










24年7月来自香港大学和UCSD的论文“Bunny-VisionPro: Real-Time Bimanual Dexterous Teleoperation for Imitation Learning”。
遥操作是收集人类演示的重要工具,但用双手灵巧手控制机器人仍然是一个挑战。现有的遥操作系统难以处理协调双手进行复杂操作的复杂性。Bunny-VisionPro,是一种利用 VR 耳机的实时双手灵巧遥操作系统。与以前基于视觉的遥操作系统不同,其设计低成本设备,为操作员提供触觉反馈,增强沉浸感。系统通过结合碰撞和奇点的避免来优先考虑安全性,同时通过设计保持实时性能。Bunny-VisionPro 在标准任务套件上的表现优于之前的系统,实现了更高的成功率并缩短了任务完成时间。此外,高质量的遥操作演示提高了下游模仿学习性能,从而提高了通用性。值得注意的是,Bunny-VisionPro 能够通过具有挑战性的多阶段、长视野灵巧操作任务进行模仿学习,这在以前的工作中很少得到解决。该系统能够处理双手操作,同时优先考虑安全性和实时性能,这使其成为推进灵巧操作和模仿学习的有力工具。
玩虚拟现实 (VR) 游戏是一种身临其境的直观体验,手和手臂动作可以无缝转换为虚拟角色的动作。现在,想象一下在现实世界中同样轻松地控制双手机器人:操作员使用自己的动作来引导机器人的运动,就像在 VR 游戏中一样。机器人遥操作的这种范式转变为更直观、更易于访问的人机交互开辟了令人兴奋的可能性。VR 技术的最新进展,例如 Apple Vision Pro,使这一概念成为可能。
然而,将这一概念转化为实用的遥操作系统面临着巨大的挑战,因为执行类似人类的操作需要复杂的动作。对于高自由度 (DoF) 手臂系统,复杂性进一步放大,操作员必须协调两只手臂和手来执行需要时空同步的任务。实现响应控制至关重要,因为延迟会导致机器人运动不精确 [1]。此外,通过减轻碰撞和奇异等风险来确保安全又增加了另一层复杂性[2]。
带夹持器的遥操作。经典的遥操作方法可根据其控制目标分为两种主要方法。第一种方法以 ALOHA [5、6、7] 为例,它在主从设置中使用关节空间映射 [8]。尽管这种方法能够实现令人印象深刻的双手操作,但它是机器人特有的,需要主机器人和从机器人之间的运动等效性 [9]。它还将管理碰撞和奇异的负担放在人类操作员身上。第二种方法优先考虑末端执行器控制 [10],使用逆运动学计算手臂关节位置。已经使用了各种输入设备,例如运动捕捉系统 [11、12]、惯性传感器 [13] 和 VR 控制器 [14、15、16、17]。然而,这些系统通常采用简单的 1 或 2 DoF 夹持器,这限制了它们的灵活性。
