







基本思想:使用yolov5-lite-e部署到OAK双目相机实现检测、测距功能
一、下载模型
https://github.com/ppogg/YOLOv5-Lite#v5lite-e这里以YOLOv5-lite-e模型为例
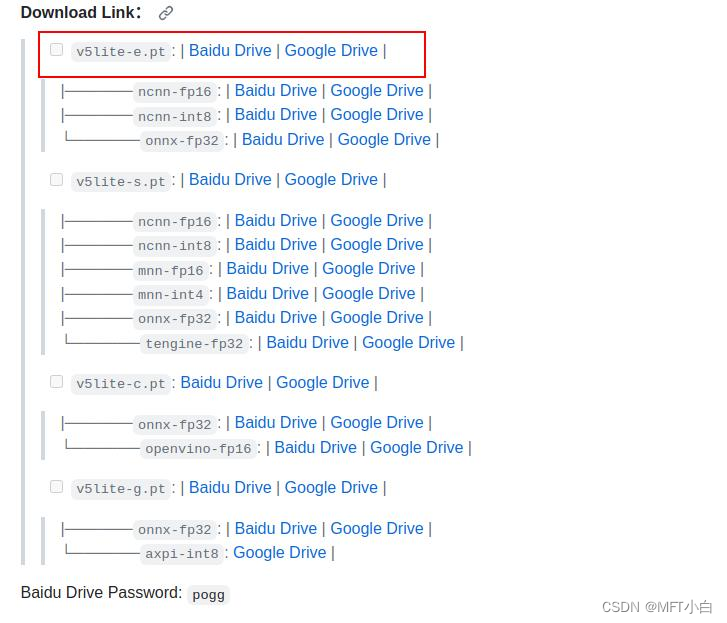
二、转换模型
2.1 pt转onnx
修改官方之后的转换脚本
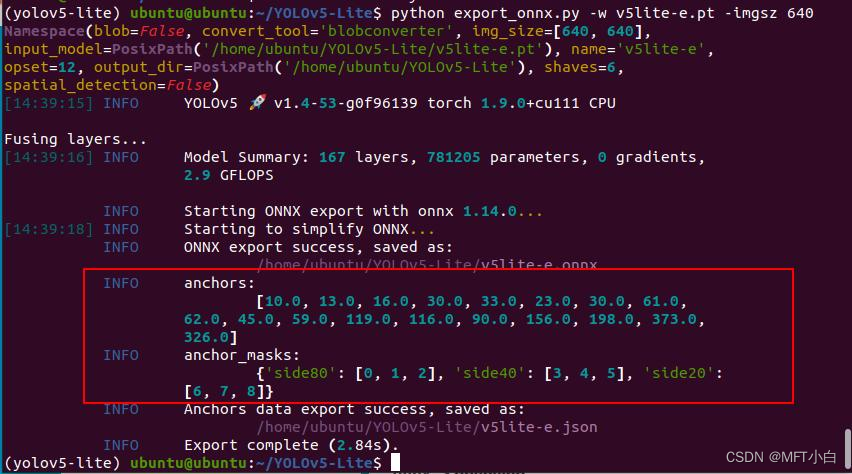
(yolov5-lite) ubuntu@ubuntu:~/YOLOv5-Lite$ python export_onnx.py -w v5lite-e.pt -imgsz 640export_onnx.py
# coding=utf-8
import argparse
from io import BytesIO
import json
import logging
import sys
import time
import warnings
from pathlib import Path
warnings.filterwarnings("ignore")
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0]
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
import torch
import torch.nn as nn
from models.common import Conv
from models.experimental import attempt_load
from utils.activations import Hardswish, SiLU
from utils.general import check_img_size
from utils.torch_utils import select_device
try:
from rich import print
from rich.logging import RichHandler
logging.basicConfig(
level="INFO",
format="%(message)s",
datefmt="[%X]",
handlers=[
RichHandler(
rich_tracebacks=True,
show_path=False,
)
],
)
except ImportError:
logging.basicConfig(
level="INFO",
format="%(message)s",
datefmt="[%X]",
)
class DetectV5(nn.Module):
# YOLOv5 Detect head for detection models
dynamic = False # force grid reconstruction
export = True # export mode
def __init__(self, old_detect): # detection layer
super().__init__()
self.nc = old_detect.nc # number of classes
self.no = old_detect.no # number of outputs per anchor
self.nl = old_detect.nl # number of detection layers
self.na = old_detect.na
self.anchors = old_detect.anchors
self.grid = old_detect.grid # [torch.zeros(1)] * self.nl
self.anchor_grid = old_detect.anchor_grid # anchor grid
self.stride = old_detect.stride
if hasattr(old_detect, "inplace"):
self.inplace = old_detect.inplace
self.f = old_detect.f
self.i = old_detect.i
self.m = old_detect.m
def forward(self, x):
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
x[i] = x[i].sigmoid()
return x
def parse_args():
parser = argparse.ArgumentParser(
description="Tool for converting YOLOv5-Lite models to the blob format used by OAK",
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
)
parser.add_argument(
"-m",
"-i",
"-w",
"--input_model",
type=Path,
required=True,
help="weights path",
)
parser.add_argument(
"-imgsz",
"--img-size",
nargs="+",
type=int,
default=[640, 640],
help="image size",
) # height, width
parser.add_argument("-op", "--opset", type=int, default=12, help="opset version")
parser.add_argument(
"-n",
"--name",
type=str,
help="The name of the model to be saved, none means using the same name as the input model",
)
parser.add_argument(
"-o",
"--output_dir",
type=Path,
help="Directory for saving files, none means using the same path as the input model",
)
parser.add_argument(
"-b",
"--blob",
action="store_true",
help="OAK Blob export",
)
parser.add_argument(
"-s",
"--spatial_detection",
action="store_true",
help="Inference with depth information",
)
parser.add_argument(
"-sh",
"--shaves",
type=int,
help="Inference with depth information",
)
parser.add_argument(
"-t",
"--convert_tool",
type=str,
help="Which tool is used to convert, docker: should already have docker (https://docs.docker.com/get-docker/) and docker-py (pip install docker) installed; blobconverter: uses an online server to convert the model and should already have blobconverter (pip install blobconverter); local: use openvino-dev (pip install openvino-dev) and openvino 2022.1 ( https://docs.oakchina.cn/en/latest /pages/Advanced/Neural_networks/local_convert_openvino.html#id2) to convert",
default="blobconverter",
choices=["docker", "blobconverter", "local"],
)
args = parser.parse_args()
args.input_model = args.input_model.resolve().absolute()
if args.name is None:
args.name = args.input_model.stem
if args.output_dir is None:
args.output_dir = args.input_model.parent
args.img_size *= 2 if len(args.img_size) == 1 else 1 # expand
if args.shaves is None:
args.shaves = 5 if args.spatial_detection else 6
return args
def export(input_model, img_size, output_model, opset, **kwargs):
t = time.time()
# Load PyTorch model
device = select_device("cpu")
model = attempt_load(input_model, map_location=device) # load FP32 model
labels = model.names
labels = labels if isinstance(labels, list) else list(labels.values())
# Checks
gs = int(max(model.stride)) # grid size (max stride)
img_size = [
check_img_size(x, gs) for x in img_size
] # verify img_size are gs-multiples
# Input
img = torch.zeros(1, 3, *img_size).to(device) # image size(1,3,320,320) iDetection
