







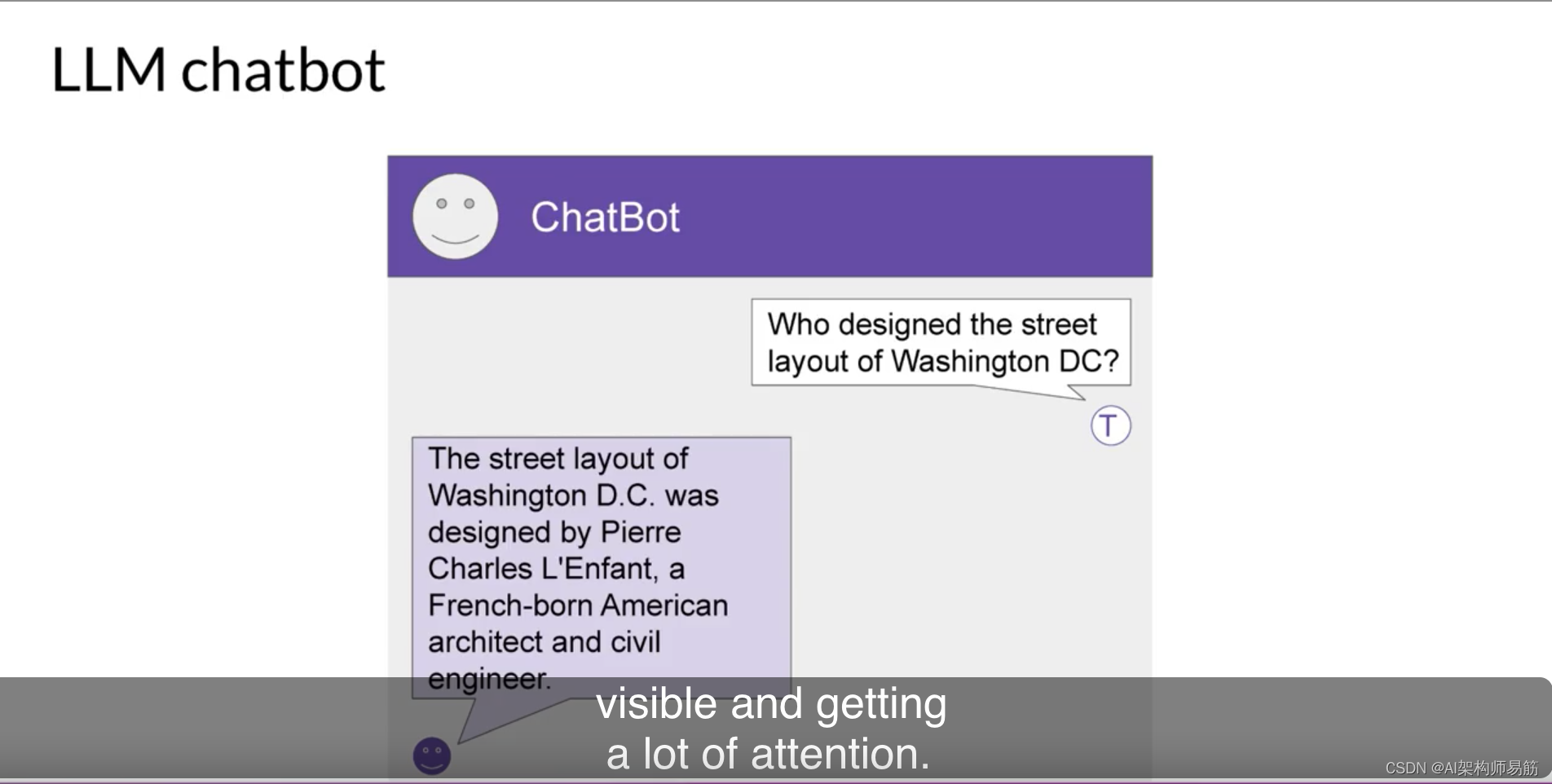
您可能会认为LLMs和生成性AI主要关注聊天任务。毕竟,聊天机器人非常受到关注并且备受瞩目。下一个词的预测是许多不同功能背后的基本概念,从基本的聊天机器人开始。
但是,您可以使用这种概念上简单的技术执行文本生成中的其他各种任务。例如,您可以要求模型根据提示写一篇文章,

或者总结您提供的对话作为提示的对话,模型使用这些数据以及其对自然语言的理解来生成摘要。

您可以使用模型执行各种翻译任务,从传统的两种不同语言之间的翻译,例如法语和德语,或英语和西班牙语。

或者将自然语言翻译为机器代码。例如,您可以要求模型编写一些Python代码,该代码将返回DataFrame中每列的平均值,模型将生成您可以传递给解释器的代码。

您可以使用LLMs执行像信息检索这样的小型、专注的任务。在此示例中,您要求模型识别新闻文章中提到的所有人和地点。这被称为命名实体识别,一个词分类。模型参数中编码的知识理解使其能够正确执行此任务并将请求的信息返回给您。

