









欢迎关注[【AIGC论文精读】](https://blog.csdn.net/youcans/category_12321605.html)原创作品
【DeepSeek论文精读】1. 从 DeepSeek LLM 到 DeepSeek R1
【DeepSeek论文精读】7. DeepSeek 的发展历程与关键技术
【DeepSeek论文精读】10. DeepSeek-Coder-V2: 突破闭源模型在代码智能领域的障碍
【DeepSeek论文精读】10. DeepSeek-Coder-V2: 突破闭源模型在代码智能领域的障碍
0. 论文简介与摘要
0.1 论文简介
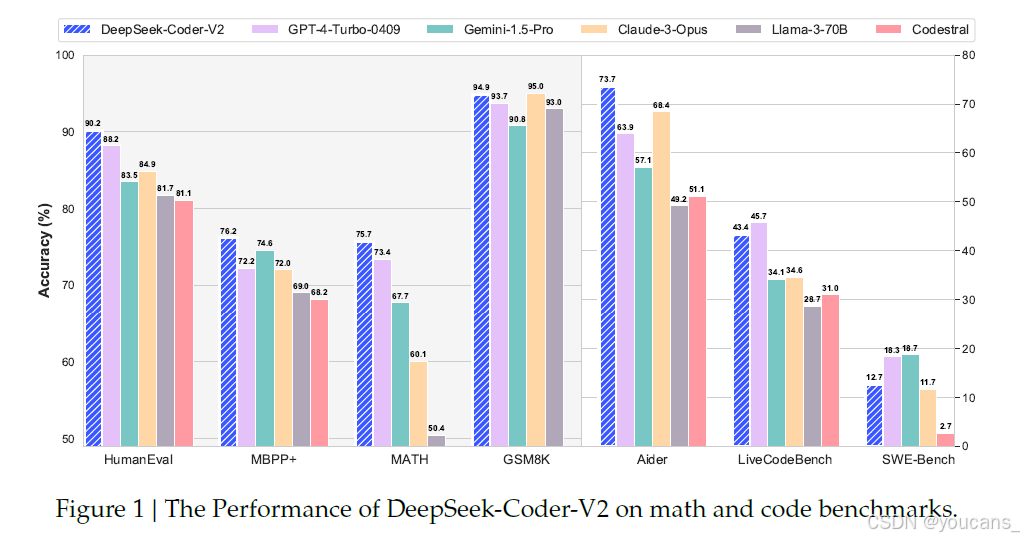
2024年 6月,DeepSeek 开源了DeepSeek-Coder-V2模型。DeepSeek-Coder-V2包含236B与16B两种参数规模,对编程语言的支持从86种扩展到338种。
DeepSeek-Coder-V2 模型是在 DeepSeek-V2 的基础上进行进一步预训练得到的,专注于代码生成和理解任务。根据相关评测,这是全球首个在代码、数学能力上超越GPT-4-Turbo、Claude3-Opus、Gemini-1.5Pro等的开源代码大模型。
- 论文标题:DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence(DeepSeek-Coder-V2: 突破闭源模型在代码智能领域的障碍)
- 发布时间:2024 年 5 月
- 论文作者:Qihao Zhu*, Daya Guo*, Zhihong Shao*, Dejian Yang*, et al.
- 下载地址:https://github.com/deepseek-ai/DeepSeek-Coder-V2

0.2 主要贡献
- 模型架构创新
- 混合专家(MoE)设计:提出 16B(2.4B激活参数)和 236B(21B激活参数)两个版本的MoE模型,显著提升计算效率。
- 超长上下文支持:将上下文窗口从 16K扩展至128K token,增强处理复杂编程任务(如长代码库分析)的能力。
- 编程语言覆盖:支持 338种编程语言,大幅提升通用性。
- 训练与数据优化
- 多模态预训练:使用 6万亿 token 混合数据(60%代码、10%数学、30%自然语言),来源包括GitHub和Common Crawl。
- 高效训练策略:
- 结合 Next-Token-Prediction 目标和 Fill-In-Middle(FIM)训练(16B版本)。
- 指令微调阶段采用 GRPO强化学习对齐**,优化模型行为。
- 性能突破
(1) 代码生成任务
- 代码生成:
- HumanEval 准确率 90.2%(236B),超越CodeLlama、StarCoder等开源模型,接近GPT-4 Turbo(88.2%)。
- MBPP+ 评分 76.2%,优于Gemini 1.5 Pro(75.3%)和Claude 3 Opus(74.7%)。
- 代码修复:
- SWE-Bench Lite 任务达成 12.7%,首个突破10%门槛的开源模型。
- 代码理解:
- CRUXEval 推理任务(CruxEval-I-COT)准确率 70.0%著领先其他开源模型。
(2) 数学推理
- MATH基准 准确率 75.7%,逼近GPT-4o(76.6%)。
- AIME 2024竞赛解决 5/30问题(maj@64),优于Claude 3 Opus(2/30)和Gemini 1.5 Pro(2/30)。
(3) 通用语言任务
- 在 MMLU、ARC、TriviaQA 等基准中保持与DeepSeek-V2相当,验证代码/数学训练未损害通用能力。
0.3 摘要
我们正式发布DeepSeek-Coder-V2——一个开源的混合专家(MoE)代码大模型,其在代码专项任务中的性能可比肩GPT4-Turbo。该模型基于DeepSeek-V2的中间检查点继续预训练,并追加训练了6万亿token。通过持续预训练,DeepSeek-Coder-V2在保持通用语言任务性能的同时,显著提升了DeepSeek-V2的代码生成与数学推理能力。相较于DeepSeek-Coder-33B,新模型在代码相关任务的各个维度及推理/通用能力上均实现重大突破。此外,DeepSeek-Coder-V2将支持的编程语言从86种扩展至338种,上下文窗口也从16K大幅提升至128K。在标准基准测试中,DeepSeek-Coder-V2于代码与数学评估项目上表现优异,性能超越GPT4-Turbo、Claude 3 Opus和Gemini 1.5 Pro等闭源模型。
1. 引言
开源社区通过开发StarCoder(Li等人,2023b;Lozhkov等人,2024)、CodeLlama(Rozière等人,2023)、DeepSeek-Coder(Guo等人,2024)和Codestral(MistralAI,2024)等开源代码模型,在推动代码智能发展方面取得了重大进展。这些模型的性能已逐步接近闭源模型,为代码智能的进步做出了贡献。然而,与GPT4-Turbo(OpenAI,2023)、Claude 3 Opus(Anthropic,2024)和Gemini 1.5 Pro(Reid等人,2024)等最先进的闭源模型相比,仍存在明显差距。为弥合这一差距并进一步推动开源代码模型的发展,我们推出了DeepSeek-Coder-V2系列模型。该系列基于DeepSeek-V2(DeepSeek-AI,2024)架构,并追加训练了包含6万亿token的语料库。
在预训练阶段,DeepSeek-Coder-V2的数据集由60%源代码、10%数学语料和30%自然语言语料构成。其中1,170亿代码相关token来自GitHub和CommonCrawl,采用与DeepSeekMath(Shao等人,2024)相同的处理流程。相较于训练DeepSeek-Coder所用的代码语料,本语料支持的编程语言从86种扩展至338种。为验证新代码语料的有效性,我们使用10亿参数模型进行消融实验,在HumanEval(Austin等人,2021a)和MBPP(Chen等人,2021)基准测试中准确率分别提升6.7%(从30.5%增至37.2%)和9.4%(从44.6%增至54.0%)。数学语料包含通过相同流程从CommonCrawl收集的2210亿token,规模约为DeepSeekMath原1200亿语料的两倍;自然语言语料则直接采样自DeepSeek-V2的训练语料。总计DeepSeek-Coder-V2接触了10.2万亿训练token,其中4.2万亿来自DeepSeek-V2数据集,剩余6万亿来自DeepSeek-Coder-V2数据集。