# Update model
model.eval()
for k, m in model.named_modules():
if isinstance(m, Conv): # assign export-friendly activations
m._non_persistent_buffers_set = set() # torch 1.6.0 compatibility
if isinstance(m.act, nn.SiLU):
m.act = SiLU()
if isinstance(m.act, nn.Hardswish):
m.act = Hardswish()
elif isinstance(m, nn.Upsample):
m.recompute_scale_factor = None # torch 1.11.0 compatibility
model.model[-1] = DetectV5(model.model[-1])
m = model.module.model[-1] if hasattr(model, "module") else model.model[-1]
num_branches = len(m.anchor_grid)
y = model(img) # dry runs
# ONNX export
try:
import onnx
print()
logging.info("Starting ONNX export with onnx %s..." % onnx.__version__)
output_list = ["output%s_yolov5" % (i + 1) for i in range(num_branches)]
with BytesIO() as f:
torch.onnx.export(
model,
img,
f,
verbose=False,
opset_version=opset,
input_names=["images"],
output_names=output_list,
)
# Checks
onnx_model = onnx.load_from_string(f.getvalue()) # load onnx model
onnx.checker.check_model(onnx_model) # check onnx model
try:
import onnxsim
logging.info("Starting to simplify ONNX...")
onnx_model, check = onnxsim.simplify(onnx_model)
assert check, "assert check failed"
except ImportError:
logging.warning(
"onnxsim is not found, if you want to simplify the onnx, "
+ "you should install it:\n\t"
+ "pip install -U onnxsim onnxruntime\n"
+ "then use:\n\t"
+ f'python -m onnxsim "{output_model}" "{output_model}"'
)
except Exception:
logging.exception("Simplifier failure:")
onnx.save(onnx_model, output_model)
logging.info("ONNX export success, saved as:\n\t%s" % output_model)
except Exception:
logging.exception("ONNX export failure")
# generate anchors and sides
anchors, sides = [], []
m = model.module.model[-1] if hasattr(model, "module") else model.model[-1]
for i in range(num_branches):
sides.append(int(img_size[0] // m.stride[i]))
for j in range(m.anchor_grid[i].size()[1]):
anchors.extend(m.anchor_grid[i][0, j, 0, 0].numpy())
anchors = [float(x) for x in anchors]
# generate masks
masks = dict()
# for i, num in enumerate(sides[::-1]):
for i, num in enumerate(sides):
masks[f"side{num}"] = list(range(i * 3, i * 3 + 3))
logging.info("anchors:\n\t%s" % anchors)
logging.info("anchor_masks:\n\t%s" % masks)
export_json = output_model.with_suffix(".json")
export_json.write_text(
json.dumps(
{
"nn_config": {
"output_format": "detection",
"NN_family": "YOLO",
"input_size": f"{img_size[0]}x{img_size[1]}",
"NN_specific_metadata": {
"classes": model.nc,
"coordinates": 4,
"anchors": anchors,
"anchor_masks": masks,
"iou_threshold": 0.5,
"confidence_threshold": 0.5,
},
},
"mappings": {"labels": labels},
},
indent=4,
)
)
logging.info("Anchors data export success, saved as:\n\t%s" % export_json)
# Finish
logging.info("Export complete (%.2fs)." % (time.time() - t))
def convert(convert_tool, output_model, shaves, output_dir, name, **kwargs):
t = time.time()
export_dir: Path = output_dir.joinpath(name + "_openvino")
export_dir.mkdir(parents=True, exist_ok=True)
export_xml = export_dir.joinpath(name + ".xml")
export_blob = export_dir.joinpath(name + ".blob")
if convert_tool == "blobconverter":
import blobconverter
from zipfile import ZIP_LZMA, ZipFile
blob_path = blobconverter.from_onnx(
model=str(output_model),
data_type="FP16",
shaves=shaves,
use_cache=False,
version="2022.1",
output_dir=export_dir,
optimizer_params=[
"--scale=255",
"--reverse_input_channel",
"--use_new_frontend",
],
download_ir=True,
)
with ZipFile(blob_path, "r", ZIP_LZMA) as zip_obj:
for name in zip_obj.namelist():
zip_obj.extract(
name,
output_dir,
)
blob_path.unlink()
elif convert_tool == "docker":
import docker
export_dir = Path("/io").joinpath(export_dir.name)
export_xml = export_dir.joinpath(name + ".xml")
export_blob = export_dir.joinpath(name + ".blob")
client = docker.from_env()
image = client.images.pull("openvino/ubuntu20_dev", tag="2022.1.0")
docker_output = client.containers.run(
image=image.tags[0],
command=f"bash -c \"mo -m {name}.onnx -n {name} -o {export_dir} --static_shape --reverse_input_channels --scale=255 --use_new_frontend && echo 'MYRIAD_ENABLE_MX_BOOT NO' | tee /tmp/myriad.conf >> /dev/null && /opt/intel/openvino/tools/compile_tool/compile_tool -m {export_xml} -o {export_blob} -ip U8 -VPU_NUMBER_OF_SHAVES {shaves} -VPU_NUMBER_OF_CMX_SLICES {shaves} -d MYRIAD -c /tmp/myriad.conf\"",
remove=True,
volumes=[
f"{output_dir}:/io",
],
working_dir="/io",
)
logging.info(docker_output.decode("utf8"))
else:
import subprocess as sp
# OpenVINO export
logging.info("Starting to export OpenVINO...")
