










25年5月来自UC Berkeley、丰田汽车北美分公司和普林斯顿大学的论文“Learning to Drive Anywhere with Model-Based Reannotation”。
开发可泛化的机器人视觉导航策略是一项重大挑战,主要受限于能否获得大规模、多样化的训练数据。虽然研究人员收集的精选数据集质量较高,但其有限的规模限制了策略的泛化。为了克服这一问题,本文探索利用丰富的被动收集数据源,包括大量众包遥操作数据和未标记的 YouTube 视频,尽管这些数据可能质量较低或缺少动作标签。提出的基于模型重标注 (MBRA) 框架,利用已学习的短视域(short - horizon)、基于模型的专家模型为这些被动数据集重标注或生成高质量动作。这些重标注的数据随后被蒸馏为 LogoNav,这是一种以视觉目标或 GPS 航点为条件的长视域(long - horizon)导航策略。用 MBRA 处理数据训练的 LogoNav 达到最佳性能,能够在未见过的室内和室外环境中实现超过 300 米距离的稳健导航。在三大洲、六座城市的机器人队伍(包括四足机器人)上进行广泛的真实世界评估,验证该策略即使在拥挤的行人环境中也能有效泛化和导航。
机器学习已在一系列任务中展现出显著的成功,包括自然语言处理 [1, 2] 和计算机视觉 [3, 4, 5]。推动这些进步的关键因素之一是拥有海量且多样化的训练数据集。在机器人技术领域,数据匮乏是一个主要瓶颈:有针对性的集中式数据收集成本高昂,需要现实世界中的机器人和人类操作员,而从互联网上抓取的数据很少能直接应用于机器人领域 [6, 7]。
