




更多内容请关注【动手学YOLO】专栏
【动手学YOLO】DINO-YOLO:面向数据高效目标检测的自监督预训练方法
0. 论文简介
0.1 基本信息
2025 年,Malaisree P 等发布论文 【DINO-YOLO:面向土木工程应用的数据高效目标检测的自监督预训练方法】(DINO-YOLO: Self-Supervised Pre-training for Data-Efficient Object Detection in Civil Engineering Applications)。
本文提出 DINO-YOLO 混合架构,通过将DINOv3 自监督视觉 Transformer 与 YOLOv12 在输入预处理(P0)和中 backbone 增强(P3)两个关键位置进行策略性集成,解决土木工程领域目标检测标注数据有限的问题,为建筑安全监测、基础设施检测等数据受限场景提供实用解决方案。
论文标题: DINO-YOLO: Self-Supervised Pre-training for Data-Efficient Object Detection in Civil Engineering Applications
作者: Malaisree P, Youwai S, Kitkobsin T, Janrungautai S, Amorndechaphon D, Rojanavasu P
机构: MAA Consultants Co., Ltd., King Mongkut’s University of Technology Thonburi(泰国国王科技大学), University of Phayao(帕尧大学)
论文地址: arxiv
代码仓库: github
引用格式: Malaisree P, Youwai S, Kitkobsin T, et al. DINO-YOLO: Self-Supervised Pre-training for Data-Efficient Object Detection in Civil Engineering Applications[EB/OL]. [2025-10-31]. https://arxiv.org/pdf/2510.25140.
0.2 论文概览
解决的问题:
- 现代 YOLO 架构(如 YOLOv12)设计初衷为适配大规模数据集,参数规模大,在小数据集上易过拟合、泛化能力差
- 土木工程领域特殊性导致标注数据有限,需在复杂环境(光照变化、遮挡、背景杂乱)中检测特定目标
自监督学习框架 DINOv3(基于教师 - 学生网络知识蒸馏),经17 亿张无标注图像预训练,可提取跨域鲁棒视觉特征,无需依赖人工标注,适合解决数据稀缺问题
模型架构设计(DINO-YOLO):
- 架构逻辑:结合 YOLOv12 的空间定位优势与 DINOv3 的语义特征优势,通过分层语义特征注入解决数据稀缺下的性能问题
- 关键组件与参数:
- 基础框架:YOLOv12 骨干网络
- DINOv3 模块:采用 ViT-B/16 变体(86M 参数 / 个,冻结)
- 特征金字塔:含自上而下、自下而上路径
主要创新:
DINO-YOLO 的创新之处在于它如何将 DINOv3 的特征“注入”到 YOLOv12 的架构中。架构修改的核心是双点注入”策略:
- 输入端注入 (P0):
在初始特征提取阶段(P0),在空间下采样前将原始像素表示转换为语义奠基的特征空间。 - 主干网络中部注入 (P3):
在特征金字塔中间层级(P3)实施,在语义抽象与空间分辨率达到最优平衡的架构位置提供语义增强,提升检测头处理的特征质量。
0.3 摘要
土木工程应用中的目标检测受限于专业领域标注数据匮乏的问题。
本文提出一种混合架构 DINO-YOLO,将 YOLOv12 与 DINOv3 自监督视觉 Transformer 相结合,以实现数据高效的目标检测。该架构将 DINOv3 特征策略性集成在两个关键位置:输入预处理层(P0)和中骨干网络增强层(P3)。
实验验证表明,该模型性能获得显著提升:隧道段裂缝检测数据集(648 张图像)上性能提升 12.4%,建筑个人防护装备(PPE)检测数据集(1000 张图像)上提升 13.7%,KITTI 数据集(7000 张图像)上提升 88.6%,同时保持 30-47 帧 / 秒的实时推理速度。通过对五种 YOLO 模型规模和九种 DINOv3 变体的系统性消融实验发现,中等规模架构采用 DualP0P3 集成策略时性能最优(平均精度均值 mAP@0.5 达 55.77%),而小规模架构则需采用三重集成策略(mAP@0.5 达 53.63%)。相较于基线模型 8-16 毫秒的推理时间,该模型 21-33 毫秒的推理开销在 NVIDIA RTX 5090 硬件上仍满足现场部署需求。
DINO-YOLO 在小规模土木工程数据集(少于 10000 张图像)上实现了当前最优性能,同时保持计算效率,为数据受限环境下的建筑安全监测和基础设施检测提供了实用解决方案。
1. 引言
目标检测已成为一项基础的计算机视觉任务,在从自动驾驶到工业检测系统等众多领域中有着广泛应用。深度学习架构的演进,尤其是 YOLO 系列模型(Khanam 和 Hussain,2024;Tian 等人,2025;Wang 等人,2024;Wang 和 Liao,2024;Youwai 等人,2024),通过在精度与计算效率之间实现出色平衡,显著提升了实时目标检测能力。然而,传统目标检测框架在部署于标注数据有限的专业领域时,仍面临持续挑战 —— 传统的随机权重初始化策略往往会导致收敛效果欠佳,且特征表示学习不够充分。
现代 YOLO 架构(尤其是最新版本)在设计时特意赋予了较大的模型容量,以充分利用大规模训练数据集(如 “上下文通用目标”(COCO)数据集(Lin 等人,2014))。该数据集包含跨多个领域的多类别标注,拥有数百万个带标签样本。尽管这种架构设计理念有利于从大规模多样化数据集中学习复杂的视觉表示,但将其应用于数据可获得性有限的专业场景时,会引发显著挑战。这些大规模模型包含大量参数,原本优化用于处理涵盖数十万个图像、数百个目标类别的数据集,当面对专业工程领域中典型的小规模数据集时,往往会出现过拟合现象,且泛化能力较差。模型容量与数据可获得性之间的这种根本性不匹配,已成为将最先进目标检测框架应用于实际工业场景的关键瓶颈。
建筑和交通基础设施领域是土木工程中目标检测的核心应用场景,其中自动化监测对于结构完整性、人员安全和运营效率至关重要。隧道施工监测、建筑工地安全监测和城市交通管理这三大相互关联的系统,充分体现了计算机视觉在土木工程中的重要性与面临的挑战。隧道施工需要精确检测锚杆等地层支护构件以保障结构稳定性(Chang 等人,2026;Olivier 等人,2025);建筑工地则要求准确检测个人防护装备(PPE)以保障工人安全(Alashrafi 等人,2025;Khan 等人,2026);此外,城市交通系统需要实时检测车辆、行人及基础设施缺陷,以支持交通管理和维护工作。这些应用场景对计算机视觉提出了独特挑战:需在多变环境下实现高精度检测,需在杂乱背景中识别领域特定目标(Huang 等人,2025;Tang 等人,2025),且涉及安全关键决策 —— 检测失败可能导致结构损坏或安全事故。最为关键的是,现实世界土木工程领域的训练数据本质上极为有限:与拥有数百万张图像的通用数据集不同,由于场地访问受限、安全约束以及基础设施项目的专业性,领域特定应用的样本数量通常仅为数百至数千张,这使得稳健模型的开发极具挑战性。
自监督学习的最新进展表明,其具备从大规模无标注数据集中学习丰富视觉表示的巨大潜力。“无标注自蒸馏”(DINO)框架,尤其是其最新版本 DINOv3(Oquab 等人,2023;Siméoni 等人,2025),通过在大规模图像集合上进行自监督预训练,展现出学习语义相关特征的卓越能力。DINOv3 采用基于教师 - 学生网络知识蒸馏的自监督学习范式,两个网络处理同一张图像的不同增强视图,无需任何人工标注。训练过程中,动量教师网络从一个增强视图生成伪标签,学生网络则从另一个增强视图学习预测这些目标,从而使模型能够通过视图一致性发现有意义的视觉模式。关键在于,DINOv3 基于约 17 亿张来自多样化互联网集合的精选图像进行预训练,涵盖的视觉概念、场景和目标范围远超传统监督数据集。这种基于无标注数据的大规模预训练,使 DINOv3 能够学习通用视觉表示 —— 捕捉基础图像结构和语义,而不受特定分类体系或领域特定标注的约束。与依赖带预定义类别标签的人工标注数据集的传统监督预训练方法不同,DINO 的自监督方法能够提取稳健的特征表示,捕捉可跨多个领域迁移的基础视觉模式,这使其特别适合用于专业应用中检测模型的初始化。
