









23年10月来自密西根大学和中科院的论文“A Comprehensive Survey on Vector Database: Storage and Retrieval Technique, Challenge”。
向量数据库用于存储传统 DBMS 无法表征的高维数据。向量数据库背后的ANN搜索问题已经研究了很长时间,在文献中可以找到大量相关算法文章。本文试图全面回顾相关算法,提供这一研究领域的总体了解。本文框架的基础是按照解决 ANNS 问题的方法将这些研究分类,分别是基于哈希、基于树、基于图和基于量化的方法。然后概述向量数据库现有的挑战。最后,概述如何将向量数据库与大语言模型相结合并提供新的可能性。
向量数据库与传统数据库相比有几个优势:
1 快速准确的相似性搜索和检索。向量数据库可以根据向量距离或相似性找到最相似或最相关的数据,这是许多涉及自然语言处理、计算机视觉、推荐系统等应用程序的核心功能。传统数据库只能根据精确匹配或预定义标准查询数据,这可能无法捕获数据的语义或上下文含义。
2 支持复杂和非结构化数据。向量数据库可以存储和搜索具有高复杂性和高粒度的数据,例如文本、图像、音频、视频等。这些类型的数据通常是非结构化的,不太适合传统数据库的严格模式。向量数据库可以将这些数据转换为捕获其特征或属性的高维向量。
3 可扩展性和性能。向量数据库可以处理大规模实时数据分析和处理,这对于现代数据科学和人工智能应用至关重要。向量数据库可以使用分片、分区、缓存、复制等技术来分配工作负载并优化跨多台机器或集群的资源利用率。传统数据库在处理大数据时可能会面临可扩展性瓶颈、延迟问题或并发冲突等挑战。
存储
A. 分片
分片是一种根据某些标准(例如哈希函数或Key距离)将向量数据库分布到多台机器或集群(称为分片)上的技术。分片可以提高向量数据库的可扩展性、可用性和性能。
分片在向量数据库中工作的一种方法是使用基于哈希的分片方法,该方法根据一个Key列或一组列的哈希值将向量数据分配给不同的分片。这样,用户可以将向量数据均匀分布在分片上并避免热点。
分片在向量数据库中工作的另一种方法是使用基于距离的分片方法,该方法根据一个Key列或一组列的Value距离将向量数据分配给不同的分片。这样,用户可以通过指定分片名称或距离更有效地查询向量数据。
B. 分区
分区是一种根据某些标准(如地理位置、类别或频率)将向量数据库划分为更小且易于管理的部分(称为分区)的技术。分区可以提高向量数据库的性能、可扩展性和可用性。
在向量数据库中进行分区的一种方式是使用距离分区方法,该方法根据Key列或一组列的Value距离将向量数据分配到不同的分区。用户可以通过指定分区名称或范围更有效地查询向量数据。
矢量数据库中分区的另一种工作方式是使用列表分区方法,该方法根据Key列或一组列的Value列表将矢量数据分配到不同的分区。用户可以通过指定分区名称或列表更轻松地查询矢量数据。
C. 缓存
缓存是一种将经常访问或最近使用的数据存储在快速且可访问的内存(如 RAM)中的技术,以减少延迟并提高数据检索的性能。缓存可用于矢量数据库,以加快矢量数据的相似性搜索和检索。
矢量数据库中缓存的一种工作方式是使用LRU策略,当缓存已满时,该策略会从缓存中逐出LRU矢量数据。这样,缓存可以存储最相关或最流行的矢量数据,这些数据可能会再次被查询。例如,流行的内存数据库Redis使用LRU缓存来存储矢量数据并支持矢量相似性搜索。
矢量数据库中缓存的另一种工作方式是使用分区缓存,它根据某些标准(例如地理位置、类别或频率)将矢量数据划分为不同的分区。每个分区可以有自己的缓存大小和驱逐策略,具体取决于矢量数据的需求和使用情况。这样,缓存可以为每个分区存储最合适的矢量数据并优化资源利用率。例如,地理信息系统(GIS)公司Esri使用分区缓存来存储矢量数据并支持地图渲染。