本文研究开发一种端到端机器人导航策略的问题,该策略能够泛化到室内外环境,并导航至数百米外的远距离目标。训练这种端到端策略需要大量多样化的数据,以广泛覆盖所有可能的环境。之前的导航研究 [8] 依赖于机器人研究人员生成后集中收集的数据集。虽然这些数据集通常质量较高,但这些数据集的总时长也只有数十小时 [9],这限制了仅凭这些高质量数据所能实现的泛化范围。
面对这种数据限制,将注意转向利用更丰富的被动数据源——缺乏动作或仅提供低质量动作标签的数据。例如,由庞大用户群以去中心化方式收集的众包数据,与中心化方式收集的数据相比,具有更高的状态覆盖率和更丰富的环境。然而,由非专业演示者进行远程数据收集的挑战性使得直接针对此类数据集中动作训练良好的策略变得困难。自然视频是另一种包含多样化环境并能实现更泛化性能的被动数据源。然而,自然视频根本没有相关的动作。
基于视觉的机器人导航(VN)。VN 已被广泛探索,旨在根据单目摄像机的视觉观测结果导航至目标位置。[10, 11, 12] 训练短视界策略,以生成可访问单个目标观测的动作。这些短视界策略通常利用拓扑记忆来扩展导航范围 [13]。一些研究 [14] 使用拓扑记忆进行探索以寻找远处的图像目标,而另一些研究 [15, 16] 使用 GPS 信号进行定位,并导航至以笛卡尔坐标中的 2D 位置提供的目标。目标图像和姿态需要事先访问目标环境并了解环境的几何形状。人们已经探索了各种学习方法,例如模仿学习 (IL) [10, 8, 9]、强化学习 (RL) [16, 17, 18] 和基于模型的学习 (MBL) [12, 19],用于在公开的机器人数据集上训练基于目标条件的视觉策略。这些方法需要从精确的车轮里程计 [12, 20]、GPS [14] 和其他可靠传感器解析出一系列图像观测和相应的动作。这些数据集是通过有意识的、集中式的远程操作收集的,其下游目标是训练导航策略,因此包含目标导向的轨迹。在全球范围内收集此类数据需要大规模的统一工作,这将耗费大量成本和时间。