OpenVINO_cmd = (
"mo --input_model %s --output_dir %s --data_type FP16 --scale 255 --reverse_input_channel"
% (output_model, export_dir)
)
try:
sp.check_output(OpenVINO_cmd, shell=True)
logging.info("OpenVINO export success, saved as %s" % export_dir)
except Exception:
logging.exception("")
logging.warning("OpenVINO export failure!")
logging.warning(
"By the way, you can try to export OpenVINO use:\n\t%s" % OpenVINO_cmd
)
# OAK Blob export
logging.info("Then you can try to export blob use:")
blob_cmd = (
"echo 'MYRIAD_ENABLE_MX_BOOT ON' | tee /tmp/myriad.conf"
+ "compile_tool -m %s -o %s -ip U8 -d MYRIAD -VPU_NUMBER_OF_SHAVES %s -VPU_NUMBER_OF_CMX_SLICES %s -c /tmp/myriad.conf"
% (export_xml, export_blob, shaves, shaves)
)
logging.info("%s" % blob_cmd)
logging.info(
"compile_tool maybe in the path: /opt/intel/openvino/tools/compile_tool/compile_tool, if you install openvino 2022.1 with apt"
)
logging.info("Convert complete (%.2fs).\n" % (time.time() - t))
if __name__ == "__main__":
args = parse_args()
print(args)
output_model = args.output_dir / (args.name + ".onnx")
export(output_model=output_model, **vars(args))
if args.blob:
convert(output_model=output_model, **vars(args))
注意以下参数,后期编码需要用到。
2.2 onnx转openvino
(yolov5-lite) ubuntu@ubuntu:~/YOLOv5-Lite$ python /opt/intel/openvino_2021/deployment_tools/model_optimizer/mo.py --input_model v5lite-e.onnx --output_dir /home/ubuntu/YOLOv5-Lite/saved/FP16 --input_shape [1,3,640,640] --data_type FP16 --scale_values [255.0,255.0,255.0] --mean_values [0,0,0]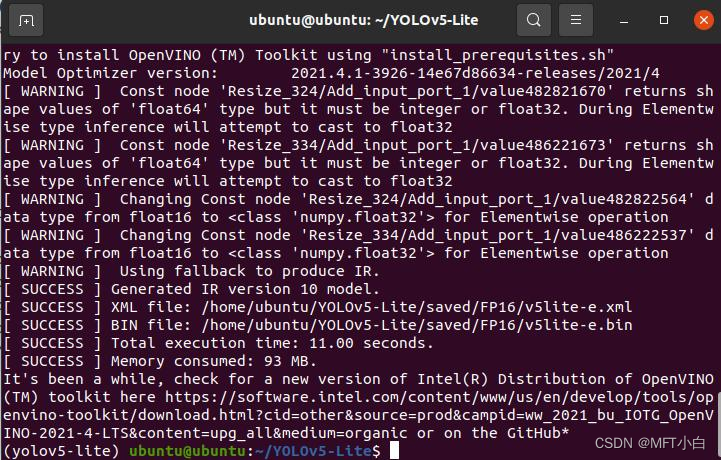
2.3 openvino转blob
第一次使用