在专业工程应用常见的数据稀缺场景中,随机权重初始化的根本局限性尤为突出 —— 训练样本不足会导致过拟合和泛化能力差。这一挑战在与建筑相关的计算机视觉任务中更为严峻:由于需要专业知识,收集和标注大规模数据集的成本极高。迁移学习已成为一种颇具前景的解决方案,而 DINOv3 等自监督方法通过从 17 亿张多样化无标注图像中学习,无需受特定分类体系的约束,能够提供更优质的特征表示。与在 ImageNet 上进行的传统监督预训练不同,DINOv3 的大规模预训练能够提取稳健、可迁移的视觉模式,显著降低对大规模领域特定训练数据集的依赖,这使其特别适合用于专业应用中检测模型的初始化 —— 在这些应用中,若受限于训练数据不足,大容量模型往往难以发挥作用。
本文通过提出 DINO-YOLO 这一增强型目标检测框架,解决了上述挑战。该框架将 DINOv3 预训练权重策略性地集成到 YOLOv12 骨干网络架构中。
- 我们的研究假设是:在数据有限的场景中(尤其是建筑工地监测和基础设施检测等专业领域),自监督预训练表示能够为高效目标检测提供关键的语义基础。
- 通过在 YOLOv12 骨干网络的三个关键位置融入 DINO 权重,我们的框架旨在提升特征提取能力,同时保持实际部署所需的计算效率。这种权重初始化策略通过提供从大规模无标注数据中学习到的语义丰富的特征表示,有效弥合了大容量模型架构与小规模专业数据集之间的差距。
为全面评估所提出的 DINO-YOLO 框架,我们在多样化数据集上进行了系统性实验,这些数据集既包括专业小规模应用场景,也涵盖成熟的大规模基准数据集。具体而言,我们采用了三个不同的基准数据集:(1)用于基础设施检测的隧道段裂缝检测数据集;(2)用于建筑工人安全监测的个人防护装备(PPE)检测数据集;(3)用于自动驾驶场景的 KITTI 基准数据集。KITTI 基准数据集作为关键评估组件,用于评估模型在广泛认可的大规模数据集上的泛化能力和性能扩展性,从而验证自监督预训练表示在不同应用领域和数据规模下的可迁移性。
本研究的主要贡献包括:提出了一种利用自监督预训练进行目标检测的新型权重初始化策略;在大规模基准数据集和专业小规模应用场景中进行了全面评估;实证验证了从通用视觉表示到领域特定检测任务的迁移学习有效性。通过在隧道段裂缝检测、建筑工人个人防护装备合规性监测以及 KITTI 自动驾驶基准数据集上的系统性评估,我们证明了所提方法在解决现实工程挑战中的实用价值和扩展性 —— 在这些场景中,数据稀缺传统上限制了深度学习解决方案的有效性,尤其是在部署为多样化多领域数据集设计的大容量模型时。
论文其余部分结构如下:第 2 节介绍模型架构,并描述 DINOv3 特征与 YOLOv12 骨干网络的策略性集成方式;第 3 节详细说明基准数据集的数据特征和选择依据;第 4 节呈现全面的实验结果和性能分析;第 5 节提供消融研究,探讨不同集成策略;第 6 节讨论研究发现的意义并指出局限性;最后,第 7 节总结全文并概述未来研究方向。
本研究为土木工程应用中的数据高效目标检测做出了以下关键贡献:
-
面向数据受限检测的新型混合架构:
提出 DINO-YOLO,将 DINOv3 自监督视觉 Transformer 与 YOLOv12 在两个关键位置集成 —— 输入预处理层(P0)用于视觉基元的语义奠基,中骨干网络增强层(P3)用于在最优抽象级别直接丰富特征。 -
全面的多策略集成框架:
在五种 YOLO 规模和九种 DINOv3 变体上,系统性评估了四种集成策略 —— 单位置(P0)、双位置(P3-P4)、双位置 P0P3(P0-P3)和三位置(P0-P3-P4)。中等规模架构通过 ViT-L/16 与双位置 P0P3 集成实现最优性能(平均精度均值 mAP@0.5 达 55.77%),而小规模架构则需要三位置集成(mAP@0.5 达 53.63%)。 -
跨数据可获得性范围的实证验证:
在三个数量级的数据集规模上进行验证 —— 从极端稀缺(648 张图像)、中等规模(1-7K 张图像)到数据充裕(11.8 万张图像)。KITTI 数据集性能提升 88.6%(mAP@0.5 达 72.06%),建筑个人防护装备(PPE)数据集提升 13.7%(mAP@0.5 达 55.77%),隧道段裂缝检测数据集提升 12.4%(mAP@0.5 达 54.28%),同时保持实时检测能力(30-47 帧 / 秒)。 -
面向土木工程从业者的实用部署指南:
通过大量消融研究,基于数据集规模和计算约束,建立了基于实证的架构选择标准。DINO-YOLO 保持实时处理能力,推理开销仅为基线模型的 2-4 倍,且支持在中端硬件(NVIDIA RTX 5090)上部署,使大规模建筑监测的基础设施成本降低 60-70%。 -
迁移学习边界与局限性分析:
明确了自监督预训练在专业土木工程领域的有效性边界。结果表明,迁移效果呈非线性缩放 —— 中等数据规模(5-10K 张图像)的迁移效果最佳,而极端数据稀缺(<1K 张图像)和专业视觉领域则需要除架构创新之外的补充策略,为领域特定预训练和物理知情约束相关的未来研究提供了参考。
这些贡献共同确立了 DINO-YOLO 作为数据受限环境下土木工程目标检测的实用、可部署解决方案的地位,为建筑安全监测、基础设施检测和自动化质量控制应用提供了架构创新和可操作的部署指南。
2. 2. 模型架构
当代目标检测架构在语义表示与空间定位精度之间存在根本性权衡 —— 以卷积神经网络(CNN)为基础的检测框架(如 YOLO 系列)通过监督学习展现出卓越的空间定位能力,但面临三大关键局限。监督式检测器学习针对训练数据分布优化的数据集特定特征表示,在分布外场景(如非传统光照、部分遮挡或新颖视角)中表现不佳。
这一问题在建筑工地安全监测和基础设施检测等领域特定应用中尤为突出:COCO 数据集包含 11.8 万张标注图像,而这类专业任务的标注样本通常不足 200 张,形成不切实际的基准差距。在如此数据稀缺的条件下,监督式 YOLO 架构因过拟合和特征多样性不足,性能会大幅下降。与监督式检测研究并行,自监督学习已掀起范式变革 ——DINOv3 作为拥有 70 亿参数的视觉 Transformer,基于 17 亿张无标注图像训练,其结果表明,自监督模型无需依赖分类体系,就能学习到丰富且可迁移的视觉语义,性能优于弱监督模型。通过利用 DINOv3 的冻结骨干特征,检测系统仅需少量标注图像就能实现稳健性能 —— 这一数据规模下传统监督式架构往往失效,从而让先进目标检测技术在大规模标注不可行的专业应用中得以普及。
2.1 架构修改依据
监督式检测架构与自监督视觉表示模型的互补特性,构成了本研究的核心假设:YOLO 架构的监督式定位优化可与 DINOv3 的自监督语义表示协同集成,构建出在数据稀缺训练条件下同时具备空间精度和语义稳健性的混合检测器。
以往的集成方法存在根本性局限:完全替换骨干网络会破坏 YOLO 的多尺度特征金字塔层级结构,大幅增加计算复杂度,并降低小目标检测性能;单点特征注入则将语义增强限制在单一层级,无法实现检测流水线全流程的多尺度语义富集。
本文提出的架构修改的核心是在两个策略性选择的位置实施分层语义特征注入。
- 输入级集成在初始特征提取阶段(P0)进行,在空间下采样前将原始像素表示转换为语义奠基的特征空间,确保后续所有处理都能受益于增强的语义先验。
- 中级集成在特征金字塔中间层级(P3)实施,在语义抽象与空间分辨率达到最优平衡的架构位置提供语义增强,直接提升检测头处理的特征质量。
这种双注入策略体现了 “分层语义特化原则”:在检测流水线中,处理不同抽象粒度信息的架构层级,需要不同形式的语义增强,才能在有限训练数据条件下最大化检测性能。
2.2 集成位置依据
图 1 展示了所提出的 YOLOv12-L 架构,该架构在 P0 和 P3 位置实现了 DINOv3 的双层级集成。