为适应更长代码输入并提升多编程场景适用性,我们将上下文窗口从16K扩展至128K token,使模型能处理更复杂的大规模编码任务。基于此多源语料库对DeepSeek-V2进行持续预训练后,发现DeepSeek-Coder-V2在保持通用语言性能的同时,显著增强了代码生成与数学推理能力。
在对齐阶段,我们首先构建包含DeepSeek-Coder(Guo等人,2024)与DeepSeek-Math(Shao等人,2024)的代码/数学数据、以及DeepSeek-V2(DeepSeek-AI,2024)通用指令数据的训练集,用于基础模型微调。随后在强化学习阶段,采用组相对策略优化(GRPO)算法使模型行为与人类偏好对齐:通过编译器反馈和测试用例收集编码领域偏好数据,并训练奖励模型指导策略模型优化,确保模型响应在编码任务中兼顾正确性与人类偏好。为实现对齐后的代码补全功能,我们在160亿参数基础模型微调时同步采用了填充中间(Fill-In-Middle)技术(Guo等人,2024)。
1.1 主要贡献
总体而言,我们的核心贡献包括:
-
高效MoE架构模型:基于DeepSeek-MoE框架推出16B和236B参数的DeepSeek-Coder-V2,其激活参数仅需2.4B和21B,高效支持多样化计算与应用需求。该模型同时支持338种编程语言及128K上下文长度。
-
开源百亿级代码模型突破:首次实现开源代码模型百亿参数规模,推动代码智能领域发展。实验表明,DeepSeek-Coder-V2 236B在代码与数学任务上均超越GPT4-Turbo、Claude 3 Opus和Gemini 1.5 Pro等顶尖闭源模型。
-
开放商用许可:模型以宽松许可证公开发布,支持研究及无限制商业用途。
1.2 评估与指标摘要
代码能力
在代码生成基准测试中,DeepSeek-Coder-V2显著超越所有开源模型,并与领先闭源模型性能持平,关键指标包括:
-
HumanEval(Chen等,2021):90.2%
-
MBPP(Austin等,2021a):76.2%(采用EvalPlus评估流程刷新SOTA记录)
-
LiveCodeBench(Jain等,2024):43.4%(测试2023年12月至2024年6月问题)
-
首个在SWEBench Lite(Jimenez等,2023)突破10%分的开源模型
数学能力
在数学推理任务中与闭源顶尖模型匹敌:
-
基础评测:GSM8K(Cobbe等,2021)
-
高阶竞赛:MATH(Hendrycks等,2021)75.7%(接近GPT-4o的76.6%)、AIME 2024(MAA)、Math Odyssey(Netmind.AI)
-
在AIME 2024竞赛中性能超越所有对比闭源模型
自然语言能力
保持与DeepSeek-V2相当的通用语言表现:
-
MMLU(OpenAI简易评测流程):79.2%
-
主观评测(GPT-4作为裁判):
-
arena-hard(Li等,2024):65.0
-
MT-bench(Zheng等,2023):8.77
-
alignbench(Liu等,2023c):7.84
-
上述分数显著优于其他代码专用模型,甚至媲美通用开源模型.
2. 数据收集
DeepSeek-Coder-V2的预训练数据主要由60%源代码、10%数学语料和30%自然语言语料构成。由于自然语言语料直接采样自DeepSeek-V2的训练数据集,本节重点介绍代码与数学数据的收集、清洗和过滤流程,同时通过对比分析实验验证数据质量。
代码数据收集
我们从GitHub收集2023年11月之前创建的公开代码库,首先采用与DeepSeek-Coder(Guo等,2024)相同的过滤规则和近重复删除技术,剔除低质量和重复源代码。为保持论文完整性,现简要说明过滤规则:
-
基础过滤
剔除平均行长度超过100字符或最大行长度超过1000字符的文件
删除字母占比低于25%的文件 -
语言特定规则
除XSLT外,移除前100字符含<?xml version=的文件
对HTML文件,保留可见文本占比≥20%且≥100字符的文件
对JSON/YAML文件,仅保留50-5000字符的文件以过滤数据密集型内容
经上述处理及近重复删除后,最终获得:
8210亿token代码(覆盖338种编程语言)
1850亿token代码相关文本(如Markdown、Issue讨论)
完整编程语言列表见附录A,分词器采用DeepSeek-V2相同方案(DeepSeek-AI,2024)。
数学与网络文本收集
对于Common Crawl中的代码与数学相关文本,我们沿用DeepSeekMath(Shao等,2024)的流程:
-
种子语料构建
代码类:StackOverflow、PyTorch文档等
数学类:StackExchange等 -
迭代扩展
基于fastText模型(Joulin等,2016)扩展语料,采用DeepSeek-V2的BPE分词器提升召回精度
标记代码/数学相关域名(首次迭代收集率>10%的域名)
经过三轮迭代,最终获得:
700亿token代码相关网页文本
2210亿token数学相关网页文本 -
GitHub补充收集
通过两轮迭代收集940亿token高质量源代码(含详细描述的代码优先)
最终,新代码语料库包含来自GitHub和CommonCrawl的1.17万亿代码相关token。
语料有效性验证
通过10亿参数模型的消融实验(见表1),对比新旧语料库效果:
-
1万亿token新语料训练:
HumanEval准确率提升5.5%(30.5%→36.0%)
MBPP准确率提升4.4%(44.6%→49.0%) -
2万亿token继续训练:
HumanEval进一步提升至37.2%
MBPP显著增至54.0%
实验结果证明新代码语料显著优于DeepSeek-Coder原训练语料。

3. 训练策略
3.1 训练目标
我们为DeepSeek-Coder-V2 16B模型采用两种训练目标:Next-Token-Prediction(下一词元预测)和Fill-In-Middle (FIM)(中间填充)(Bavarian等,2022;Guo等,2024;Li等,2023b)。对于DeepSeek-Coder-V2 236B模型,则仅使用Next-Token-Prediction目标。
以下简要介绍FIM训练策略:
在DeepSeek-Coder-V2-16B的开发中,我们采用基于PSM模式(前缀-后缀-中间)的FIM训练方法。该方法按以下顺序重构内容序列:
<|fim_begin|> 𝑓𝑝𝑟𝑒<|fim_hole|> 𝑓𝑠𝑢 𝑓<|fim_end|> 𝑓𝑚𝑖𝑑𝑑𝑙𝑒<|eos_token|>
该结构在文档级别应用,作为预打包流程的一部分。FIM的使用比例为0.5(与PSM框架一致),以提升训练效率和模型性能。
3.2 模型架构
我们的架构与DeepSeekV2(DeepSeek-AI,2024)保持一致。超参数设置(16B和236B)分别对应DeepSeek-V2-Lite和DeepSeek-V2的配置。