(openvino) ubuntu@ubuntu:~/YOLOv5-Lite$ cd /opt/intel/openvino_2021/deployment_tools/tools
(openvino) ubuntu@ubuntu:/opt/intel/openvino_2021/deployment_tools/tools$ sudo chmod 777 compile_tool/
(openvino) ubuntu@ubuntu:/opt/intel/openvino_2021/deployment_tools/tools$ cd compile_tool/
(openvino) ubuntu@ubuntu:/opt/intel/openvino_2021/deployment_tools/tools/compile_tool$ ./compile_tool -m /home/ubuntu/YOLOv5-Lite/saved/FP16/v5lite-e.xml -ip U8 -d MYRIAD -VPU_NUMBER_OF_SHAVES 4 -VPU_NUMBER_OF_CMX_SLICES 4(openvino) ubuntu@ubuntu:~/YOLOv5-Lite$ cd /opt/intel/openvino_2021/deployment_tools/tools/compile_tool
(openvino) ubuntu@ubuntu:/opt/intel/openvino_2021/deployment_tools/tools/compile_tool$ ./compile_tool -m /home/ubuntu/YOLOv5-Lite/saved/FP16/v5lite-e.xml -ip U8 -d MYRIAD -VPU_NUMBER_OF_SHAVES 4 -VPU_NUMBER_OF_CMX_SLICES 4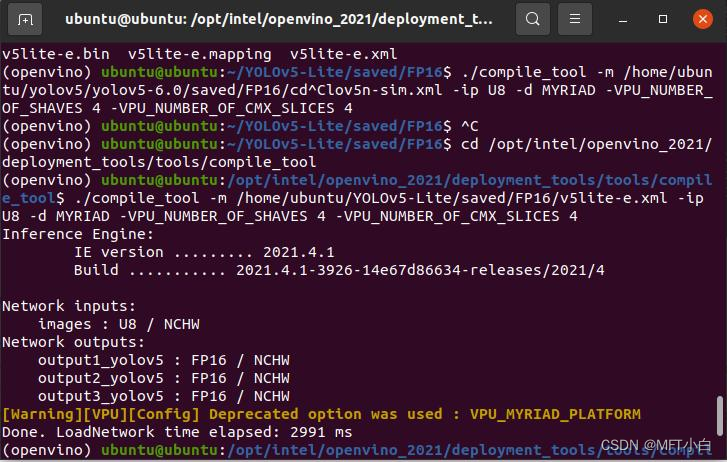
三、部署OAK
前言:OAK相机编程,最好基于官方给与的框架结构比较好理解
参考此处:Nodes — DepthAI documentation | Luxonis
本次用到node
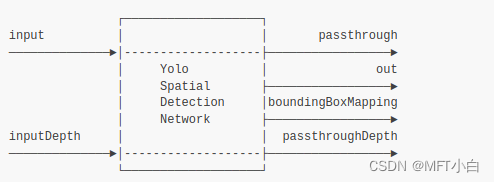
colorcamera node
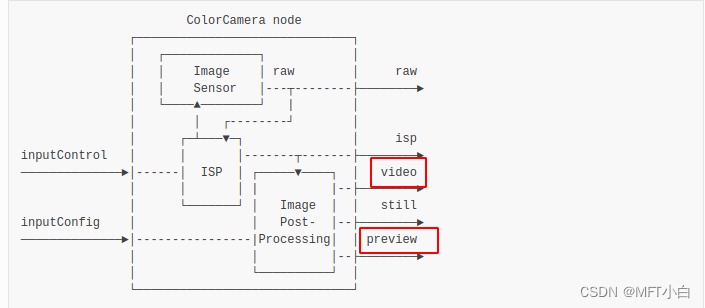
monocamera node
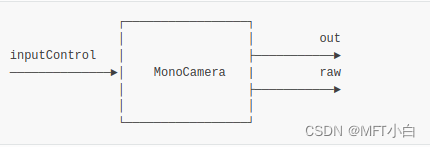
SpatialLocationCalculator node
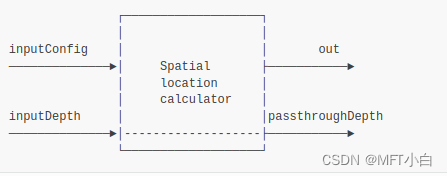
YoloSpatialDetectionNetwork node
3.1 python测试
test_yolov5-lite-e_depthai.py
# coding=utf-8
import cv2
import depthai as dai
import numpy as np
numClasses = 80
model = dai.OpenVINO.Blob("./v5lite-e.blob")
dim = next(iter(model.networkInputs.values())).dims
W, H = dim[:2]
output_name, output_tenser = next(iter(model.networkOutputs.items()))
if "yolov6" in output_name:
numClasses = output_tenser.dims[2] - 5
else:
