









24年4月来自Meta FAIR为首的众多研究机构合写论文“Ego-Exo 4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives”。
Ego-Exo4D 是一个多样化、大规模的多模态多视角视频数据集和基准挑战。Ego-Exo 4D 围绕同时捕捉的以自我为中心和以外部为中心熟练的人类活动视频(例如,运动、音乐、舞蹈、自行车修理)。来自全球 13 个城市的 740 名参与者在 123 种不同的自然场景环境中进行了这些活动,产生了每次 1 到 42 分钟的长篇内容捕捉和总共 1,286 小时的视频。该数据集的多模态性前所未有:视频伴随着多通道音频、眼神注视、3D 点云、相机姿势、IMU 和多种成对的语言描述——包括由教练和老师制作并针对熟练的活动领域量身定制的“专家评论”。为了推动第一人称视频对熟练的人类活动理解,还提供了一套基准任务及其注释,包括细粒度活动理解、熟练度评估、跨视图转换和 3D 手部/身体姿势。资源都是开源的,推动社区研究。
舞者在舞台上跳跃;梅西传球精准;祖母准备饺子。在各种各样的场景中观察和寻找人类的技能,从实用技能(修理自行车)到理想技能(跳出优美的舞)。人工智能理解人类技能意味着什么?要达到这个目标需要什么?
人工智能对人类技能理解的进步可以促进许多应用的发展。在增强现实 (AR) 中,佩戴智能眼镜的人,可以通过提供实时指导的虚拟人工智能教练,快速掌握新技能。在机器人学习中,一个机器人观察环境中的人,可以在较少的身体经验下获得新的灵巧操作技能。在社交网络中,新的社区可以根据人们如何在视频中分享他们的专业知识和互补技能而形成。
以自我为中心和外部为中心的视角,对于捕捉人类技能都至关重要。首先,这两个视角是协同的。第一人称(自我)视角捕捉近距离手-物体交互的细节和携带相机者的注意,而第三人称(外)视角捕捉全身姿势和周围环境背景。参见下图所示。并非巧合的是,教学视频或“操作方法”视频,经常在演示者的第三人称视角和近场演示的特写视角之间交替。例如,厨师可以从外部视角描述他们的方法和设备,然后从类似自我的视角剪辑到展示他们用手操作食材和工具的片段。

其次,不仅自我和外部视角是协同的,而且在获得技能时需要流畅地从一个视角转换到另一个视角。例如,想象一下看着一位专家修理自行车轮胎、玩足球或折纸天鹅——然后将他们的步骤映射到个人身体坐标系上。认知科学告诉我们,即使在很小的时候,也可以观察他人的行为(从外部),并将其映射到自己身上(从自我) [42, 108],这种演员-观察者的转换仍然是视觉学习的基础。
然而,使用当今的数据集和学习范式无法实现这一潜力。现有的由自我视角和外部视角(即自我-外部)组成的数据集很少 [76, 77, 127, 139, 145],规模小,缺乏跨摄像头同步,和/或过于表演或精心策划,无法适应现实世界的多样性。因此,目前关于活动理解的文献主要关注自我 [28, 47] 或外部 [48, 67, 105, 149] 视角,而无法在第一人称和第三人称视角之间流畅切换。教学视频数据集[103、159、204、207]为了解人类熟练的活动提供了一个引人注目的窗口,但仅限于单视点视频,无论纯粹以外部视角拍摄,还是在某些时间点混合“似自我”的视角拍摄。
相关工作
人们对以自我为中心视频理解的兴趣激增,这得益于最近的自我为中心视频数据集,这些数据集展示了非脚本自然的日常生活活动,如 Ego4D [47]、EPIC-Kitchens [27, 28, 163]、UT Ego [78]、ADL [119] 和 KrishnaCam [147],或程序性活动,如 EGTea [81]、AssistQ [172]、Meccano [126]、CMU-MMAC [77] 和 EgoProcel [10]。与上述任何一个都不同,(注:Ego-Exo4D 专注于多模态自我视图和外部视图捕捉,并且专注于熟练活动领域。)
现有的多视角数据集大多侧重于静态场景 [20, 128, 151, 175, 176] 和物体 [133, 173],而多视角人体活动有限(仅限外部视图)[26, 169]。CMU-MMAC [77] 和 CharadesEgo [145] 是捕捉自我中心 ego 和外部中心 exo 视频的早期成果。CMU-MMAC [77] 中有 43 名身穿动作捕捉服的参与者,在实验室厨房中烹饪 5 种菜谱。在 CharadesEgo [145] 中,71 名 Mechanical Turkers 从 ego 和 exo 视角依次记录了 34 小时的脚本场景(例如“在笔记本电脑上打字,然后拿起枕头”),产生了非同步的活动视频。