灵巧的遥操作。遥操作灵巧手具有挑战性,因为它们具有高自由度和复杂的运动学。基于手套的系统 [18、19、20、21],例如 Tesla Bot 使用的 MANUS 手套 [22],可以跟踪操作员的手指运动,但成本高昂,并且需要特定的手尺寸。最近的基于视觉的方法,例如 AnyTeleop [4],使用摄像头 [3、23、24、25] 或 VR 耳机 [26、27、28] 实现灵巧的手臂遥操作。然而,AnyTeleop 需要复杂的 GPU 处理来计算手臂运动,并且主要为单臂设计。一个并发的工作 [29] ,使用把手按钮,控制具有较低自由度的 Ability 手,牺牲灵巧指的步态以避免重定位延迟。
从演示中进行模仿学习。模仿学习使机器人能够通过专家指导模仿人类行为。利用深度学习 [30、31、32、33] 的开创性研究制定了基于图像 [5、34、35、36、37、38] 和点云数据 [39、40、41、42] 生成机器人控制命令的策略,并进一步标志着双手系统的进展 [18、5、6、43]。此外,最近的研究结合了触觉数据 [44、29],以丰富机器人学习的感官数据库。演示收集是劳动密集型的,但对于有效的模仿学习却至关重要。
如图所示 Bunny-VisionPro 系统概述和任务套件。(a)Apple Vision Pro 捕捉的手势被转换成机器人运动控制命令,用于实时远程操作。机器人通过 Vision Pro 和配备执行器的指套向操作员提供感官反馈,包括视觉和触觉。(b)设计不同的短视界(左栏)和长视界任务(右栏)来评估遥操作性能及其在模仿学习中的应用。
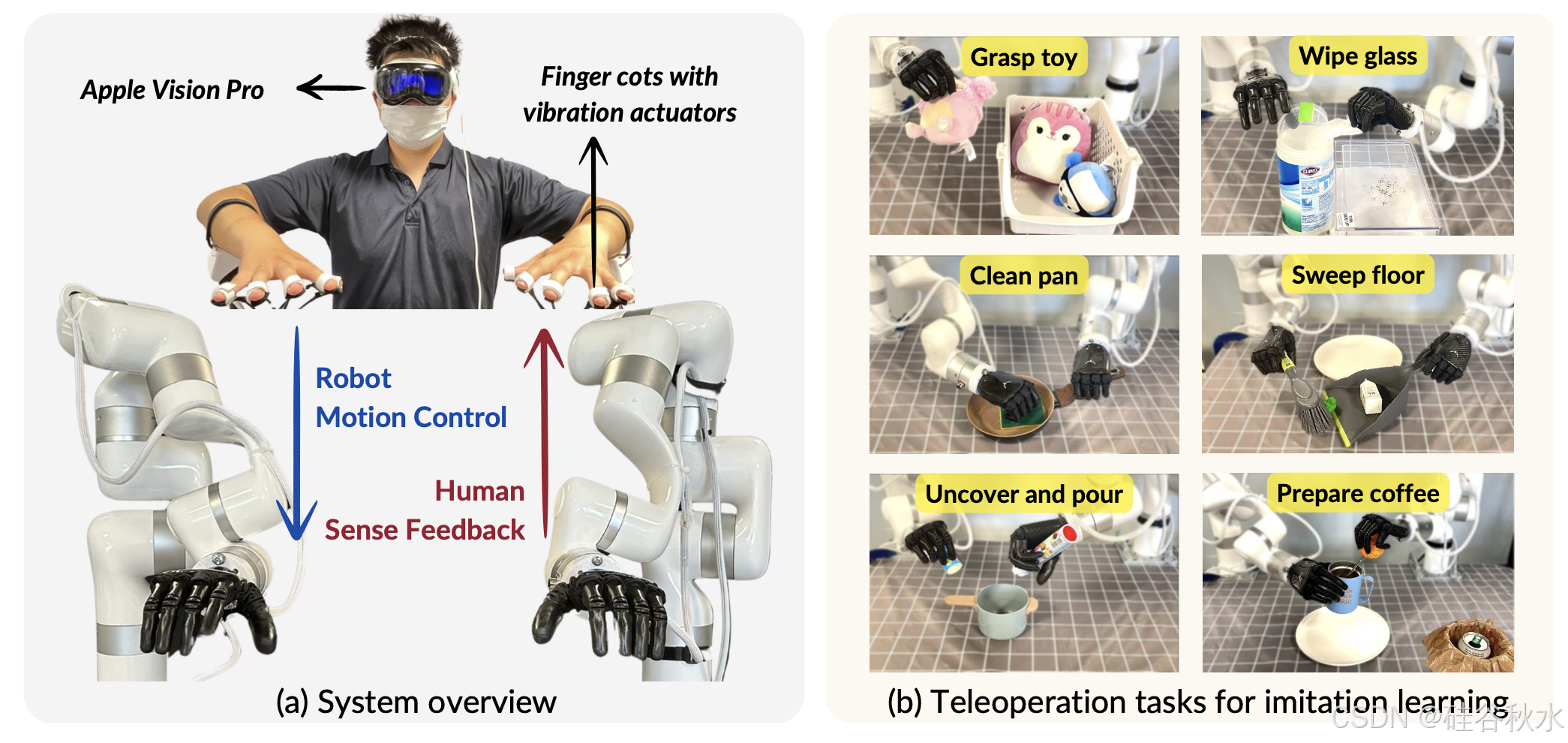
Bunny-VisionPro 是一个模块化的遥操作系统,利用 VR 头戴设备的手部和腕部跟踪功能来控制高自由度双手机器人,如图所示。该系统由三个解耦组件组成:手部运动重定向、手臂运动控制和人体触觉反馈。
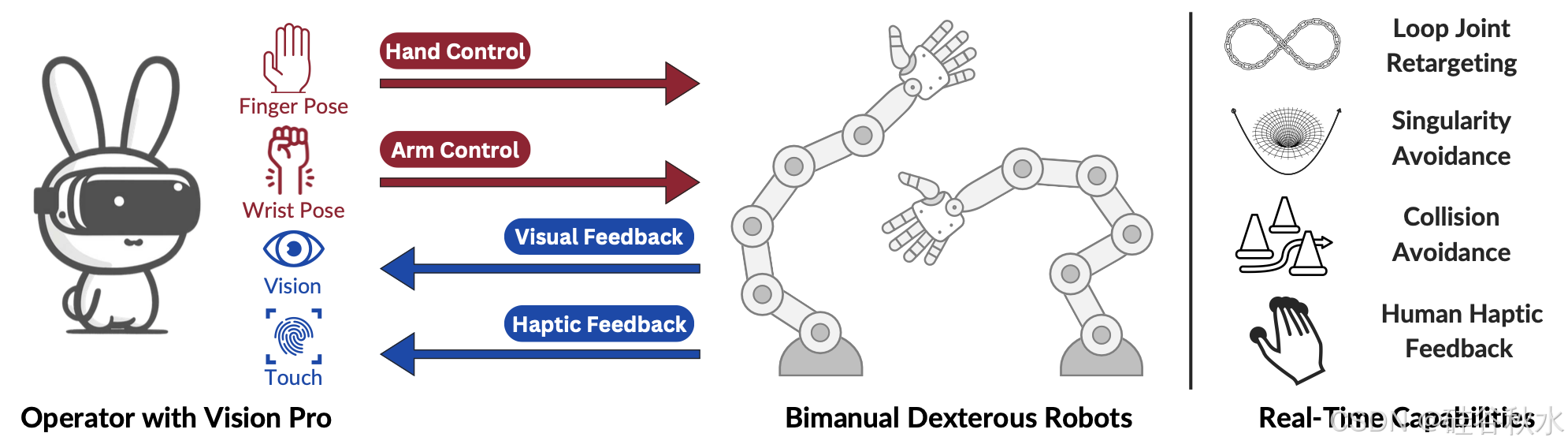