numClasses = output_tenser.dims[2] // 3 - 5
labelMap = [
# "class_1","class_2","..."
"class_%s" % i
for i in range(numClasses)
]
# Create pipeline
pipeline = dai.Pipeline()
# Define sources and outputs
camRgb = pipeline.create(dai.node.ColorCamera)
detectionNetwork = pipeline.create(dai.node.YoloDetectionNetwork)
xoutRgb = pipeline.create(dai.node.XLinkOut)
xoutNN = pipeline.create(dai.node.XLinkOut)
xoutRgb.setStreamName("image")
xoutNN.setStreamName("nn")
# Properties
camRgb.setPreviewSize(W, H)
camRgb.setResolution(dai.ColorCameraProperties.SensorResolution.THE_1080_P)
camRgb.setInterleaved(False)
camRgb.setColorOrder(dai.ColorCameraProperties.ColorOrder.BGR)
# Network specific settings
detectionNetwork.setBlob(model)
detectionNetwork.setConfidenceThreshold(0.5)
# Yolo specific parameters
detectionNetwork.setNumClasses(numClasses)
detectionNetwork.setCoordinateSize(4)
detectionNetwork.setAnchors(
[
10,13, 16,30, 33,23,
30,61, 62,45, 59,119,
116,90, 156,198, 373,326
]
)
detectionNetwork.setAnchorMasks(
{
"side%s" % (W // 8): [0, 1, 2],
"side%s" % (W // 16): [3, 4, 5],
"side%s" % (W // 32): [6, 7, 8],
}
)
detectionNetwork.setIouThreshold(0.5)
# Linking
camRgb.preview.link(detectionNetwork.input)
camRgb.preview.link(xoutRgb.input)
detectionNetwork.out.link(xoutNN.input)
# Connect to device and start pipeline
with dai.Device(pipeline) as device:
# Output queues will be used to get the rgb frames and nn data from the outputs defined above
imageQueue = device.getOutputQueue(name="image", maxSize=4, blocking=False)
detectQueue = device.getOutputQueue(name="nn", maxSize=4, blocking=False)
frame = None
detections = []
# nn data, being the bounding box locations, are in <0..1> range - they need to be normalized with frame width/height
def frameNorm(frame, bbox):
normVals = np.full(len(bbox), frame.shape[0])
normVals[::2] = frame.shape[1]
return (np.clip(np.array(bbox), 0, 1) * normVals).astype(int)
def drawText(frame, text, org, color=(255, 255, 255), thickness=1):
cv2.putText(
frame, text, org, cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), thickness + 3, cv2.LINE_AA
)
cv2.putText(
frame, text, org, cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, thickness, cv2.LINE_AA
)
def drawRect(frame, topLeft, bottomRight, color=(255, 255, 255), thickness=1):
cv2.rectangle(frame, topLeft, bottomRight, (0, 0, 0), thickness + 3)
cv2.rectangle(frame, topLeft, bottomRight, color, thickness)
def displayFrame(name, frame):
color = (128, 128, 128)
for detection in detections:
bbox = frameNorm(
frame, (detection.xmin, detection.ymin, detection.xmax, detection.ymax)
)
drawText(
frame=frame,
text=labelMap[detection.label],
org=(bbox[0] + 10, bbox[1] + 20),
)
drawText(
frame=frame,
text=f"{detection.confidence:.2%}",
org=(bbox[0] + 10, bbox[1] + 35),
)
drawRect(
frame=frame,
topLeft=(bbox[0], bbox[1]),
bottomRight=(bbox[2], bbox[3]),
color=color,
)
# Show the frame
cv2.imshow(name, frame)
while True:
imageQueueData = imageQueue.tryGet()
detectQueueData = detectQueue.tryGet()
if imageQueueData is not None:
frame = imageQueueData.getCvFrame()
if detectQueueData is not None:
detections = detectQueueData.detections
if frame is not None:
displayFrame("rgb", frame)
if cv2.waitKey(1) == ord("q"):
break
测试结果

3.2 c++测试(不含测距)
CMakeLists.txt
cmake_minimum_required(VERSION 3.16)
project(test_yolov5_lite)
set(CMAKE_CXX_STANDARD 14)
find_package(OpenCV REQUIRED)
find_package(depthai CONFIG REQUIRED)
add_executable(test_yolov5_lite main.cpp)
target_link_libraries(test_yolov5_lite ${OpenCV_LIBS} depthai::opencv)main.cpp
#include <iostream>
// Includes common necessary includes for development using depthai library
#include "depthai/depthai.hpp"
/*
The code is the same as for Tiny-yolo-V3, the only difference is the blob file.
The blob was compiled following this tutorial: https://github.com/TNTWEN/OpenVINO-YOLOV4
*/
static const std::vector<std::string> labelMap = {
"person", "bicycle", "car", "motorbike", "aeroplane", "bus", "train", "truck", "boat",
"traffic light", "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse",
"sheep", "cow", "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag",
"tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove",
"skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon",
"bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza",
"donut", "cake", "chair", "sofa", "pottedplant", "bed", "diningtable", "toilet", "tvmonitor",
"laptop", "mouse", "remote", "keyboard", "cell phone", "microwave", "oven", "toaster", "sink",
"refrigerator", "book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush"};
static std::atomic<bool> syncNN{true};
int main() {
// Create pipeline
dai::Pipeline pipeline;
// Define sources
auto camRgb = pipeline.create<dai::node::ColorCamera>();
// Properties
camRgb->setPreviewSize(640, 640);
camRgb->setBoardSocket(dai::CameraBoardSocket::RGB);