值得注意的是,训练过程中出现了梯度值波动和不稳定现象,经分析归因于指数归一化技术。为解决此问题,我们回退至传统归一化方法。
3.3 训练超参数
遵循DeepSeek V2方法(DeepSeek-AI,2024),我们使用AdamW优化器(Loshchilov和Hutter,2019),参数配置为𝛽₁=0.9、𝛽₂=0.95,权重衰减为0.1。批量大小和学习率根据DeepSeek-V2规范调整。
学习率调度采用余弦衰减策略:
- 初始2000步为热身阶段
- 后续逐步降低学习率至初始值的10%
DeepSeek-Coder-V2和DeepSeek-Coder-V2-Lite采用相同训练方法。为保持模型在自然语言理解上的强健性,我们从DeepSeek-V2的一个中间检查点(已预训练4.2万亿token)继续预训练。最终,DeepSeek-Coder-V2在预训练阶段共接触10.2万亿高质量token。
3.4 长上下文扩展
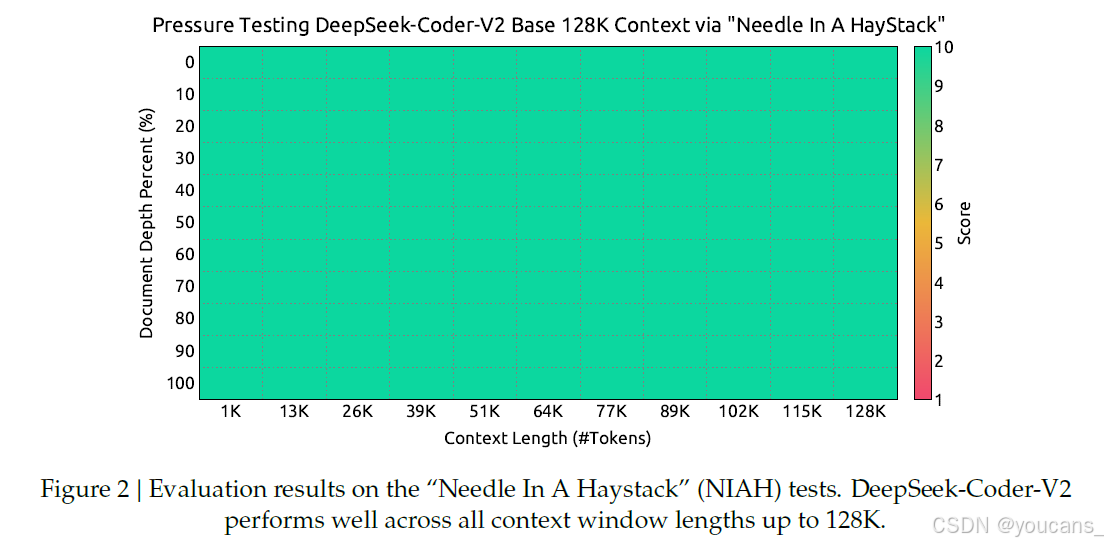
我们沿用DeepSeek-V2的方案,采用YARN方法(Peng等,2023)将DeepSeek-Coder-V2的上下文长度扩展至128K。YARN的超参数与DeepSeek-V2保持一致:缩放系数𝑠=40,𝛼=1,𝛽=32。
为增强模型处理长上下文的能力,我们采用两阶段继续训练:
-
第一阶段
序列长度:32K
批量大小:1152
训练步数:1000 -
第二阶段
序列长度:128K
批量大小:288
训练步数:1000
(注:在长上下文扩展阶段,我们提高了长上下文数据的采样比例)
如图2所示,在"Needle In A Haystack"(NIAH)测试中,DeepSeek-Coder-V2在128K上下文窗口内的所有长度上均表现优异。
3.5 对齐
3.5.1 监督微调
为构建DeepSeek-Coder-V2 Chat模型,我们构建了包含代码与数学数据的指令训练数据集:
- 从DeepSeek-Coder和DeepSeek-Math分别收集20K代码相关和30K数学相关指令数据
- 为保持通用能力,额外采样DeepSeek-V2的部分指令数据
- 最终使用300M token的指令数据集
训练参数:
- 学习率调度:余弦衰减(初始学习率5𝑒−6,100步热身)
- 批量大小:1M token
- 总训练量:1B token
3.5.2 强化学习
我们采用强化学习(RL)技术进一步优化模型能力,该方法被证实非常有效。
提示词工程
从多源收集约40K代码与数学相关提示词,每个代码提示词均配有对应测试用例。
奖励建模
奖励模型在RL训练中起关键作用:
- 数学偏好数据:采用真实标签
- 代码偏好数据:
- 编译器可提供0-1反馈(代码是否通过所有测试用例)
- 但部分提示词的测试用例覆盖不足,直接使用编译器信号存在噪声
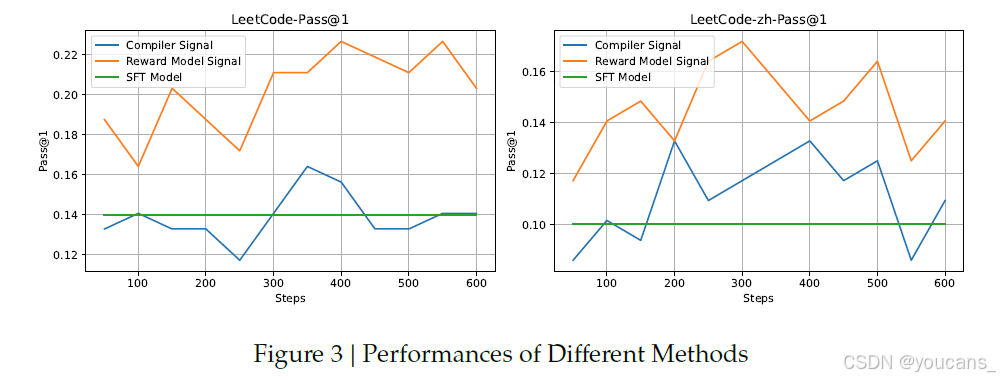
- 最终选择在编译器数据上训练奖励模型,因其比原始编译器信号更鲁棒、泛化能力更强
如图3所示,在内部测试集(Leetcode和Leetcode-zh)上,使用奖励模型信号的RL训练效果显著优于直接使用编译器信号。故后续实验均采用奖励模型信号。
强化学习算法
采用Group Relative Policy Optimization(GRPO)(Shao等,2024),该算法:
- 与DeepSeek-V2所用方案一致
- 相比PPO更高效(无需维护额外的critic模型)
- 已被证实具有显著效果优势
4. 实验结果
本节从代码、数学和通用自然语言三类任务评估DeepSeek-Coder-V2,并与当前最先进的大语言模型进行对比。
-
对比模型
CodeLlama(Rozière等,2023)
基于Llama2(Touvron等,2023)架构的代码大模型系列,在5000亿至1万亿代码token上继续预训练。提供7B/13B/34B/70B四种规模。 -
StarCoder(Lozhkov等,2024)
150亿参数开源模型,基于精选Stack数据集(Kocetkov等,2022)训练,覆盖86种编程语言。 -
StarCoder2(Lozhkov等,2024)
包含3B/7B/15B参数版本,在3.3-4.3万亿token的Stack2数据集训练,支持619种编程语言。 -
DeepSeek-Coder(Guo等,2024)
10亿至330亿参数的代码模型系列,使用2万亿token(87%代码+13%中英文自然语言)从头训练。通过16K窗口和填空任务预训练,支持项目级代码补全与填充。 -
Codestral(MistralAI,2024)
Mistral开发的220亿参数模型,训练数据涵盖80+编程语言(含Python/Java/JavaScript等主流语言及Swift/Fortran等专业语言)。
(注:后续实验结果部分将展示DeepSeek-Coder-V2与上述模型在三大类任务中的量化对比)
- 通用大语言模型
Llama3 70B(Meta,2024)
GPT-4(OpenAI,2023)
Claude 3 Opus(Anthropic,2024)
Gemini 1.5 Pro(Reid等,2024)
尽管这些模型并非专门针对代码训练,但在代码生成任务中仍展现出顶尖性能。
4.1 代码生成
HumanEval与MBPP基准测试
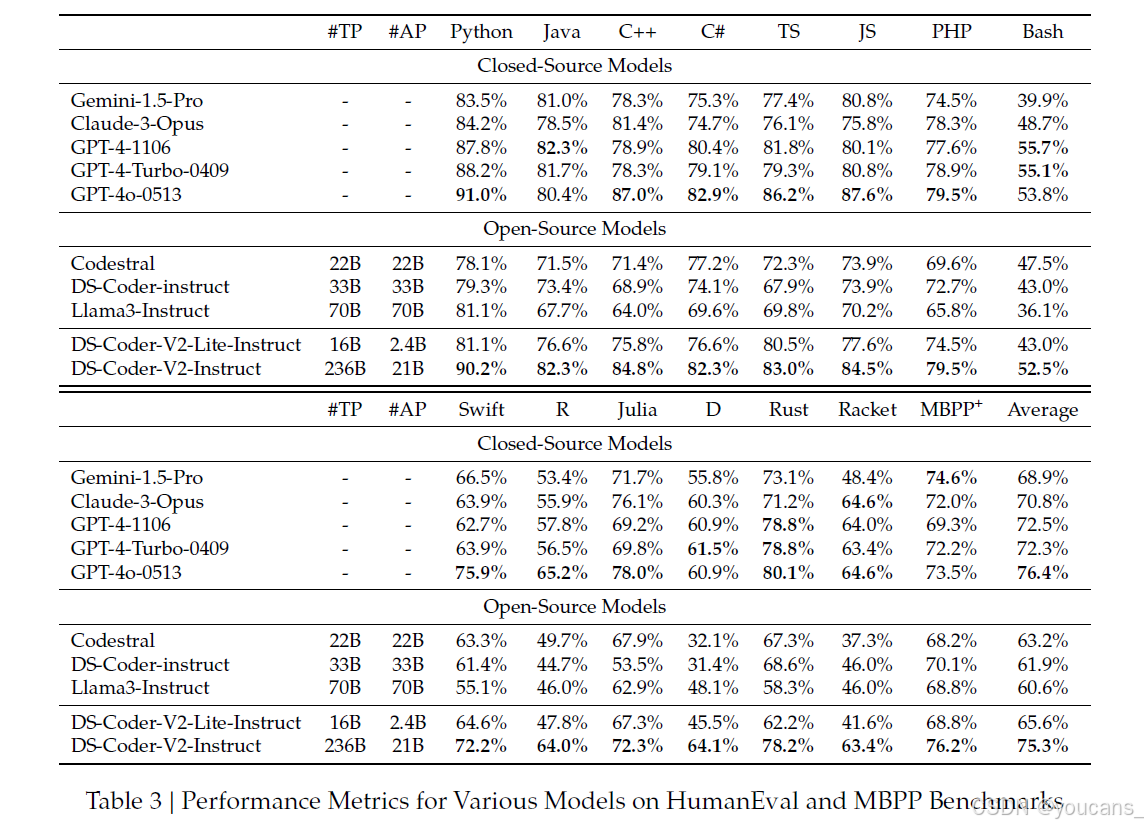
HumanEval(Chen等人,2021)和MBPP(Austin等人,2021b)基准测试通常用于评估代码生成大语言模型(LLMs)的性能。HumanEval包含164个Python任务,通过测试用例验证以评估Code LLMs在零样本场景下的表现。对于MBPP,我们使用MBPP-Plus版本(Liu等人,2023a)来评估模型。为了测试模型的多语言能力,我们将HumanEval基准问题扩展到以下七种额外语言:C++、Java、PHP、TypeScript、C#、Bash、JavaScript、Swift、R、Julia、D、Rust和Racket。对于这两个基准测试,我们采用贪婪搜索策略,并使用相同的脚本和环境重现基线结果以确保公平比较。
表3 提供了各模型在HumanEval和MBPP+基准测试中跨多种编程语言的性能指标概览。DeepSeekCoder-V2-Instruct表现出色,以75.3%的平均分位列第二。这一表现值得注意,因为它打破了闭源模型通常的统治地位,成为领先的开源竞争者。它仅落后于GPT-4o,后者以76.4%的平均分领先。DeepSeek-Coder-V2-Instruct在多种语言中均取得顶级结果,包括在Java和PHP中获得最高分,以及在Python、C++、C#、TypeScript和JavaScript中表现强劲,突显了其在处理多样化编码挑战时的稳健性和多功能性。