最近的 ego-exo 工作侧重于一两个环境中的特定活动。 Assembly101 [139] 和 H2O [76] 在实验室桌面上提供时间同步的 ego 和 exo 视频,人们在桌面上组装玩具车或操纵手持物体,分别有 53 名和 4 名参与者,以及 513 和 5 小时的镜头。Homage [127] 提供了 27 名参与者在 2 个家庭中进行洗衣服等家务活动的 30 小时 ego-exo 视频。
注:与之前的任何努力相比,Ego-Exo4D 提供了数量级更多的参与者、多样化的地点和数小时的镜头(740 名参与者、123 个独特场景、13 个城市、1,286 小时)。重要的是,对熟练任务的关注将参与者带出实验室或家庭,进入足球场、舞蹈室、攀岩墙和自行车修理店等场所。除了使用桌面上的物体外,此类活动还可以在场景中产生各种各样的全身姿势和动作。这种多样性意味着 Ego-Exo4D 增强了现有的 3D 人体姿势数据集 [49, 66, 68, 80, 193]。最后,与任何先前的 ego-exo 资源相比,Ego-Exo4D 的模态套件和基准任务都是新颖的,扩展在自我中心和/或外部中心视频理解方面的研究。
分析学习的技能和动作质量受到的关注有限[12,34,35,113,120,194]。教学视频或“如何做”视频的研究,由 HowTo100M [103] 等(主要是外部视图)数据集 [11,159,204,207] 推动。挑战包括落地关键步骤 [10,36,37,89,103,104,178,207]、程序规划 [15,17,22,71,143,167,196,201]、学习任务结构 [4,9,37,107,202,205] 以及利用嘈杂的叙述 [89,103,104]。
注:Ego-Exo4D 的一部分是程序性活动,但同时提供 ego-exo 视频捕获。数据的规模和多样性(包括其三种语言描述形式)拓宽了熟练活动理解的研究途径。
之前关于 ego-exo 跨视图建模的研究有限,这可能是由于缺乏高质量的同步现实世界数据。之前的研究探索了视频之间的人物匹配 [5, 6, 40, 170, 179] 和学习视角不变特征 [7, 141, 144, 182, 184, 185] 或自我为中心特征 [82]。除了 ego-exo 的具体情况外,跨视图方法还被探索用于转换 [130, 131, 134, 157]、新视图合成 [19, 90, 135, 137, 164, 168, 171] 和航空-到-地面匹配 [86, 132]。(注:Ego-Exo4D 为跨视图建模提供了一个新的规模和多样性的试验台。此外,自我-外部视图关系的任务,在具有广泛不同视角的新视角合成中提出了新的挑战。)
目标是同时捕捉自我和外部为中心的视频,以及多种自我中心传感的模态。贡献之一是创建和共享一个低成本(不到 3,000 美元)、轻量级的自我-外部拍摄装置,该装置具有用户友好标定和时间同步的程序。
相机配置采用 Aria 眼镜 [38] 进行自我捕捉,利用其丰富的传感器阵列,包括一个 8 MP RGB 相机、两个 SLAM 相机、IMU、7 个麦克风和眼动追踪。自我相机经过标定并与放置在三脚架上四到五个(固定)GoPro 摄像头进行时间同步,作为外部为中心的捕捉设备,允许对环境点云和参与者的身体姿势进行 3D 重建。外部为中心相机的数量和位置是根据场景确定的,以便最大限度地覆盖有用的视点,而不会妨碍参与者的活动。
时间同步和标定设计,依赖于二维码程序来自动同步相机并自动分离单个“采集”,即活动实例。根据 Aria 的电池寿命,可以进行长达 60 分钟的连续录制。
Ego-Exo4D 视频数据集专注于熟练的人类活动。这与现有的仅针对自我的研究形成了鲜明对比,例如 Ego4D [47],其涵盖了广泛的日常生活活动。
这里根据几个标准来选择领域:它是否会展示技能和各种专业知识?不同实例之间是否会有视觉变化?自我和外部为中心视图是否会提供互补的信息?它会带来当前数据集未解决的新挑战吗?
