










23年12月来自美国Notre Dame大学的综述论文“User Modeling in the Era of Large Language Models: Current Research and Future Directions“。
**用户建模(UM)**旨在从用户数据中发现模式或学习有关特定用户特征的表示,如profile、偏好和个性。用户模型能够在推荐、教育和医疗保健等许多在线应用程序中实现个性化和可疑检测。两种常见的用户数据类型是文本和图,因为这些数据通常包含大量用户生成内容(UGC)和在线交互。在过去的二十年里,文本和图挖掘的研究发展迅速,为许多显著的解决方案做出了贡献。最近,大语言模型(LLM)在生成、理解甚至推理文本数据方面表现出了优越的性能。用户建模的方法已经配备LLM,并且很快变得非常出色。
本文总结关于LLM如何以及为什么是建模和理解UGC的好工具等现有研究。回顾了几类用于用户建模的大语言模型(LLM-UM)方法,这些方法以不同的方式将LLM与基于文本和图的方法集成在一起。然后介绍用于各种UM应用程序的特定LLM-UM技术。最后,提出了LLM-UM研究的挑战和未来方向。
如图所示:用户建模旨在从用户数据中发现知识和模式,识别profile、偏好和个性。图中的三个蓝色箭头对应于三个主要贡献:(1)总结LLM如何以及为什么是建模和理解UGC的好工具,(2)回顾将LLM与基于文本和图UM方法集成的方法,以及(3)介绍用于各种应用的LLM-UM技术。
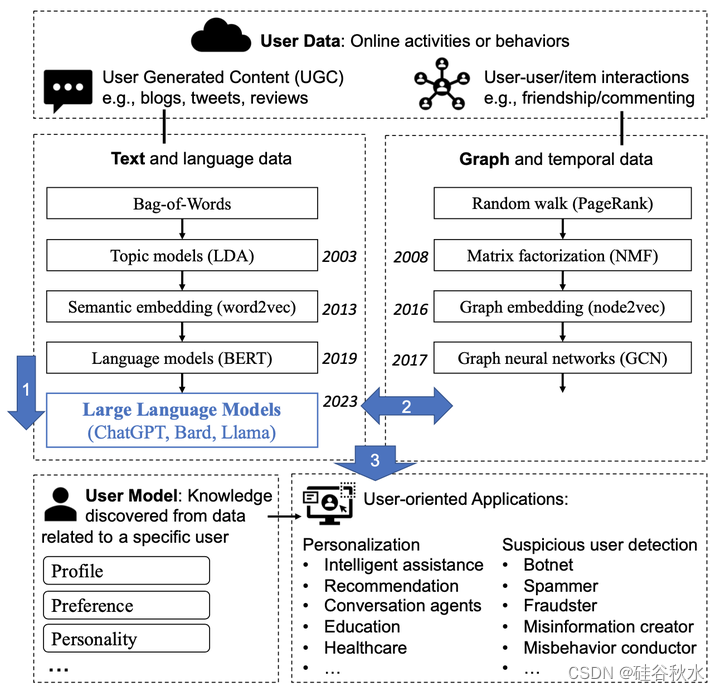
用户建模(UM)涉及从用户数据中提取或预测洞察力,如profile、个性特征、行为模式和偏好。这些见解可用于定制和优化面向用户的系统或服务,使其能够有效适应个人用户的独特需求[124]。从用户数据的角度来看,系统主要有两种类型:用户生成内容(UGC)和用户-用户/条目交互。这些数据模态包括文本内容和基于图的交互。用户建模技术可以大致分为两类:基于文本的方法和基于图的方法,每种分别侧重于UGC和用户交互图。
语言模型是自然语言的概率模型,可以生成单词序列的似然,从而预测未来tokens的概率[119,283]。大语言模型(LLM)是指具有数十亿可学习参数的深度神经语言模型,这些模型在超大的文本语料库上进行预训练,了解自然语言的分布和结构[283]。由于Transformer架构[219]的效率,几乎所有大语言模型都将其作为主干。有三种类型的语言模型设计:编码器(例如BERT[102])、解码器(例如GPT[180])和编码器-解码器(例如T5[182])。编码器模型,特别是BERT,使用双向注意来处理tokens序列,并在掩码token预测和下一句分类任务上进行预训练。该过程可以提取用于一般目的的语义嵌入,并使模型能够在微调后快速适应不同的下游任务。解码器的模型,如GPT,基于Transformer解码器架构执行文本-到-文本的任务。在从左到右的下一代代币预测任务中进行训练。编码器-解码器模型,例如T5,是在文本到文本任务上进行训练的。其编码器从输入序列中提取上下文表示,解码器使用交叉注意将潜表示映射回文本输出空间。在LLM的背景下,大多数模型遵循解码器的架构,因为它简化了模型并进行了有效的推断[232]。
