










23年8月来自苹果公司的论文“FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization“。
FastViT是一种混合视觉Transformer架构,可以获得最先进的延迟精度折衷。为此,作者引入了一种新的token混合算子RepMixer,这是FastViT的构建块,它用结构重新参数化,消除网络的跳连接来降低内存访问成本。进一步应用训练-时间的过参数化和大核卷积来提高精度,并从经验上表明这些选择对延迟的影响最小。在移动设备上,模型比CMT(最近最先进的混合Transformer架构)快3.5倍,比EfficientNet快4.9倍,比ConvNeXt快1.9倍,在ImageNet数据集上具有相同的精度。在类似的延迟下,模型在ImageNet上获得的Top-1准确率比MobileOne高4.2%。模型在多项任务中始终优于竞争对手的架构——图像分类、检测、分割和3D网格回归,显著提高移动设备和桌面GPU的延迟。此外,模型对分布外(OOD)样本和破坏具有高度鲁棒性,比竞争的其他鲁棒模型有所改进。
代码和模型:https://github.com/apple/ml-fastvit
视觉Transformer[14]在图像分类、检测和分割[35]等多项任务上取得了最先进的性能。然而,这些模型传统上在计算上是昂贵的。一些工作[68,39,42,59,29]提出了降低视觉Transformer的计算和内存要求的方法。最近的混合架构[42,17,10,64]有效地结合了卷积架构和Transformer的优势,构建了在广泛的计算机视觉任务上具有高度竞争力的架构。其目标是建立一个模型,实现最先进的延迟-精度权衡。
最近的视觉和混合Transformer模型[53,17,43,42]遵循Metaformer[67]架构,该架构由具有跳连接的token混合器和具有另一个跳连接的前馈网络(FFN)组成。由于内存访问成本的增加,这些跳连接导致了延迟的显著开销[13,57]。为了解决这种延迟开销,作者引入了RepMixer,一种完全可重新参数化的token混合器,它使用结构重新参数化来删除跳连接。RepMixer块还使用深度卷积进行信息的空间混合,类似于ConvMixer[55]。然而,关键的区别在于,RepMixer模块可以在推理时重新参数化,删除任何分支。
为了进一步改进延迟、FLOPS和参数量,将所有密集的k×k卷积替换为分解版,即逐深度卷积和逐点卷积。这是高效体系结构[26,47,25]用于改进效率指标的常用方法,但是,简单地使用这种方法会损害性能。为了增加这些层的容量,作者使用[13,11,12,57,18]中介绍的线性训练-时间过参数化。这些附加分支仅在训练期间引入,并在推理时重新进行参数化。
此外,在网络中使用大内核卷积。这是因为,尽管基于自注意的token混合非常有效地实现了有竞争的准确度,但它们在延迟方面效率低下[39]。因此,作者在前馈网络(FFN)[14]层和补丁嵌入层中加入了大核卷积。这些更改在提高性能的同时,对模型的总体延迟影响最小。