此外,DeepSeek-Coder-V2-Lite-Instruct的表现也令人印象深刻,超越了更大的33B模型。在平均性能上有显著优势(65.6%对61.9%),这凸显了16B模型尽管规模较小,仍能提供有竞争力的结果。这强调了模型的效率以及模型架构和训练方法的进步,使其能够超越更大的同类模型。
竞技编程。
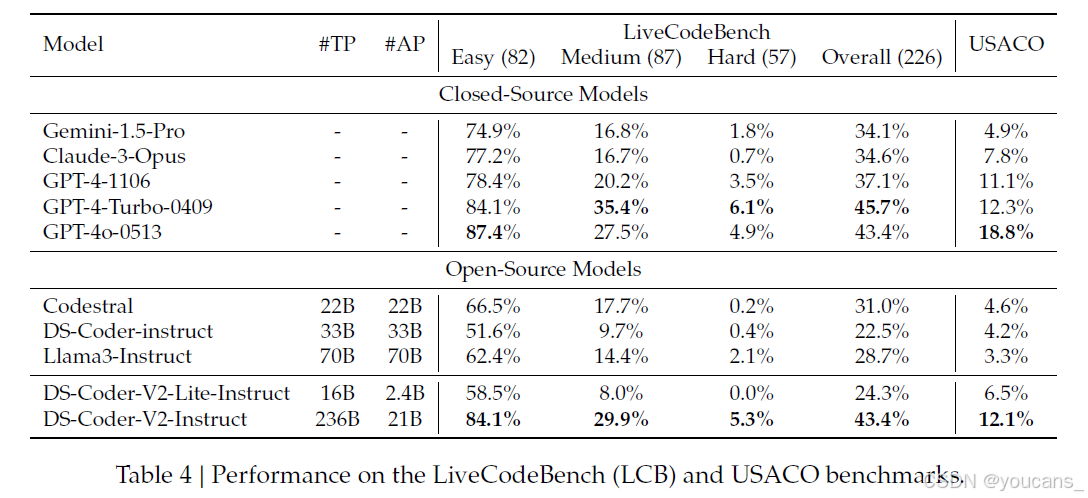
为了进一步验证模型在实际竞技编程问题中的能力,我们使用LiveCodeBench(Jain等人,2024)和USACO基准测试(Shi等人,2024)来评估DeepSeek-Coder-V2的有效性。LiveCodeBench是对大语言模型(LLMs)代码生成能力的细致且无污染的评估,系统性地从三个著名竞技编程平台:LeetCode、AtCoder和CodeForces收集新挑战。由于训练数据的截止日期是2023年11月之前,我们使用Livecodebench的子集(1201-0601)。USACO基准测试包含来自美国计算机奥林匹克竞赛的307个问题,每个问题都配有高质量的单元测试、参考代码和官方分析。
表4展示了各语言模型在这两个基准测试上的表现。值得注意的是,DeepSeek-Coder-V2-Instruct表现突出,以43.4%的分数与GPT-4o并列大模型中的最高分。这一优异表现使其总体排名第二,仅次于GPT-4-Turbo-0409,后者的总体表现为45.7%。DeepSeek-Coder-V2-Instruct处理复杂编码挑战的出色能力,使其成为顶级竞争者,紧随领先的GPT-4-Turbo变体之后。
4.2 代码补全
4.2.1 代码仓库级代码完成评估
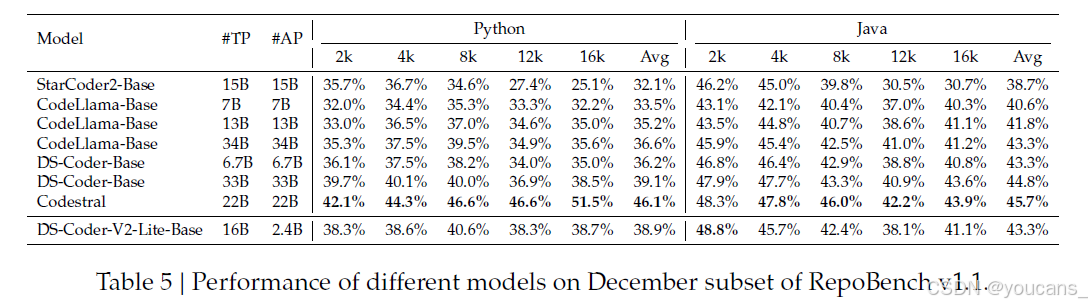
我们使用 RepoBench(Liu et al., 2023b)来评估当前可用的开源代码模型在代码仓库级代码完成任务中的能力,这些模型的大小都在 35B 以下。该数据集是从两个流行的编程语言(Python 和 Java)中构建的多样化的真实世界、开源、宽容许可的代码仓库中构建的。值得注意的是,RepoBench 的最新版本(v1.1)从 2023 年 10 月 6 日至 2023 年 12 月 31 日之间创建的 GitHub 代码仓库中获取数据,而我们的预训练数据包括在 2023 年 11 月之前创建的代码。为了确保该数据集不在我们的预训练数据中并避免数据泄露,我们只使用 2023 年 12 月的数据。
我们的评估包括五个上下文长度级别——2k、4k、8k、12k 和 16k 标记——跨三个设置:跨文件首先,跨文件随机和在文件中。我们对所有评估模型使用贪婪搜索。模型被限制为每个提示最多生成 64 个新标记,并且选取输出的第一个非空白和非注释行作为预测。提示的最大标记长度被设置为 15,800,方法是截断多余的跨文件上下文。我们报告了不同上下文长度级别的平均精确匹配。
如表 5 所示,结果表明 DeepSeek-Coder-V2-Lite-Base 模型尽管只有 2.4 亿个活跃参数,但在 Python 中实现了与 DeepSeek-Coder-Base 33B 模型相当的代码完成能力,在 Java 中实现了与 DeepSeek-Coder-Base 7B 模型相当的代码完成能力。与 CodeStral 相比,DeepSeek-Coder-V2-Lite-Base 模型只有 CodeStral 的十分之一的活跃参数,从而导致代码完成任务的性能较低。然而,我们相信 DeepSeek-Coder-V2 中较少的活跃参数使其在代码完成场景中更快。
4.2.2 填充中间代码完成
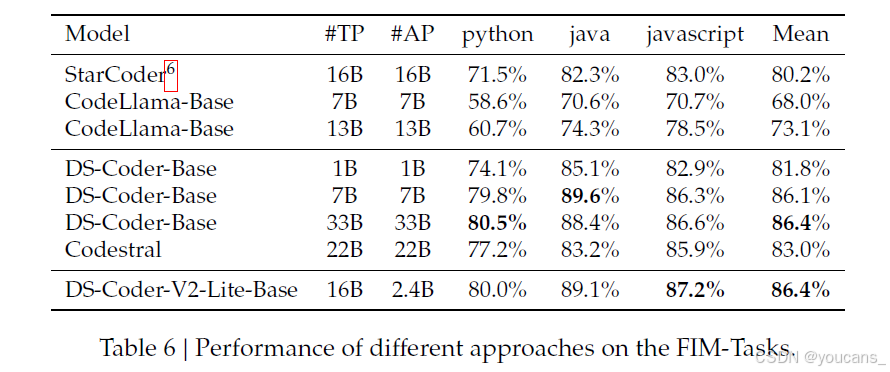
DeepSeek-Coder-V2-Lite 在预训练阶段采用了一种独特的方法,包括 0.5 的填充中间(FIM)率。这一方法允许模型通过使用周围上下文(包括前后的代码段)填充空白来完成代码,这对代码完成工具特别有优势。几个开源模型,如 SantaCoder(Allal et al., 2023)、StarCoder(Li et al., 2023b)和 CodeLlama(Roziere et al., 2023),也利用了类似的功能,并在代码生成和完成领域树立了高标准。
为了评估 DeepSeek-Coder-V2 模型的性能,我们进行了与领先模型的比较分析。评估基于 Single-Line Infilling 基准,涵盖 Allal et al.(2023)描述的三个不同编程语言。该评估的主要指标是线精确匹配准确率。
表格显示了各种编码模型在 FIM(填充中间)任务中跨三个编程语言(Python、Java 和 JavaScript)的性能,平均分表示整体有效性。在比较的模型中,具有 2.4B 活跃参数配置的 DeepSeek-Coder-V2-Lite-Base 实现了杰出的结果。它在 Python 中得分 80.0%,在 Java 中得分 89.1%,在 JavaScript 中得分 87.2%,从而获得了最高的平均分 86.4%。这证明了 DeepSeek-Coder-V2-Lite-Base 的优越有效性,特别是在处理不同编程语言的 FIM 任务时,与评估中的其他更大模型实现了相当的性能。
4.3 代码修复
为评估模型的缺陷修复能力,我们使用Defects4J、SWE-bench(Jimenez等人,2023)和Aider数据集进行测试。Defects4J是软件工程领域广泛使用的数据集,专门用于评估和测试程序修复技术。它包含来自各种开源项目(包括但不限于Apache Commons、JFreeChart和Closure Compiler)的真实软件缺陷集合。数据集中的每个缺陷都附带有测试套件,可用于验证程序修复工具的有效性。由于Defects4J中的原始缺陷可能需要修改代码库中的多个文件导致上下文过长,我们从该基准中筛选出仅需修改单个方法的238个缺陷。
SWE-bench是一个综合性基准,旨在评估大语言模型解决GitHub来源的真实软件问题的能力。该基准提供一个代码库及特定问题,要求语言模型生成能有效解决所述问题的补丁。这个严格的评估框架确保对语言模型理解和修复现实软件问题的能力进行全面测试,清晰衡量其在软件开发任务中的实际效用和有效性。我们在官方提供的SWE-Bench Lite版本上进行评估,该测试集包含300个问题,更高效且使用更广泛。我们采用OpenDevin的CodeACT agent v1.3框架并改进其动作提取部分。解码参数设置为𝑡𝑒𝑚𝑝𝑒𝑟𝑎𝑡𝑢𝑟𝑒=0.5和𝑡𝑜𝑝𝑝=0.95。GPT系列的结果来自OpenDevin,Claude-3-Opus的结果来自SWE-Agent。此外,我们使用相同测试脚本提供Gemini-1.5-Pro和Codestral的评估结果。但未评估Llama3-Instruct在SWE-Bench Lite上的表现,因其仅支持8K上下文长度。