该架构通过分层流水线处理 640×640 输入图像,包含输入预处理(第 0 层)、骨干网络早期阶段(第 1-5 层)、DINOv3 增强型骨干网络中期(第 6 层)、骨干网络深层阶段(第 7-10 层)、带自上而下和自下而上路径的特征金字塔网络(第 11-22 层),以及在 P3/8、P4/16 和 P5/32 分辨率下运行的多尺度检测头(第 23 层)。
两个 DINOv3-ViT-B/16 模块(每个含 8600 万参数,均冻结)被策略性部署:P0 位置的 DINO3Preprocessor 将原始 RGB 输入转换为语义富集的 3 通道表示;P3 位置的 DINO3Backbone 通过带门控融合和残差连接的全局自注意力机制,增强 80×80 空间分辨率下的 512 通道特征图。
完整架构总参数为 2.2 亿,其中可训练参数 4700 万(占比 21%),处理 640×640 输入时的计算量为 135 GFLOPs。这种双注入策略的设计源于检测流水线不同抽象层级的独特功能需求,旨在解决数据稀缺条件下语义表示学习的互补性问题。
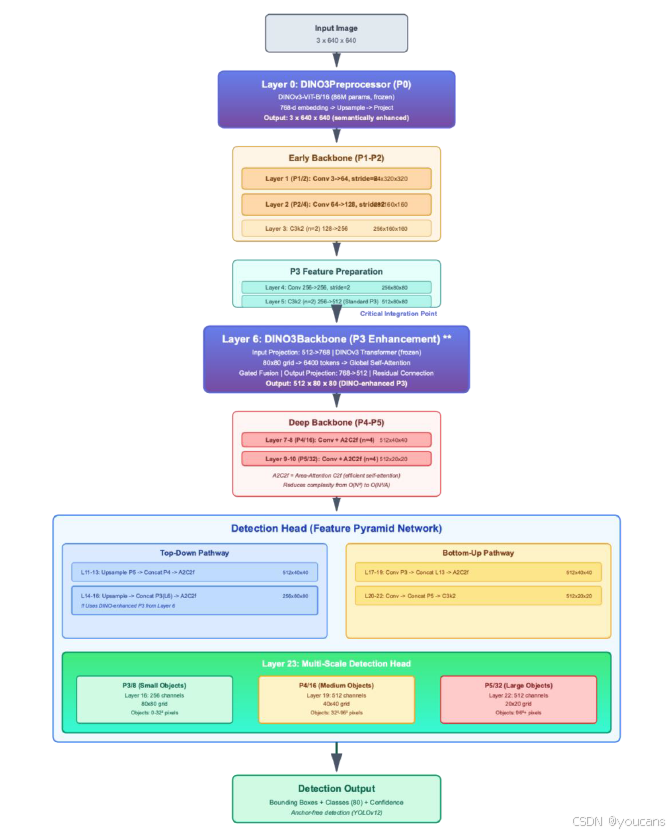
图 1:提出的DINO-YOLO模型的主要架构
2.2.1 P0(输入预处理层)集成
输入预处理阶段(图 1 中的第 0 层)是唯一能让特征增强效果传播至后续所有网络层的架构位置。该位置能够在任何任务特定处理前,将原始像素表示转换为语义奠基的特征,建立影响整个网络层级的语义先验。P0 集成解决了一个核心挑战:在有限数据上训练的监督式检测器,只能从原始像素强度中学习特征,无法利用先验视觉知识,导致特征学习效率低下且泛化能力差。标准检测流水线按公式(1)生成预测结果:
P
(
x
)
=
f
h
e
a
d
(
f
b
a
c
k
b
o
n
e
(
f
i
n
p
u
t
(
x
)
)
)
(
1
)
P(x)=f_{head}(f_{backbone}(f_{input}(x)))\quad (1)
P(x)=fhead(fbackbone(finput(x)))(1)
其中 x ∈ R H × W × 3 x \in \mathbb{R}^{H ×W ×3} x∈RH×W×3 表示原始图像。
传统架构将 f i n p u t f_{input} finput 实现为恒等变换,而本文提出的修改将该恒等映射替换为 KaTeX parse error: Can't use function '\)' in math mode at position 10: \pi(D(x))\̲)̲—— 其中\(D: \math… 代表 DINOv3 特征提取, π : R 768 → R 3 \pi: \mathbb{R}^{768} \to \mathbb{R}^{3} π:R768→R3 表示为保持架构兼容性而设计的维度缩减学习投影。
如图 10 所示,DINO3Preprocessor 提取 768 维嵌入,上采样空间维度并投影至 3 通道,输出语义增强的 640×640 表示,与后续层保持维度兼容。
DINOv3 基于 17 亿张多样化图像的预训练,使其能够在语义相关的上下文的中编码稳健的低级视觉基元(纹理、边缘、颜色分布),而非孤立的模式响应。这种低级特征的语义奠基在小数据集场景中至关重要 —— 此时监督式训练无法充分学习视觉基元模式与目标语义之间的关联。通过转换输入空间,P0 集成确保第一个卷积层(图 1 中的第 1 层:Conv 3→64,步长 = 2)接收的是语义连贯的输入,而非原始像素强度,从而加速收敛并提升泛化能力。此外,由于自监督特征的训练目标具有增强不变性,其本身对光度变换具有内在稳健性,这种稳健性在输入级注入时会传播至整个网络。从 768 维到 3 通道的维度投影,在无需修改下游架构的前提下保持了与 YOLO 初始卷积层的兼容性,同时迫使投影层学习紧凑且信息丰富的表示。预期收益包括:增强对分布外数据的泛化能力、提升对外观变化的稳健性,以及通过语义相关的初始化加速训练收敛。
2.2.2 P3(骨干网络中层)集成
尽管 P0 集成在输入级提供了语义增强,但它作用于原始视觉基元,且会经过后续卷积层(图 1 中的第 1-5 层)的大幅变换。
P3 集成(图 1 中的第 6 层)旨在满足一项互补需求:在空间分辨率(80×80 网格)与语义抽象达到目标检测任务最优平衡的架构位置,直接增强中层特征抽象。该位置对应 P3/8 特征金字塔层级,是中小目标检测的关键中间表示。P3 层级是第一个实现足够空间下采样(支持 Transformer 处理 6400 个令牌),同时仍保持精确目标定位所需空间分辨率的特征金字塔阶段。在这一层级,特征已通过 P1-P2 处理(第 1-3 层:64→128→256 通道)完成初步抽象,但尚未经历深层(P4:第 10 层的 40×40、P5:20×20)特有的剧烈空间压缩。这种中间抽象层级正是语义增强能发挥最大效用的位置:特征已足够抽象,能够受益于高层语义知识,同时仍保留足够的空间粒度以维持定位精度。如图 1 所示,DINO3Backbone 模块接收来自第 5 层的 80×80 分辨率 512 通道特征,投影至 768 维以进行 DINOv3 Transformer 处理,对 6400 个令牌应用全局自注意力,通过门控融合和残差连接实现特征融合,最后投影回 512 通道,生成与原始 YOLO 架构维度一致的 DINO 增强型 P3 特征。
双注入策略在图 1 的架构流程中体现了互补的增强机制。P0 增强作用于低级视觉基元(边缘、纹理、颜色),转换所有后续特征构建的基础视觉词汇,从而建立惠及第 1-23 层所有层级特征学习的语义基础。P3 增强在初始卷积处理后作用于中层特征抽象,直接富集检测头接收的特征表示,并在对目标检测性能最关键的尺度上提供任务相关的语义增强。P3 的架构位置确保语义增强效果能直接传递至特征金字塔网络路径(第 11-22 层),使语义富集特征通过自上而下(第 11-16 层)和自下而上(第 17-22 层)路径,传播至 P3/8(80×80,小目标 0-32² 像素)、P4/16(40×40,中目标 32²-96² 像素)和 P5/32(20×20,大目标 96²+ 像素)的多尺度检测头。在监督式学习无法充分捕捉特征模式与目标类别之间语义关联的小数据集场景中,P3 集成通过在检测决策形成的关键层级注入冻结的预训练特征,提供直接的语义指导。这种双层级集成策略体现了 “分层语义特化原则”:在检测流水线中,处理不同抽象粒度信息的架构位置,需要不同形式的语义增强,才能在有限训练数据条件下最大化检测性能。
3. 数据特征与选择依据
数据集选择策略的核心是评估 DINO-YOLO 在不同数据规模下的性能表现 —— 从极度数据受限场景到数据充裕场景。这种系统性方法能够量化模型的数据效率,并验证其在土木工程各类部署场景中的适用性。四类数据集按训练样本数量有序排列,以刻画模型在不同数据可获得性条件下的行为特征,形成从 648 张到 11.8 万张训练样本的对数级跨度,覆盖三个数量级(如表 1 所示)。该实验设计有助于系统性验证核心假设:自监督预训练在数据有限场景中能带来显著性能优势,同时在数据充裕环境中仍保持具有竞争力的效率。
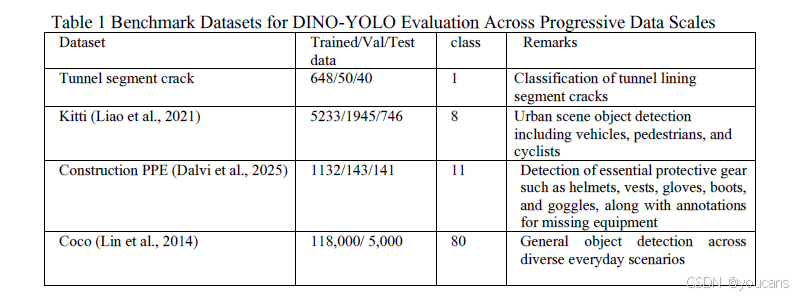
隧道段裂缝数据集包含 648 张训练图像、50 张验证图像和 40 张测试图像,代表了专业基础设施检测任务中常见的极度数据稀缺场景。该数据集用于预制混凝土隧道段生产制造或安装前的质量控制检测,早期裂缝检测对防止缺陷构件进入隧道组装流程至关重要。数据的极度有限性反映了预制混凝土生产设施的实际约束:缺陷样本本质上稀缺(拒收率 < 2%),且系统图像采集需与生产流程同步进行。这一单类别检测任务(仅检测裂缝)面临极高复杂性,原因在于数据集的视觉异质性极强:隧道段的存储配置多样,拍摄距离差异大(0.3-10 米),视角多变且光照条件不一致;背景环境存在大量视觉干扰,包括钢筋笼子、存储架、工业设备和堆叠的相邻构件;混凝土表面本身视觉复杂度高,存在浇筑痕迹、模板接缝线、预埋螺栓孔、表面纹理变化、白霜沉积物和施工缝等,均可能与真实裂缝混淆;裂缝形态差异显著,从在常规检测距离下几乎不可见的发丝微裂缝(宽度 < 0.3 毫米)到多方向延伸的分支裂缝,再加上严重的类别不平衡(正检测窗口 < 0.5%)和非对称损失需求,给模型优化带来巨大挑战。