camRgb->setResolution(dai::ColorCameraProperties::SensorResolution::THE_1080_P);
camRgb->setInterleaved(false);
camRgb->setColorOrder(dai::ColorCameraProperties::ColorOrder::RGB);
// Network specific settings
auto detectionNetwork = pipeline.create<dai::node::YoloDetectionNetwork>();
detectionNetwork->setBlob("../v5lite-e.blob");
detectionNetwork->setConfidenceThreshold(0.5);
//Yolo specific parameters
detectionNetwork->setNumClasses(80);
detectionNetwork->setCoordinateSize(4);
detectionNetwork->setAnchors({10,13,16,30,33,23,30,61,62,45,59,119,116,90,156,198,373,326});
detectionNetwork->setAnchorMasks({{{"side80",{0, 1, 2}},{"side40",{3, 4, 5}},{"side20",{6, 7, 8}}}});
detectionNetwork->setIouThreshold(0.5);
auto xoutRgb = pipeline.create<dai::node::XLinkOut>();
xoutRgb->setStreamName("image");
auto xoutNN = pipeline.create<dai::node::XLinkOut>();
xoutNN->setStreamName("nn");
// Linking
camRgb->preview.link(xoutRgb->input);
camRgb->preview.link(detectionNetwork->input);
if(syncNN) {
detectionNetwork->passthrough.link(xoutRgb->input);
} else {
camRgb->preview.link(xoutRgb->input);
}
detectionNetwork->out.link(xoutNN->input);
// Connect to device and start pipeline
dai::Device device(pipeline);
// Output queues will be used to get the rgb frames and nn data from the outputs defined above
auto imageQueue = device.getOutputQueue("image",8,false);
auto detectQueue = device.getOutputQueue("nn", 8, false);
cv::Mat frame;
std::vector<dai::ImgDetection> detections;
auto startTime = std::chrono::steady_clock::now();
int counter = 0;
float fps = 0;
auto color2 = cv::Scalar(255, 255, 255);
// Add bounding boxes and text to the frame and show it to the user
auto displayFrame = [](std::string name, cv::Mat frame, std::vector<dai::ImgDetection>& detections) {
auto color = cv::Scalar(255, 0, 0);
// nn data, being the bounding box locations, are in <0..1> range - they need to be normalized with frame width/height
for(auto& detection : detections) {
int x1 = detection.xmin * frame.cols;
int y1 = detection.ymin * frame.rows;
int x2 = detection.xmax * frame.cols;
int y2 = detection.ymax * frame.rows;
uint32_t labelIndex = detection.label;
std::string labelStr = std::to_string(labelIndex);
if(labelIndex < labelMap.size()) {
labelStr = labelMap[labelIndex];
}
cv::putText(frame, labelStr, cv::Point(x1 + 10, y1 + 20), cv::FONT_HERSHEY_TRIPLEX, 0.5, 255);
std::stringstream confStr;
confStr << std::fixed << std::setprecision(2) << detection.confidence * 100;
cv::putText(frame, confStr.str(), cv::Point(x1 + 10, y1 + 40), cv::FONT_HERSHEY_TRIPLEX, 0.5, 255);
cv::rectangle(frame, cv::Rect(cv::Point(x1, y1), cv::Point(x2, y2)), color, cv::FONT_HERSHEY_SIMPLEX);
}
// Show the frame
cv::imshow(name, frame);
};
while(true) {
std::shared_ptr<dai::ImgFrame> inRgb;
std::shared_ptr<dai::ImgDetections> inDet;
if(syncNN) {
inRgb = imageQueue->get<dai::ImgFrame>();
inDet = detectQueue->get<dai::ImgDetections>();
} else {
inRgb = imageQueue->tryGet<dai::ImgFrame>();
inDet = detectQueue->tryGet<dai::ImgDetections>();
}
counter++;
auto currentTime = std::chrono::steady_clock::now();
auto elapsed = std::chrono::duration_cast<std::chrono::duration<float>>(currentTime - startTime);
if(elapsed > std::chrono::seconds(1)) {
fps = counter / elapsed.count();
counter = 0;
startTime = currentTime;
}
if(inRgb) {
frame = inRgb->getCvFrame();
std::stringstream fpsStr;
fpsStr << "NN fps: " << std::fixed << std::setprecision(2) << fps;
cv::putText(frame, fpsStr.str(), cv::Point(2, inRgb->getHeight() - 4), cv::FONT_HERSHEY_TRIPLEX, 0.4, color2);
}
if(inDet) {
detections = inDet->detections;
}
if(!frame.empty()) {
displayFrame("rgb", frame, detections);
}
int key = cv::waitKey(1);
if(key == 'q' || key == 'Q') {
return 0;
}
}
return 0;
}
测试结果

3.3 加上测距
#include <iostream>
// Includes common necessary includes for development using depthai library
#include "depthai/depthai.hpp"
/*
The code is the same as for Tiny-yolo-V3, the only difference is the blob file.
The blob was compiled following this tutorial: https://github.com/TNTWEN/OpenVINO-YOLOV4
*/
static const std::vector<std::string> labelMap = {
"person", "bicycle", "car", "motorbike", "aeroplane", "bus", "train", "truck", "boat",
"traffic light", "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse",
"sheep", "cow", "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag",
"tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove",
"skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon",
"bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza",
"donut", "cake", "chair", "sofa", "pottedplant", "bed", "diningtable", "toilet", "tvmonitor",
"laptop", "mouse", "remote", "keyboard", "cell phone", "microwave", "oven", "toaster", "sink",
"refrigerator", "book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush"};
static std::atomic<bool> syncNN{true};
int main() {
// Create pipeline
dai::Pipeline pipeline;
// Define sources
auto camRgb = pipeline.create<dai::node::ColorCamera>();
