具)并在生产环境中进行监控(使用langfuse等框架)。
推荐:
- OWASP LLM Top 10 by HEGO Wiki: List of the 10 most critical vulnerabilities seen in LLM applications.(https://owasp.org/www-project-top-10-for-large-language-model-applications/)
- Prompt Injection Primer by Joseph Thacker: Short guide dedicated to prompt injection for engineers.(https://github.com/jthack/PIPE)
- LLM Security by @llm_sec: Extensive list of resources related to LLM security.(https://llmsecurity.net/)
- Red teaming LLMs by Microsoft: Guide on how to perform red teaming with LLMs.(https://learn.microsoft.com/en-us/azure/ai-services/openai/concepts/red-teaming)
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