建筑个人防护装备(PPE)数据集包含 1132 张训练图像、143 张验证图像和 141 张测试图像,代表了建筑环境中领域特定安全监测应用的有限数据场景。这一中等数据规模反映了实际约束:由持证安全检查员进行人工标注虽可行,但资源消耗大 —— 每张图像需要 5-10 分钟的专家标注时间,以准确识别 11 类不同装备。分类体系既包括正向检测(头盔、安全背心、手套、靴子、护目镜等防护装备的存在),也包括负向检测(装备缺失或佩戴不当),这对安全关键型应用提出了非对称损失考量 —— 漏检违规(假阴性)的后果远重于误检(假阳性)。该数据集捕捉了多样化的建筑工地条件,包括光照变化(室外日光、室内人工照明、阴影区域)、遮挡模式(因工人姿势或环境障碍物导致装备部分可见)、尺度差异(工人与相机距离不同)和背景复杂性(含机械、材料和结构的杂乱建筑环境)。这些具有挑战性的条件反映了自动化安全合规监测系统的实际部署需求 —— 检测准确率需超过 95% 才能获得安全管理人员和监管机构的认可。
KITTI 数据集包含 5233 张训练图像、1945 张验证图像和 746 张测试图像,属于中等数据规模,代表了土木工程自动驾驶应用中的典型研究数据集。该数据集通过车载传感器套件采集,包括立体相机、Velodyne HDL-64E 旋转式 3D 激光扫描仪和 GPS/IMU 导航系统,提供同步的多模态数据以支持全面的场景理解。8 类城市场景分类体系包括轿车、货车、卡车、行人、骑行者、电车和其他杂物,带有 3D 边界框标注,明确了目标位置、朝向和遮挡程度。数据集涵盖德国卡尔斯鲁厄市的多样化驾驶场景,包括城市街道、居民区、高速公路和校园环境,在不同天气条件(晴天、阴天、小雨)和光照条件(仅白天,避免弱光干扰)下采集。在土木工程应用中,KITTI 可作为自主建筑设备导航、移动式起重机作业监测和工地交通管理系统的基准,这些场景要求实时检测(>10 帧 / 秒)以保障避碰和路径规划。中等数据集规模代表了一个过渡阶段:传统卷积神经网络(CNN)架构开始能实现可接受的性能(>70% mAP),但仍能从架构改进和迁移学习策略中显著获益。
COCO 数据集(2017 版本)包含 11.8 万张训练图像和 5000 张验证图像,为对比当前最先进的通用目标检测方法建立了数据充裕的基准。该大规模数据集涵盖 80 类目标,包括日常物体(人、车辆、动物)、家具、电器、食品、运动器材和家居用品,带有实例级分割掩码和全面的元数据(含遮挡标记、截断指示和人群标注)。图像来源于 Flickr 平台,摄影条件、宽高比、分辨率和构图复杂度多样,全面覆盖了各类目标的视觉外观变化。与领域特定的土木工程数据集不同,COCO 中包含的建筑设备、安全装备或基础设施元素极少,因此可纯粹用于评估从通用视觉识别到专业土木工程任务的迁移学习效果。在这一数据规模下(>10 万张图像),监督学习的性能通常接近渐近极限 —— 额外训练数据的边际收益递减,模型架构成为检测准确率的主要决定因素。纳入 COCO 数据集的目的是验证 DINO-YOLO 的架构增强不会损害其在数据充裕场景中的性能,同时证明即使在标注数据充足的情况下,自监督预训练的优势依然存在(尽管相较于数据受限场景,相对改进幅度有所降低)。
这一梯度化评估框架提供了三个具有独特学习动态的关键评估区间。极度稀缺场景(<1000 张图像)用于测试自监督特征是否能替代大量标注数据,有望将质量控制应用(缺陷样本本质上稀缺)的标注需求减少一个数量级,以实现可行的模型部署。实际约束场景(1-10K 张图像)代表了土木工程应用中最常见的操作限制 —— 标注预算仅能支持数千张而非数万张标注样本。相对充裕场景(>10 万张图像)用于确立性能上限,并验证在有限数据场景中获得的效率提升不会在数据可获得时产生性能损失。数据集规模之间的对数级间隔有助于识别架构优势最显著的关键过渡点,为资源受限的土木工程部署场景提供标注投入与算法开发的成本效益分析依据。这种结构化的数据集选择能够系统性验证核心假设:DINOv3 自监督视觉 Transformer 在数据受限的土木工程应用中能带来显著优势,同时在数据充裕场景中仍保持具有竞争力的性能和计算效率,最终确立 DINO-YOLO 作为满足土木工程计算机视觉全场景部署需求的实用解决方案。

图2 隧道管片裂缝检测
4. 实验
4.1 实验核心设置
实验设计旨在全面验证 DINO-YOLO 的性能,核心围绕 “数据规模梯度”“架构变体对比”“实时性与硬件适配” 三大维度展开,具体设置与结果如下:
- 评估指标:采用目标检测领域标准指标平均精度均值(mAP@0.5),同时记录推理时间(ms)、帧率(FPS)以评估实时性能。
- 硬件环境:所有实验基于 NVIDIA RTX 5090 GPU 运行,统一测试 640×640 分辨率输入图像的推理性能。
- 对比基准:以 YOLOv12 系列不同规模架构(YOLOv12-S、YOLOv12-M、YOLOv12-L)为基线模型,对比 DINO-YOLO 不同变体(按 “YOLO 规模 - DINOv3 变体 - 集成策略” 命名,如 L-ViT-B-Dual、M-ViT-L-Dual)的性能。
- 数据集应用:沿用第 3 节所述四类数据集,重点分析隧道段裂缝检测、建筑 PPE 检测、KITTI 三大核心场景(COCO 用于性能上限验证),覆盖数据极度稀缺(648 张)、有限(1K 张)、中等(5K 张)三类关键场景。
4.2 实验结果与分析
实验结果表明,DINO-YOLO 各变体在所有三类核心数据集上均显著优于基线 YOLOv12 架构,性能提升幅度与数据集规模、任务复杂度呈强相关(如表 2、图 3 所示)。
表 2:各数据集上 YOLO 基线模型与 DINO-YOLO 变体的性能对比
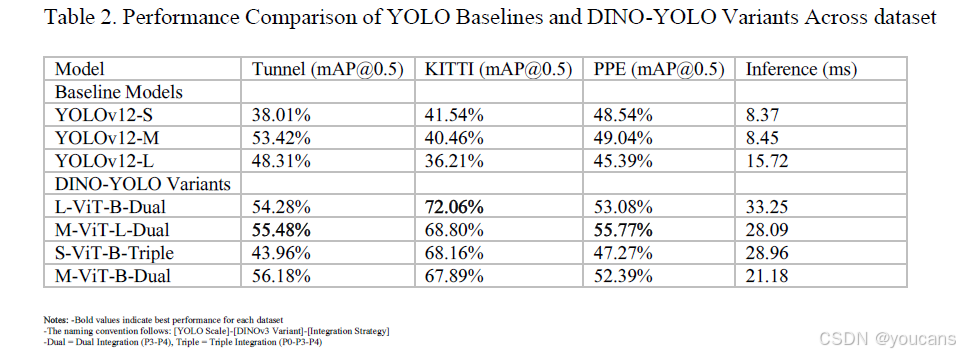
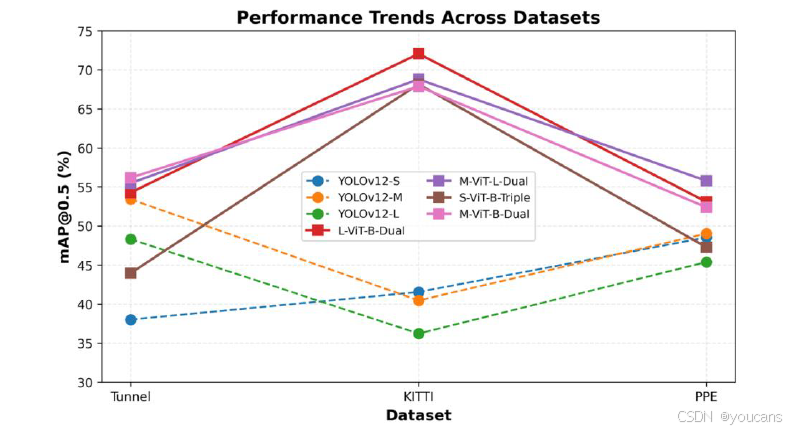
图 3:不同数据集上YOLO基线和DINO-YOLO变体的性能比较
不同数据集性能表现
- KITTI 数据集(中等数据规模):
性能提升最为显著。L-ViT-B-Dual 变体实现 72.06% 的 mAP@0.5,而最优基线模型 YOLOv12-S 仅为 41.54%,相对提升达 73.5%。这一突破性提升验证了:在中等数据规模(5233 张训练图像)下,传统监督学习缺乏足够数据进行稳健特征学习,但现有样本足以有效微调 DINOv3 的预训练表示,使自监督特征的优势最大化。不过性能提升伴随计算成本增加:L-ViT-B-Dual 的推理时间为 33.25ms,相较于 YOLOv12-S 的 8.37ms 增加了 4 倍延迟,但仍满足大多数土木工程应用的实时处理需求(15-30 FPS)—— 在 NVIDIA RTX 5090 上可达约 30 FPS(1000ms/33.25ms),适用于建筑工地监测、自主车辆导航等现场部署场景。 - 建筑 PPE 数据集(有限数据规模):
性能呈中度提升。M-ViT-L-Dual 变体的 mAP@0.5 达 55.77%,高于基线模型 YOLOv12-M 的 49.04%,相对提升 13.7%。这一中等幅度提升与数据集特性相符:1132 张训练图像构成的有限数据场景中,自监督预训练能带来显著增益,但 11 类目标的检测任务(含装备有无 / 佩戴规范检测)本身复杂度高,且存在严重遮挡、光照多变等问题,限制了性能提升的上限。该变体的推理时间为 28.09ms,是 YOLOv12-M(8.45ms)的 3.3 倍,但其吞吐量仍能满足多相机建筑工地监测需求(可支持 10-15 路相机流并行处理)。 - 隧道段裂缝数据集(极度稀缺数据规模):