Aider的代码编辑基准评估LLM修改Python源文件的能力,需完成133个不同的编码任务。该基准不仅测试LLM的编码技能,还检查其根据提示要求生成代码修改的一致性。对于DeepSeek-Coder-V2模型,我们使用完整格式进行评估。
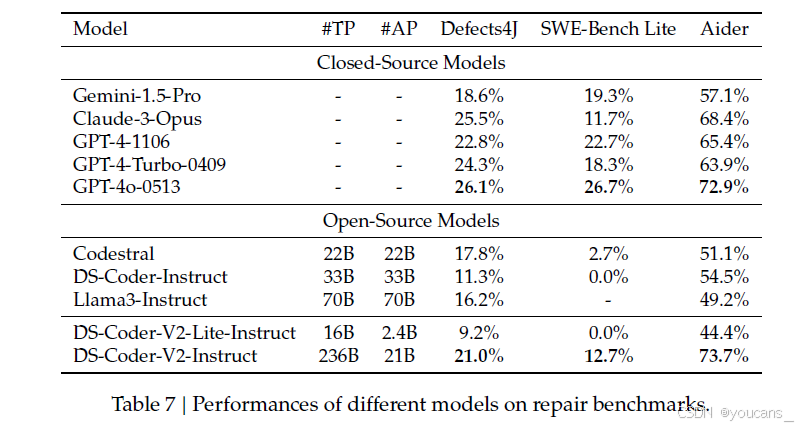
表7列出了不同语言模型在软件修复基准(包括Defects4J、SWE-Bench Lite和Aider)上的表现。在开源模型中,DeepSeek-Coder-Instruct表现突出,以21%的Defects4J得分和12.7%的SWE-Bench Lite得分成为开源模型中的最佳表现者,其处理长代码序列的能力已接近领先闭源模型。值得注意的是,DeepSeek-Coder-V2-Instruct在Aider上获得73.7%的最高分,超越所有列出的模型(包括闭源模型)。这一卓越表现突显了其在自动化代码修复任务中的高效性和稳健性,使DeepSeek-Coder-V2-Instruct成为顶级开源模型,也是该领域闭源替代方案的有力竞争者。
4.4 代码理解和推理
为了评估我们模型的代码推理能力,我们使用了CRUXEval基准测试。
该基准测试由800个Python函数及其对应的输入输出示例组成。它分为两个不同的任务:CRUXEval-I,要求大型语言模型(LLM)根据给定的输入预测输出,而CRUXEval-O则要求模型根据已知输出预测输入。这种结构挑战了模型理解和推理Python代码的能力,既可以正向也可以反向。
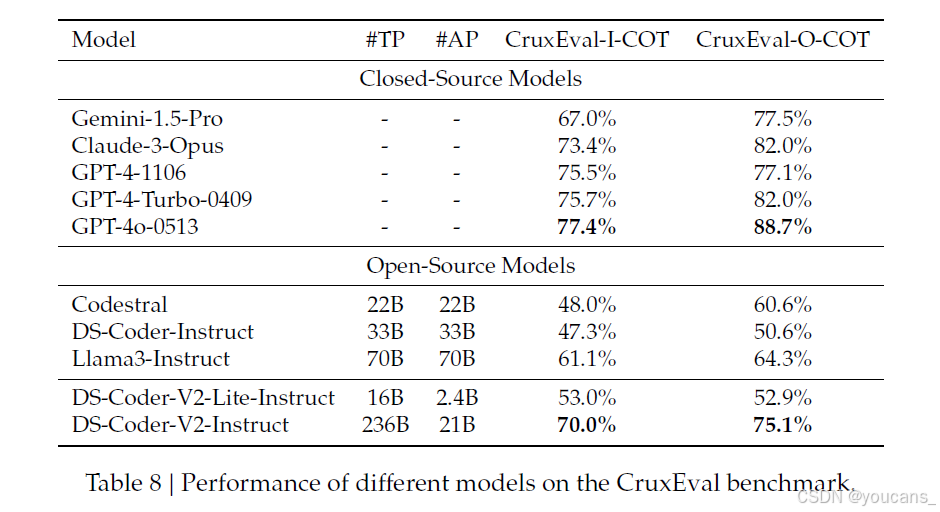
表8显示了各种语言模型在CruxEval基准测试上的性能,该基准测试使用两个指标评估模型:CruxEval-I-COT和CruxEval-O-COT。在开源模型中,DeepSeek-Coder-V2-Instruct表现出色。它在CruxEval-I-COT上获得了70.0%的分数,在CruxEval-O-COT上获得了75.1%的分数,展示了其在开源领域的优越能力。然而,与更大的闭源模型相比,仍然存在性能差距。这种性能差距在很大程度上可以归因于DeepSeek-Coder-V2-Instruct仅使用21亿激活参数,而闭源模型如GPT-4o的参数数量远远超过这一数字。这种模型复杂性的限制可能会限制其学习和问题解决能力。
4.5 数学推理
为了评估DeepSeekCoder-V2的数学推理能力,我们使用了流行的初级学校基准测试GSM8K(Cobbe et al., 2021),以及高级竞赛级别的基准测试,包括MATH(Hendrycks et al., 2021)、美国邀请数学考试(AIME)2024(MAA, 2024)和数学奥德赛(Netmind.AI, 2024)11。
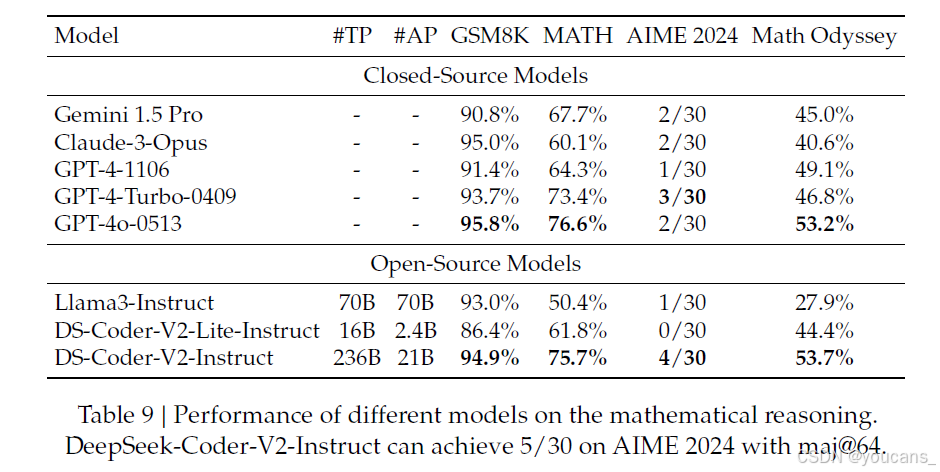
表9中的结果是在不使用工具或投票技术的情况下使用贪婪解码获得的,除非另有说明。DeepSeek-Coder-V2在MATH基准测试上实现了75.7%的准确率,在数学奥德赛基准测试上实现了53.7%的准确率,相当于最先进的GPT-4o。另外,DeepSeek-Coder-V2解决了比其他模型更多的AIME 2024问题,展示了其强大的数学推理能力。
4.6 通用自然语言
由于DeepSeek-Coder-V2是建立在DeepSeek-V2基础上的,因此它继承了强大的自然语言能力,甚至在推理相关基准测试中超越了DeepSeek-V2。我们比较了DeepSeek-Coder-V2 Instruct和DeepSeek-V2 Chat在标准基准测试上的性能,这些基准测试涵盖了英语和中文基准测试,包括BigBench Hard(BBH)(Suzgun et al., 2022)、MMLU(Hendrycks et al., 2020)、ARC(Clark et al., 2018)、TriviaQA(Joshi et al., 2017)、自然问题(Kwiatkowski et al., 2019)、AGIEval(Zhong et al., 2023)、CLUEWSC(Xu et al., 2020)、C-Eval(Huang et al., 2023)和CMMLU(Li et al., 2023a)。此外,我们还评估了模型的开放式生成能力,包括Arena-Hard(Li et al., 2024)、AlpacaEval2.0(Dubois et al., 2024)、MT-Bench(Zheng et al., 2023)和Alignbench(Liu et al., 2023c)。
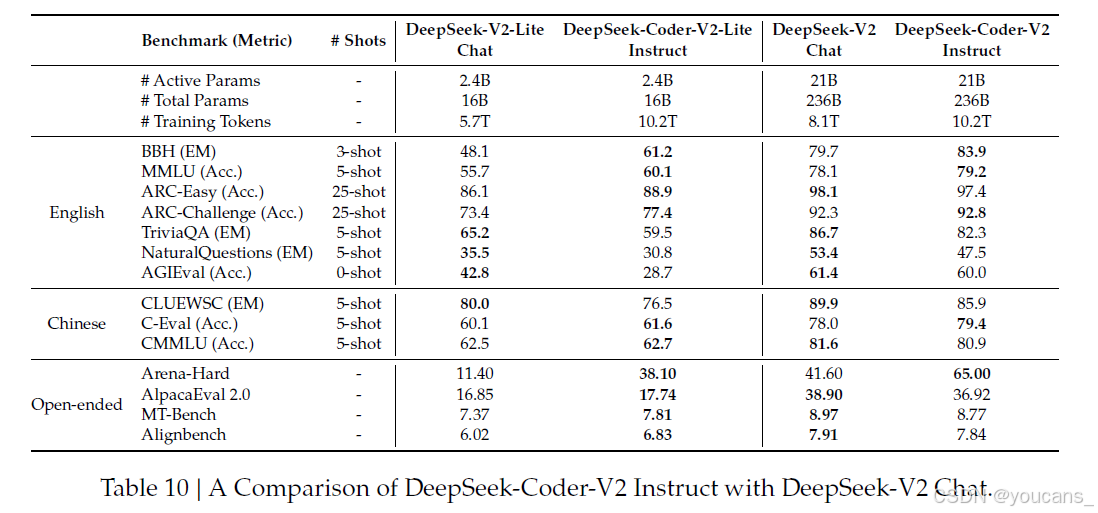
评估流程和指标与DeepSeek-V2相同,其中MMLU使用OpenAI simple-eval包进行评估https://github.com/openai/simple-evals。比较16B模型的性能时,很明显DeepSeek-Coder-V2-Lite-Instruct在BBH和Arena-Hard等基准测试中超越了DeepSeek-V2-Lite-Chat。这些基准测试对模型的推理能力要求很高,DeepSeek-Coder-V2-Lite-Instruct在这方面表现出色。然而,DeepSeek-Coder-V2-Lite Instruct在知识密集型基准测试如TriviaQA中落后,主要是因为预训练中使用的网页数据相对较少。
继续讨论236B模型,DeepSeek-Coder-V2 Instruct在推理基准测试中表现出更大的优势,特别是在Arena-Hard中,后者包含大量的代码、数学和推理问题。另一方面,DeepSeek-V2 Chat在MT-bench(Zheng et al., 2023)、AlpacaEval 2.0(Dubois et al., 2024)和AlignBench(Liu et al., 2023c)等基准测试中表现出略好的结果。这种优势可以归因于DeepSeek-V2 Chat的通用目的对齐阶段。
5. 结论
在本文中,我们介绍DeepSeek-Coder-V2,以进一步推进代码智能领域的发展,该模型在DeepSeek-V2的基础上持续预训练,使用了来自高质量和多源语料库的6万亿个标记。通过这种持续预训练,我们发现DeepSeek-Coder-V2显著增强了模型在编码和数学推理方面的能力,同时保持了与DeepSeek-V2相当的通用语言性能。相比DeepSeek-Coder,DeepSeek-Coder-V2支持的编程语言数量显著增加,从86种增加到338种,并将最大上下文长度从16K扩展到128K个标记。实验结果表明,DeepSeek-Coder-V2在代码和数学特定任务中实现了与state-of-the-art闭源模型(如GPT-4 Turbo、Claude 3 Opus和Gemini 1.5 Pro)相当的性能。