被动数据的机器人学习。视觉 SLAM [21] 和逆动力学模型 [22] 可用于估计第一人称视频的轨迹,能够训练策略,将这些轨迹作为机器人动作的近似值,这些动作来自无动作和非机器人数据。虽然视觉 SLAM 及其后续技术 [23, 24, 25, 26] 提供了良好的局部轨迹估计,但其准确性依赖于图像视图中一致且良好的视觉特征。使用 IL 在精选数据上训练的机器人基础模型 (RFM) [9, 27] 可以解决具身差距问题,并通过一致的机器人动作增强被动数据源 [28]。然而,当前的 RFM 仍然缺乏对多样化环境的覆盖,并且无法在训练期间利用带有噪声动作标签的被动数据。为了解决这些问题,用 MBL 训练了一个专家重标注 MBRA 模型,以更好地逼近合理的机器人动作。由于 MBL 在训练期间对噪声动作标签具有鲁棒性,可以使用被动数据源训练 MBRA 模型,并使用它来重新标注大量被动数据,从而缩小具身差距。然后,可以训练 LogoNav,它可以成功执行各种长距离导航任务,并展示出相对于基线策略的明显优势。
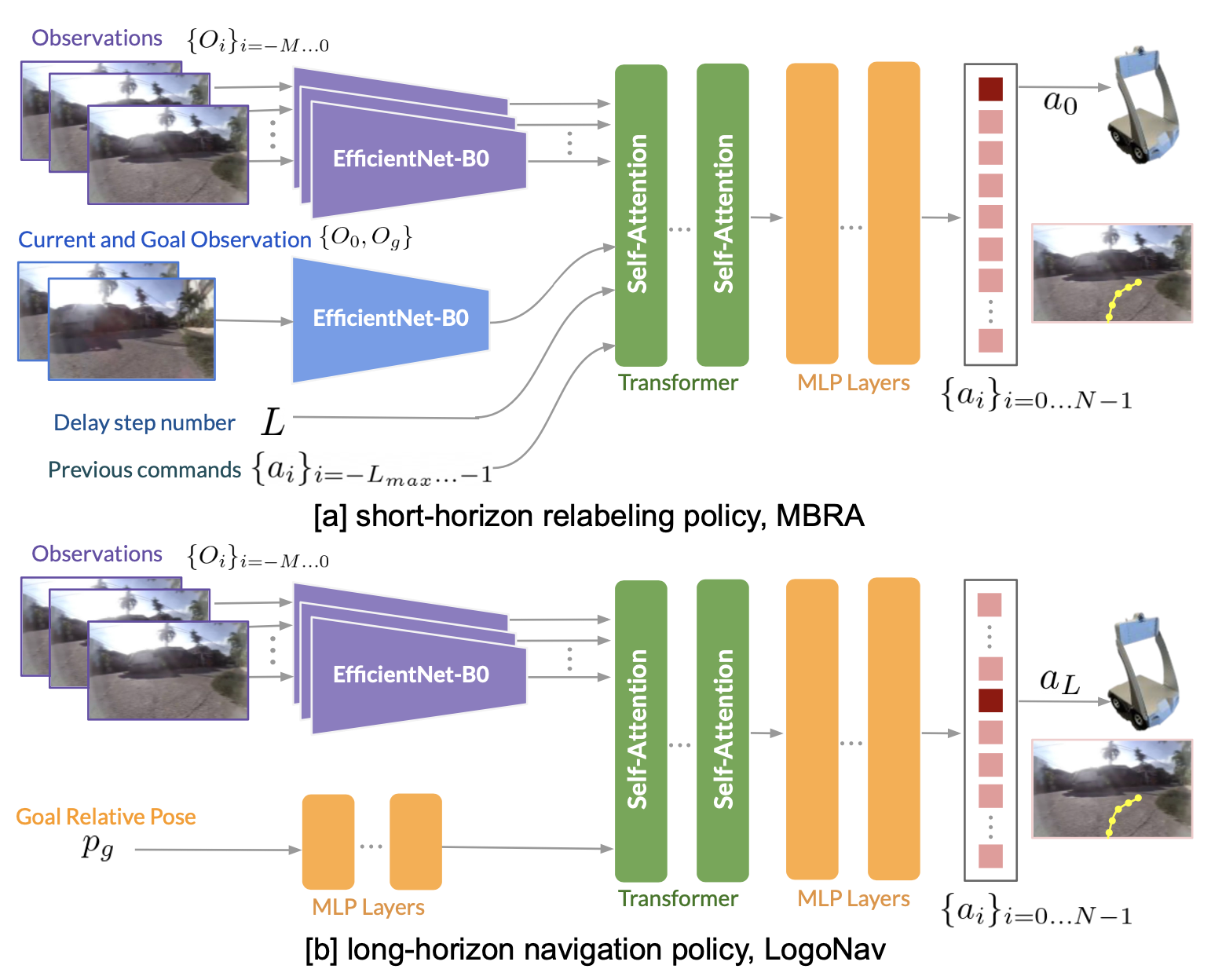
为了能够使用这些廉价、可扩展的数据源,本文提出一种基于稳健模型的学习方法,用于训练一个短期专家重标注模型,以生成连接两个邻近状态的高质量动作。用这个短期重标注模型来标注被动数据集中的动作,从而获得比原始数据集更清晰、更高质量的动作。然后,该重标注模型的输出被蒸馏为长视界策略,该策略可根据视觉目标或未来的 GPS 航点进行调整,以实现长距离导航。如图所示:
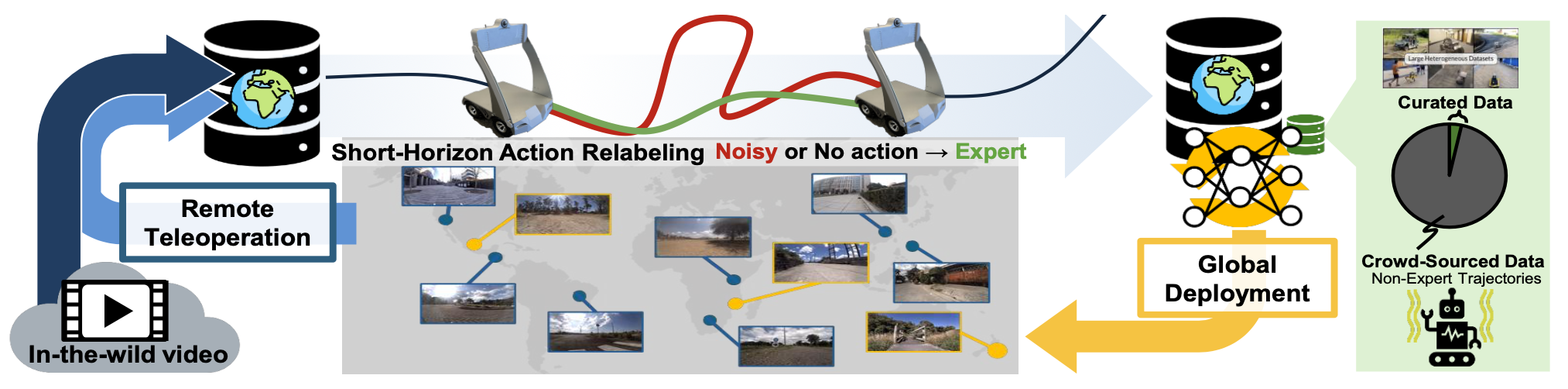
对全球部署的一系列低成本机器人以及包括四足机器人在内的各种实例进行全面的评估,发现该系统能够在三大洲的六个不同城市中展现出强大的泛化性能。