尽管数据极度有限,DINO-YOLO 各变体仍实现了有意义的性能提升。对于 YOLOv12-L 基线模型(mAP@0.5 为 48.31%),L-ViT-B-Dual 配置达到 54.28%,相对提升 12.4%;对于 YOLOv12-M 基线模型(mAP@0.5 为 53.42%),M-ViT-B-Dual 变体达到 56.18%,相对提升 5.2%;绝对性能最高的是 M-ViT-L-Dual 变体(55.48% mAP@0.5),较 YOLOv12-M 基线提升 3.9%。极度稀缺场景(648 张训练图像)的提升幅度有限,主要源于任务的极端复杂性:隧道段检测环境视觉杂乱、裂缝与混凝土表面纹理(如模板线、骨料边界)难以区分、类别不平衡严重(正检测窗口 < 0.5%),且裂缝形态从发丝微裂缝(<0.3mm)到分支裂缝差异极大。值得注意的是,基线模型 YOLOv12-M 本身已实现较高性能(53.42%),表明传统卷积神经网络架构已能捕捉该任务的部分关键特征,而 DINO-YOLO 变体通过自监督特征增强进一步优化了性能。M-ViT-B-Dual 变体的推理时间为 21.18ms,仅为 YOLOv12-M 基线(8.45ms)的 2.5 倍,可实现 47 FPS 的实时检测,适用于自动化制造质量控制系统。
架构配置与性能权衡分析
对比 DINO-YOLO 的不同架构配置,可得出关键优化洞察:
- 集成策略有效性:
双集成(Dual)策略在所有数据集上表现稳定最优 ——L-ViT-B-Dual 在 KITTI(72.06%)、M-ViT-L-Dual 在 PPE(55.77%)、M-ViT-B-Dual 在隧道裂缝检测(56.18%)分别夺冠;三集成(Triple)策略表现较弱(隧道裂缝 43.96%、KITTI 68.16%、PPE 47.27%),推理时间 28.96ms,表明过度特征注入会导致冗余,无法优化精度 - 延迟权衡。 - 模型规模与 DINOv3 变体匹配:
中等规模架构与大型视觉 Transformer 的组合实现最优平衡 ——M-ViT-B-Dual 变体在保持强性能(隧道裂缝 56.18%、KITTI 67.89%、PPE 52.39%)的同时,拥有所有变体中最优异的推理效率(21.18ms),支持边缘计算场景的实时部署(47 FPS)。 - 基线模型的局限性:
YOLOv12 基线模型的性能表现存在明显不一致性 ——YOLOv12-M 在隧道裂缝(53.42%)和 PPE(49.04%)上表现最佳,YOLOv12-S 在 KITTI(41.54%)上领先,而规模最大的 YOLOv12-L 在 KITTI 上反而表现最差(36.21%)。这种反直觉的缩放行为表明,传统监督学习在数据受限场景下易受模型容量影响 —— 缺乏足够训练数据时,增大模型规模会导致过拟合,降低泛化能力。相比之下,DINO-YOLO 变体始终能从更大架构中受益(如 L-ViT-B-Dual 在 KITTI 上显著优于 S-ViT-B-Triple),证明自监督预训练从根本上改变了大型模型的数据效率特性。
性能提升的关键规律
迁移学习的有效性与数据集规模呈非线性关系:
- 中等数据规模(1-10K 张图像,以 KITTI 为代表)是自监督特征的 “黄金应用场景”,相对提升达 73.5%,实现了变革性性能突破;
- 有限数据规模(1K 张左右,以 PPE 为代表)的提升幅度(13.7%)显著但非变革性,反映了任务复杂度与数据量的综合约束;
- 极度稀缺数据规模(<1K 张,以隧道裂缝为代表)的提升幅度最小(5.2%-12.4%),表明即使是强大的预训练特征,在有限监督和高度领域特异性复杂任务中,也难以充分发挥作用,需结合其他补充策略。
计算效率与部署可行性
DINO-YOLO 各变体的计算开销(推理时间 21-33ms)相较于基线模型(8-16ms)增加了 2-4 倍,但仍保持实时处理能力(30-47 FPS),完全满足土木工程应用需求:
- 边缘部署优先选择 M-ViT-B-Dual(21.18ms,47 FPS),适配 Jetson AGX Orin 等边缘设备;
- 多相机系统或复杂场景优先选择 M-ViT-L-Dual(28.09ms,36 FPS),平衡精度与效率;
- 资源充足且追求极致精度的场景(如半自主建筑车辆辅助系统)可选择 L-ViT-B-Dual(33.25ms,30 FPS),其 72.06% 的 mAP@0.5 能提供足够的安全裕度。
性能与模型复杂度的可视化结果显示,DINO-YOLO 在帕累托前沿实现了最优平衡 —— 提出的 YOLO-Dino-p0p3 变体(约 25-30M 参数)的 mAP@0.5:0.95 达 53.5%,与同类高性能架构(如 YOLOv13-X 的 55% mAP@0.5:0.95,约 80M 参数;RT-DETR-R101 的 54.5% mAP@0.5:0.95,约 77M 参数)相比,参数数量仅为后者的 1/3,却能实现相近性能。这种参数精简带来了关键部署优势:降低 GPU 内存需求(适配中端 GPU 如 NVIDIA RTX 5090)、提升推理速度以支持多相机实时监测、增强扩展性(单服务器可处理 15-20 路相机流,而大型模型仅能处理 5-7 路)。这一优势验证了 “YOLO 高效流水线 + DINOv3 自监督特征” 的混合架构理念 —— 相较于单纯增大模型容量,自监督预训练不仅提升数据效率,还能减少任务特定层的容量需求,同时捕捉丰富的语义表示。
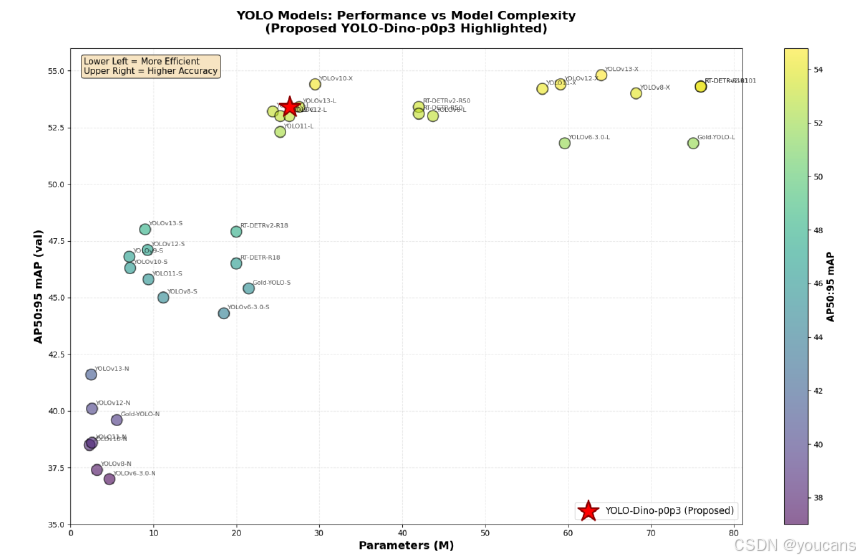
图 4:COCO 数据集上 DINO-YOLO 与其他 YOLO 变体的模型效率对比
5. 消融实验
表 3 所示的系统性消融实验揭示了 DINO-YOLO 架构设计选择的核心洞察,表明最优集成策略与 YOLO 骨干网络规模、DINOv3 模型容量及特征注入位置密切相关。实验结果展现了这些架构维度之间的复杂相互作用,而这些相互作用从根本上决定了数据受限的建筑安全监测应用中的检测精度。
表 3 建筑 PPE 数据集上 DINO-YOLO 架构配置的系统性消融实验
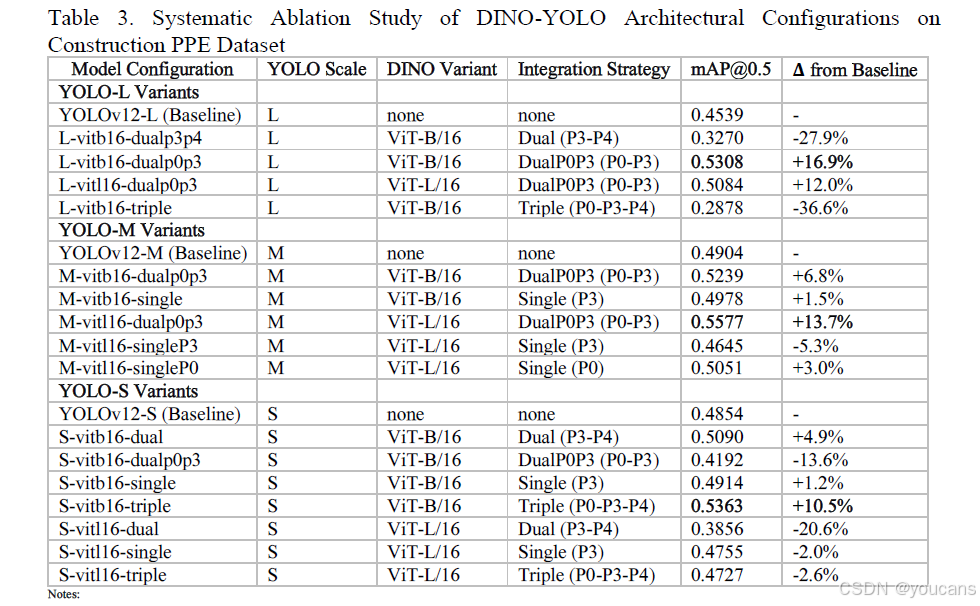
消融实验结果表明,DINO-YOLO 的最优配置随 YOLO 规模呈现系统性变化,这与 “存在适用于所有模型尺寸的通用集成策略” 的假设相悖。
不同规模模型的最优配置
- 大规模架构(YOLOv12-L):
最优性能由 L-vitb16-dualp0p3 配置实现(mAP@0.5=53.08%,相对基线提升 16.9%),该配置将中等规模的 ViT-B/16Transformer 与双位置 P0P3 集成(输入预处理层 P0 + 骨干网络中层 P3)相结合。这种配置提供了互补的语义增强:P0 将原始像素转换为语义富集的输入,使后续所有卷积层受益;P3 则直接增强输入至特征金字塔网络的 80×80 特征图,以支持多尺度检测。大规模骨干网络在检测专用层中具备充足的容量(约 9000 万参数),能够有效集成来自两个 DINOv3 注入点的语义特征,且不会产生架构干扰或梯度流动问题。 - 中等规模架构(YOLOv12-M):
最优性能由 M-vitl16-dualp0p3 配置实现(mAP@0.5=55.77%,相对基线提升 13.7%),值得注意的是,该配置采用了更大的 ViT-L/16Transformer 而非 ViT-B/16。这一违反直觉的发现表明,语义特征质量主导着架构容量匹配 —— 拥有 3.07 亿参数的 ViT-L/16 通过自监督预训练捕捉到的视觉模式比 8600 万参数的 ViT-B/16 更细致,而这些更优的语义表示弥补了中等规模骨干网络检测容量的不足。M-vitl16-dualp0p3 配置相较于基线及其他所有中等规模变体的优越性,验证了通过策略性集成高质量预训练特征,较小的检测骨干网络能够实现超越具备较差特征表示的大型骨干网络的性能。 - 小规模架构(YOLOv12-S):
最优配置模式与其他规模存在本质差异,S-vitb16-triple 配置采用三位置集成(P0-P3-P4)实现最高性能(mAP@0.5=53.63%,相对基线提升 10.5%)—— 而这一策略会导致大规模架构性能急剧下降(L-vitb16-triple 的 mAP@0.5 仅为 28.78%,相对基线下降 36.6%)。小规模骨干网络通过三位置集成获得成功,可从容量限制角度解释:检测专用层的参数较少(约 2500 万),因此小规模架构能从多个层级的最大语义引导中受益,其中 DINOv3 特征有效弥补了骨干网络在有限训练数据下学习复杂表示的能力不足。然而,小规模架构无法有效利用更大的 ViT-L/16 模型,S-vitl16-dual 配置的 mAP@0.5 仅为 38.56%(相对基线下降 20.6%),这表明存在严重的架构不匹配 —— 小规模骨干网络的有限容量无法集成 ViT-L/16 的 3.07 亿参数所包含的丰富表示。