D.复制
复制是一种创建矢量数据的多个副本并将其存储在不同节点或集群上的技术。复制可以提高矢量数据库的可用性、耐用性和性能。
矢量数据库中复制的一种工作方式是使用无主复制方法,该方法不区分主节点和次节点,并允许任何节点接受写入和读取请求。无主复制可以避免单点故障,提高矢量数据库的可扩展性和可靠性。但是,它也可能引入一致性问题,需要协调机制来解决冲突。
矢量数据库中复制的另一种工作方式是使用主从复制方法,该方法将一个节点指定为主节点,将其他节点指定为从节点,并且只允许主节点接受写入请求并将其传播给从节点。主从复制可以确保强一致性并简化矢量数据库的冲突解决。但是,它也可能引入可用性问题,并且需要故障转移机制来处理主节点故障。
搜素
最近邻搜索 (NNS) 是在给定集合中查找与给定点最接近(或最相似)的点的优化问题。接近度通常用相异函数来表示:目标越不相似,函数值越大。
近似最近邻搜索 (ANNS) 是 NNS 的一种变型,允许搜索结果中存在一些误差或近似值。ANNS 可以在准确性和速度和空间效率之间进行权衡,这对于大规模和高维数据非常有用。
NNS
- 暴力法:一种非常简单和朴素的算法,它扫描数据集中的所有点并计算到查询点的距离,跟踪迄今为止的最佳点。该算法保证找到任何查询点的真正最近邻,但计算成本很高。时间复杂度为 O(n),其中 n 是数据集的大小。
- 基于树的方法:四种基于树的方法,即 KD 树、Ball 树、R 树和 M 树。
ANNS
1)基于哈希的方法:三种方法,即局部敏感哈希、谱哈希(spectral hashing)和深度哈希。其思想是通过比较二进制代码而不是原始向量来减少内存占用和搜索时间[8]。
2)基于树的方法:三种方法,即近似NN、最佳箱(bin)优先和 K -均值树。其思想是通过跟踪最有可能包含查询点的最近邻树的分支来减少搜索空间。
3)基于图的方法:两种方法,即可导航小世界和分层可导航小世界。
4)基于量化的方法:三种方法,即积量化、优化积量化和在线积量化。积量化通过比较码而不是原始向量,可以减少内存占用和 ANN 搜索的搜索时间 [28]。
主要的挑战
A. 高维向量的索引构建与搜索
B. 异构向量数据类型支持
C. 分布式并行处理支持
D. 与主流机器学习框架集成
大语言模型
1)数据:通过从大量预训练文本数据中学习,LLM 可以获得各种涌现能力,这些能力在较小的模型中不存在,但在较大的模型中存在,例如,上下文学习、思维链和指令跟踪 [36],[37]。
数据的能力又可以从三个方面展开:
数据规模。这是用于训练 LLM 的数据量。根据 [38],即使没有有针对性的创新,LLM 也可以随着数据规模的增加而可预测地提高其能力。
数据质量。这是用于训练 LLM 的数据的准确性、完整性、一致性和相关性。数据质量越高,LLM 就越可靠和稳健 [39],这可以帮助它们避免错误和偏差。
数据多样性。这是用于训练 LLM 的数据的多样性和丰富性。数据越多样化,LLM 就越具有包容性和可推广性,这可以帮助它们处理不同的语言、领域、任务和用户。
对于向量数据库来说,传统的数据库技术如清洗,去重,对齐等可以帮助LLM获得高质量、大规模的数据,并且向量形式的存储也适合多样化的数据。
2)模型:除了数据之外,LLM 还受益于模型规模的增长。大量的参数给模型训练和存储带来了挑战。向量数据库可以帮助 LLM 在这方面降低成本并提高效率,体现在以下方面:
分布式训练。
模型压缩。
向量存储。
3)检索:用户可以使用大语言模型根据查询或提示生成一些文本,但输出可能不够丰富、不一致、不真实。向量数据库可以根据具体情况改善这些问题,提升用户体验,包括以下方面:
- 跨模态支持。
- 实时知识。
- 较少幻觉。
向量数据库和 LLM 可以协同工作,以增强彼此的功能,并创建更智能、更具交互性的系统。以下是向量数据库在 LLM 上的一些潜在应用:
- 长期记忆:向量数据库可以通过以向量形式存储相关文档或信息,为 LLM 提供长期记忆。
- 语义搜索:向量数据库可以允许用户根据文本的含义而不是关键字搜索文本,从而为 LLM 实现语义搜索。
- 推荐系统:向量数据库可以根据向量表示查找相似或互补的条目,为 LLM 的推荐系统提供支持。
在向量数据库的 LLM 也非常有趣且前景广阔。以下是向量数据库上 LLM 的一些潜在应用:
- 文本生成:LLM 可以基于来自向量数据库的向量输入生成自然语言文本。
- 文本增强:LLM 可以使用来自向量数据库的附加信息或详细信息来增强现有文本。
- 文本转换:LLM 可以使用 VDB 将文本从一种形式转换为另一种形式。
关于基于检索的 LLM,那么
- 定义:基于检索的 LLM 是一种从外部数据存储中检索的语言模型(至少在推理期间)[46]。
- 优势:基于检索的 LLM 是 LLM 和数据库的高级协同作用,与单独的 LLM 相比具有多种优势如下。
- 记忆长尾知识。基于检索的 LLM 可以访问外部知识源,这些知识源包含比预训练的 LLM 参数更具体、更多样化的信息。
- 易于更新。基于检索的LLM 可以根据用户输入从数据源中动态检索最相关、最新的文档。
- 更适合解释和验证。基于检索LLM可以生成引用其信息来源的文本,这允许用户验证信息并可能根据需求更改或更新底层信息。
- 改进的隐私保障。基于检索LLM可以通过使用加密和匿名化技术查询数据源来保护用户的隐私。
- 减少时间和金钱成本。基于检索LLM 可以通过减少运行 LLM所需的计算和存储资源来为用户节省时间和金钱。
3)推理:推理涉及数据流的多个部分。
- 数据存储。数据存储可以非常多样化,它可以只有一种模态,例如原始文本语料库,也可以是集成不同模态数据的向量数据库,它对数据的处理决定了后续检索的具体算法。
- 索引。当用户输入查询时,可以将其作为检索的输入,然后使用特定算法找到最接近查询的数据存储小子集,对于向量数据库,具体算法是前面提到的NNS 和 ANNS 算法。
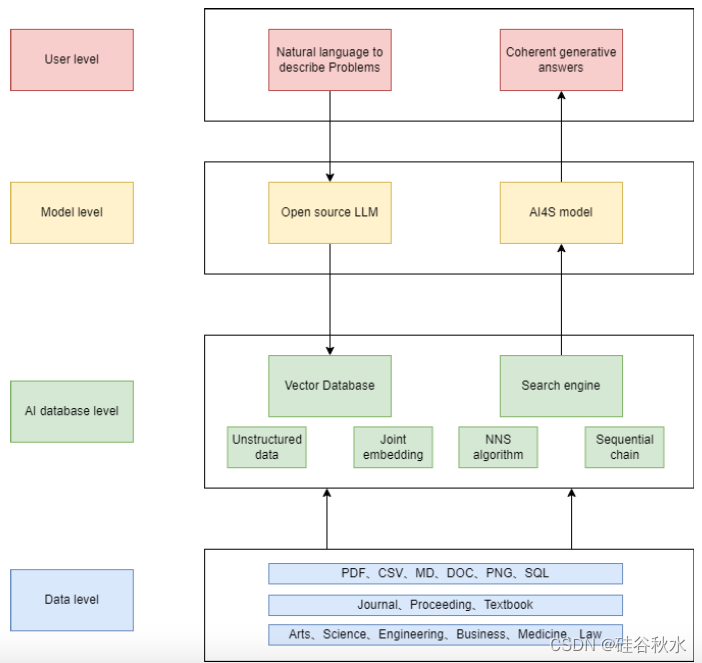
对于一个包含大语言模型和向量库的工作流程,可以分为四个层次来理解:用户层、模型层、AI数据库层和数据层。对于一个从未接触过大语言模型的用户,可以输入自然语言来描述问题。对于精通大语言模型的用户,可以输入精心设计的提示。接下来,LLM会处理问题,提取其中的关键词,或者在开源LLM的情况下,直接获得相应的向量嵌入。
向量库和LLM的结合工作流如图所示:
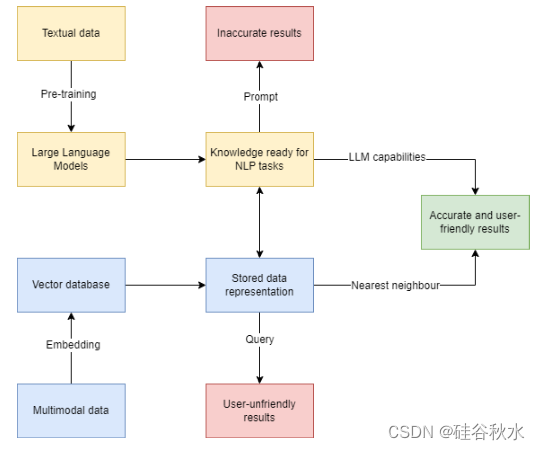
向量库会存储非结构化数据及其联合嵌入。下一步是去向量库中寻找相似的最近邻居。通过NNS或ANNS算法,将从大语言模型中的序列中获得的相似最近邻居与向量数据库中的向量编码进行比较。并通过预定义的序列化链得出不同的结果,该链充当搜索引擎的角色。
如果不是泛化问题,得出的结果需要进一步放入域模型中,获得连贯的生成结果。
对于位于最底层的数据层,可以从多种文件格式中选择,例如PDF,CSV,MD,DOC,PNG,SQL等,其来源可以是期刊,会议,教科书等。对应的学科可以是艺术,科学,工程,商业,医学,法律等。
如图是LLM和向量库在科学研究的一个复杂工作流:

















 1030
1030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