最近,研究人员发现,规模化预训练语言模型的训练数据和参数大小,通常会带来显著的性能增益,也称为规模化定律[101]。大语言模型呈现出涌现能力[240],指的是小模型中不存在的能力。通常,有三种类型的涌现能力:上下文学习(ICL)、指令跟随和逐步推理。上下文学习假设语言模型已经提供了自然语言指令和/或几个任务演示。LLM可以完成输入文本的单词序列来生成测试实例的预期输出,不需要额外的训练或梯度更新,这是GPT-3[17]首次引入的。ICL最近的研究重点是减少归纳偏置[116,201]。指令跟随能力,意味着LLM在自然语言描述的混合多任务数据集进行微调,称为指令微调,这样的模型在指令形式描述的未见过任务上表现良好。
指令微调提高了LLM的泛化能力。LLM更符合人类意图[238]。最近的指令微调研究,集中在如何实际地[161]和有效地[290]使LLM与任务和用户偏好保持一致。逐步推理意味着LLM可以解决需要多步推理的复杂任务。思维链(CoT)[241]介绍了提示设计中推理步骤的中间步。从最少到最多[291]将推理步骤分解为更简单的问题。自一致性(Self-consistency)[234]提示通过整合不同的CoT推理路径进一步增强LLM推理。思维树(ToT)[257]和思维图(GoT)[12,258]使LLM能够分别探索树和图结构中的思维过程。此外,初步探索表明,LLM可以使用外部工具[195],成为参数知识基础[163],具有思维论[108],充当智体[230,247],具有图理解能力[226],并可以充当优化器[251]。
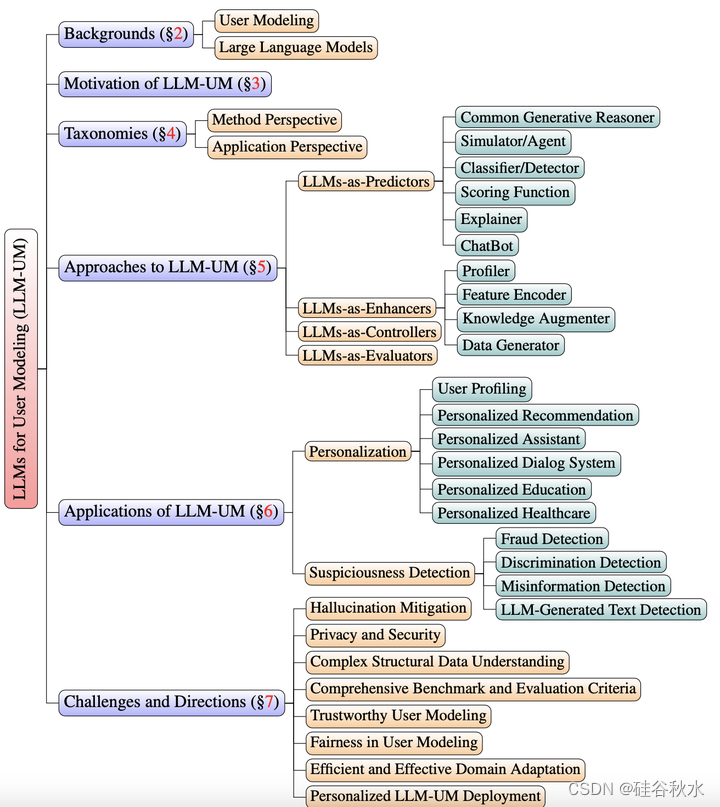
如图是该文的综述结构:
除了使用冻结参数的LLM,另一项工作侧重于有效地微调LLM中的参数,即参数有效微调(PEF),这有助于LLM有效地适应特定任务、数据集和特定领域的理解。前缀-调优[126]保持语言模型参数冻结,并优化小型连续任务特定的向量,称为前缀。提示-调优[115]是前缀-调整的一种更简单的变型,其中一些向量在输入层的序列开头进行预置。Llama-适配器[278]将一组可学习的提示作为前缀附加到Llama[216]中Transformer较高层的输入指令tokens中。LoRA[74]将可训练秩分解矩阵注入到Transformer架构的每一层,大大减少下游任务可训练参数量。QLoRA[42]通过一个冻结的4位LLM将参数更新到低秩适配器中。