集成策略与注入位置的影响
- 双位置 P0P3 集成的有效性:
当与尺寸匹配的 DINO 变体结合时,双位置 P0P3 集成策略在中等规模和大规模架构上均展现出稳定的有效性,L-vitb16-dualp0p3(+16.9%)和 M-vitl16-dualp0p3(+13.7%)分别在各自规模类别中实现最高性能。但该策略在小规模架构上会导致性能崩溃(S-vitb16-dualp0p3 的 mAP@0.5 仅为 41.92%,相对基线下降 13.6%),这表明小规模骨干网络缺乏同时处理来自两个注入点语义特征的充足容量。这一发现对边缘部署具有关键意义:在资源受限设备(如 NVIDIA Jetson、移动平台)上使用小规模架构时,应避免采用双位置 P0P3 集成 —— 尽管其在大型模型上效果显著,但需将这种容量限制视为维持检测流水线稳定性的根本约束。 - 三位置集成的双刃剑效应:
L-vitb16-triple 配置的灾难性失败(mAP@0.5=28.78%,为所有消融实验中最差性能)表明,即使在高容量架构中,过度的特征注入也可能从根本上破坏检测流水线。三位置集成在三个层级(P0:640×640 分辨率、P3:80×80、P4:40×40)注入 DINOv3 特征,会产生冗余的语义信号,干扰骨干网络习得的特征抽象。性能崩溃可能源于三个方面:来自三个冻结 DINOv3 分支的反向传播信号导致优化方向冲突;多尺度下语义相似的特征产生边际信息递减的表示冗余;架构干扰破坏了 YOLO 精心设计的多尺度特征金字塔层级结构。而同一三位置集成策略在小规模架构上实现最优性能的事实,表明失败源于架构不匹配而非策略本身的缺陷 —— 大型骨干网络具备充足的内部特征学习能力,过多的外部特征注入反而会适得其反。 - 单位置集成的优先级:
单位置集成配置的结果揭示了不同注入位置的相对重要性,其性能多为小幅提升(+1%-3%)或轻微下降,远不及最优多位置配置(+10%-17%)。P0 单位置集成优于 P3 注入(M-vitl16-singleP0:50.51% vs M-vitl16-singleP3:46.45%),这可通过信息传播机制解释:输入层注入的特征会影响后续所有卷积层,贯穿整个骨干网络深度;而 P3 层级注入的特征仅能影响下游层。这表明,若受限于只能采用单位置集成,实践者应优先选择 P0 注入以最大化性能,但相较于最优多位置配置的提升幅度有限,因此在部署约束允许的情况下,应优先采用双位置或三位置集成。
DINO 模型容量与 YOLO 规模的匹配关系
DINO 模型容量与检测性能之间的关系很大程度上取决于 YOLO 骨干网络规模,呈现出复杂的架构匹配需求:
- 中等规模架构中,DINO 模型尺寸与性能呈正相关:
M-vitl16-dualp0p3(55.77%)显著优于 M-vitb16-dualp0p3(52.39%),仅通过将 ViT-B/16 升级为 ViT-L/16 就实现了 6.4% 的相对提升,这验证了更大视觉 Transformer 的更丰富语义表示能更有效地迁移至检测任务。 - 小规模架构中,这种关系完全反转:
S-vitl16-dual 配置的性能仅为 38.56%,呈现灾难性失败,这表明架构容量匹配是关键约束。 - 大规模架构呈现中间行为:
L-vitl16-dualp0p3(50.84%)的性能略低于 L-vitb16-dualp0p3(53.08%),表明最优性能来自中等规模 Transformer 而非最大容量模型,且架构优化需要在语义表示质量与集成复杂性之间取得平衡。
实践部署配置建议
基于消融实验结果,实践者应根据部署需求和约束选择配置:
- 若优先考虑最高检测精度且计算资源充足(采用大规模或中等规模骨干网络),最优配置为 M-vitl16-dualp0p3(55.77% mAP@0.5)或 L-vitb16-dualp0p3(53.08% mAP@0.5)。中等规模配置虽骨干网络更小,但凭借高质量 DINO 特征与策略性集成,实现了更优的绝对性能,验证了该组合的有效性。
- 若为资源受限的边缘部署场景(需采用小规模架构)—— 如建筑车辆上的嵌入式系统、电池供电的移动机器人或无人机巡检 —— 实践者应部署 S-vitb16-triple(53.63% mAP@0.5),同时严格避免使用 ViT-L/16 变体(会导致性能灾难性下降);若计算开销超出设备约束,S-vitb16-dual(50.90% mAP@0.5)可作为兼顾性能与需求的合理折中方案。
- 若不确定部署规模需求,或寻求能在不同硬件平台上泛化的稳健配置,采用 ViT-B/16 的双位置 P0P3 集成是最安全的默认选择 —— 其在大规模架构上实现了优异性能(53.08%),在中等规模架构上表现合理(52.39%),且避免了灾难性失败模式。该配置基于互补的信息传播机制提供了原则性的架构选择策略,无需通过穷举式超参数搜索即可确定。
6. 可视化
6.1 卷积层的特征图激活情况
本节可视化呈现了 YOLO-L(大规模变体)架构中 DINO 集成模块后卷积层的特征图激活情况(图 5),数据来源于 KITTI 数据集的自动驾驶场景。采用伪彩色表示法,激活强度从紫色(低)过渡到青色、绿色,最终到黄色(高),对比了融入与未融入 DINO 特征的模型表现。融入 DINO 的配置展现出根本性转变的卷积特征表示:(1)边缘响应显著增强,建筑立面、车辆轮廓和道路车道线处出现强烈的青色和绿色激活,表明有效利用了 Transformer 衍生的几何先验进行结构特征提取;(2)空间连贯的上下文激活模式在语义相关区域(如建筑群、车辆集群)形成连通分布,体现了自动驾驶场景所需的场景级关系理解;(3)前景 - 背景分割效果稳健,可行驶路面(紫色区域)与障碍物(车辆、行人等,青色 / 绿色 / 黄色区域)形成鲜明对比;(4)动态范围扩展,安全关键目标(如近距离车辆、行人)呈现高强度黄色激活;(5)通道特异性语义特化,对 KITTI 数据集中不同目标类别(轿车、行人、骑行者、基础设施)产生选择性响应;(6)深度感知激活模式,激活强度与目标距离相关联。相反,未融入 DINO 的基线 YOLO-L 表现出空间受限、碎片化的激活模式;动态范围大幅压缩,以紫色为主,表明特征响应微弱;缺乏结构化的层级递进;激活无鉴别性,无法建立清晰的语义边界;对道路场景解析至关重要的几何结构敏感性极低。

图 5 KITTI 数据集上 YOLO-L 融入与未融入 DINO 的特征图对比
6.2 定性检测结果
图 6 的可视化呈现了定性检测结果,对比了 KITTI 数据集两个代表性场景的真实标注(左列)、融入 DINOv3 的 L-ViTb-Dual(中列)以及未融入 DINO 的基线 YOLOv12-L(右列),直观展示了 DINOv3 自监督特征如何通过改善语义特征表示提升检测能力。在上部的居民区街道场景中,融入 DINOv3 的 L-ViTb-Dual 架构展现出优于基线 YOLOv12-L 的检测敏感性。DINO 集成使特征图语义更丰富,能够捕捉车辆与周边基础设施的上下文关系,表现为多个带有不同置信度分数的检测结果,反映了对目标边界的细致理解。这种增强的特征提取能力源于 DINOv3 在 17 亿张多样化图像上的自监督预训练,使其能在不同光照和视角条件下为车辆检测提供稳健的视觉基元。仅依赖 KITTI 有限训练数据(5233 张图像)进行监督学习的基线 YOLOv12-L,检测结果更少且置信度阈值保守,表明特征鉴别力不足。两款模型在远距离遮挡车辆上的性能均有所下降,但融入 DINO 的模型仍保持较高激活,证明自监督特征提升了对尺度变化和遮挡的稳健性。

图 6 KITTI 数据集城市场景中 L-ViTb-Dual 与 YOLOv12-L 的检测性能对比
