







论文链接 https://arxiv.org/pdf/1511.02274.pdf
一、摘要
We argue that image question answering (QA) often requires multiple steps of reasoning. Thus, we develop a multiple-layer SAN in which we query an image multiple times to infer the answer progressively.
VQA问题的解决大多是层次性的,比如,当问题为:什么东西在车筐里? 我们往往会先定义到自行车,再去注意车筐,再去看车筐里的东西。所以论文作者提出了注意力堆叠模型。

二、分析SAN网络结构
1、图片特征提取
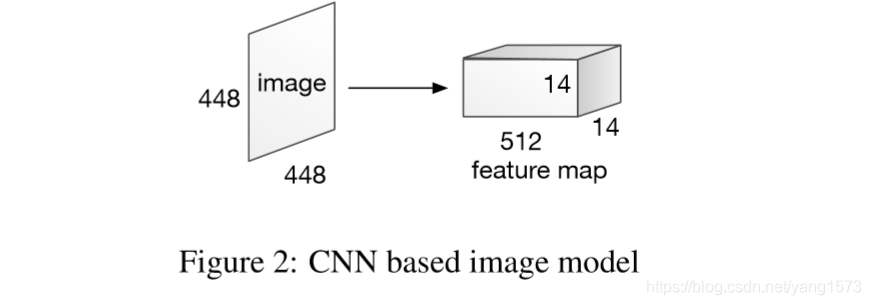
1、VGGNet
2、选取最后一个池化层作为特征输出14x14个512维的特征向量,每个特征向量代表原图32x32的区域。
3、单层感知机将512维向量转化为与问题特征向量同维(方便注意力模型之后的操作)。
2、问题特征提取
论文提出了两种方法。
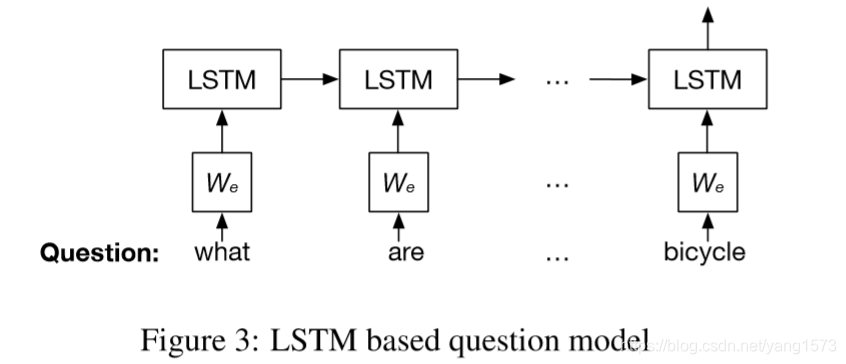
a、LSTM
b、CNN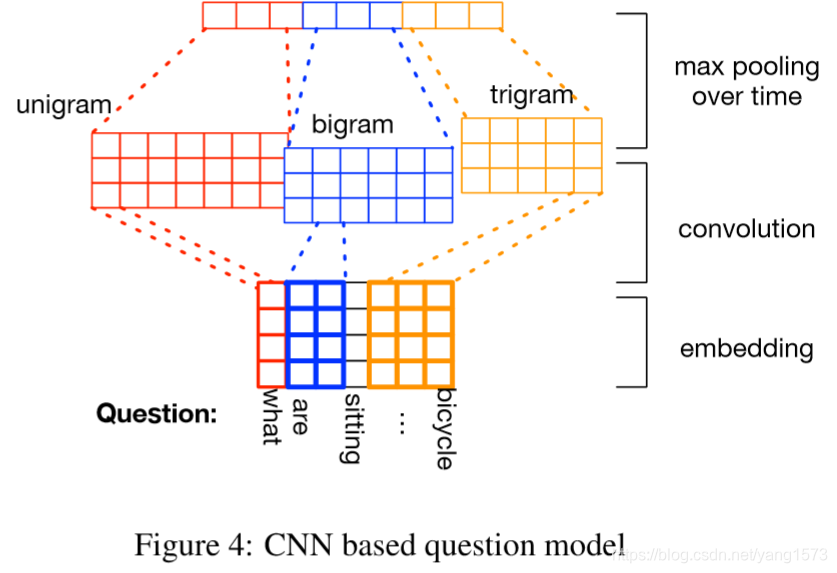
这里的卷积与一维的卷积很类似。使用了卷积核长度分别是1、2、3的卷积。论文的后面说到通道数的选择分别为128,256,256。卷积后池化、拼接。如图所示。
3、堆叠注意力模型
通常问题的解决只需要图中一小部分区域的信息,如果将所有区域完整的特征向量全部应用,会引入噪声影响结果。SAN能够逐步过滤噪声,指出与答案高度相关的区域。
看公式。
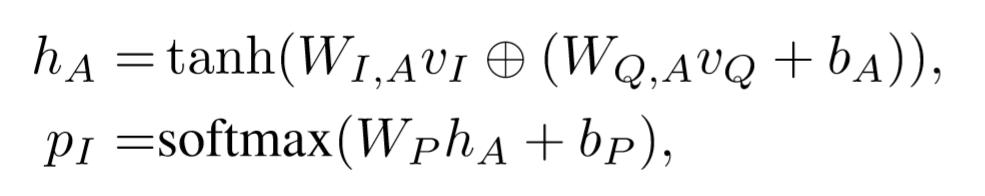
Vi为 d x m 维矩阵,d为图像特征向量的维度,m为区域的个数(14x14)
Vq为d维向量。
⊕ 为矩阵与向量的相加 (broadcast 机制)
这个元素直接相加是最令我疑惑不解的地方,应该是问题决定注意力是否在这一区域,而非两者是并列的关系,直接相加未免过于简单?将单独一区域的图像特征与问题特征拿出来,随便扔进某个小神经网络,最后得出一个数值。对所有区域进行遍历,最后softmax应该效果会更好。不过由于区域数196太多了,如此效率低下的网络不太可行,我猜测 在这里作者应该是考虑到并行化训练的影响,折中采用这种简单的策略,最后测试结果也不差。
得到pi为196个区域各自的注意力大小。
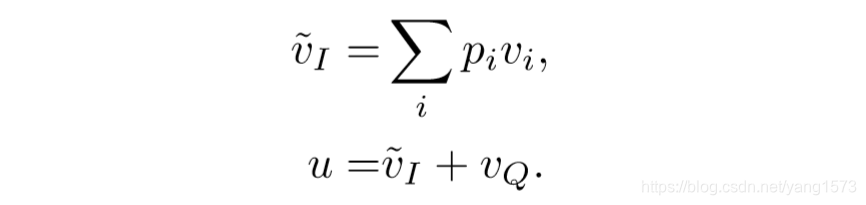
得到加注意力权重之后的图像特征。
综合图像与问题的两个特征的方式是将两个特征向量直接相加。(总觉得如此过于简单)
对于复杂的包含逻辑处理的问题,比如啥东西在车筐里,作者提出可以将上述注意力模型拓展为多层,就像开头的那幅图片,非常的amazing啊。
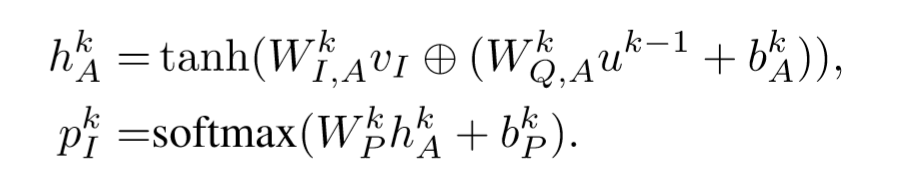
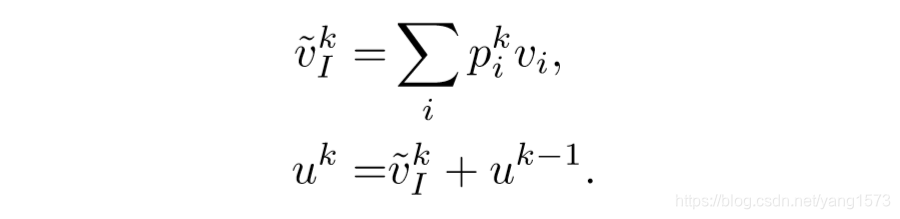