根据这些标准,得出了两大类熟练活动:自然的和程序的,总共包含八个领域。自然活动领域包括足球、篮球、舞蹈、抱石和音乐。它们强调身体姿势和动作以及与物体(例如球、乐器)的互动。程序活动领域包括烹饪、自行车维修和医疗保健。它们需要执行一系列步骤才能达到目标状态(例如,完成食谱、修好自行车),并且通常需要对各种物体(例如,自行车修理工具;炊具、电器和配料)进行复杂的物体手动操作。
总的来说,有 43 项活动来自八个领域。例如,烹饪由 14 种食谱组成;足球由 3 种训练组成。拍摄时长从 8 秒到 42 分钟不等,其中像烹饪这样的程序活动具有最长的持续拍摄时间。
为了实现数据的视觉多样性,由多个实验室(通常为 3-5 个)捕获各个 Ego-Exo4D 域。数据是在真实环境中收集的,例如现实世界的自行车商店、足球场或抱石馆——而不是实验室环境。例如,有纽约市、温哥华、费城、波哥大等地厨师视频;有东京、Chapel Hill、Hyderabad、新加坡和匹兹堡的足球运动员。如图所示。

从 12 个实验室的当地社区招募了总共 740 名参与者。所有场景都以现实世界的专家为特色,其中佩戴相机的参与者具有特定的资格、培训或所展示技能所需要的专业知识。例如,Ego-Exo4D 相机拍摄者中有专业运动员和大学生运动员;爵士舞、萨尔萨舞和中国民间舞蹈的演员和教练;竞技攀岩者;在工业化规模厨房工作的专业厨师;每天维修数十辆自行车的自行车技师。他们中的许多人(个人)拥有超过 10 年的经验。
专家被优先考虑,因为他们很可能在不犯错或分心的情况下展开活动,为如何处理给定任务提供了强有力的事实依据。然而,也包括了不同技能水平人的活动捕捉——这对于提出的技能熟练程度评估任务至关重要。值得注意的是,Ego-Exo4D 以一种新的方式展现人类的智能,捕捉特定领域的专业知识——既包括视频,也包括陪同的专家评论,描绘了技能从初学者到专家的演变过程。
根据参与者调查,相机携带者年龄从 18 岁到 74 岁不等,其中 37% 的人是女性,60% 的人是男性,3% 的人非这两类或不愿意透露。总的来说,参与者自称来自 24 多个不同的种族。
Ego-Exo4D 的收集遵循了严格的隐私和道德标准。在每个机构进行正式的独立审查程序,建立收集、管理和知情同意的标准。同样,所有 Ego-Exo4D 数据收集都遵守 Project Aria 研究社区指南,进行负责任的研究。由于场景允许封闭环境(例如,没有路人),因此几乎所有视频都无需去识别即可获得。Ego-Exo4D 数据受牌照系统的保护,该许可系统定义允许的用途、限制和不合规的后果。
Ego-Exo4D 还提供三种成对的自然语言数据集,每种数据集都与视频一起按时间进行索引。如图所示。这些语言注释不针对任何单一基准,而是支持浏览和挖掘数据集的通用资源——以及视频语言学习中的挑战,如落地动作和目标、自我监督的表征学习、视频-条件语言模型和技能评估。