本文专注于从高度多样化但次优的数据集 D_n 中学习长距离导航策略。具体而言,希望从众包数据集中学习高质量的导航;这需要训练一个重标注器,使其能够预测比原始数据集中更好的行为。假设可以访问一个规模较小的干净数据集 D∗,其中包含高质量行为,并且 |D^∗| << |D_n|。虽然 D_n 中的观测值可能代表较高的状态覆盖率,但其行为质量较低:这既是因为状态估计误差导致的不准确性,也是因为未经筛选且技能水平参差不齐的人类操作员的异质性。提出的方法分为两步(如图所示):步骤 1),用 MBL 学习一个基于模型的重标注模型,从噪声数据中学习;步骤 2),训练一个长距离导航策略来模仿第一步重标注的行为。
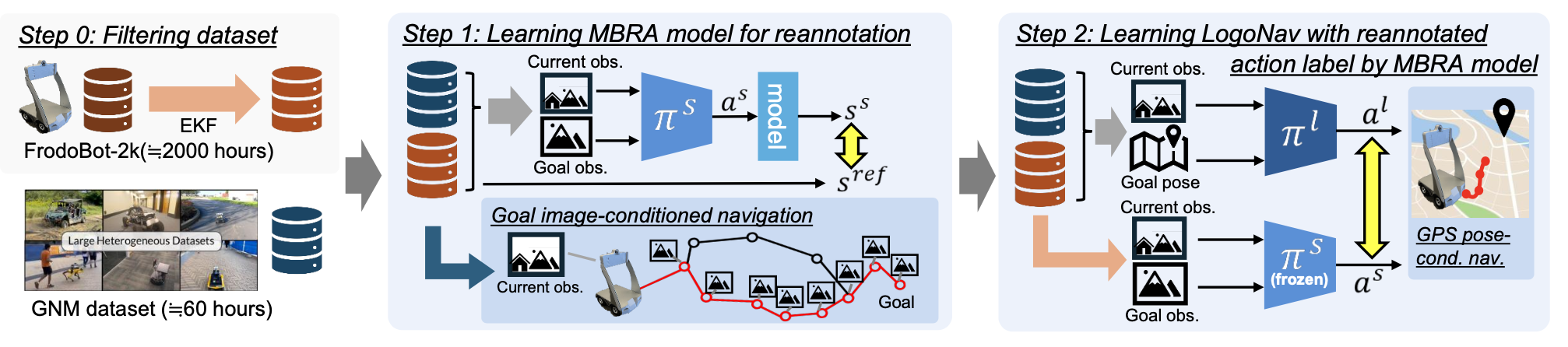
学习短期重标注模型 (MBRA)
训练一个模型 {as_i} = π_s(O_c;O_g),称之为 MBRA 模型,通过受模型预测控制 (MPC) 启发的学习方法,推断当前观测值 O_c 和目标观测值 O_g 之间的最优动作。其方法直接优化目标函数,而不是模仿数据集的动作。在联合数据集 D_n ∪ D∗ 上训练 πs。
采用以下基于模型的目标函数来学习 πs,遵循 Hirose [19] 的先前研究:
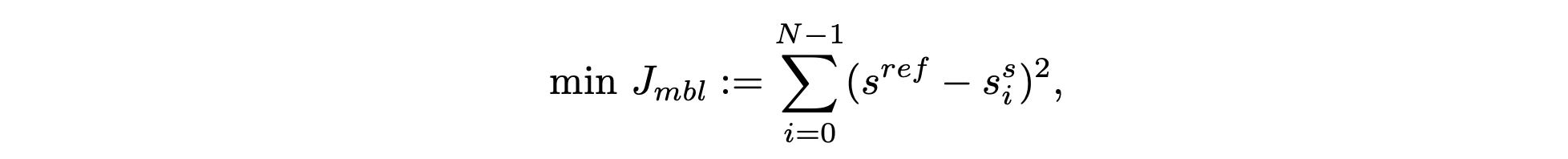
ss_i 由三个部分定义:[pˆ_i , cˆ_i , ∆as_i ],用于确保策略平稳地向目标位姿 p_g 移动而不会发生碰撞。其中,pˆ_i 表示第 i 个虚拟机器人位姿,cˆ_i 表示第 i 个虚拟机器人位姿 pˆ_i 处的估计碰撞状态(0 表示无碰撞),∆as_i 表示动作差异,as_i+1 − as_i。因此,将目标(target)状态 s^ref 定义为 [p_g , 0.0, 0.0]。