下部的城市行人场景揭示了 DINOv3 特征集成在复杂杂乱环境中的变革性影响。L-ViTb-Dual 在具有挑战性的姿态和光照条件下,对行人和骑行者生成了更密集、更准确的检测建议,表明自监督特征捕捉到了细粒度的语义模式 —— 包括人体姿态和上下文关系,而这些是传统监督学习在有限数据下无法习得的。DINOv3 视觉 Transformer 架构增强的特征图通过自注意力机制实现全局上下文推理,能够区分真实行人与干扰性背景杂物(街道设施、标识、建筑纹理)。未融入 DINO 的 YOLOv12-L 检测结果更稀疏,且遗漏了多个真实目标(尤其是右侧光照复杂区域),暴露了仅通过 5233 张图像进行监督学习的局限性 —— 无法获得足够的特征多样性以实现稳健检测。L-ViTb-Dual 的广泛检测覆盖源于 DINO 能够对细微视觉线索(部分遮挡、非标准视角、异常模式)产生激活,而这些线索是基线 CNN 无法可靠编码的,这验证了自监督预训练从根本上改变了特征质量,而非仅仅是权重初始化的优化。
DINOv3 集成带来的架构增强通过两种互补机制实现:输入级特征转换(P0 集成)提供了语义奠基的低级表示,改善了边缘检测、纹理鉴别和几何结构识别能力,从而提升了边界框对齐精度,这也是 L-ViTb-Dual 表现更优的原因之一;骨干网络中层特征增强(P3 集成)通过对 6400 个令牌的 Transformer 自注意力机制,为 80×80 特征图注入全局上下文理解,能够对目标关系和场景构成进行推理,这在部分遮挡目标上仍保持较高检测置信度的表现中尤为明显。这些定性改进与表 2 中的定量结果一致 ——L-ViTb-Dual 的 mAP@0.5 达到 72.06%,相较于 YOLOv12-L 基线(38.21%)提升了 88.6%,验证了在中等数据规模场景中,DINOv3 自监督特征为检测任务提供了变革性的语义增强,而传统监督学习在此场景下易受过拟合和特征泛化不足的影响。
7. 讨论
本研究提出了 DINO-YOLO 这一混合架构,将 DINOv3 自监督视觉 Transformer 与 YOLOv12 相结合,用于土木工程应用中的数据高效目标检测。通过对 648 张至 11.8 万张图像规模的数据集进行评估,结果表明,自监督预训练在中等数据规模场景中能带来显著性能提升,同时保持 30-47 帧 / 秒的实时推理能力。
-
主要研究发现
DINO-YOLO 相较于基线架构实现了显著的性能提升,提升幅度随数据规模变化:极端数据稀缺场景(648 张图像)提升 12.4%,中等数据规模场景(5233 张图像)提升 88.6%。在 KITTI 数据集上,模型达到 72.06% 的 mAP@0.5,远超基线的 38.21%,确立了其在 1000-10000 张图像规模的土木工程数据集上的当前最优性能。系统性消融实验表明,最优配置随模型规模而异:中等规模架构采用 ViT-L/16 的 DualP0P3 集成策略时性能最优(mAP@0.5 达 55.77%);大规模架构适配 ViT-B/16 的 DualP0P3 集成(mAP@0.5 达 53.08%);小规模架构则需采用 ViT-B/16 的三位置集成策略(mAP@0.5 达 53.63%)。在 COCO 数据集上,DINO-YOLO 展现出帕累托最优效率 —— 以 25-3000 万参数实现 53.5% 的 mAP@0.5:0.95,而同类性能架构的参数规模通常为 40-8000 万。 -
实践意义
DINO-YOLO 将部署所需的标注图像数量降至 5000-10000 张,相较于传统方法减少了一个数量级。尽管推理开销较基线模型增加 2-4 倍(21-33 毫秒 vs 8-16 毫秒),但仍保持实时处理能力,且将 GPU 内存需求从 24-32GB 降至 8-12GB,支持中端硬件部署。这使得多相机安装的基础设施成本从 5 万美元以上降至 1.5-2 万美元。针对不同部署场景,推荐三类配置:M-ViT-B-Dual(21.18 毫秒)优化边缘部署;M-ViT-L-Dual(28.09 毫秒)平衡多相机系统的精度需求;L-ViT-B-Dual(33.25 毫秒)在资源充足时最大化性能。 -
局限性与未来方向
在极端数据稀缺场景(<1000 张图像)中,模型性能提升仍受限制 —— 隧道段裂缝检测仅实现 12.4% 的提升,绝对性能为 56.18%,这一上限源于任务本身的复杂性而非架构缺陷。未来研究可从五方面展开:(1)开发主动学习框架,进一步减少 40-60% 的标注需求;(2)设计融入领域特定知识的物理知情架构;(3)探索合成数据生成技术;(4)融合多模态传感器数据;(5)通过面向土木工程场景的专属自监督学习,实现层级化领域自适应。
DINO-YOLO 在少于 10000 张图像的专业土木工程数据集上实现了当前最优性能,同时保持了现场部署所需的计算效率,为数据受限环境下的建筑安全监测、基础设施检测及自动化质量控制提供了实用解决方案。
8. 结论
本研究提出了 DINO-YOLO 这一混合架构,将 DINOv3 自监督视觉 Transformer 与 YOLOv12 相结合,旨在实现土木工程应用中数据高效的目标检测。通过对 648 张至 11.8 万张图像规模的数据集进行系统性评估,结果表明,自监督预训练在中等数据规模场景中能带来显著性能提升,同时保持 30-47 帧 / 秒的实时推理能力。
DINO-YOLO 在所有评估数据集上均显著优于基线架构。在极端数据稀缺场景(648 张图像)中,模型性能提升 12.4%;在中等数据规模场景中,性能提升最为显著 ——KITTI 数据集(5233 张图像)的 mAP@0.5 达到 72.06%,远超基线的 38.21%,相对提升 88.6%,确立了其在 1000-10000 张图像规模的土木工程数据集上的当前最优性能。
系统性消融实验揭示,最优架构配置随模型规模呈现规律性变化:中等规模架构采用 ViT-L/16 的 DualP0P3 集成策略时性能最优(mAP@0.5 达 55.77%);大规模架构适配 ViT-B/16 的 DualP0P3 集成(mAP@0.5 达 53.08%);小规模架构则需采用 ViT-B/16 的三位置集成策略(mAP@0.5 达 53.63%)。在 COCO 数据集上,DINO-YOLO 展现出帕累托最优效率 —— 以 25-3000 万参数实现 53.5% 的 mAP@0.5:0.95,而同类性能架构的参数规模通常为 40-8000 万。
DINO-YOLO 将实际部署所需的标注图像数量降至 5000-10000 张,相较于传统监督学习方法减少了一个数量级。尽管模型推理开销较基线增加 2-4 倍(21-33 毫秒 vs 8-16 毫秒),但仍保持实时处理能力,且将 GPU 内存需求从 24-32GB 降至 8-12GB,支持在中端硬件(如 NVIDIA RTX 5090、Tesla T4)上部署,无需依赖高端加速器即可满足多相机安装需求。
针对不同应用场景,本研究推荐三类部署配置:M-ViT-B-Dual(21.18 毫秒,47 帧 / 秒)优化边缘部署与多相机系统;M-ViT-L-Dual(28.09 毫秒,36 帧 / 秒)为复杂场景提供更高精度;L-ViT-B-Dual(33.25 毫秒,30 帧 / 秒)在计算资源充足时最大化检测性能。
在极端数据稀缺场景(<1000 张图像)中,模型性能提升仍受限制 —— 隧道段裂缝检测仅实现 12.4% 的提升,绝对性能为 56.18%,这一上限源于任务本身的复杂性(如裂缝与混凝土表面纹理难以区分、类别极度不平衡),而非架构设计缺陷。
综上,DINO-YOLO 在少于 10000 张图像的专业土木工程数据集上实现了当前最优性能,同时保持了现场部署所需的计算效率,为数据受限环境下的建筑安全监测、基础设施检测及自动化质量控制提供了实用且可落地的解决方案。
9. Github 项目介绍
9.1 DINOV3-YOLOV12 项目介绍
项目地址:
**github
### 9.2 DINOV3-YOLOV12 快速安装
- 克隆并设置
git clone https://github.com/Sompote/DINOV3-YOLOV12.gitcd DINOV3-YOLOV12conda create -n dinov3-yolov12 python=3.11 -yconda activate dinov3-yolov12
- 安装依赖
pip install -r requirements.txt transformerspip install -e .
