









24年4月来自北大的论文“A Survey on Self-Evolution of Large Language Models”。
大语言模型(LLM)在各个领域和智体应用中取得了显着的进步。 然而,目前从人类或外部模型监督中学习的LLM成本高昂,并且随着任务复杂性和多样性的增加可能面临性能的天花板。 为了解决这个问题,使LLM能够自主获取、完善模型本身生成的经验并从中学习的自我进化方法,正在迅速发展。 这种受人类体验式学习过程启发的新训练范式提供了将LLM扩展到超级智能的潜力。 这项工作对LLM的自我进化方法进行了全面的调查。 首先提出了自我进化的概念框架,并将进化过程概述为由四个阶段组成的迭代循环:经验获取、经验细化、更新和评估。 其次,对 LLM 和基于 LLM 智体的演化目标进行了分类; 然后总结文献并为每个模块提供分类和见解。 最后,指出现有的挑战并提出了改进自我进化框架的未来方向。
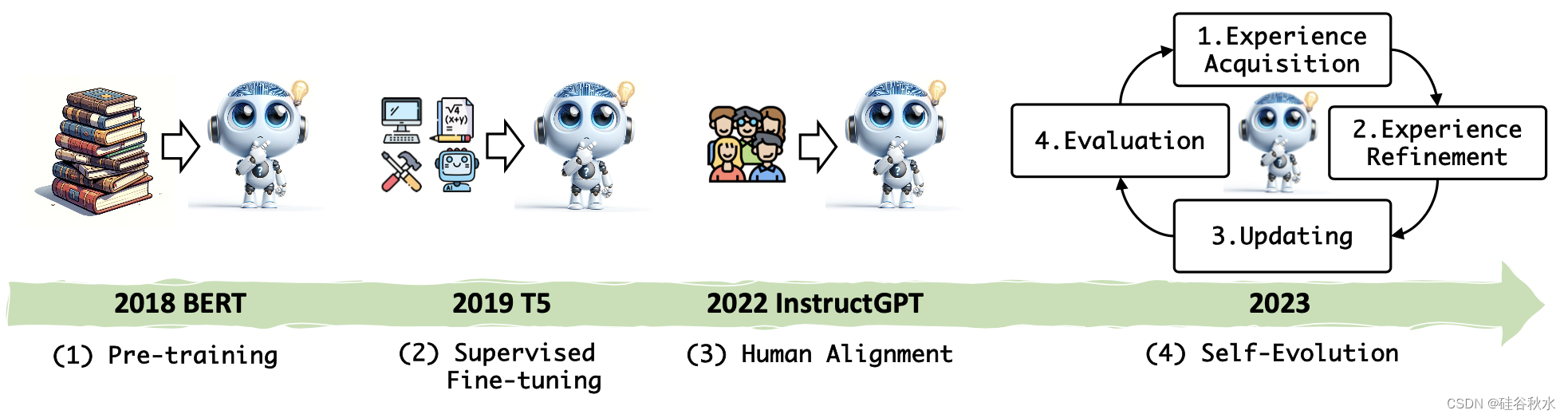