状态 {ss_i } 是通过可微分的前向动力学模型 f(在本例中为单轮车模型)计算展开得到的。该前向模型考虑了当前观测值 O_c 和由短视域 MBRA 模型 πs [29] 生成的动作 {a^s_i }:
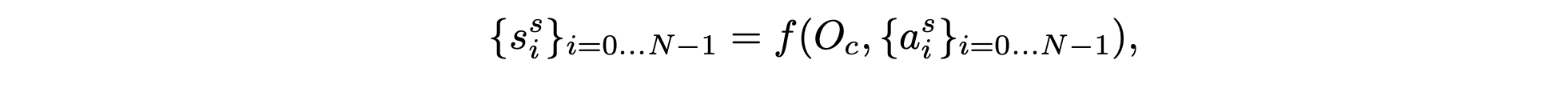
虽然状态 {ss_i} 取决于动作 {as_i} 且 f 可微,但可以在每个训练步骤中计算 πs 的梯度以最小化 J_mbl,并通过重复更新 πs 的参数来学习 πs,类似于其他机器学习方法。在训练 πs 期间,不会修改前向动力学模型 f。
需要注意的是,虽然除了 D∗ 之外,仍在次优数据集上训练 πs,但并未直接模仿动作。通过依赖前向模型 f 和合理的远距离目标姿态 p_g,可以减轻次优动作标签以及噪声跟踪信息的影响。因此,尽管动作质量较低,MBRA 模型仍然可以利用视觉和行为多样化的数据集。
学习长视界导航策略 LogoNav
为了训练长视界导航策略,首先用学习的 πs 重新标注众包数据集 D_n。这样可提供一组清晰的动作标签,可以蒸馏成端到端导航策略 πl。希望导航策略 πl 能够预测如下动作:
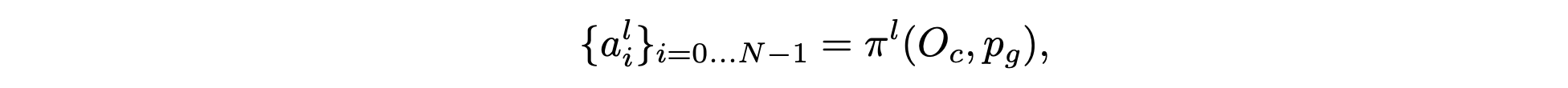
注:二维相对目标姿态 p_g 比短视域重标注模型的常规目标姿态至少远 10 倍,约为 50 米,而之前的距离只有 3 米。使用模仿学习,对短视域重标记模型中重标注的动作命令 {a^s_i} 进行训练,如下所示:
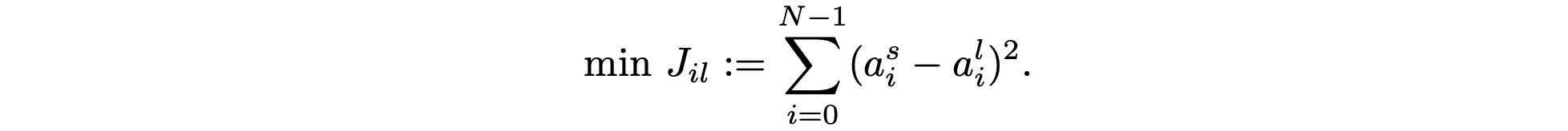
通过模拟连接 O_c 和 O_g 的清理动作命令,长视域策略 LogoNav 可以学习导航功能,例如保持在路径上、避免碰撞以及不干扰行人,这代表 MBRA 模型所建模的“良好”导航行为。需要注意的是,在重标注的 D_n 和高质量数据集 D∗ 上进行联合训练。在训练 πl 时,会冻结 πs。