手部运动重定向模块,将操作员的手指姿势映射到机器人灵巧的手上,从而实现直观的灵巧操作。同时,手臂运动控制模块,使用操作员的手腕姿势作为输入来计算机器人手臂的关节角度,同时考虑避免碰撞和奇点处理。人体触觉反馈模块,将安装在机器人手上的传感器的触觉读数转换为操作员手上可穿戴偏心旋转质量 (ERM) 执行器的驱动信号。这为操作员提供了实时触觉反馈,增强了他们的存在感并允许更精确的操纵。
在遥操作过程中,协调双手机器人还需要保持两个机器人手之间的距离以匹配两个操作员手之间的距离,以确保自然、协调的动作。然而,机器人手之间的初始距离可能与人手的距离不匹配。为了解决这个问题,设计几种初始化模式,当机器人开始移动时,可以动态地将机器人的手与操作员的手对齐。不同的任务可能受益于不同的初始化模式。此步骤创建一个一致的起点,使整个遥操作过程中的双手任务执行直观、高效。
为了进行通信,通过 [45] 将手势结果从 VisionPro 传输到计算机。模块化架构允许更好的可扩展性,并使每个模块能够在单独的计算过程中运行,防止系统中的延迟累积并确保实时控制。
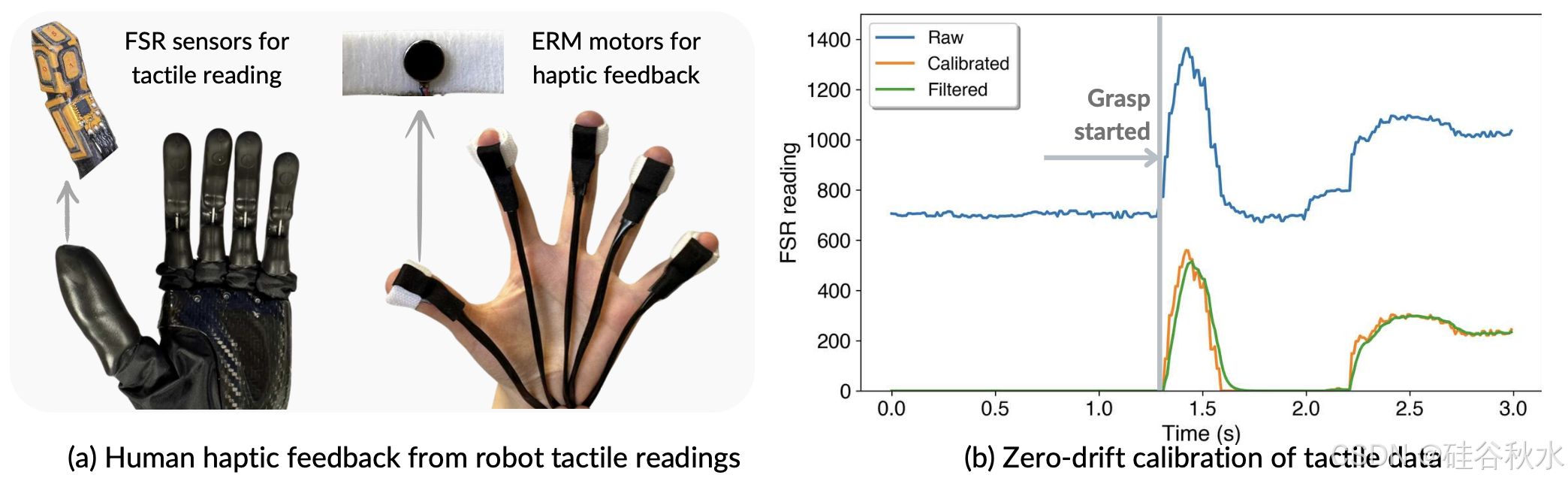
有效的人类操控依赖于视觉和触觉反馈的整合。然而,许多基于视觉的遥操作系统 [4, 23, 26, 28, 3] 忽视了触觉反馈。为了解决这一限制,本文开发一种使用 ERM 执行器的经济高效触觉反馈系统(如图(a)所示)。该系统首先处理来自机器人手的触觉信号(步骤 I),然后驱动振动电机模拟触觉(步骤 II)。尽管成本低廉,但系统使操作员能够更直观地感知和响应环境,获得更身临其境的体验,从而提高操控性能。
步骤 I:触觉信号处理。Ability 手(如图(a)所示)使用力敏电阻 (FSR) 来测量手指压力。然而,FSR 传感器存在不精确和零漂移问题 [53, 54],可变形的包裹材料加剧了这些问题。为了解决这个问题,记录各个关节位置的基线 FSR 读数,并从操作期间的实时读数中减去插值基线值,实现零漂移标定。每次启动遥操作时,都可以自动执行这种有效的标定。此外,应用低通滤波器来降低噪音并平滑触觉数据。如图 (b) 所示,这些信号处理技术显著提高了触觉反馈的质量和可靠性。
