










24年5月来自哈工大、香港科技大学和美团的论文“Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts”。
多模态大语言模型 (MLLM) 的最新进展强调了可扩展模型和数据对提升性能的重要性,但这通常会产生大量的计算成本。尽管混合专家 (MoE) 架构已被用于有效扩展大语言和图像-文本模型,但这些努力通常涉及较少的专家和有限的模态。为了解决这个问题,提出一种具有 MoE 架构的统一 MLLM,称为 Uni-MoE,它可以处理多种模态。
具体来说,它具有特定于模态的编码器和连接器,实现统一的多模态表示。还在 LLM 中实现稀疏 MoE 架构,通过模态级数据并行和专家级模型并行实现高效的训练和推理。为了增强多专家协作和泛化能力,提出一种渐进式训练策略:1)使用具有不同跨模态数据的各种连接器进行跨模态对齐,2)使用跨模态指令数据训练特定模态专家,激活专家的偏好,3)利用LoRA在混合多模态指令数据上调整 Uni-MoE 框架。在一组全面多模态数据集上评估指令调优后的 Uni-MoE。结果表明,Uni-MoE 的主要优势在于显著减少处理混合多模态数据集时的性能偏差,同时改善了多专家协作和泛化能力。
代码开源 GitHub - HITsz-TMG/UMOE-Scaling-Unified-Multimodal-LLMs
虽然之前的研究已经证明了 MoE 在构建纯文本和图像文本大模型方面的成功应用,但开发 MoE 架构以构建强大的统一 MLLM 仍然基本上是未知的,例如,扩展 MLLM 以纳入 4 个以上的专家并将其应用扩展到图像和文本以外的模态。
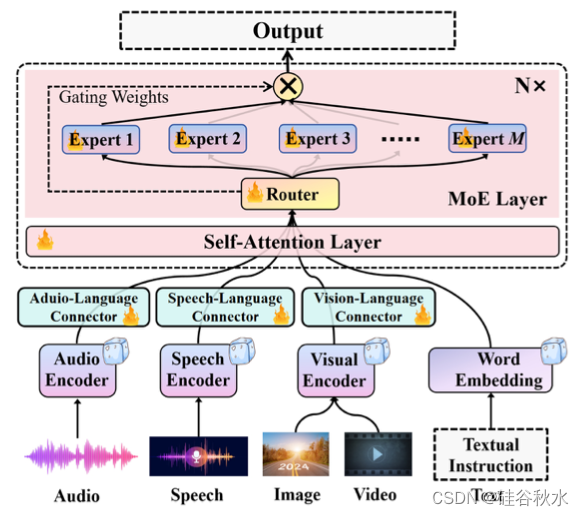
Uni-MoE 可以利用稀疏 MoE 熟练地管理和解释多种模态,如图所示,首先使用模态特定编码器来获得不同模态的编码,并通过设计的各种连接器将它们映射到 LLM 的语言表示空间中。它们包含一个可训练的Transformer模型,随后的线性投影层分别用于提取和投影冻结编码器的输出表示。然后,在密集 LLM 的内部块中引入一个稀疏 MoE 层。因此,每个基于 MoE 的块都具有一个适用于所有模态的共享自注意层、基于前馈网络 (FFN) 的多样化专家以及用于分配 token 级专业知识的稀疏路由器。通过这种方式,Uni-MoE 可以理解多种模态,例如音频、语音、图像、视频和文本,在推理中只激活部分参数。
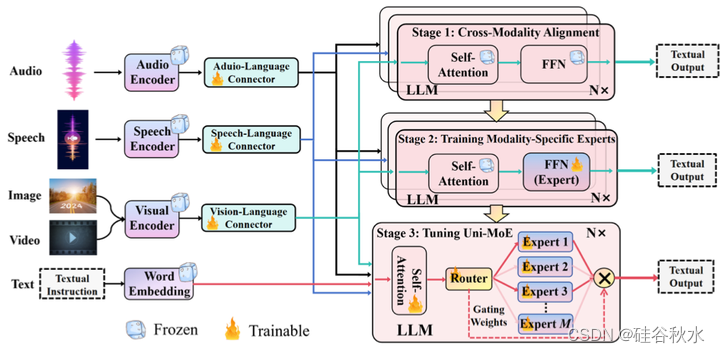
此外,为了增强 Uni-MoE 的多专家协作和泛化,开发一种三阶段渐进式训练方法:首先,分别使用大量图像/语音/音频到语言对来训练相应的连接器,实现 LLM 语言空间中的统一模态表示。其次,用跨模态数据集分别训练特定模态的专家,以提高每位专家在各自领域的熟练程度。第三,将这些训练有素的专家集成到 LLM 的 MoE 层,并使用混合多模态指令数据训练整个 Uni-MoE 框架。为了进一步降低训练成本,采用 LoRA [21] 技术来微调这些预先调整的专家和自注意层。通过上述三阶段训练方法,获得一个高效、稳定的 Uni-MoE,可以熟练地管理和解释多种模态。这个训练方法的总览如图所示:
算法 1 概述了旨在实现集成的MoE MLLM 架构Uni-MoE三阶段训练协议:

实验扩展基于 LLaMA-7B 架构的 Uni-MoE 模型为基础。下表是Uni-MoE 的详细架构以及与视觉-语言 MoE-LLaVA 的比较。部分内容来自 MoE-LLaVA 模型 [20]。“Width”表示隐状态维度。“FFN”表示前馈网络中间层维度。“FFN Factor”表示 FFN 中的线性层数。“Activated”或“Total Param”是指激活的参数量或总参数量。“7B×4-Top2”表示具有 7B 参数的密集基础模型,旨在包含总共4个专家,其中两个被激活。“†”表示所有层都配备 MoE 层。