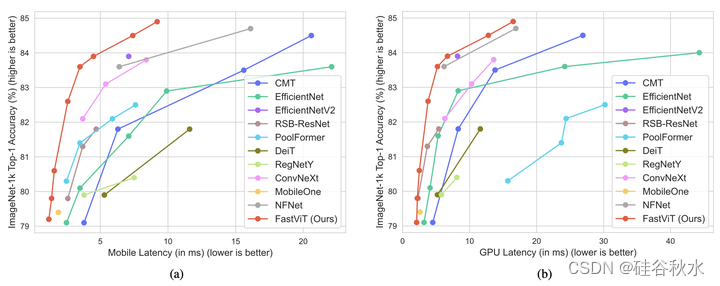
关于RepMixer与其他方法的性能比较如图所示:(a) 最近方法的准确性与移动延迟的曲线。这些模型在iPhone 12 Pro上进行基准测试[57]。(b) 最近方法的精度与GPU延迟曲线。为了更好的可读性,只绘制精度高于79%的Top-1模型。在这两种计算结构中,RepMixer模型具有最佳的准确度-延迟折衷。
在过去的十年里,卷积神经网络一直是视觉模型的标准架构[21,44,66,50,51,26,47,25,36,13,57]。最近,Transformer在计算机视觉任务上取得了巨大成功[14,65,53,35,60,54,43,42]。与卷积层不同,视觉Transformer中的自注意层通过建模长距依赖关系提供了全局上下文。不幸的是,这种全局范围往往要付出高昂的计算代价[39]。像[42,59,29,39]这样的工作解决了减轻与自注意层相关的计算成本方法。
混合视觉Transformer。为了在保持准确性的同时设计高效的网络,最近的工作引入了混合架构,将卷积和Transformer设计相结合,有效地捕获局部和全局信息。一些设计用卷积层[65]取代了补丁化的词干[14],引入了早期卷积步[9,42],或者通过窗注意进行隐式混合[35,7]。最近的工作构建了显式混合结构,更好地在token(或补丁)之间交换信息[17,10,64]。在大多数混合架构中,token混合器主要基于自注意。最近,MetaFormer[67]引入了池化算子,这是token混合的一种简单高效候选方案。
结构重新参数化。最近的工作[13,57]显示,重新参数化跳连接去降低内存访问成本的好处。本文引入一个新的体系结构组件RepMixer,它在推理时可重新参数化。为了获得更好的效率,像[26,47,25,37,71]这样的工作引入了分解k×k卷积的方法,使用深度卷积或分组卷积,然后是1×1点卷积。虽然这种方法在提高模型的整体效率方面非常有效,但较低的参数量可能会导致模型容量减少。最近,[57,11,12]中引入过参数化的线性训练-时间,提高此类模型的容量。本文在模型中使用分解的k×k卷积,并使用线性训练-时间过参数化来提高这些层的容量。
如图是FastViT的直观图:(a) FastViT架构概述,该架构将训练-时间和推理-时间架构解耦。步1、2和3具有相同的体系结构,并用RepMixer进行token混合。在步4中,自注意层用于token混合。(b) 卷积词干的结构。(c) 卷积FFN的体系结构(d)RepMixer块的概述,其在推理时对跳连接进行重新参数化。
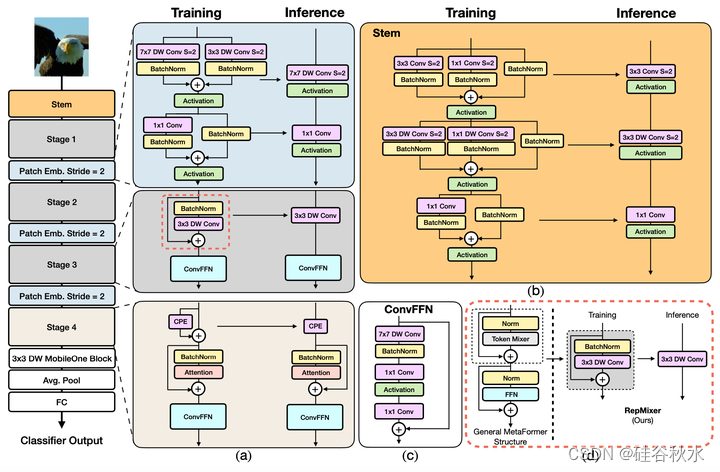
FastViT使用RepMixer,其对跳连接进行重新参数化,有助于降低内存访问成本。为了进一步提高效率和性能,用训练-时间过参数化的分解版取代通常在主干和补丁嵌入层中使用的密集k×k卷积。