auto monoLeft = pipeline.create<dai::node::MonoCamera>();
auto monoRight = pipeline.create<dai::node::MonoCamera>();
auto stereo = pipeline.create<dai::node::StereoDepth>();
auto spatialDataCalculator = pipeline.create<dai::node::SpatialLocationCalculator>();
// Properties
camRgb->setPreviewSize(640, 640);
camRgb->setBoardSocket(dai::CameraBoardSocket::RGB);
camRgb->setResolution(dai::ColorCameraProperties::SensorResolution::THE_1080_P);
camRgb->setInterleaved(false);
camRgb->setColorOrder(dai::ColorCameraProperties::ColorOrder::RGB);
camRgb->setPreviewKeepAspectRatio(false); //将调整视频大小以适应预览大小,对齐
monoLeft->setBoardSocket(dai::CameraBoardSocket::LEFT);
monoLeft->setResolution(dai::MonoCameraProperties::SensorResolution::THE_720_P);
monoRight->setBoardSocket(dai::CameraBoardSocket::RIGHT);
monoRight->setResolution(dai::MonoCameraProperties::SensorResolution::THE_720_P);
stereo->setDefaultProfilePreset(dai::node::StereoDepth::PresetMode::HIGH_ACCURACY);
stereo->setLeftRightCheck(true);
stereo->setDepthAlign(dai::CameraBoardSocket::RGB);
stereo->setExtendedDisparity(true);
dai::Point2f topLeft(0.4f, 0.4f);
dai::Point2f bottomRight(0.6f, 0.6f);
dai::SpatialLocationCalculatorConfigData config;
config.depthThresholds.lowerThreshold = 100;
config.depthThresholds.upperThreshold = 10000;
config.roi = dai::Rect(topLeft, bottomRight);
spatialDataCalculator->initialConfig.addROI(config);
spatialDataCalculator->inputConfig.setWaitForMessage(false);
// Network specific settings
auto detectionNetwork = pipeline.create<dai::node::YoloDetectionNetwork>();
detectionNetwork->setBlob("../v5lite-e.blob");
detectionNetwork->setConfidenceThreshold(0.5);
//Yolo specific parameters
detectionNetwork->setNumClasses(80);
detectionNetwork->setCoordinateSize(4);
detectionNetwork->setAnchors({10,13,16,30,33,23,30,61,62,45,59,119,116,90,156,198,373,326});
detectionNetwork->setAnchorMasks({{{"side80",{0, 1, 2}},{"side40",{3, 4, 5}},{"side20",{6, 7, 8}}}});
detectionNetwork->setIouThreshold(0.5);
// rgb输出
auto xoutRgb = pipeline.create<dai::node::XLinkOut>();
xoutRgb->setStreamName("rgb");
// depth输出
auto xoutDepth = pipeline.create<dai::node::XLinkOut>();
xoutDepth->setStreamName("depth");
// 测距模块数据输出
auto xoutSpatialData = pipeline.create<dai::node::XLinkOut>();
xoutSpatialData->setStreamName("spatialData");
// 测距模块配置输入
auto xinSpatialCalcConfig = pipeline.create<dai::node::XLinkIn>();
xinSpatialCalcConfig->setStreamName("spatialCalcConfig");
// Linking preview 画布 video 实时分辨率
camRgb->video.link(xoutRgb->input); //显示用video
camRgb->preview.link(detectionNetwork->input); //推理用preview
monoLeft->out.link(stereo->left);
monoRight->out.link(stereo->right);
spatialDataCalculator->passthroughDepth.link(xoutDepth->input);
stereo->depth.link(spatialDataCalculator->inputDepth);
spatialDataCalculator->out.link(xoutSpatialData->input);
xinSpatialCalcConfig->out.link(spatialDataCalculator->inputConfig);
// output
auto xlinkParseOut = pipeline.create<dai::node::XLinkOut>();
xlinkParseOut->setStreamName("parseOut");
auto xlinkoutOut = pipeline.create<dai::node::XLinkOut>();
xlinkoutOut->setStreamName("out");
auto xlinkPassthroughOut = pipeline.create<dai::node::XLinkOut>();
xlinkPassthroughOut->setStreamName("passthrough");
detectionNetwork->out.link(xlinkParseOut->input);
detectionNetwork->passthrough.link(xlinkPassthroughOut->input);
// Connect to device and start pipeline
dai::Device device;
device.setIrLaserDotProjectorBrightness(1000);
device.setIrFloodLightBrightness(0);
device.startPipeline(pipeline);
// Output queues will be used to get the rgb frames and nn data from the outputs defined above
auto detectQueue = device.getOutputQueue("parseOut",8,false);
auto passthQueue = device.getOutputQueue("passthrough", 8, false);
auto depthQueue = device.getOutputQueue("depth", 8, false);
auto spatialCalcQueue = device.getOutputQueue("spatialData", 8, false);
auto spatialCalcConfigInQueue = device.getInputQueue("spatialCalcConfig", 8, false);
auto rgbQueue = device.getOutputQueue("rgb", 8, false);
bool printOutputLayersOnce = true;
auto color = cv::Scalar(0,255,0);
std::vector<dai::ImgDetection> detections;
auto startTime = std::chrono::steady_clock::now();
int counter = 0;
float fps = 0;
auto color2 = cv::Scalar(255, 255, 255);
cv::Scalar color1 = cv::Scalar(0, 0, 255);
while (true) {
counter++;
auto currentTime = std::chrono::steady_clock::now();
auto elapsed = std::chrono::duration_cast<std::chrono::duration<float>>(currentTime - startTime);
if(elapsed > std::chrono::seconds(1)) {
fps = counter / elapsed.count();
counter = 0;
startTime = currentTime;
}
std::shared_ptr<dai::ImgFrame> inRgb = rgbQueue->get<dai::ImgFrame>();
std::shared_ptr<dai::ImgFrame> inDepth = depthQueue->get<dai::ImgFrame>();
std::shared_ptr<dai::ImgDetections> inDet = detectQueue->get<dai::ImgDetections>();
std::shared_ptr<dai::ImgFrame> ImgFrame = passthQueue->get<dai::ImgFrame>();