人工智能的自我进化。 人工智能代表了智体的一种高级形式,具有与人类相似的认知能力和行为。 人工智能开发人员的愿望在于使人工智能能够利用自我进化能力,与人类发展的体验式学习过程平行进行。 人工智能中自我进化的概念源于更广泛的机器学习和进化算法领域(Bäck & Schwefel,1993)。 最初受到自然进化原理(例如选择、突变和繁殖)的影响,研究人员开发了模拟这些过程的算法,优化复杂问题的解决方案。 Holland(1992)引入了遗传算法,标志着人工智能自我进化能力历史上的一个基础性时刻。 神经网络和深度学习的后续发展进一步增强了这种能力,允许人工智能系统在无需人工干预的情况下修改自己的架构并提高性能(Liu et al., 2021)。
在自我进化的概念框架中,一个动态的、迭代的过程,反映了人类获取和完善技能和知识的能力。 该框架如图所示,强调学习和改进的循环性质。 该过程的每次迭代都专注于特定的演化目标,允许模型参与相关任务、优化其体验、更新其架构并在进入下一个周期之前评估其进度。

该概念框架概述了LLM的自我进化,类似于人类的获取、完善和自主学习过程,其类别如图所示:
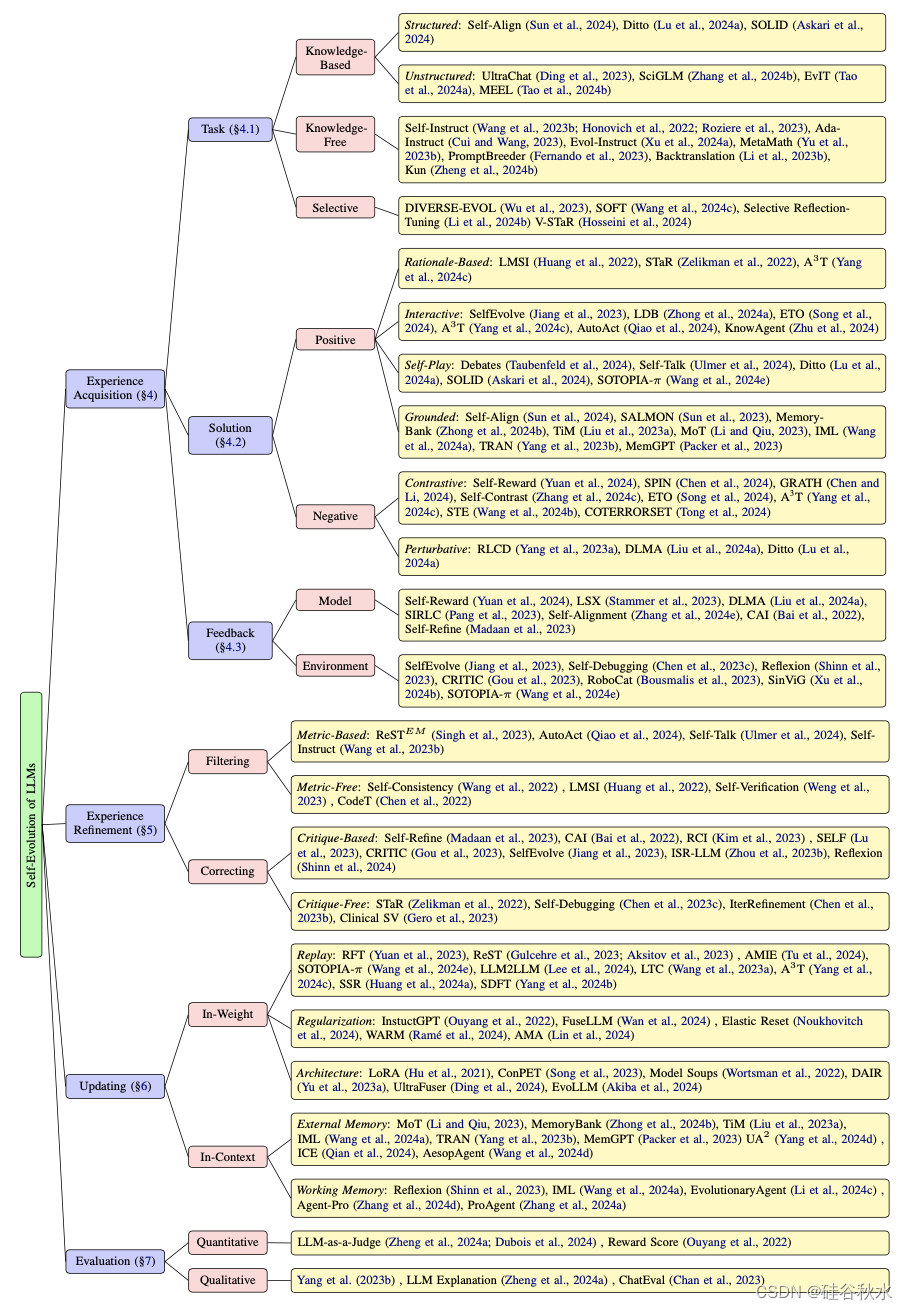
如图是LLM训练范式的变化史:
自我进化LLM的进化目标是预定义的目标,可以自主指导其发展和完善。 就像人类根据需求和愿望设定个人目标一样,这些目标至关重要,因为它们决定了模型如何迭代地自我更新。 它们使LLM能够自主地从新数据中学习、优化算法并适应不断变化的环境,通过反馈或自我评估有效地“感受”其需求,并设定自己的目标来增强功能,而无需人工干预。
进化目标定义为进化能力和进化方向的结合。 不断发展的能力代表着与生俱来的、细致的技能。 进化方向是进化目标旨在改进的方面。
下表是自我进化方法概述,详细介绍了各个进化阶段的方法。 其中:Pos(积极)、Neg(消极)、R(基于基本原理)、I(互动)、S(自我搏击)、G(落地)、C(对比)、P(扰动)、Env(环境) 、In-W(权重内)、In-C(上下文中)、IF(指令跟随)。 对于进化目标,“反馈的适配”为绿色,“知识库扩展”为蓝色,“安全、道德和减少偏见”为棕色。 “提高性能”采用默认的黑色。
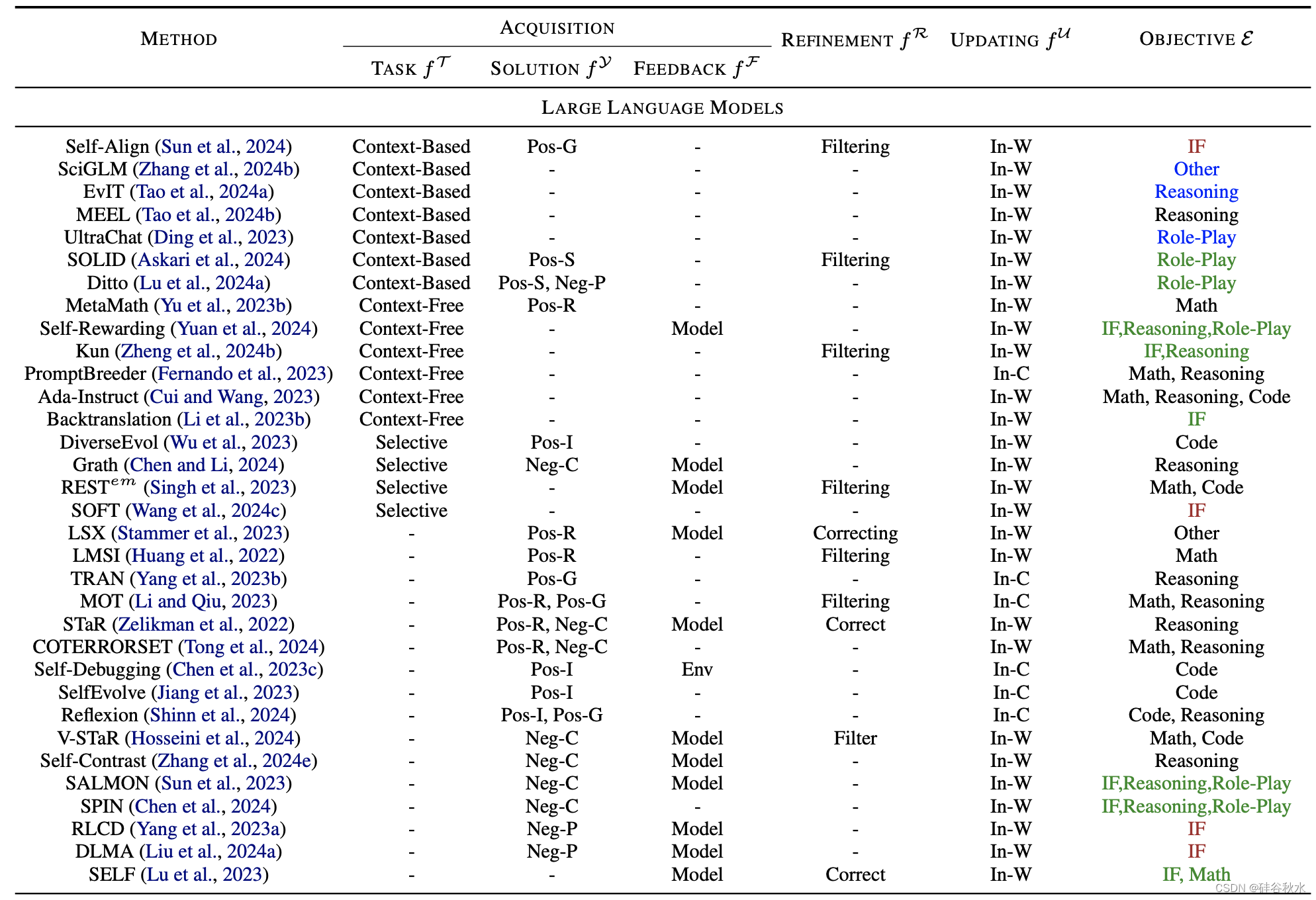
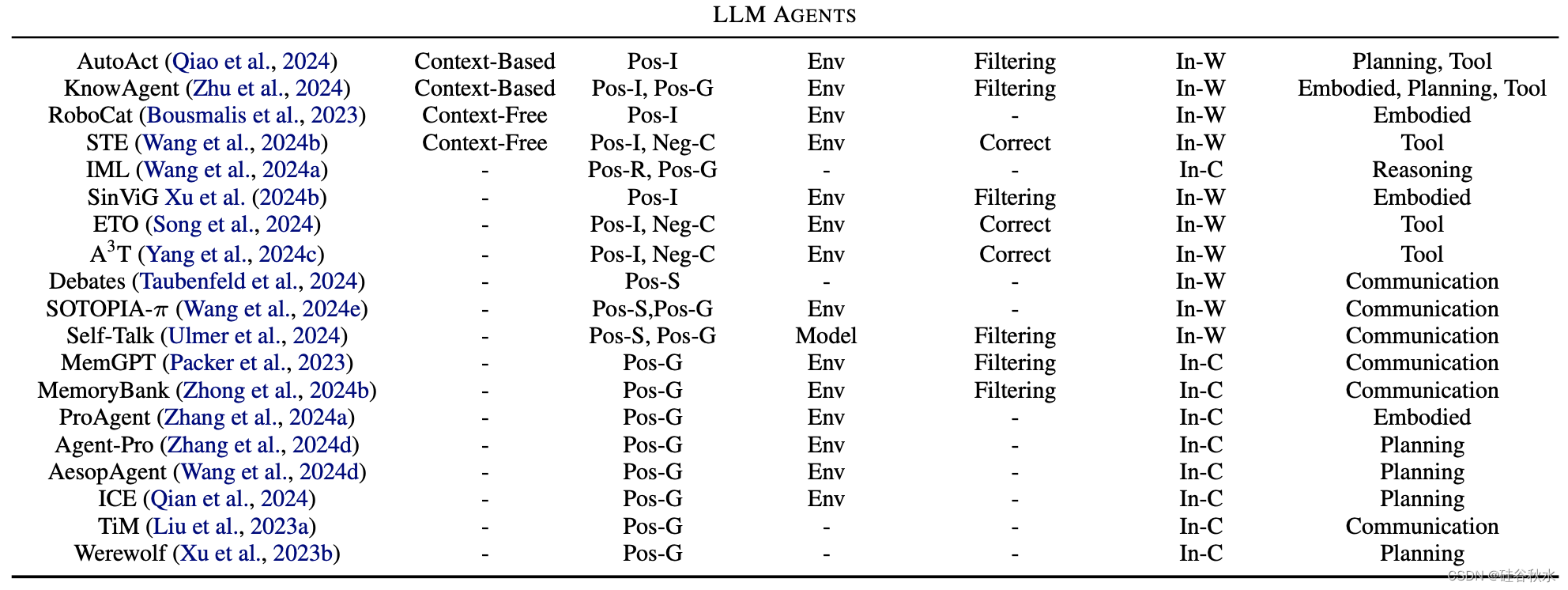
表中目标进化能力分为两类:LLM和LLM智体。