第一个语言数据集,是口头专家评论。目标是揭示非专家并不总是能看到的技能细微差别。招募了 52 位专家(不同于参与者)来评论录制的视频,指出优点和缺点,解释参与者的具体行为(例如,手/身体姿势、物体的使用)如何影响表现,并提供空间标记(markings)来支持他们的评论。这些专家不仅在各自的专业领域拥有良好的资质,而且还有指导或教学经验,这有助于清晰地沟通。他们观看视频,每当有评论时就暂停播放,通常每分钟视频暂停7次。每条评论长度不受限制,平均4句话。提供了转录的语音和原始音频(有趣的是,它的语调和非词话语),以及专家的空中比划和对每个参与者技能的数字评分。视频有2-5位不同专家的专家评论,为同一内容提供多种视角。总的来说,有117,812条带时间戳、与视频对齐的评论。这些评论非常新颖:它们关注活动的执行方式而不是活动所需的内容,捕捉到熟练执行中的细微差别。这可以解决新的根本问题(例如,熟练程度评估)和颠覆性的未来应用(例如,AI 辅导)。
第二个语言数据集,由参与者自己提供的叙述和行为描述组成。它们采用教程或操作视频的风格,参与者解释他们正在做什么以及为什么这样做。与上面的第三方专家评论不同,这些是活动的人对活动的第一人称反思。这些叙述占数据集中所有记录的 10% 左右,因为参与者在大部分录音中不暂停地执行任务。
第三语言数据集由原子动作描述组成。虽然评论和叙述-和-行为语言揭示了口头意见和行动的原因(“为什么和如何做”),但这一文字流专门讲述“是什么”。受 Ego4D 旁白 [47] 的启发,这些简短的语句由第三方(非领域专家)注释者编写,为参与者对数据集中所有视频执行的每个原子操作都打上时间戳,总共 432K 个句子。这些数据对于挖掘数据中目标和操作的分类、使用关键字索引视频探索数据集以及未来视频语言学习研究都很有价值,正如 Ego4D 旁白所取得的相当成功一样 [8, 85, 123]。
第二个贡献是,定义以自我为中心技能活动感知域的核心研究挑战,特别是当“自我-外部为中心”数据可用于训练(如果不是测试)时。为此,设计一套基础的基准任务,分为四个任务系列:关系、识别、熟练程度和自我姿势。对于每个任务,提供高质量的注释和基线。
自我-外部视图关系
“自我-外部为中心”关系任务,处理在极端的自我-外部视点变化中关联视频内容。它们采用目标级匹配(对应)和从一个视图合成另一个视图(转换)的形式。
给定一对同步的 “自我-外部为中心”视频和其中一个视频中感兴趣目标的查询掩码序列,任务是预测另一个视图的每个同步帧中相同目标的对应掩码(如果可见)。参见如图左。该任务可以在自我或外部视角视频中使用查询目标,两个方向都提出了有趣的挑战(例如,在自我视图中遮挡程度高,而在外部视图中目标尺寸小)。
将自我-外部转换分解为两个独立的任务:自我轨迹预测和自我视频片段生成,如图右所示。自我轨迹预测根据观察到的外部视图片段中的目标掩码,估计未观察自我帧中的目标分割掩码。自我视图片段生成,必须利用外部视图片段和这些帧中的目标模版,在给定的真实自我视图模版内生成图像(即 RGB)。这种分解有效地将问题分为两个任务:1)预测自我视图片段中目标的位置和形状,2)根据真实位置合成其外观。对于每一个任务,考虑一种变体,其中自我视图相机相对于外部视图相机的姿势可在推理时使用。这简化了问题,但降低了方法的适用性,因为这些信息通常不适用于任意第三人称视频。

“自我-外部”关键步识别
研究自我-外部视图在视频识别中的应用。在训练期间,模型可以访问成对的自我-外部视图数据——从多个已知视点对同一活动进行时间同步的捕获。每个训练实例都有一个自我视图、N 个外部视图和一个相应的关键步骤标签(例如,“翻转煎蛋”)。在测试时,仅给定一个修剪的以自我为中心视频片段,模型必须从 17 个程序活动中的 689 个关键步骤分类中识别出执行的关键步骤。如图左所示。重要的是,所有额外的监督(时间对齐、相机姿势等)仅在训练时可用;推理是标准的关键步骤识别,但模型受益于跨视点训练。