cv::Mat frame = inRgb->getCvFrame();
cv::Mat src = ImgFrame->getCvFrame();
cv::Mat depthFrameColor;
cv::Mat depthFrame = inDepth->getFrame();
cv::normalize(depthFrame, depthFrameColor, 255, 0, cv::NORM_INF, CV_8UC1);
cv::equalizeHist(depthFrameColor, depthFrameColor);
cv::applyColorMap(depthFrameColor, depthFrameColor, cv::COLORMAP_HOT);
inDet = detectQueue->get<dai::ImgDetections>();
if(inDet) {
detections = inDet->detections;
for(auto& detection : detections) {
int x1 = detection.xmin * src.cols;
int y1 = detection.ymin * src.rows;
int x2 = detection.xmax * src.cols;
int y2 = detection.ymax * src.rows;
uint32_t labelIndex = detection.label;
std::string labelStr = std::to_string(labelIndex);
if(labelIndex < labelMap.size()) {
labelStr = labelMap[labelIndex];
}
cv::putText(src, labelStr, cv::Point(x1 + 10, y1 + 20), cv::FONT_HERSHEY_TRIPLEX, 0.5, 255);
std::stringstream confStr;
confStr << std::fixed << std::setprecision(2) << detection.confidence * 100;
cv::putText(src, confStr.str(), cv::Point(x1 + 10, y1 + 40), cv::FONT_HERSHEY_TRIPLEX, 0.5, 255);
cv::rectangle(src, cv::Rect(cv::Point(x1, y1), cv::Point(x2, y2)), color, cv::FONT_HERSHEY_SIMPLEX);
// 1920*1080
//cv::rectangle(depthFrameColor, cv::Rect(cv::Point(x1, y1), cv::Point(x2, y2)), color, cv::FONT_HERSHEY_SIMPLEX);
int top_left_x = detection.xmin * frame.cols;
int top_left_y = detection.ymin * frame.rows;
int bottom_right_x = detection.xmax * frame.cols;
int bottom_right_y = detection.ymax * frame.rows;
// 最值限定
top_left_x = top_left_x < 0 ? 0 : top_left_x;
bottom_right_x = bottom_right_x > frame.cols - 1 ? frame.cols - 1 : bottom_right_x;
top_left_y = top_left_y < 0 ? 0 : top_left_y;
bottom_right_y = bottom_right_y > frame.rows - 1 ? frame.rows - 1 : bottom_right_y;
topLeft.x = top_left_x;
topLeft.y = top_left_y;
bottomRight.x = bottom_right_x;
bottomRight.y = bottom_right_y;
// 测距模块推送实际像素大小的ROI
config.roi = dai::Rect(topLeft, bottomRight);
dai::SpatialLocationCalculatorConfig cfg;
cfg.addROI(config);
spatialCalcConfigInQueue->send(cfg);
std::vector<dai::SpatialLocations> spatialData = spatialCalcQueue->get<dai::SpatialLocationCalculatorData>()->getSpatialLocations();
for (auto &depthData : spatialData) {
auto roi = depthData.config.roi;
roi = roi.denormalize(depthFrameColor.cols, depthFrameColor.rows);
auto xmin = (int) roi.topLeft().x;
auto ymin = (int) roi.topLeft().y;
auto xmax = (int) roi.bottomRight().x;
auto ymax = (int) roi.bottomRight().y;
// 最值限定
// xmin = xmin < 0 ? 0 : xmin;
// xmax = xmax > frame.cols - 1 ? frame.cols - 1 : xmax;
// ymin = ymin < 0 ? 0 : ymin;
// ymax = ymax > frame.rows - 1 ? frame.rows - 1 : ymax;
auto coords = depthData.spatialCoordinates;
auto distance = std::sqrt(coords.x * coords.x + coords.y * coords.y + coords.z * coords.z);
auto fontType = cv::FONT_HERSHEY_TRIPLEX;
std::stringstream rgb_depthX, depthX, rgb_depthX_;
rgb_depthX << "X: " << (int) coords.x << " mm";
rgb_depthX_.precision(2);
rgb_depthX_ << "dis: " << std::fixed << static_cast<float>(distance) << " mm";
cv::rectangle(frame,
cv::Rect(cv::Point(xmin, ymin), cv::Point(xmax, ymax)),
color,
fontType);
cv::putText(frame, rgb_depthX_.str(), cv::Point(xmin + 10, ymin - 20),
fontType,
0.5, color1);
cv::putText(frame, rgb_depthX.str(), cv::Point(xmin + 10, ymin + 20),
fontType,
0.5, color1);
std::stringstream rgb_depthY, depthY;
rgb_depthY << "Y: " << (int) coords.y << " mm";
cv::putText(frame, rgb_depthY.str(), cv::Point(xmin + 10, ymin + 35),
fontType,
0.5, color1);
std::stringstream rgb_depthZ, depthZ;
rgb_depthZ << "Z: " << (int) coords.z << " mm";
cv::putText(frame, rgb_depthZ.str(), cv::Point(xmin + 10, ymin + 50),
fontType,
0.5, color1);
cv::rectangle(depthFrameColor,
cv::Rect(cv::Point(xmin, ymin), cv::Point(xmax, ymax)),
color,
fontType);
depthX << "X: " << (int) coords.x << " mm";
cv::putText(depthFrameColor, depthX.str(), cv::Point(xmin + 10, ymin + 20),
fontType, 0.5, color1);
depthY << "Y: " << (int) coords.y << " mm";
cv::putText(depthFrameColor, depthY.str(), cv::Point(xmin + 10, ymin + 35),
fontType, 0.5, color1);
depthZ << "Z: " << (int) coords.z << " mm";
cv::putText(depthFrameColor, depthZ.str(), cv::Point(xmin + 10, ymin + 50),
fontType, 0.5, color1);
}
}
std::stringstream fpsStr;
fpsStr << "NN fps: " << std::fixed << std::setprecision(2) << fps;
// printf("fps %f\n",fps);
cv::putText(src, fpsStr.str(), cv::Point(4, 22), cv::FONT_HERSHEY_TRIPLEX, 1,
cv::Scalar(0, 255, 0));
cv::putText(frame, fpsStr.str(), cv::Point(4, 22), cv::FONT_HERSHEY_TRIPLEX, 1,
cv::Scalar(0, 255, 0));
// Show the frame
// cv::imshow("src", src);
cv::imshow("frame", frame);
// cv::imshow("depth", depthFrameColor);
int key = cv::waitKey(1);
if(key == 'q' || key == 'Q' || key == 27) {
return 0;
}
}
}
}测试结果

参考文章
1. examples/Yolo/tiny_yolo.cpp · OAKChina/depthai-core - Gitee.com

















 1815
1815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