Uni-MoE 的设计和优化下表中列出的专门训练任务为指导。这些任务有助于完善 MLP 层的功能,从而利用它们的专业知识来提高模型性能。有8项单模态专家任务,阐明不同训练方法的不同影响。综合训练方法使用 MoE 框架执行6项不同的任务,涵盖多种模态,包括视频、音频、语音、图像和文本。这项多方面的训练任务评估 Uni-MoE 在不同 MoE 配置下的性能,从而确保一种适用于各种数据类型和应用程序的稳健且通用的建模方法。
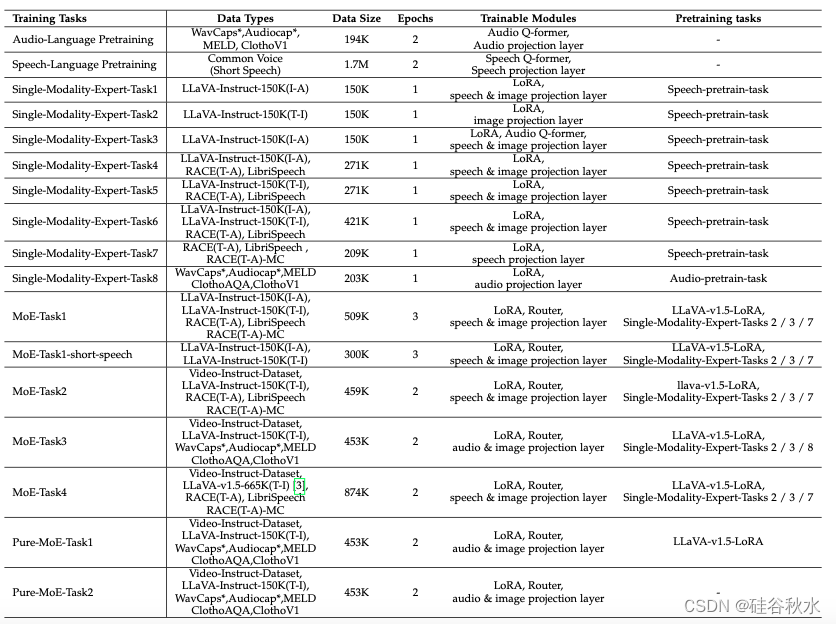
训练数据集。为了使模型具备语音识别能力,在训练的跨模态对齐阶段加入 Common Voice 数据集 [53]。该数据集包含简短的语音片段,每个片段的持续时间不到 30 秒,累计总数超过 170 万个实例。随后,开发一个源自 LLaVA-Instruct-150K [45] 的三模态数据集,利用 Microsoft Azure [54] 的复杂TTS技术将用户查询转换为听觉格式。此外,原始 LLaVA-Instruct-150K 数据集用于各种训练任务,方便进行比较分析。为了提高模型理解扩展语音序列的能力,将 LibriSpeech 数据集 [55] 中的音频文件与 30 秒的简短语音集成并串联成更长的声音文件,每个文件最长可达两分钟。此外,将 RACE 数据集 [56](一个源自中国英语考试的综合阅读理解集合)从其原始文本格式转换为长音频文件。随后将这些转换后的音频文件输入到模型中,使其能够解释冗长的语音输入并准确确定对问题的适当回答。对于音频字幕任务,该模型使用相同的数据集进行跨模态对齐和单模态专家训练过程。WavCaps 数据集 [57] 构成 ChatGPT 辅助的弱标注音频字幕集,分为四个子集(AudioSet SL 子集、SoundBible、FreeSound 和 BBC Sound Effects),部分用于优化框架。此外,AudioCaps 数据集 [58] 是一个综合语料库,包含大约 46,000 对音频片段及其相应的人工生成的文本描述,也在训练过程中有选择地使用。 Clotho 和 ClothoAQA 数据集 [59]、[60] 用于增强模型在音频相关问答任务中的能力。此外,MELD [61](一个用于音频情绪检测的数据集)用于增强框架内音频相关任务的多样性。在视频相关任务领域,这是增强模型视觉理解的关键组成部分,VideoChatGPT [62] 的 Video-Instruct-Dataset(包含 100,000 个视频-文本指令对)被用作训练语料库,以提高模型在涉及视频内容的场景中的表现。
评估数据集。该模型在各种基准上进行评估,反映了它们旨在执行的专门任务多样性。为了评估模型在短语音识别和图像理解方面的熟练程度,用A-OKVQA [63]、OKVQA [64] 和 VQAv2 [65] 基准的修改版本,利用语音合成技术 TTS 将问题转换为人类语音。为了设计长语音任务,利用图像文本推理数据集 MMBench [5] 并利用 TTS 将上下文提示转换为长音频(称为 MMBench-Audio),以及 RACE 评估集的语音版(称为 RACE-Audio),严格评估模型。更准确地说,模型的熟练度还通过它们在中国高考英语听力部分的表现来评估,以检查它们在现实世界中的实际语音识别能力。该紧凑数据集包含 150 个与长音频片段相关的问题(平均长度为 109 秒),以及 50 个与短音频片段相关的问题(平均长度为 14 秒)。这些材料的格式与 RACE-Audio 评估数据集的格式一致。此外,还利用 Clotho V1/2 和 ClothoAQA 的测试集来评估环境音频理解能力。在视频相关任务的背景下,使用 ActivityNet-QA [66] 和 MSVD-QA [67] 的基准来衡量 Uni-MoE 的性能,这些基准有助于评估视频理解和交互能力。

















 873
873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