问题表述为在线动作检测任务,并给定能量预算。参见图右。给定音频、IMU 和 RGB 视频数据流,模型必须识别每帧执行的关键步骤,并决定在后续时间步骤中使用哪个传感器。这项任务将启发那些对何时部署哪种模态有战略性的模型。功耗是传感器能量(操作摄像头/音频/IMU 传感器)、模型推理成本和内存传输成本的总和,并且必须在 20mW 以内才能反映现实世界对设备功率限制。
在程序理解任务中,给定一个视频片段 st 及其先前的视频片段历史,模型必须 1)确定先前的关键步骤(在 st 之前执行);推断 st 是 2)可选的,还是 3)程序错误;4)预测缺失的关键步骤(应该在 st 之前执行但没有执行);5)下一个关键步骤(满足依赖关系)。该任务提供了两种版本的弱监督:实例级,片段及其关键步骤标签可用于训练/测试;程序级,仅提供未标记的片段和特定于程序的关键步骤名称用于训练/测试。参见图中心。

自我-外部熟练程度估计
考虑两种变型:(1)演示者和(2)演示熟练程度估计。这两项任务都将一个以自我为中心和(可选)M 个时间同步以外部为中心性视频作为输入。演示者熟练程度被制定为视频分类任务,其中模型必须输出四个标签之一(新手、早期、中级或晚期专家)。演示熟练程度被制定为时间动作定位任务,其中给定未修剪的视频,模型必须输出一个三元组列表,每个三元组包含一个时间戳、一个熟练程度类别(即执行好或需要改进)及其概率。注:视频中未显示参与者技能的部分并未标记。如图所示:

自我姿态估计
这一系列任务的目的是恢复参与者的熟练身体动作,即使在动态环境中的单目自我视角视频输入的极端环境下也是如此。
对于身体和手部姿势(“自我姿势”)估计任务,输入都是自我视角视频。输出是携带相机者身体和手部在每个时间步骤的一组 3D 关节位置,按照 MS COCO 约定,参数化为 17 个 3D 身体关节位置和每只手 21 个 3D 关节位置 [87]。Ego-Exo4D 提供迄今为止最大的手动真值 (GT) 自我中心身体和手部姿势注释。并且,它总共提供了约 14M 帧的 3D GT 和伪 GT 组合。如图所示:

附录:
Project Aria 设备 [38]是 Meta 开发的一款眼镜形状的自我中心记录设备。它被设计为一种用于自我为中心机器感知和上下文化人工智能研究的研究工具。如图所示:

Project Aria 设备旨在模拟未来的 AR 或智能眼镜,以满足机器感知和以自我为中心 AI 的需求,而不是人类消费。它设计为可长时间佩戴而不会妨碍或阻碍佩戴者,即使在进行高度动态的活动(例如踢足球或跳舞)时也能保持自然运动。它的总重量为 75 克(而单个 GoPro 相机的重量超过 150 克),就像一副眼镜一样合适。
此外,该设备集成了丰富的传感器套件,经过严格标定和时间同步,可捕捉各种模态。对于 Ego-Exo4D,使用记录配置文件 15,用以下传感器配置:
一个滚动快门 RGB 相机,以 30fps 和 1408 × 1408 分辨率录制。它配备一个 F-Theta 鱼眼镜头,视野范围为 110度。