最后,一个活跃的发展领域是通过将它们连接到外部数据源或使用它们来调用外部API来增强LLMs。您可以使用此功能为模型提供其预训练中不知道的信息,并使您的模型能够与真实世界互动。
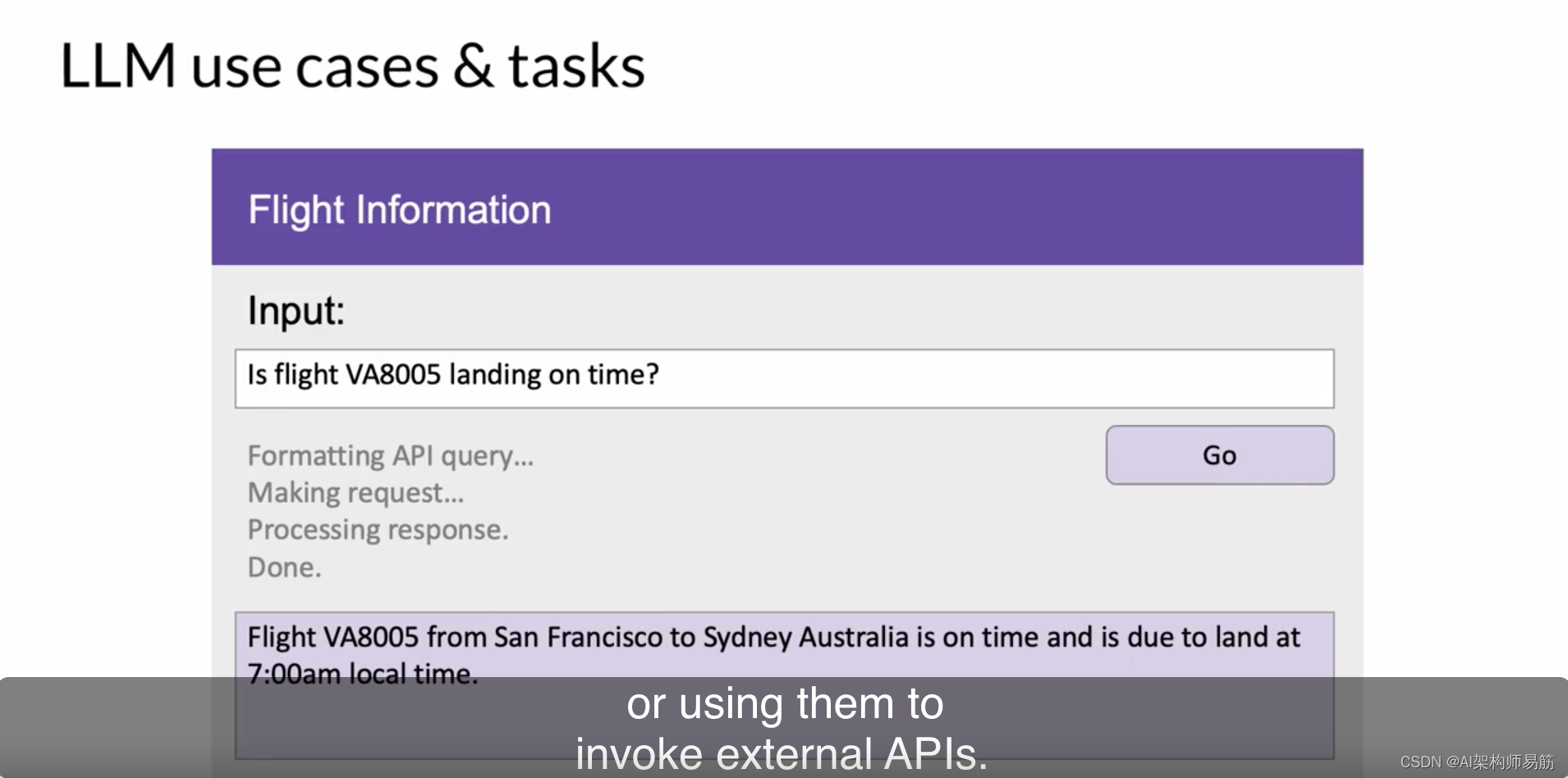
您将在课程的第3周中了解更多关于如何做到这一点的信息。开发人员已经发现,随着基础模型的规模从数亿个参数增长到数十亿,甚至数千亿,模型所拥有的语言理解也在增加。模型参数中存储的这种语言理解是处理、推理并最终解决您给予它的任务的内容,

但同样真实的是,较小的模型可以被微调以在特定的专注任务上表现良好。您将在课程的第2周中了解更多关于如何做到这一点的信息。LLMs在过去几年中展现出的能力的迅速增长主要归功于为它们提供动力的架构。让我们继续观看下一个视频,以便更仔细地了解。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/7zFPm/llm-use-cases-and-tasks

















 644
644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