尽管DeepSeek-Coder-V2在标准基准测试中取得了令人印象深刻的性能,但我们发现它在遵循指令的能力方面仍然与当前state-of-the-art模型(如GPT-4 Turbo)相比存在显著差距。这一差距导致在复杂场景和任务(如SWEbench中)中的性能较差。因此,我们认为代码模型不仅需要强大的编码能力,还需要异常的遵循指令的能力,以处理现实世界中的复杂编程场景。在未来,我们将专注于提高模型的遵循指令的能力,以更好地处理现实世界中的复杂编程场景,并提高开发过程的生产力。
6. 模型下载与应用
6.1 模型下载
我们基于DeepSeekMoE框架,向公众发布了具有16B和236B参数的DeepSeek-Coder-V2,该框架仅激活了2.4B和21B的参数,包括基础模型和指令模型。
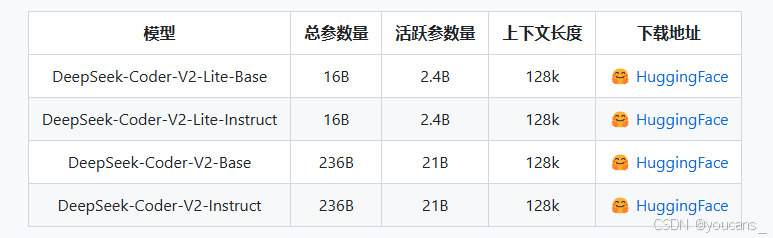
下载地址:
https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Lite-Base
6.2 API平台
我们还在 DeepSeek 平台提供了与 OpenAI 兼容的 API:platform.deepseek.com,并且您可以以无与伦比的价格按需付费。
6.3 本地运行
在这里,我们提供了一些使用 DeepSeek-Coder-V2-Lite 模型的示例。如果您想使用 BF16 格式的 DeepSeek-Coder-V2 进行推理,需要 80GB*8 块 GPU。
使用 Huggingface 的 Transformers 进行推理
您可以直接使用 Huggingface 的 Transformers 进行模型推理。
6.3.1 代码补全
from modelscope import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Instruct", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Instruct", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
input_text = "#write a quick sort algorithm"
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
6.3.2 代码插入
from modelscope import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Instruct", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Instruct", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
input_text = """<|fim▁begin|>def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
left = []
right = []
<|fim▁hole|>
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right)<|fim▁end|>"""
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True)[len(input_text):])
6.3.3 聊天补全
from modelscope import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Instruct", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Instruct", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
messages=[
{ 'role': 'user', 'content': "write a quick sort algorithm in python."}
]
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
# tokenizer.eos_token_id is the id of <|end▁of▁sentence|> token
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, top_k=50, top_p=0.95, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
聊天模板完整版可在 Huggingface 模型仓库中的 tokenizer_config.json 文件内找到。
一个聊天模板示例如下:
<|begin▁of▁sentence|>User: {user_message_1}
Assistant: {assistant_message_1}<|end▁of▁sentence|>User: {user_message_2}
Assistant:
您还可以添加一个可选的系统消息:
<|begin▁of▁sentence|>{system_message}
User: {user_message_1}
Assistant: {assistant_message_1}<|end▁of▁sentence|>User: {user_message_2}
Assistant:
6.3.4 使用 vLLM 进行推理(推荐)
为了使用 vLLM 进行模型推理,请将此 Pull Request 合并到您的 vLLM 代码库中:https://github.com/vllm-project/vllm/pull/4650。
from modelscope import AutoTokenizer
from vllm import LLM, SamplingParams
max_model_len, tp_size = 8192, 1
model_name = "deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
llm = LLM(model=model_name, tensor_parallel_size=tp_size, max_model_len=max_model_len, trust_remote_code=True, enforce_eager=True)