现有的LLM可以根据可访问性分为:开源的和基于API的模型。开源模型提供了对模型权重的访问和在本地机器上运行模型的能力,而基于API的模型限制用户直接访问模型权重,只允许通过API与模型交互。开源LLM包括T5[182]、Flan-T5[34]、OPT[279]、BLOOM[192]、GLM[271]、Llama[216]和Falcon。通过对Llama进行微调或指令调整,出现了一系列LLM,如Alpaca[213]和Vicuna[28]。对于基于API的模型,OpenAI提供了四个主要系列的GPT-3[17]接口,包括ada、babbage、curie和davinci,分别对应于GPT-3(350M)、GPT-3(1B)、GPT-3(6B)和GPT-3(175B)。GPT-3.5系列包括davinci和turbo:turbo利用来自人类反馈的强化学习(RLHF)[161]来创建类人的对话。GPT-4[159]是公认的最先进技术,在广泛的任务中取得了惊人的性能。还有其他一些基于API的模型,如BARD[146]、Claude、PaLM[31]、BloombergGPT[245]和LangChain。
尽管LLM研究蓬勃发展,但一些挑战仍未解决。例如,LLM存在幻觉问题,也就是说,LLM生成的文本流畅自然,但对源内容不忠或确定不足[99]。LLM也因微妙的预训练数据集而存在偏见,包括政治话语[57]、仇恨言论[81]和歧视。此外,由于低并行性和大内存占用,LLM的推理延迟仍然很高[175]。剩余的挑战还包括有限的上下文长度[99]、过时的知识[259]、偏离的行为[188]、易变的评估[284]和有限的结构理解能力[27]。
LLM展示了新的功能,在建模和理解用户生成内容(UGC)方面显示出强大的潜力。
越来越多的研究集中在利用LLM进行推荐,根据用户的行为历史,目标是预测用户基于条目的兴趣。例如,PALR[26]基于UGC历史生成用户配置文件,并构建包含历史、profile和条目候选的提示,使LLM能够提供建议。LLM考虑用户的查看历史,成功地生成了合理的推荐。在用户分析领域,目标是根据用户生成的内容和历史,总结用户的特征,包括个性、兴趣和感兴趣的主题。最近的研究表明,LLM在用户评测方面表现出色。Liu[136]将行为历史放入LLM中,提取用户的兴趣题目和物理区域,从而增强推荐系统。
在评级预测的背景下,Kang[100]研究了LLM预测候选条目的用户评级能力。他们发现,由于缺乏用户交互数据,零样本LLM落后于传统的推荐模型。LLM可以使用基于用户先前评级的推理为候选条目预测用户评级。最近的研究强调了LLM理解用户个性的能力。Ji[87]采用各种提示探究LLM基于UGC历史去识别用户个性的能力。在零样本条件下,LLM在个性识别方面取得了令人印象深刻的结果。对于有无害行为历史的用户,UM建立在一般兴趣、内容偏好和交互风格的基础上。
然而,有可疑行为历史(如仇恨言论)的用户,UM必须评估与可疑活动相关的行为模式、未来事件的风险,并可能标记这些用户以进行更密切的监控。从应用方面来看,用户历史中仇恨言论的存在与否对个性化推荐有显著影响。例如,有仇恨言论历史的用户可能会在推荐中避开敏感话题。因此,可疑检测,例如仇恨言论检测,是用户建模中的一个重要应用。
