










24年2月来自哈尔滨工大和中科院自动化所的论文“A Survey on Data Selection for LLM Instruction Tuning”。
指令调优是训练大语言模型(LLM)的重要步骤,如何提升指令调优的效果受到越来越多的关注。现有研究表明,在LLM的指令调优过程中,数据集的质量比数量更重要。因此,近年来许多研究致力于探索从指令数据集中选择高质量子集的方法,旨在降低训练成本并增强LLM的指令跟随能力。本文对LLM指令调优的数据选择进行全面的综述。首先,介绍广泛使用的指令数据集。然后,提出一种新的数据选择方法分类并详细介绍最近的进展,还详细阐述了数据选择方法的评估策略和结果。最后,强调这项任务面临的挑战并提出前沿问题。
在早期的研究中,指令调优的工作主要集中在构建大规模指令数据集上,而创建指令数据集主要有两种方式。一种是通过模板将现有带注释的自然语言数据集中的文本-标签对转换为指令-输出对,例如 P3[Sanh et al., 2022]。另一种方法是使用 GPT-3.5-Turbo 等 LLM 为给定的指令生成输出,例如self-instruct[Wang et al., 2023]。虽然有各种各样的方法创建大规模指令数据集,但它们往往在数量、多样性和创造力方面存在局限性。此外,增强对大规模指令数据集的指令跟随能力和处理意外响应的能力是当前尚待解决的问题。
因此,选择合适的数据集对于指令微调阶段至关重要。虽然指令微调主要依赖于大量数据,但 LIMA[Zhou et al., 2023a] 等研究表明数据质量比数量更为关键。他们仅使用 1k 个高质量指令数据就证明了 LLM 的性能显著提高。这一发现表明 LLM 在预训练阶段已经获得了世界知识,指令调优阶段只需要少量高质量指令数据即可生成高质量响应。
手工指令数据选择通常成本高昂,并会引入人为偏见。因此,创建高效选择指令数据的自动化方法变得至关重要。然而,由于涉及的因素复杂且考虑多维,这项任务具有挑战性。例如,很难评估单个指令的质量并确保所选数据的整体多样性。另一个挑战是降低成本并提高选择过程的效率。鉴于这些因素,已经开发了各种数据选择方法。一些方法使用指示器系统来评估单个数据点,而另一些方法则依赖于可训练的 LLM 或强大的外部 LLM。这些方法利用了 LLM 自身选择指令的能力。此外,使用较小模型并设计综合流程以在各个方面实现平衡效果的方法也值得关注。这些方法已经显示出令人鼓舞的结果。例如,IFD[Li et al., 2023a] 方法仅使用约 5% 的 Alpaca 数据集就显著优于 Alpaca 模型,并且也比 WizardLM 模型高出约 10%。使用高质量的子集进行微调不仅可以增强 LLM 的指令跟随能力,还可以显著降低计算成本和时间。
各种由 LLM 生成的指令调优数据集(例如 Self-Instruct 和 Alpaca)无需人工操作即可提供大量样本,但其数据质量取决于 LLM 的性能,并且不确定。相反,手工整理的数据集(例如 LIMA 和 Dolly)通过人为选择获得更高的质量,但可能会受到人为偏见的影响。替代数据集构建方法,例如 提示映射(prompt mapping) 和 evol-instruct,旨在提高数据集质量和多样性,但在质量保证方面带来了新的挑战。数据集构建和来源的这种多变性会显著影响数据质量,凸显了仔细选择数据对于 LLM 指令调整的重要性。
正式地,定义一个大小为 n 的指令数据集 X,其中 X = {x1, x2, . . . , xn},每个 xi 代表一个指令微调数据实例。为了从 X 中采用特定的指令数据选择方法 π 并选择大小为 m 的子集 S(m)π [Liu et al., 2023],用预定义的评估指标 Q 来评估 S(m)π 的质量。通过评估指标衡量获得的子集质量可以衡量所选指令数据选择方法的有效性。设计选择方法的过程可以看作是:
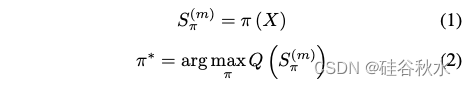
指令数据选择方法分类,基于该方法使用的评分规则和所采用的模型基。方法可分为以下四类:基于指示器体系的方法、可训练的 LLM、如ChatGPT强大的 LLM 和小模型,如图所示:

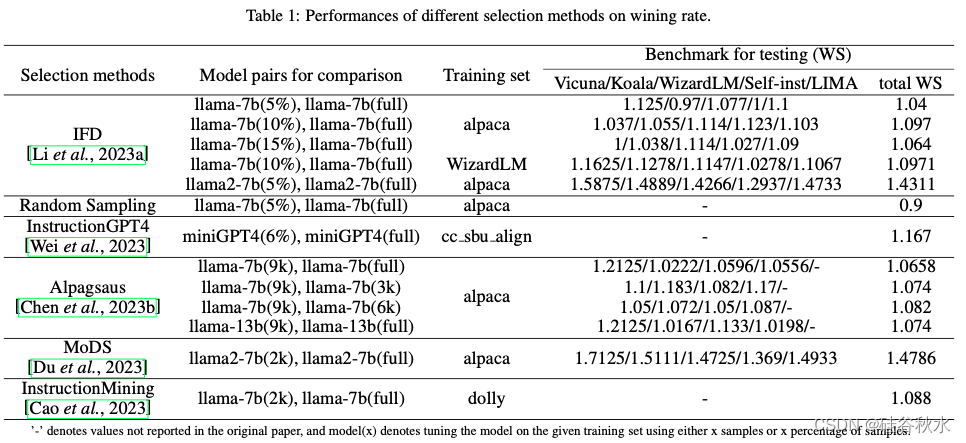
数据选择方法的有效性取决于从给定数据集中所筛选出子集的质量。为了衡量子集的质量,在子集上微调的LLM会在不同的方法不同的基准上进行评估,其方法可分为三类:胜率、内部比较和外部比较,如下三个表格所示:



















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