训练细节
短时域重标注模型 MBRA 和长时域导航策略 LogoNav 的训练设置。
短时域重标注模型:由于机器人系统在通过互联网操控远程机器人时存在 L 步系统延迟 [42,43],在设计目标和网络架构时考虑系统延迟,以防止出现过冲或在目标轨迹附近震荡。受模型预测控制 [44, 45] 的启发,考虑机器人状态与先前动作命令 {a_i} 之间的关系,以生成动作 {a_i}。
在训练中,为了与 GNM 数据集保持一致,将轨迹采样的观测和动作速率设置为 3 Hz。训练期间,从整个数据集中随机选择一个图像帧作为当前观测,然后从未来最多 N_g = 20 步(约 7 秒)中随机选择一个目标帧。距离目标较短能够学习精确的标签,从而重标注 O_c 和 O_g 之间的动作。
长视界导航策略:对于长视界导航,使用较大的 N_g = 100 来采样未来最多 33 秒的目标位置。使用短视界 MBRA 模型重标注动作,以获取 FrodoBots-2k 数据集的高质量动作标签。此过程生成块大小为 N = 8 步的动作标签。使用与短视界重标注模型相同的参数和设置,在 IL 目标 J_il 上进行训练。
评估设置
具体描述用于评估方法的短视域和长视域导航任务及其相关基准。
短视域导航策略:短视域导航策略可以将机器人导航至最远 3 米外的目标,因此使用拓扑记忆使机器人能够导航至更远的目标位置,类似于其他基于视觉的导航方法 [10, 12, 9]。为了收集此目标循环,遥控机器人并以 1 Hz 的固定帧速率记录图像观测值。为了部署该策略,从初始观测值开始,并在每个时间步持续估计最近的节点作为当前节点,遵循 [9, 27]。将下一个节点的图像作为目标图像 O_g 输入到策略中,以计算下一步动作。