LLM擅长检测UGC中的可疑情况。Del Arco【40】探索零样本提示LLM进行仇恨言论检测。他们发现零样本提示可以实现与微调模型相当甚至超过微调模型的性能。
总之,这些研究和例子展示了LLM对UGC和用户行为进行建模、理解和推理的能力。它们提供了全面的证据,证明LLM可以作为用户建模的宝贵工具,展示了改进面向用户的应用程序的巨大潜力。
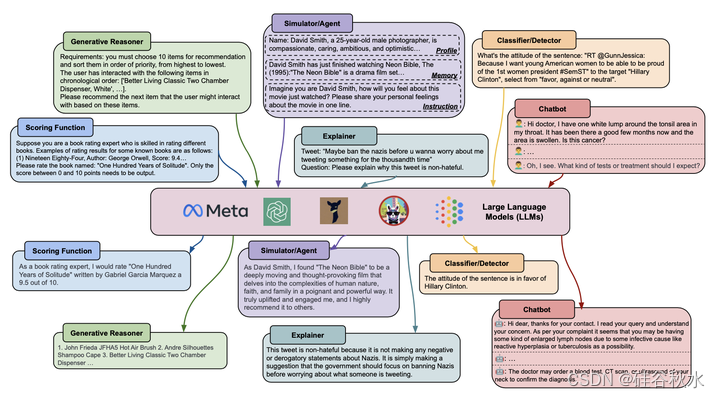
如图所示是用于推荐、评级预测、用户分析、个性分析和仇恨言论检测的一些LLM示例。这些令人信服的例子,基于用户生成内容(UGC)和用户交互,展示了LLM有效建模、理解和推理的能力。

LLM在LLM-UM系统中扮演着不同的角色。根据其功能,LLM-UM工作可以分为四种不同的方法。
(1) LLMs-as-Predictors:利用LLM进行推理并直接生成答案。根据LLM的作用,这些LLM-UM方法可以进一步分类为复杂任务的常见生成式推理器、建模和预测人类行为的智体/模拟器、分类器/检测器、评分函数、解释的生成和用于用户建模的聊天机器人。
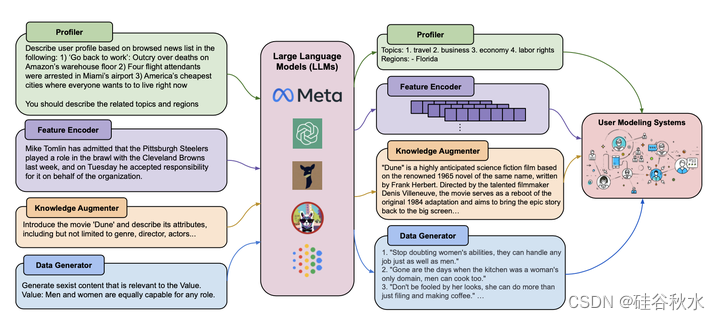
(2) LLMs-as-Enhancers:使用LLMs作为增强模块来增强下游用户建模系统。LLM可以充当profiler来推断用户偏好和特征,充当特征编码器来生成潜在的UGC表示,用LLM中存储的知识增强鉴别式用户建模系统,并生成用于小UM模型训练的高质量数据。
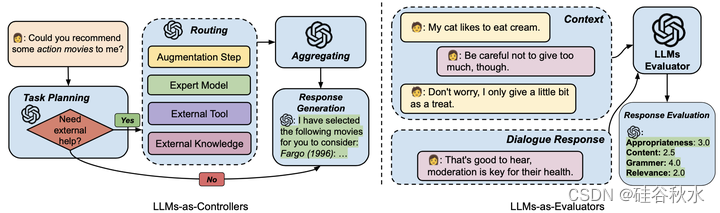
(3) LLM还具有控制UM系统流水线的能力(LLMs-as-Controllers),自动确定是否执行某些操作。
(4) LLM还可以充当评估器(LLMs-as-Evaluators),对开放域设置生成的对话和文本进行评分和分析。
如图所示是LLMs-as-Predictors:
如图所示是LLMs-as-Enhancers:
如图所示则是LLMs-as-Controllers 和 LLMs-as-Evaluators 两个:
鉴于在生成[283]、推理[241]、知识理解[205]方面的强大能力以及对UGC的良好理解,LLM可用于增强UM系统。LLM-UM方法根据LLM的作用分为三类:第一类将LLM设想为直接生成预测的唯一预测器,第二类使用LLM作为增强器来探测UM系统增强的更多信息,第三类赋予LLM控制UM方法流水线的能力,使UM过程自动化,最后一类使用LLM作为评估者,评估系统的性能。值得一提的是,LLM-UM中“用户模型”的形式与之前的定义保持一致,是在用户生成内容和用户-用户/条目交互网络的帮助下所发现的知识和模式[71]。LLM-UM与以前范式的区别在于方法,其中LLM-UM由LLM授权或增强,获得与用户相关的知识。

















 483
483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