两台全局快门单色相机,以 30 fps 和 640 × 480 分辨率录制。它们提供周边视觉,并配备 F-Theta 鱼眼镜头,视野范围为 150度。
两台单色眼动追踪相机,以 10 fps 和 320 × 240 分辨率录制。
七个麦克风阵列,记录眼镜佩戴者周围的空间音频。
两个 IMU(分别为 800Hz 和 1000Hz)、一个气压计(50 fps)和一个磁力计(10 fps)。
出于隐私原因,Ego-Exo4D 禁用 GNSS 和 WiFi 扫描。
所有传感器流都带有元数据,例如时间戳和每帧曝光时间。所有数据均以原始形式提供,作为 Ego-Exo4D 数据集的一部分。为了方便起见,还包括适合特定用途的预计算数据切片,例如 2D 注视点、每个摄像头的 mp4 以及较小的传感器流子集 .vrs 文件。如图所示:

Project Aria 的机器感知服务 (MPS) 提供了软件构建模块,可简化利用记录的不同模式。这些功能很可能在未来的 AR 或智能眼镜中以实时设备功能的形式提供。用 Project Aria 目前提供的以下核心功能,并将其原始输出作为数据集的一部分。
首先,为每个完整的 Aria 录制调用 MPS 流水线——这些录制通常大约持续 20 分钟到 1 小时,可能包括多次拍摄、拍摄之间的交接以及一些其他设置步骤。接下来是定位该场景所有 GoPro 视频,最后是 Aria 和 GoPro 摄像机之间的时间同步以及拍摄分离。
Aria 录音和 MPS 输出的技术文档和开源工具可在 Github 和相关文档页面 上找到。它包括用于转换、加载和可视化数据的 Python 和 C++ 工具;以及常见机器感知和 3D 计算机视觉任务的示例代码。
在全球规模内收集 ego-exo 数据,需要开发一种便携式、自动同步且可在国际范围内使用的低成本摄像机记录装置。这个统一的相机装备细节如下:1 个 Aria、4 个 GoPros、1 个 GoPro Remote、4 个三脚架、4 张 SD 卡、4 个三脚架安装适配器、4 个 Velcro 电池组、4 根 USB-A 转 USB-C 线缆、1 条眼镜运动带、1 部智能手机、1 台用于问卷调查的笔记本电脑或平板电脑。不包括 Aria /手机/笔记本电脑的总成本不到 3,000 美元,其中大部分用于购买 GoPros。
为了分摊每次录制所需的准备和拆卸时间,连续录制多个“拍摄”(即某项任务的一个实例),并使用后期处理中识别的“镜头分隔符”二维码(不同于时间同步二维码视频)自动分隔每个镜头。这能够扩大录制规模,特别是对于单镜头可能不到一分钟的物理场景。数据收集器跟踪每个镜头的元数据,通过索引识别它们并标记数据,例如参与者 ID(匿名唯一标识符)、任务(例如泡茶、做黄瓜沙拉、进行心肺复苏CPR)以及是否应删除镜头(即,如果它只是活动表演之间的准备时间)。
为了同步相机,用预先渲染的 QR 码序列(即 QR 码视频),其中编码挂钟时间。用智能手机以 29fps 的速度向所有相机依次播放此 QR 码视频,并利用帧速率的差异来精细同步相机。理论上,在捕捉一个 QR 变化的帧中解码的QR 码,很可能是在该帧的曝光中心期间可见的 QR 码。对于单个 QR,相机的曝光时间中心可能位于 QR 显示的 34.48 毫秒内任何位置。但是,对于具有相同 QR 的两个连续帧,可以将该时间定位到 ±0.574 毫秒以内。对于给定 3 个连续帧的 59fps GoPro,同样的方法可以得到 ±0.558 毫秒以内提供亚帧同步精度,如图所示。

