







24年3月Arcee公司的论文“Arcee’s MergeKit: A Toolkit for Merging Large Language Models”。
开源语言模型领域的快速扩展提供了通过组合参数来合并这些模型检查点(checkpoint)能力的机会。 迁移学习(针对特定任务微调预训练模型的过程)的进步导致了大量特定任务模型的开发,这些模型通常专门针对单个任务,无法利用彼此的优势。 模型合并(model merging)有助于创建多任务模型,而无需额外的训练,为增强模型性能和多功能性提供了一条有希望的途径。 通过保留原始模型的内在功能,模型合并解决了人工智能中的复杂挑战,包括灾难性遗忘和多任务学习的困难。 为了支持这一不断扩大的研究领域,提出 MergeKit,一个综合性的开源库,旨在促进模型合并策略的应用。 MergeKit 提供了一个可扩展的框架,可以在任何硬件上有效地合并模型,为研究人员和从业者提供实用性。 迄今为止,开源社区已经合并了数千个模型,从而创建了一些世界上最强大的开源模型检查点,正如 Open LLM 排行榜所评估的那样。
GitHub - github.com/arcee-ai/MergeKit
模型合并(Ainsworth,2022)虽然是研究界相对较新的焦点,但它建立在大量先前研究奠定的基础上。 从本质上讲,模型合并涉及将两个或多个预训练模型(无论它们是针对相同任务还是不同架构进行训练)集成到一个统一模型中,该模型保留所有原始模型的优势和功能。 其中大部分建立在探索权重平均(weight averaging)的概念之上,例如 Utans (1996)。 这些技术的成功依赖于模式连接的概念(Garipov ,2018)。 在最简单的情况下,技术利用从一个从常见预训练模型(Nagarajan&Kolter,2019;Neyshabur,2021)微调后模型的线性模式连接(LMC)(Entezari ,2021)。 其他工作基于这一概念,通过采用排列对称性并对模型权重进行变换,将模型带入损失域中的公共区域(Ainsworth,2022;Stoica,2023;Verma & Elbayad,2024) 。
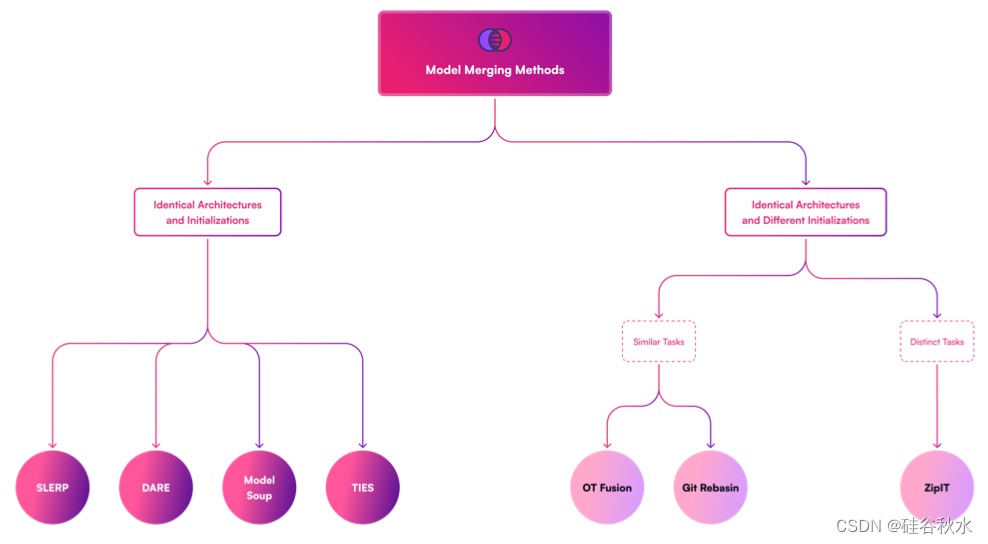
在工具包的开发过程中,如图所示,对现有的和预期的模型合并技术进行分类。 这种系统分类旨在增强对功能的理解,重点关注两个关键方面:权重初始化和各种检查点的架构配置。目前支持图中左侧概述的模型合并方法,并且正在积极努力合并其他合并技术,例如 ZipIt、OT Fusion 和 Git Rebasin。
注:在 HuggingFace Transformers 中,检查点通常是指训练期间模型的保存版本。 它是模型参数以及训练过程中特定点可能相关信息快照。 检查点的用途有多种,包括:恢复训练、微调、模型评估和部署。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 171
171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