长视域导航策略:长视域导航策略可以导航至距离机器人初始位姿 25 至 100 米之间的目标。依靠 GPS(室外)和追踪摄像头 [46](室内)获取机器人位置并指定目标。通过设置多个间隔约 80 米的子目标来评估更长的轨迹。在每个时间步,计算当前相对目标位姿 p_g 与下一个目标位姿之间的相对关系。当 |p_g| < 5.0 米时,目标已达成,并更新到下一个子目标以获得更长的轨迹。
使用与收集 FrodoBots-2k 数据集相同的机器人平台 Earth Rover Zero (ERZ) 来获得主要评估结果,并使用不同的机器人平台进行跨实例分析。
如图所示网络架构:除了视觉观测之外,还将延迟步骤和先前的动作输入到基于模型的学习目标中,以考虑系统延迟。对于长视域导航策略,将用于当前和目标观测的视觉编码器替换为用于目标位姿的 MLP 层。
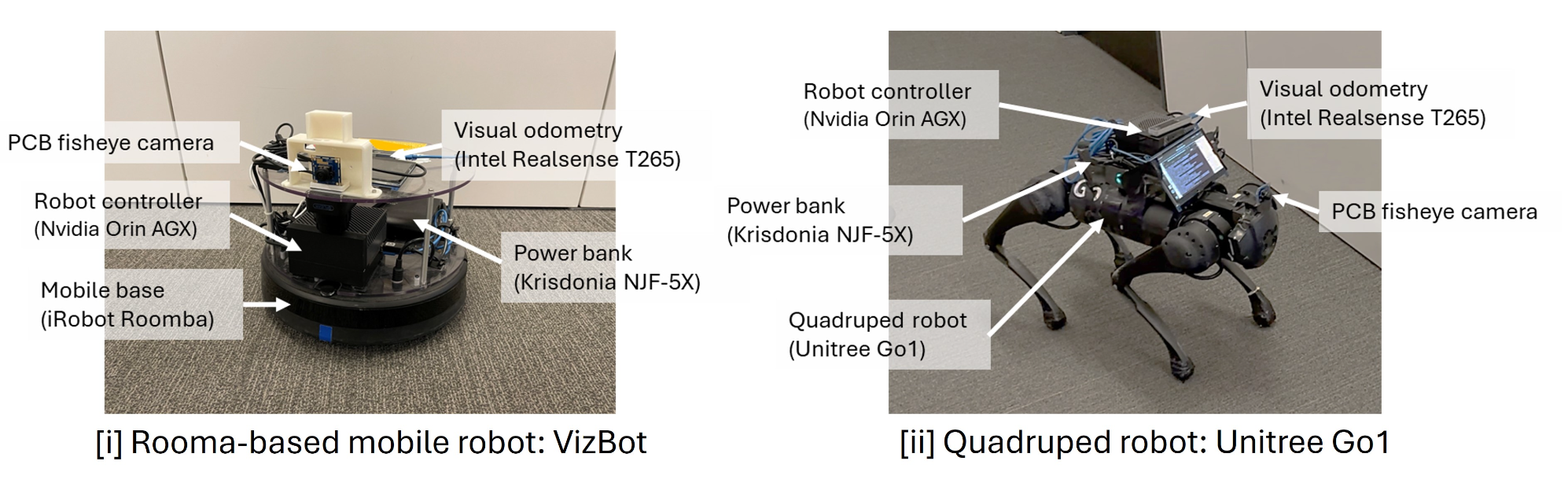
使用三个机器人平台进行评估,即FrodoBot“Earth Rover Zero”(ERZ)、VizBot和四足机器人Go 1。
如图所示:ERZ 可以通过 4G 互联网连接进行控制,以进行游戏和数据收集以及部署导航策略。
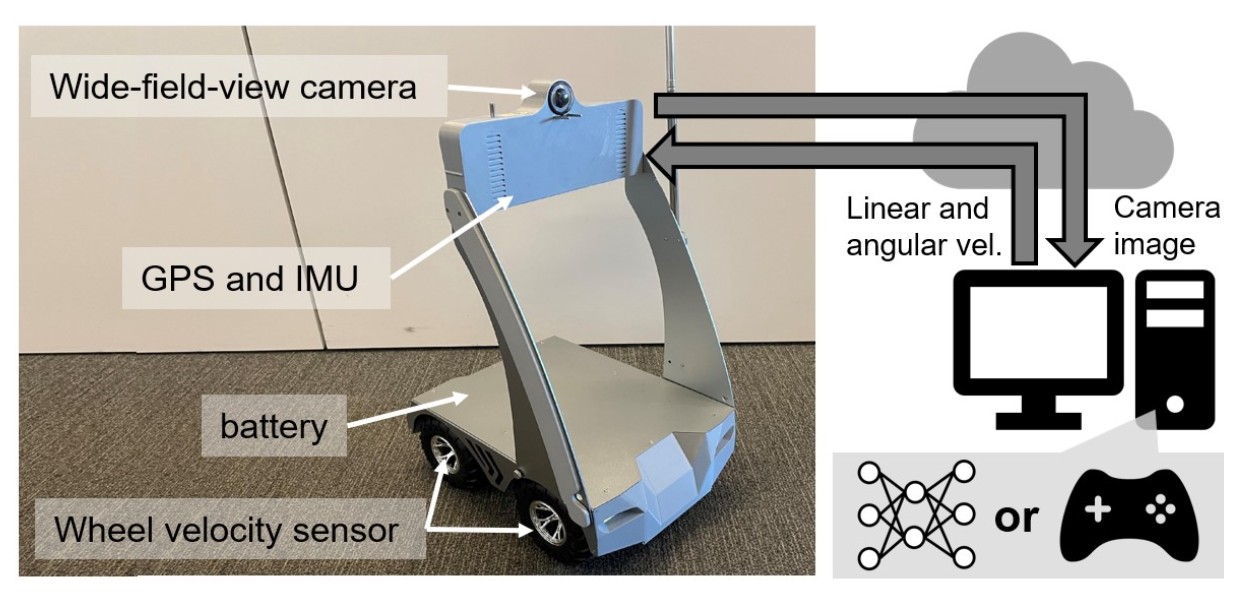
如图所示:机器人平台 VizBot 和 Go 1 概述。这些机器人安装与 ERZ 不同的摄像头,可以通过搭载 ROS 的 Nvidia Orin AGX 上的板载机器人控制器进行控制。

















 1584
1584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