配置的设置程序包括在录制环境中设置固定的外部相机并显示二维码以执行时间同步,然后进行分离。如图概述录制过程:

自我-外部视图对应的标注方法如下。
用分割掩码注释时间同步的自我中心-外部视频对,这些视频对来自六个场景的选定目标实例:烹饪、自行车修理、健康、音乐、篮球和足球。将攀岩和舞蹈排除在这个基准之外,因为它们的目标多样性有限。关注的是相机拍摄者在执行活动期间任何时候使用的目标,这些目标在序列中至少某些帧的两个视图都可见。这些掩码能够定义视图之间目标级对应关系。
用了一个多阶段注释过程来标注成对的自我-外部视频:
• 第 0 阶段:目标枚举。注释者用一个清晰可见的帧中边框,标记在自我中心视频的某个点上处于活动状态的每个目标,并提供自由格式的文本描述。
• 第 1 阶段:自我中心视频注释。注释者观看以自我为中心的视频,并看到 (a) 文本和 (b) 上一阶段注释的目标之一的边框。然后,注释者在所有可见该目标的视频帧中为该目标标记分割掩码。利用 Segment Anything (SAM)[70] 仅通过点击即可高效生成分割掩码。
• 第 2 阶段:以自我为中心的视频注释。如图所示,注释者观看时间同步自我为中心的视频,并看到 (a) 文本和 (b) 该目标多个以自我为中心的分割掩码。然后,只要该目标可见,注释者就在所有以自我为中心的视频帧中为该目标标记分割掩码。
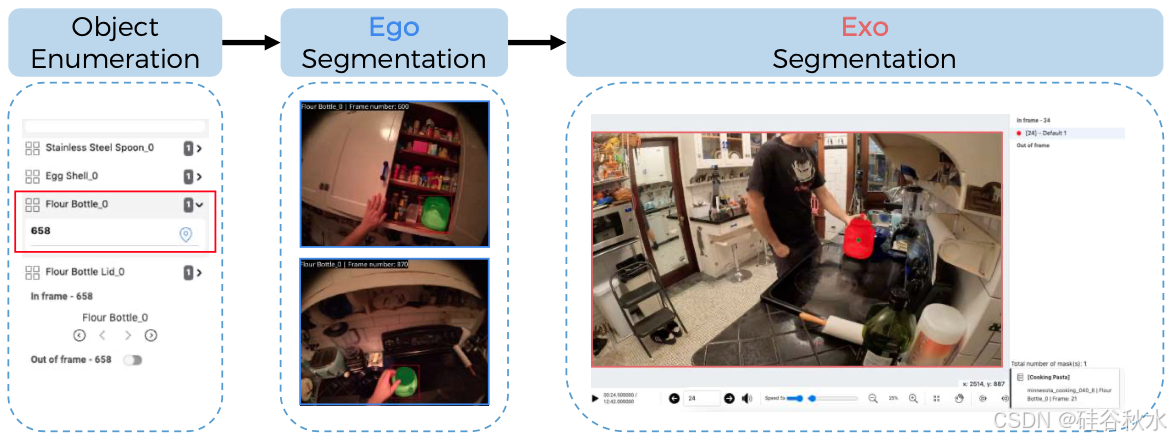
总的来说,注释过程为 1,335 个 ego-exo 视频对中的 5,566 个目标生成分割掩码。注释大约 400 万帧,共生成 742K 个 ego 和 110 万个 exo 配对分割掩码。除此之外,还注释 367K 个 ego 的分割掩码。总共生成 220 万个分割掩码。
在视频对中寻找目标掩码对应关系是视频理解中尚未深入研究的领域。研究了两种不同的基线方法来完成自我-外部视图对应关系任务:(a) 在每个时间点独立解决对应关系问题的空间基线模型,以及 (b) 考虑预测对应关系历史的时空基线模型。
空间基线模型。该模型接收在一个视图中的自我中心框架、相关的外部中心框架和查询目标分割掩码作为输入。然后,它输出另一个视图中的掩码(如果该目标在该视图中可见)。它可以被认为是针对稀疏图像对应提出的查询点对应方法的泛化 [65]。以基于 Transformer 的图像对应模型 XSegTx(跨视图分割Transformer)形式实现此基线,该模型扩展 SegSwap [142],一种最初为图像共分割而提出的方法,即用于分割一对图像中的公共目标。为了使 SegSwap 的架构适应对应问题,将查询掩码作为第三个输入提供给模型,将模型的条件设定为感兴趣目标的分割掩码。具体来说,首先将自我中心框架、外部中心框架和查询掩码(作为二进制掩码)传递到视觉主干网络。然后,将得到的特征展平(flatten)为三个序列,并将它们传递到具有交替的自注意层和交叉注意层的交叉-图像Transformer中。首先使用查询掩码特征来关注查询视图中的特征,然后将其用于交叉-关注目标视图(target view)中的特征。这允许模型根据输入掩码推理来自两个视图的特征。两个视图的结果序列都是“未展平的(unflattened)”,并通过解码器传递以预测两个视图中的目标分割掩码。还将目标视图(target view)特征传递给分类头,以对查询目标是否在目标视图中可见进行分类。