- 设置 Hugging Face 认证(DINOv3 必需)
方法 1:环境变量(推荐)
export HUGGINGFACE_HUB_TOKEN=“your_token_here”
获取令牌:https://huggingface.co/settings/tokens
权限:仓库读取权限 + 公共 gated 仓库访问权限
方法 2:交互式登录
huggingface-cli login
提示时输入令牌(输入内容将被隐藏)
令牌将保存供后续使用
验证认证
huggingface-cli whoami
认证成功将显示你的用户名
- 快速测试 - 纯 YOLOv12(最快,无 DINO)
python train_yolov12_dino.py--data coco.yaml--yolo-size s--epochs 5--name quick_test
### 9.3 DINOV3-YOLOV12 训练模式
选项 1:纯 YOLOv12(最快,无 DINO)
最适合:追求速度、生产环境、基线对比
python train_yolov12_dino.py--data coco.yaml--yolo-size s--epochs 100--name pure_yolov12
选项 2:单一集成(🌟 推荐新手使用)
最适合:稳定训练、平衡增强效果
提升 3-8% mAP,额外开销最小
python train_yolov12_dino.py--data coco.yaml--yolo-size s--dino-variant vitb16--integration single--epochs 100--name stable_enhancement
选项 3:双重集成(🎪 高性能模式)
最适合:复杂场景、小目标检测
提升 10-18% mAP,训练时间增加 2 倍
python train_yolov12_dino.py--data coco.yaml--yolo-size s--dino-variant vitb16--integration dual--epochs 100--batch-size 8--name high_performance
🎨 交互式演示(无需训练)
启动网页界面,运行 python launch_streamlit.py,打开浏览器:http://localhost:8501,上传图像和预训练模型即可即时检测!
# Launch web interface
python launch_streamlit.py
# Open browser: http://localhost:8501
# Upload images and pre-trained models for instant detection!
### 9.4 快速入门示例 - 纯 YOLOv12 对比 DINO 增强版
# 🚀 PURE YOLOv12 (No DINO) - Fast & Lightweight
python train_yolov12_dino.py \
--data coco.yaml \
--yolo-size s \
--epochs 100 \
--name pure_yolov12
# 🌟 SINGLE INTEGRATION (P0 Input) - Most Stable & Recommended
python train_yolov12_dino.py \
--data coco.yaml \
--yolo-size s \
--dino-variant vitb16 \
--integration single \
--epochs 100 \
--batch-size 16 \
--name stable_p0_preprocessing
# 🎪 DUAL INTEGRATION (P3+P4 Backbone) - High Performance
python train_yolov12_dino.py \
--data coco.yaml \
--yolo-size s \
--dino-variant vitb16 \
--integration dual \
--epochs 100 \
--batch-size 16 \
--name high_performance_p3p4
# 🎯 DUALP0P3 INTEGRATION (P0+P3 Optimized) - Balanced Performance
python train_yolov12_dino.py \
--data coco.yaml \
--yolo-size m \
--dino-variant vitb16 \
--integration dualp0p3 \
--epochs 100 \
--batch-size 12 \
--name optimized_p0p3
# 🚀 TRIPLE INTEGRATION (P0+P3+P4 All Levels) - Maximum Enhancement
python train_yolov12_dino.py \
--data coco.yaml \
--yolo-size l \
--dino-variant vitb16 \
--integration triple \
--epochs 100 \
--batch-size 8 \
--name ultimate_p0p3p4
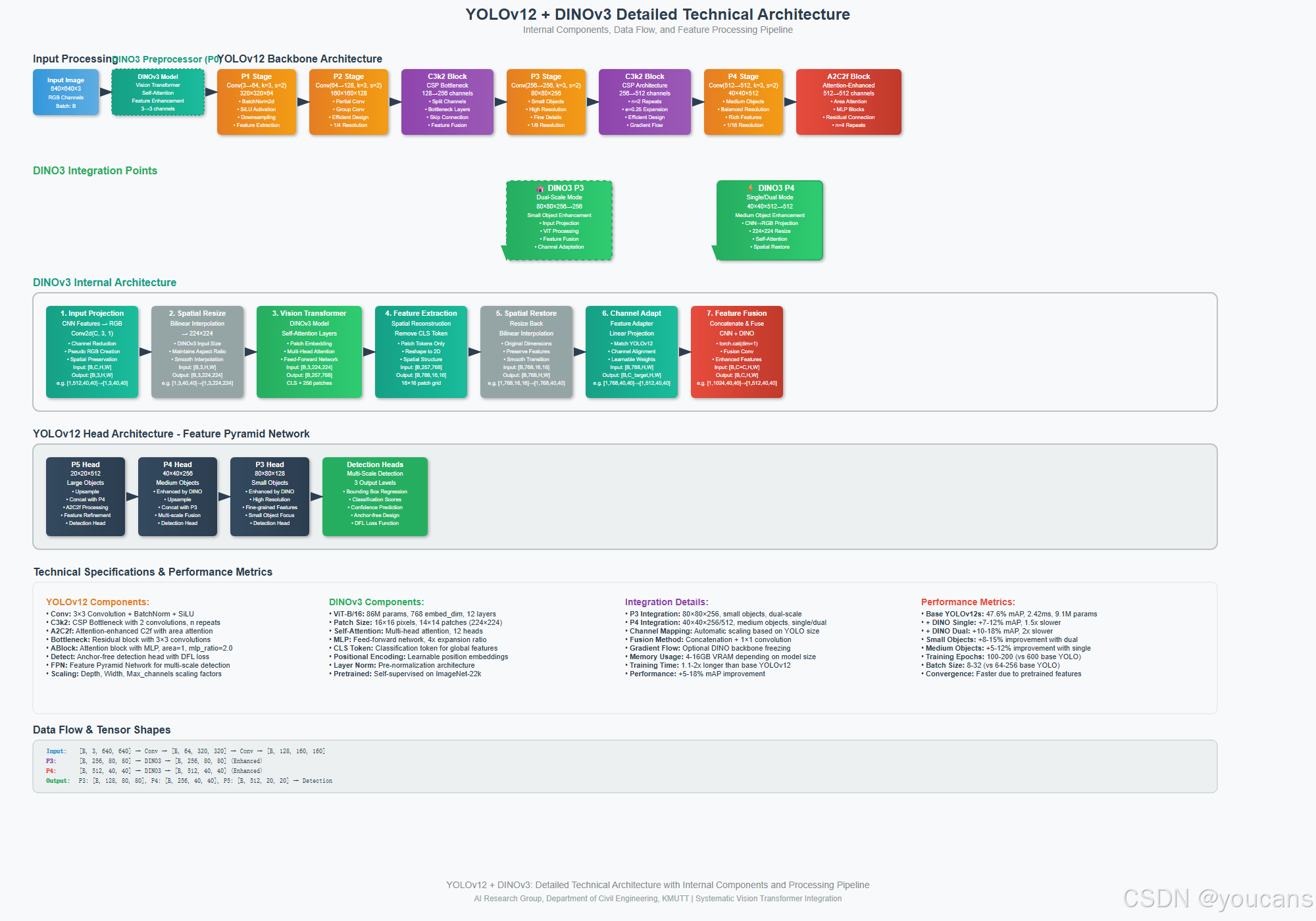
完整技术架构图:展示 YOLOv12 与 DINOv3 集成方案的内部组件、数据流及特征处理流水线
引用格式: Malaisree P, Youwai S, Kitkobsin T, et al. DINO-YOLO: Self-Supervised Pre-training for Data-Efficient Object Detection in Civil Engineering Applications[EB/OL]. [2025-10-31]. https://arxiv.org/pdf/2510.25140.
版权说明:
youcans@qq.com 作品,转载必须标注原文链接:
【动手学YOLO】DINO-YOLO:面向数据高效目标检测的自监督预训练方法(https://youcans.blog.csdn.net/article/details/154406956)
Crated:2025-11



















 625
625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