步骤 II:振动电机驱动。在此步骤中,用 ELEGOO UNO 板将处理后的触觉信号转换为 ERM 执行器振动。由于 ERM 电机需要恒定的输入电压,采用脉冲宽度调制 (PWM) 通过调制脉冲宽度控制 ERM 振动强度来模拟连续触觉强度。为了进一步增强触觉信号的稳定性和系统的稳健性,在每个 ERM 执行器及其相应的 PWM 引脚之间添加了一个双极结型晶体管 (BJT)。这确保了每个 ERM 电机的触觉反馈都单独调整,仅在脉冲宽度期间激活,并且能够抵抗电路噪声。
触觉反馈的实现可以分为两个方面:服务器端信号处理和 Arduino (意大利公司)端电机控制。
服务器-端信号处理。如算法 1 所述,服务器-端涉及多个信号处理阶段。首先,对触觉读数进行标定、过滤和规范化。随后,将这些处理后的信号转换为有效的 PWM 值并传输到 ELEGOO UNO 板。这可确保准确地准备触觉数据以用于电机激活,从而有助于精确控制触觉反馈。

Arduino-端电机控制。如算法 2 详细说明了 Arduino-端电机控制的伪代码。该系统的这个组件负责解析通过串行通信从服务器接收的 PWM 值。解析后,这些值将直接映射到板上的 PWM 引脚,进而控制 ERM 电机。这种安排使 Arduino 能够根据来自服务器的输入动态调整触觉反馈的强度,确保触觉响应及时且符合上下文。

双手灵巧系统由两个 UFactory xArm-7 机械臂组成,每个机械臂都配备 6 自由度 Ability 手,从而形成一个 24 自由度系统。每只手都集成分布在五个指尖上的 30 个触觉传感器。为了进行演示收集,两个 RealSense L515 摄像头被放置在机器人工作空间的前面和顶部,以捕捉足够的视觉观察。
为了从模仿学习的角度评估 AnyTeleop+ 和系统收集的演示质量,训练了几种流行的方法:ACT [5]、扩散策略 [34] 和 DP3 [40],并测试了它们对未见过场景的泛化性能。此外,还研究触觉数据在模仿学习中的有效性。尽管事实证明触觉反馈系统是有效的,但它并未在演示集中使用,因为它是在数据收集完成后设计的。
来自 Ability 手指尖的触觉信号集成到模仿学习框架中,评估其在各种条件下的有效性。在数据采集方面,来自 FSR 传感器的原始数据(用于测量在目标操作过程中施加在机器人上的压力)经过类似于触觉反馈处理的零漂移标定和低通滤波。此外,可以通过区分随时间变化的力来处理这些信号以计算力冲量。