自注意[14]token混合器在计算上是昂贵的,尤其是在更高的分辨率下[43,39]。虽然[17,42]中探讨了自注意层的高效版,但作者用大核卷积作为一种高效替代方案,在网络架构的早期阶段改善感受野。
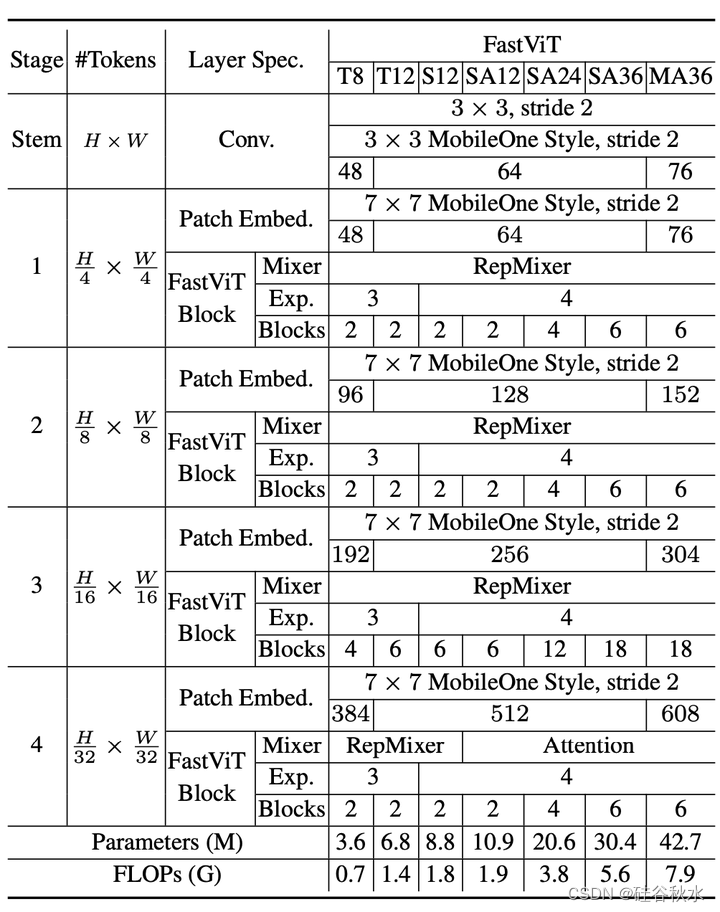
如表是各种FastViT变型的体系结构细节。嵌入维度较小的模型,即[64,128,256,512],前缀为“S”,包含自注意层的模型前缀为“SA”。嵌入维度较大的模型,即[76,152,304,608],前缀为“M”。MLP膨胀比小于4的模型前缀为“T”。符号中的数字表示FastViT块的总数。FLOPS计数由fvcore[15]库计算。
作者采用条件位置编码[7,8],它是动态生成的,并以输入token的局部邻域为条件。这些编码是作为深度卷积算子的结果而生成的,并且被添加到补丁嵌入中。请注意,这组操作中缺乏非线性,因此该块被重新参数化。
由于添加分支的计算开销,训练-时间过参数化导致训练时间增加。在该体系结构中,作者只对那些以分解版取代密集k×k卷积的层进行过参数化。这些层存在于卷积词干、补丁嵌入和投影层中。这些层产生的计算成本低于网络的其他部分,因此过参数化这些层不会显著增加训练时间。
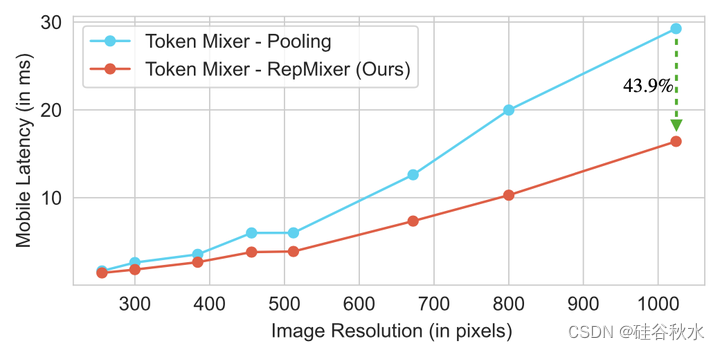
如图是带池化和和RepMixer的MetaFormer(S12)【67】架构分别作为token混合的一个选项,运行在iPhone12 Pro。RepMixer中缺席的跳连接,降低了导致低延迟的总体内存访问成本。
与自注意token混合器相比,RepMixer的感受野是局部的。然而,基于自注意的token混合器在计算上是昂贵的。一个改善无自注意的早期阶段感受野的一种计算有效方法,是结合深度大核卷积。在FFN和补丁嵌入层中引入了深度大核卷积。用深度大内核卷积的变型,与使用自注意层的变型相比,具有高度竞争力,同时导致延迟的适度增加。V5与V3比较,模型大小增加了11.2%,延迟增加了2.3倍,Top-1准确率的增益相对较小,为0.4%。V2模型比V4大20%,延迟比V4高7.1%,同时在ImageNet上获得类似的Top-1精度。总体而言,在FastViT-S12上,大核卷积在Top-1精度上提高了0.9%。
FFN块的结构类似于ConvNeXt[36]块,但有一些关键差异。作者用批规范化而不是层规范化,因为它可以在推理时与前一层融合。此外,它不需要额外的整形操作来获得LayerNorm的适当张量大小,就像在ConvNeXt块的原始实现中所做的那样。
随着感受野的增加,大核卷积有助于提高模型的鲁棒性,如[61]所观察的,卷积FFN块通常比[38]中所观察的普通FFN块更鲁棒。因此,结合大核卷积是提高模型性能和鲁棒性的有效方法。















 1468
1468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