LLM的基本能力包括:遵循指令(Xu 等人,2023a)、推理(Cui & Wang,2023)、数学(Ahn,2024)、编码(Singh ,2023;Zelikman,2023)、角色扮演(Lu et al., 2024a)和其他NLP 任务(Stammer et al., 2023; Koa et al., 2024; Gulcehre et al., 2023; Zhang et al. ., 2024b,c)。
基于LLM的智体能力是用于在数字或物理世界中解决任务或模拟的高级人类特征。 这些功能反映了人类的认知功能,使这些智体能够执行复杂的任务并在动态环境中有效地交互。 包括:规划(Qiao et al., 2024)、工具使用(Zhu et al., 2024)、具身控制(Bousmalis,2023)和沟通(Ulmer et al., 2024)。
探索和利用(Gupta et al., 2006)是人类和LLM学习的基本策略。 其中,探索涉及寻求新的经验以实现目标,类似于LLM自我进化的初始阶段,即经验获取。 这个过程对于自我进化至关重要,使模型能够自主应对核心挑战,例如适应新任务、克服知识限制和增强解决方案的有效性。 此外,经验是一个整体的建构,不仅包括所遇到的任务(Dewey,1938),还包括为解决这些任务而开发的解决方案(Schön,2017)以及作为任务执行的结果而收到的反馈(Boud et al.,2013)。
受此启发,经验获取分为三个部分:任务进化、解决方案进化和获取反馈。 在任务进化中,LLM根据进化目标策划和进化新的任务。 对于解决方案的进化,LLM制定并实施策略来完成这些任务。 最后,LLM可以选择收集与环境交互的反馈,以进一步改进。
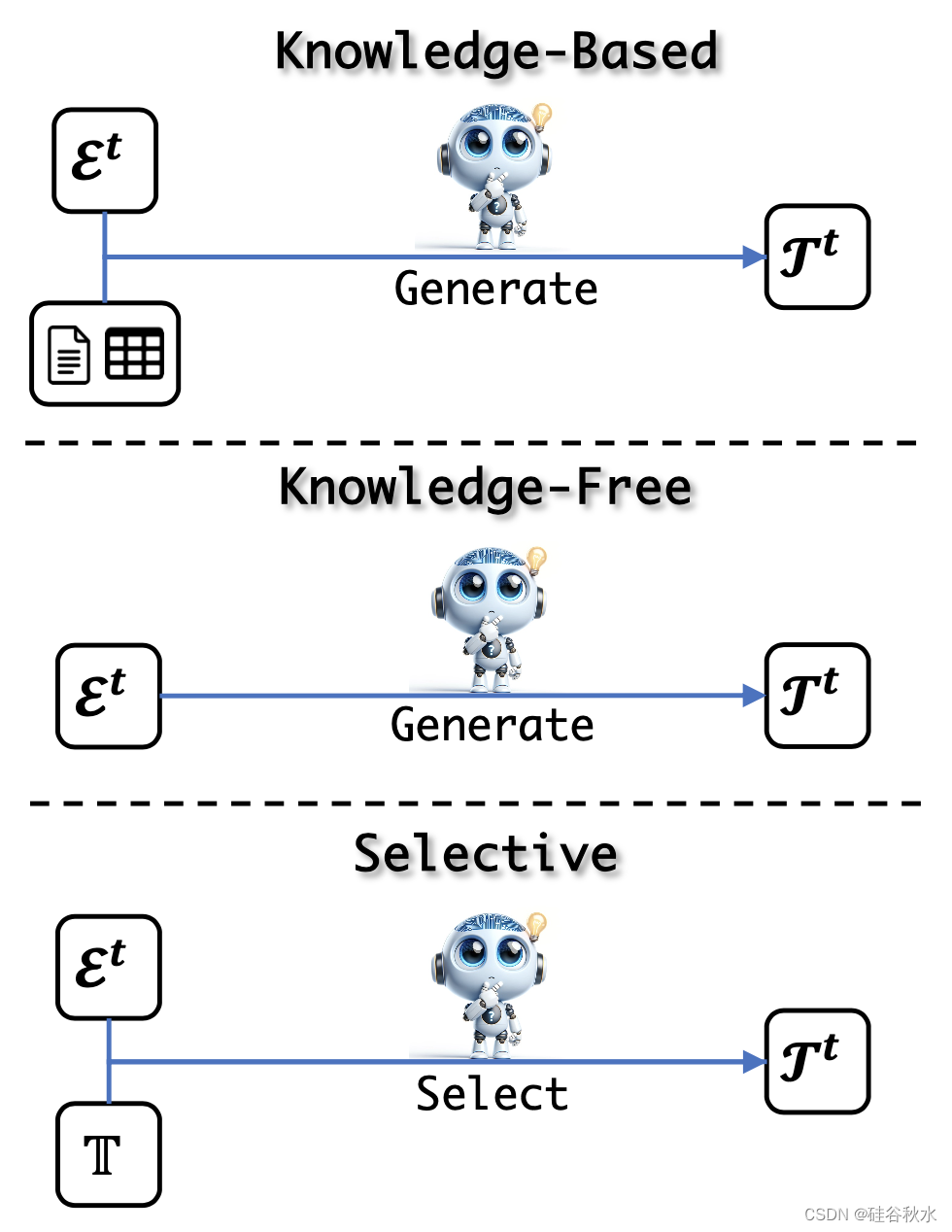
如图所示任务进化示意图:基于知识、无知识和选择方法;前两种是生成方法,根据各自对知识的使用而有所不同;相比之下,第三种方法采用判别性方法来选择要学习的内容。
获得进化任务后,LLM解决任务以获得相应的解决方案。 最常见的策略是直接根据任务公式生成解决方案(Zelikman et al., 2022; Gulcehre et al., 2023; Singh et al., 2023; Cheng et al., 2024b; Yuan et al., 2024 )。 