sampling_params = SamplingParams(temperature=0.3, max_tokens=256, stop_token_ids=[tokenizer.eos_token_id])
messages_list = [
[{"role": "user", "content": "Who are you?"}],
[{"role": "user", "content": "write a quick sort algorithm in python."}],
[{"role": "user", "content": "Write a piece of quicksort code in C++."}],
]
prompt_token_ids = [tokenizer.apply_chat_template(messages, add_generation_prompt=True) for messages in messages_list]
outputs = llm.generate(prompt_token_ids=prompt_token_ids, sampling_params=sampling_params)
generated_text = [output.outputs[0].text for output in outputs]
print(generated_text)
参考文献
L. B. Allal, R. Li, D. Kocetkov, C. Mou, C. Akiki, C. M. Ferrandis, N. Muennighoff, M. Mishra,
A. Gu, M. Dey, et al. Santacoder: don’t reach for the stars! arXiv preprint arXiv:2301.03988,
2023.
A. Anthropic. The claude 3 model family: Opus, sonnet, haiku. Claude-3 Model Card, 2024.
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry,
Q. Le, and C. Sutton. Program synthesis with large language models, 2021a.
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry,
Q. Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732,
2021b.
M. Bavarian, H. Jun, N. Tezak, J. Schulman, C. McLeavey, J. Tworek, and M. Chen. Efficient
training of language models to fill in the middle. arXiv preprint arXiv:2207.14255, 2022.
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y. Burda,
N. Joseph, G. Brockman, et al. Evaluating large language models trained on code. arXiv
preprint arXiv:2107.03374, 2021.
P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord. Think you
have solved question answering? try arc, the AI2 reasoning challenge. CoRR, abs/1803.05457,
2018. URL http://arxiv.org/abs/1803.05457.
K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek,
J. Hilton, R. Nakano, et al. Training verifiers to solve math word problems. arXiv preprint
arXiv:2110.14168, 2021.
DeepSeek-AI. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language
model, 2024.
Y. Dubois, B. Galambosi, P. Liang, and T. B. Hashimoto. Length-controlled alpacaeval: A simple
way to debias automatic evaluators. arXiv preprint arXiv:2404.04475, 2024.
D. Guo, Q. Zhu, D. Yang, Z. Xie, K. Dong,W. Zhang, G. Chen, X. Bi, Y.Wu, Y. Li, et al. Deepseekcoder:
When the large language model meets programming–the rise of code intelligence.
arXiv preprint arXiv:2401.14196, 2024.
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring
massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt. Measuring
mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874,
2021.
Y. Huang, Y. Bai, Z. Zhu, J. Zhang, J. Zhang, T. Su, J. Liu, C. Lv, Y. Zhang, J. Lei, et al. C-Eval: A
multi-level multi-discipline chinese evaluation suite for foundation models. arXiv preprint
arXiv:2305.08322, 2023.
N. Jain, K. Han, A. Gu,W.-D. Li, F. Yan, T. Zhang, S.Wang, A. Solar-Lezama, K. Sen, and I. Stoica.
Livecodebench: Holistic and contamination free evaluation of large language models for code,
2024.