对于触觉数据表示,触摸信号被有效地表示为矢量,被视为机器人状态的组成部分,并使用多层感知器 (MLP) 进行编码。此外,由于触摸表示机器人和目标之间的接触点,这些点被可视化为虚点集。然后将它们与来自摄像机的点云数据连接起来,以增强模仿学习策略在视觉观察空间中的视觉嵌入。为了突出显示活动信号,附加一个布尔维度来指示触觉信号何时超过预定义阈值:力数据为 500,脉冲数据为 50。此表示法,受 DexPoint [55] 启发并改编。
遥操作系统有助于将人类运动映射到机器人动作。例如,将右手向前移动 0.1 米应导致机器人右端执行器产生等效运动。为了确保在三维空间中将人类运动精确转换为机器人动作,必须在初始化步骤中为人类操作员和机器人定义和同步坐标系。此阶段涉及为两个系统建立一个3-D框架,称为初始人体框架和初始机器人框架。然后测量人类操作员相对于初始人体框架的运动,机器人在其自己的初始机器人框架内复制这些运动。
双手遥操作需要仔细考虑操作员两只手的相对定位,这对于需要复杂双手协调的任务至关重要。鉴于机器人双手之间的间距可能因特定硬件配置而与人类不同,设计能够动态对齐机器人双手与操作员双手的适应性初始化模式至关重要。
本文实施 ACT [5]、扩散策略 [34] 和 3D 扩散策略 [40] 来严格评估系统收集的演示质量。为了加强绩效评估,设计泛化实验,重点关注每个任务中目标的空间位置和与未见过目标的交互。
学习算法。对于扩散策略,用多视角图像作为视觉输入,并建立一个视野为 8,包括 2 个观察步骤和 6 个行动步骤。该模型训练了 300 个 epochs,批次大小为 64。对于 3D 扩散策略,用多视角的点云作为输入,并保持与扩散策略相同的视野设置。该模型训练 500 个epochs,批次大小为 64。对于 ACT,使用多视角图像,块大小设置为 20,训练延长 3000 个epochs。
泛化评估设计。对于涉及不同空间位置和演示中未出现的新目标泛化实验,如图详细描述了每个任务的设计,其中蓝框表示目标的泛化范围,绿框确认在演示中未见过的目标。

这里空间范围包含一个很大的工作空间,而未见过目标的大小、颜色和形状各不相同,为从演示中学习的策略稳健性提供了全面的评估。

















 2001
2001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









