






 DriveVLM利用VLMs增强自动驾驶理解与规划,通过CoT推理改善性能。DriveVLM-Dual结合传统模块优化特征分析和实时轨迹规划。实验显示其在复杂场景中的优势,尤其是在数据量有限时。作者通过异步系统设计解决了大模型推理速度问题,并探讨了VLM与感知的集成方式和再训练需求。
DriveVLM利用VLMs增强自动驾驶理解与规划,通过CoT推理改善性能。DriveVLM-Dual结合传统模块优化特征分析和实时轨迹规划。实验显示其在复杂场景中的优势,尤其是在数据量有限时。作者通过异步系统设计解决了大模型推理速度问题,并探讨了VLM与感知的集成方式和再训练需求。
概述:
DriveVLM是一种结合了自动驾驶技术和大型视觉语言模型(VLMs)的系统,旨在提高自动驾驶车辆在复杂和长尾场景下的理解能力和规划能力。该系统通过引入一种特殊的思维链(Chain-of-Thought,CoT)推理过程,将场景描述、场景分析和层级规划三个关键模块结合起来,以对应传统的感知、预测和规划流程。此外,DriveVLM-Dual作为一种混合系统,结合了DriveVLM和传统自动驾驶流程的优势,以弥补VLM在空间推理和计算需求方面的局限性。
关键贡献:
- DriveVLM利用VLMs的强大泛化和认知能力,实现了比传统模块更优越的性能。
- DriveVLM-Dual通过与传统感知和规划模块的有选择性交互,提高了特征分析的精度,并实现了实时且更精细的轨迹规划。
- 作者提出了一套挖掘复杂和长尾驾驶场景的数据挖掘流程,并构建了多样化的SUP-AD数据集。
- DriveVLM在提出的SUP-AD和nuScenes数据集上的实验结果证明了其有效性,尤其在少量样本情况下的性能表现,以及DriveVLM-Dual在规划任务上的先进性能。
主要模块:
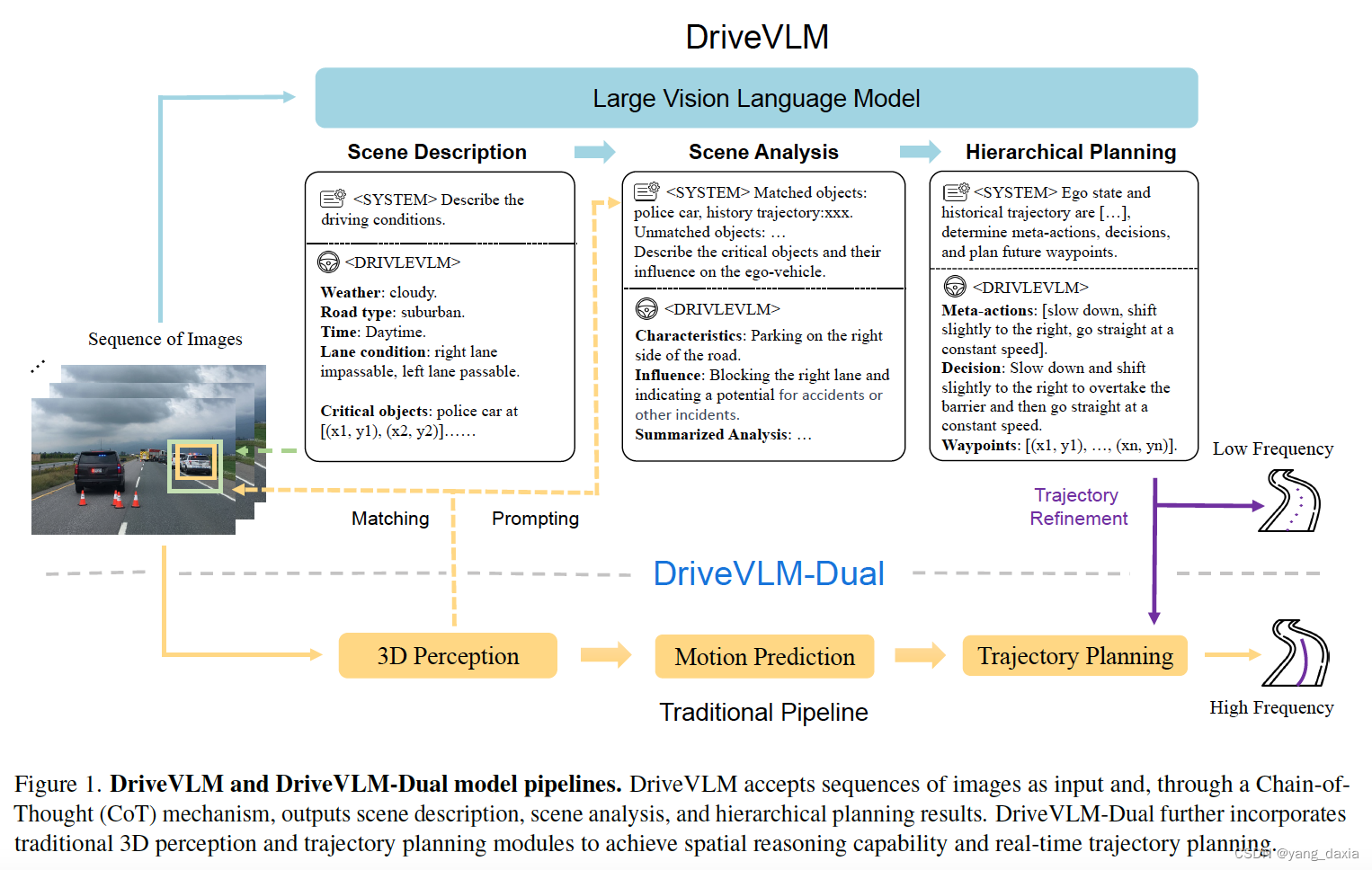
场景描述:包括环境描述和关键物体识别,用于描绘驾驶环境并识别可能影响驾驶决策的关键物体。
场景分析:对关键物体的特征和潜在影响进行分析,包括静态属性、运动状态和特殊行为。
层级规划:通过逐步推理生成驾驶决策的元动作、决策描述和轨迹点。
实验:
细节:VLM:Qwen-VL

作者在SUP-AD和nuScenes数据集上进行了实验,展示了DriveVLM在处理复杂驾驶场景时的有效性。与现有的大型视觉-语言模型相比,DriveVLM在场景描述任务中生成无关信息较少,并且在规划任务的位移误差(L2)和碰撞率(CR)指标上取得了最佳性能。
结论:
DriveVLM和DriveVLM-Dual的提出,为自动驾驶领域带来了新的视角,特别是在处理复杂和长尾场景时,展现了其优越的性能。通过结合VLM的强大能力和传统自动驾驶系统的实时性,这些系统为未来自动驾驶技术的发展提供了新的可能性。
疑问
如何解决大模型推理慢的问题
设计了快慢的异步双系统。单纯的VLM推理很慢,所以作者选择性的将VLM输出的轨迹输入到传统的轨迹预测模块中。如快系统频率10hz,VLM频率1hz。
VLM与感知的交互
将感知的输出框与VLM预测的框匹配结合,作为VLM的prompt


















 1617
1617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