然而,这种简单的方法可能会得到与进化目标无关的解决方案,从而导致次优进化(Hare,2019)。 因此,解决方案的进化使用不同的策略来解决任务并通过确保解决方案不仅生成而且具有相关性和信息性来增强LLM能力。 如图所示:
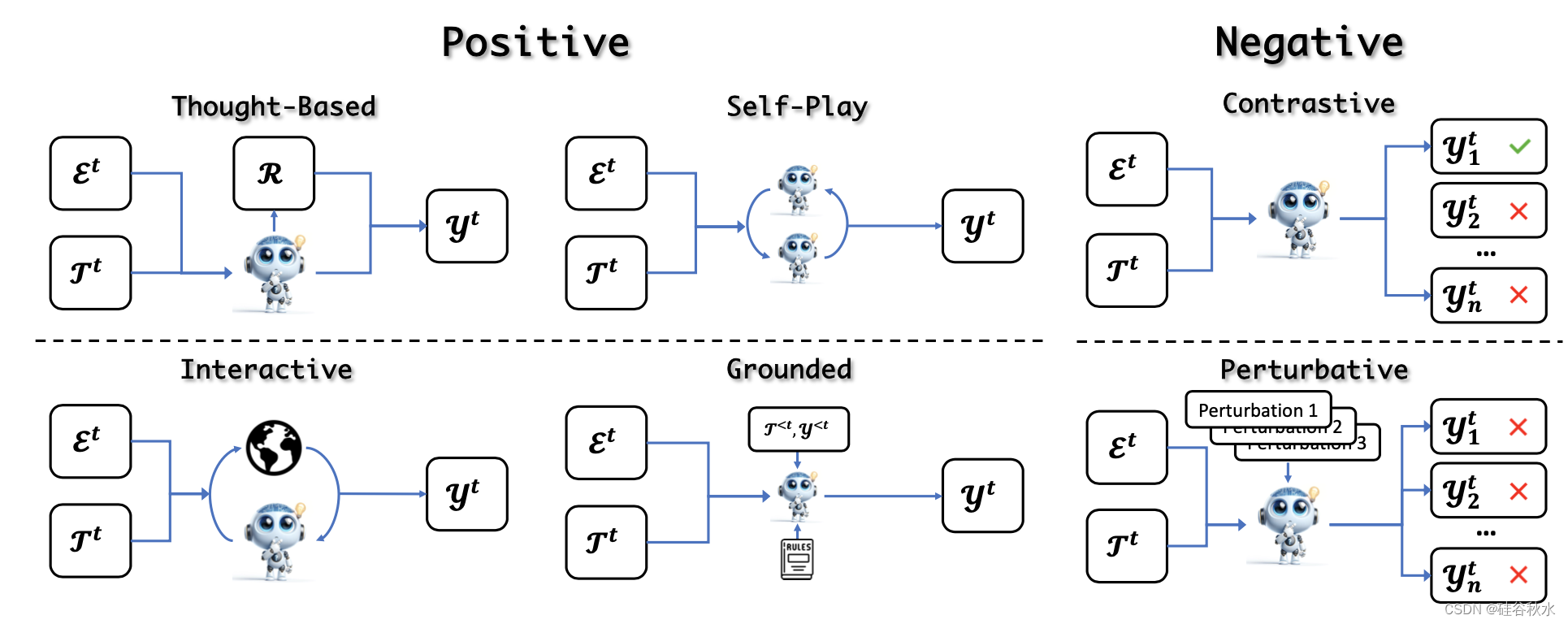
根据解决方案的正确性将这些方法分为积极方法和消极方法。 积极方法引入了各种方法来获得正确且理想的解决方案。 相反,消极方法会引出并收集不需要的解决方案,包括不忠实或不一致的模型行为,然后将其用于偏好对齐。
当人类学习技能时,反馈在证明解决方案的正确性方面发挥着至关重要的作用。 这些关键信息使人类能够反思并更新他们的技能。 与此过程类似,LLM应该在自我进化周期中的任务解决期间或之后获得反馈。
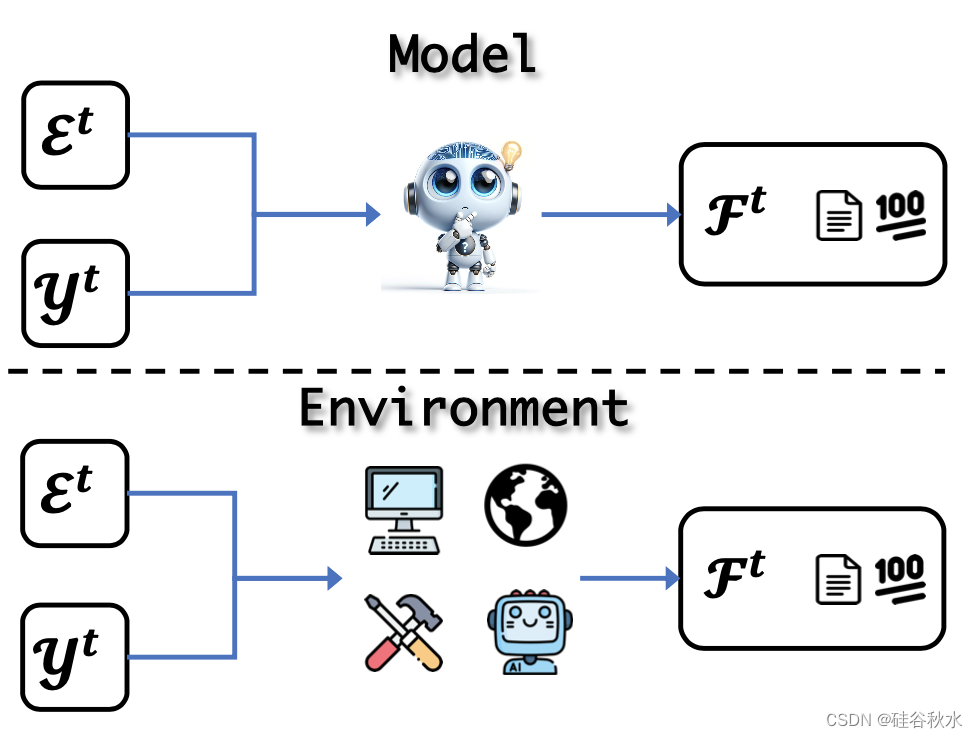
存在两种类型的反馈:模型反馈是指收集LLM自己评价的批评或评分;此外,环境反馈表示直接从外部环境收到的反馈。 如图所示这些概念:
在获得经验之后和自我进化更新之前,LLM可以通过经验细化来提高其输出的质量和可靠性。 它帮助LLM适应新的信息和环境,而无需依赖外部资源,从而在动态环境中获得更可靠、更有效的帮助。这些方法分为两类:过滤和修正。如图所示:
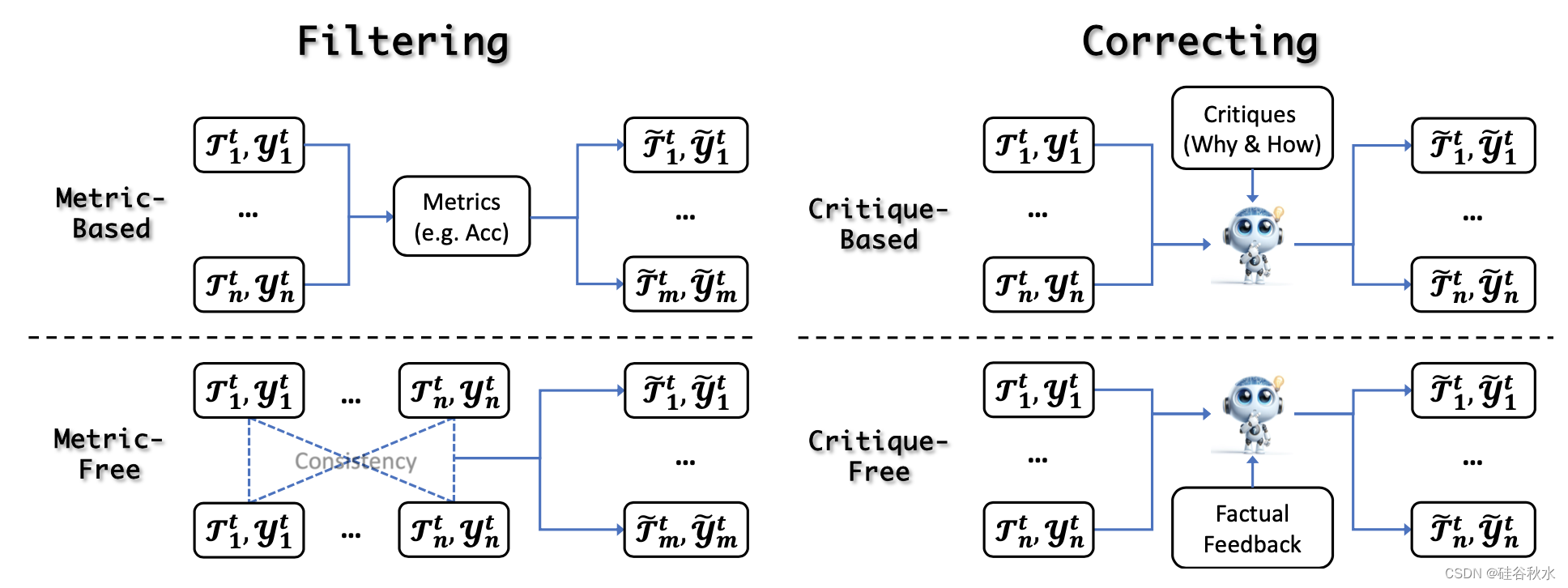
自我进化的经验细化涉及两种主要的滤波策略:基于度量和无度量。 前者使用外部指标来评估和过滤输出,而后者不依赖这些指标。 这确保了只有最可靠和高质量的数据才能用于进一步更新。
自我进化的最新进展凸显了迭代自我修正的重要性,它使模型能够完善其经验。 把方法分为两类:基于批评的纠正和无批评的纠正。 批评通常作为强烈的暗示,包括感知错误或次优输出背后的基本原理,指导模型改进迭代。
经验细化后,进入关键的更新阶段,利用细化的经验来提高模型性能。这些方法分为权重学习(涉及模型权重的更新)和上下文学习(涉及外部或工作记忆的更新)。如图所示:
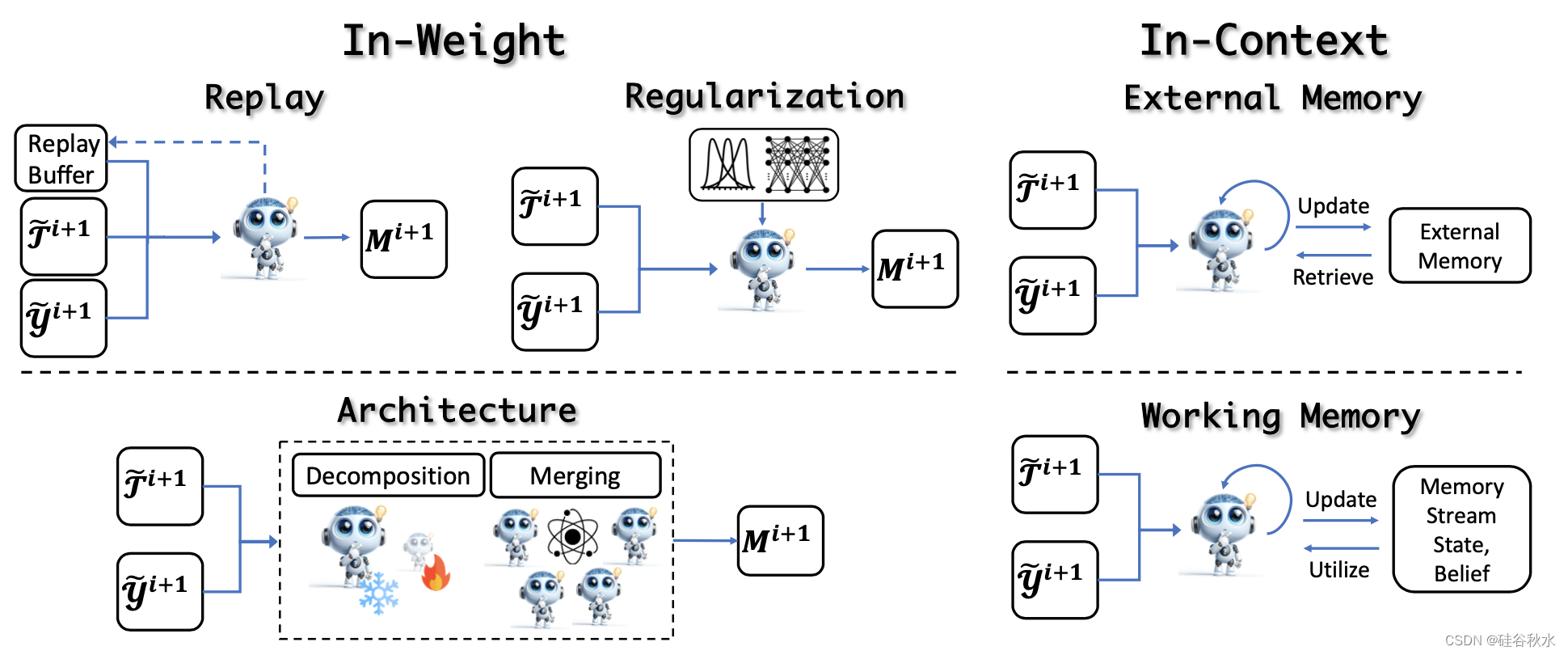
更新LLM权重的经典训练范式包括连续预训练(Brown et al., 2020; Roziere et al., 2023)、有监督微调(Longpre et al., 2023)和偏好对齐(Ouyang et al., 2022;Touvron,2023a)。 然而,在自我进化的迭代训练过程中,核心挑战在于实现整体改进并防止灾难性遗忘,这需要在保留原有技能的同时提炼或获取新的能力。 这一挑战的解决方案可以分为三种主要策略:**基于重放、基于正则化和基于合并(架构)**的方法。
除了直接更新模型参数之外,另一种方法是利用LLM的上下文能力从经验中学习,从而无需昂贵的培训成本即可实现快速自适应更新。 这些方法可分为更新外部记忆和更新工作记忆。
就像人类的学习过程一样,必须通过评估来确定当前的能力水平是否足够,是否满足应用要求。此外,正是从这些评估中,人们可以确定未来学习的方向。然而,如何准确评估进化模型的性能并为未来的改进提供方向是一个至关重要但尚未充分探索的研究领域。其方法分成定量和定性两种。
自我进化方法存在的开放问题:
分级和多样。
自动化级别:低、中、高。
经验获取和细化:从经验到理论。
更新方法:稳定性-可塑性困境。
评估:系统和进化。
安全和超对齐。

















 271
271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