C. E. Jimenez, J. Yang, A.Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan. Swe-bench: Can
language models resolve real-world github issues? arXiv preprint arXiv:2310.06770, 2023.
M. Joshi, E. Choi, D.Weld, and L. Zettlemoyer. TriviaQA: A large scale distantly supervised challenge
dataset for reading comprehension. In R. Barzilay and M.-Y. Kan, editors, Proceedings of
the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long
Papers), pages 1601–1611, Vancouver, Canada, July 2017. Association for Computational
Linguistics. doi: 10.18653/v1/P17-1147. URL https://aclanthology.org/P17-1147.
A. Joulin, E. Grave, P. Bojanowski, M. Douze, H. Jégou, and T. Mikolov. Fasttext. zip: Compressing
text classification models. arXiv preprint arXiv:1612.03651, 2016.
D. Kocetkov, R. Li, L. Jia, C. Mou, Y. Jernite, M. Mitchell, C. M. Ferrandis, S. Hughes, T. Wolf,
D. Bahdanau, et al. The stack: 3 tb of permissively licensed source code. Transactions on
Machine Learning Research, 2022.
T. Kwiatkowski, J. Palomaki, O. Redfield, M. Collins, A. P. Parikh, C. Alberti, D. Epstein,
I. Polosukhin, J. Devlin, K. Lee, K. Toutanova, L. Jones, M. Kelcey, M. Chang, A. M. Dai,
J. Uszkoreit, Q. Le, and S. Petrov. Natural questions: a benchmark for question answering
research. Trans. Assoc. Comput. Linguistics, 7:452–466, 2019. doi: 10.1162/tacl_a_00276.
URL https://doi.org/10.1162/tacl_a_00276.
H. Li, Y. Zhang, F. Koto, Y. Yang, H. Zhao, Y. Gong, N. Duan, and T. Baldwin. CMMLU: Measuring
massive multitask language understanding in Chinese. arXiv preprint arXiv:2306.09212,
2023a.
R. Li, L. B. Allal, Y. Zi, N. Muennighoff, D. Kocetkov, C. Mou, M. Marone, C. Akiki, J. Li, J. Chim,
et al. Starcoder: may the source be with you! arXiv preprint arXiv:2305.06161, 2023b.
T. Li,W.-L. Chiang, E. Frick, L. Dunlap, B. Zhu, J. E. Gonzalez, and I. Stoica. From live data to
high-quality benchmarks: The arena-hard pipeline, April 2024. URL https://lmsys.org/
blog/2024-04-19-arena-hard/.
J. Liu, C. S. Xia, Y. Wang, and L. Zhang. Is your code generated by chatGPT really correct? rigorous
evaluation of large language models for code generation. In Thirty-seventh Conference
on Neural Information Processing Systems, 2023a. URL https://openreview.net/for
um?id=1qvx610Cu7.
T. Liu, C. Xu, and J. McAuley. Repobench: Benchmarking repository-level code auto-completion
systems. In The Twelfth International Conference on Learning Representations, 2023b.
X. Liu, X. Lei, S.Wang, Y. Huang, Z. Feng, B.Wen, J. Cheng, P. Ke, Y. Xu,W. L. Tam, X. Zhang,
L. Sun, H. Wang, J. Zhang, M. Huang, Y. Dong, and J. Tang. Alignbench: Benchmarking
chinese alignment of large language models. CoRR, abs/2311.18743, 2023c. doi: 10.48550/A
RXIV.2311.18743. URL https://doi.org/10.48550/arXiv.2311.18743.
I. Loshchilov and F. Hutter. Decoupled weight decay regularization, 2019.
A. Lozhkov, R. Li, L. B. Allal, F. Cassano, J. Lamy-Poirier, N. Tazi, A. Tang, D. Pykhtar,
J. Liu, Y. Wei, et al. Starcoder 2 and the stack v2: The next generation. arXiv preprint
arXiv:2402.19173, 2024.
MAA. American invitational mathematics examination - aime. American Invitational
Mathematics Examination - AIME 2024, 2024. URL https://maa.org/math-competi
tions/american-invitational-mathematics-examination-aime.
Meta. Introducing meta llama 3: The most capable openly available llm to date. https:
//ai.meta.com/blog/meta-llama-3/, April 2024.
MistralAI. Codestral. https://mistral.ai/news/codestral/, 2024. Accessed: 2024-05-29.
Netmind.AI. Odyssey-math. https://github.com/protagolabs/odyssey-math/tree
/main, 2024. Accessed: April 22, 2024.
OpenAI. Gpt-4 technical report, 2023.
B. Peng, J. Quesnelle, H. Fan, and E. Shippole. Yarn: Efficient context window extension of large
language models. arXiv preprint arXiv:2309.00071, 2023.
M. Reid, N. Savinov, D. Teplyashin, D. Lepikhin, T. Lillicrap, J.-b. Alayrac, R. Soricut, A. Lazaridou,
O. Firat, J. Schrittwieser, et al. Gemini 1.5: Unlocking multimodal understanding across
millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024.
B. Roziere, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y. Adi, J. Liu, T. Remez, J. Rapin,
et al. Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950, 2023.
Z. Shao, P.Wang, Q. Zhu, R. Xu, J. Song, M. Zhang, Y. Li, Y.Wu, and D. Guo. Deepseekmath:
Pushing the limits of mathematical reasoning in open language models. arXiv preprint
arXiv:2402.03300, 2024.
Q. Shi, M. Tang, K. Narasimhan, and S. Yao. Can languagemodels solve olympiad programming?
arXiv preprint arXiv:2404.10952, 2024.
M. Suzgun, N. Scales, N. Schärli, S. Gehrmann, Y. Tay, H.W. Chung, A. Chowdhery, Q. V. Le,
E. H. Chi, D. Zhou, et al. Challenging big-bench tasks and whether chain-of-thought can solve
them. arXiv preprint arXiv:2210.09261, 2022.
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra,
P. Bhargava, S. Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv
preprint arXiv:2307.09288, 2023.
L. Xu, H. Hu, X. Zhang, L. Li, C. Cao, Y. Li, Y. Xu, K. Sun, D. Yu, C. Yu, Y. Tian, Q. Dong, W. Liu,
B. Shi, Y. Cui, J. Li, J. Zeng, R. Wang, W. Xie, Y. Li, Y. Patterson, Z. Tian, Y. Zhang, H. Zhou,
S. Liu, Z. Zhao, Q. Zhao, C. Yue, X. Zhang, Z. Yang, K. Richardson, and Z. Lan. CLUE: A chinese
language understanding evaluation benchmark. In D. Scott, N. Bel, and C. Zong, editors,
Proceedings of the 28th International Conference on Computational Linguistics, COLING
2020, Barcelona, Spain (Online), December 8-13, 2020, pages 4762–4772. International Committee
on Computational Linguistics, 2020. doi: 10.18653/V1/2020.COLING-MAIN.419. URL
https://doi.org/10.18653/v1/2020.coling-main.419.
L. Zheng,W.-L. Chiang, Y. Sheng, S. Zhuang, Z.Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing,
H. Zhang, J. E. Gonzalez, and I. Stoica. Judging llm-as-a-judge with mt-bench and chatbot
arena, 2023.
W. Zhong, R. Cui, Y. Guo, Y. Liang, S. Lu, Y.Wang, A. Saied, W. Chen, and N. Duan. AGIEval: A
human-centric benchmark for evaluating foundation models. CoRR, abs/2304.06364, 2023.
doi: 10.48550/arXiv.2304.06364. URL https://doi.org/10.48550/arXiv.2304.06364.
版权声明:
本文由 youcans@xidian 对论文 DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence进行摘编和翻译,只供研究学习使用。
youcans@xidian 作品,转载必须标注原文链接:
【DeepSeek论文精读】10. DeepSeek-Coder-V2: 突破闭源模型在代码智能领域的障碍
Copyright 2025 youcans, XIDIAN
Created:2025-05


















 2724
2724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