4、网络整体结构
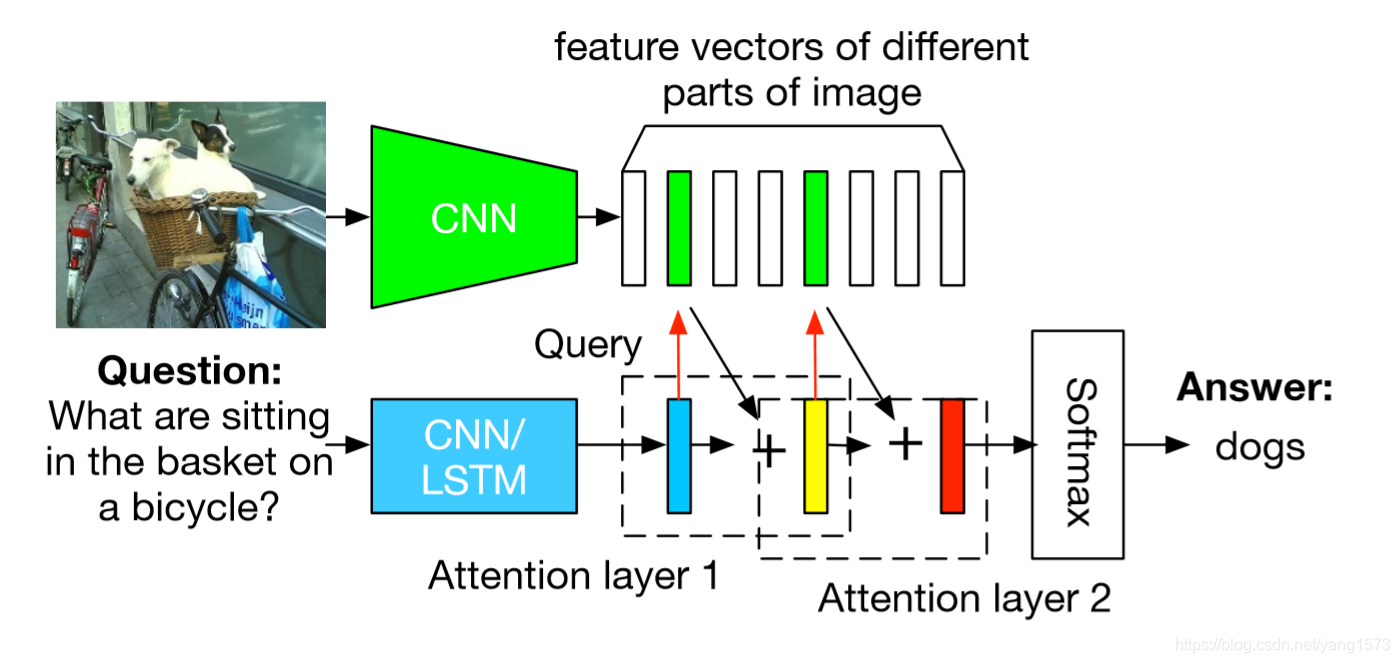
5、注意力层的可视化


















 733
733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