训练模型使用逐点二元交叉熵损失和DICE损失对预测和真值掩码执行掩码预测。只使用感兴趣的目标在两个视图上都可见的帧对,并将损失应用于两个视图中的预测掩码。在推理过程中,仅考虑目标视图中预测的掩码,并丢弃查询视图中的预测掩码。用一个二元交叉熵损失对序列的所有帧进行可视性分类来训练头部。
时空基线模型。时空模型接收一对 ego-exo 视频剪辑以及其中一个视图中的目标分割轨迹作为输入,对目标在两个视图都可见的帧,输出另一个视图中目标的分割掩码。它可以被认为是跨视图执行广义跟踪。在 XMem [24] 之上构建了基线模型,该模型最初是针对给定第一帧中的分割掩码来跟踪特定目标目标而提出的。具体来说,基线模型称为 XView-XMem,它根据给定每个帧中一个视图的真实分割掩码,调整 XMem 跨不同视图跟踪目标。为了鼓励模型学习以自我为中心和以外部为中心视图之间的目标关联,训练 XView-XMem 在以自我为中心和以外部为中心视图的交错帧序列中跟踪目标,即每个以自我为中心帧后面跟着一个以外部为中心帧,反之亦然,如图所示。
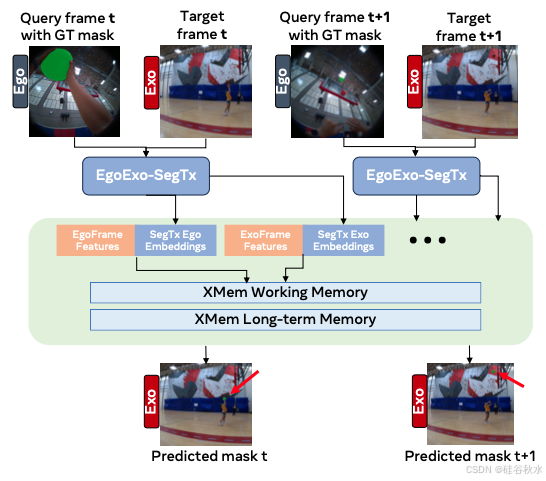
为了减轻轨迹漂移(视图内和视图间),还探索将 XSegTx 嵌入馈送到 XMem 工作内存。由于这些嵌入经过训练独立引导每个帧的掩码解码器,因此它们可以捕获有关感兴趣目标的丰富信息。从 XMem 中的 ResNet 中提取的图像特征,与来自 XSegTx 的 SA(自注意)和 CA(交叉注意)层的多层编码嵌入融合,然后将它们投影到K中并存储在内存中以进行跟踪。
实现的细节如下。对于空间基线模型,将所有视图的图像下采样为 480x480 分辨率,同时使用填充来保持图像的原始宽高比。对于图像主干,用与 SegSwap 相同的 ResNet50 [51] 检查点,并在训练期间冻结其权重。跨图像Transformer架构也遵循 [142]的方法。用批量大小 32 和 Adam [69] 作为优化器,学习率为 0.0002,在 50,000 次迭代后衰减为 0.0001。在单个 Nvidia RTX A6000 GPU 上运行所有实验,进行 200,000 次迭代。
对于时空基线模型,用与 XMem [24] 相同的视觉主干(ResNet50 [51])和架构。唯一的修改是在每帧插入工作内存的信息。首先从 ResNet 和 XSegTx 中提取查询和目标帧的特征。然后通过简单的 2D 卷积将相应的特征连接起来并投影到原始特征维度。在 8 个交错的 ego 和 exo 帧序列上进行训练。该模型使用 AdamW 作为优化器进行训练,学习率为 0.00001,迭代 50,000 次,权重衰减为 0.05。批量大小为 8 个剪辑对。用原始的预训练 XMem 初始化模型,并保持 ResNet 主干以及微调的 XSegTx 模型冻结。注:不应用任何数据增强。

















 1803
1803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









