






隐含马尔科夫模型(翻译)
介绍:
隐含马尔科夫模型被广泛用于科学,工程学以及其他领域。
定义:隐含马尔科夫模型(HMM)是有限状态机的一个变体,包含一系列隐含状态Q,和一个输出状态(Observation)O,传递概率矩阵(transition probabilities)A,混合概率矩阵B,以及初始化概率pi。当前状态是不可见的,相反,每个状态以恒定概率B产生一个输出状态B.通常状态Q,输出O,是默认的,所以一个HMM是一个三组元(A,B,pi)。
定义:隐含状态Q={q[i]},i= 1,2,….,N.
传递概率矩阵A = {a[i][j] = P(q[i] at t+1 | q[i] at t)}, 其中P(a|b)是关于b的条件概率,t=1,,,,T是时间。正式说,A是由状态q[i]到状态q[i+1]的概率。
观察序列O = {o[k]}, k = 1,…,M.
混合概率矩阵 B = {b[i][o[k]] = P(o[k] | q[i])}.
初始状态概率 pi = {p[i] = P(q[i] at t = 1)}.
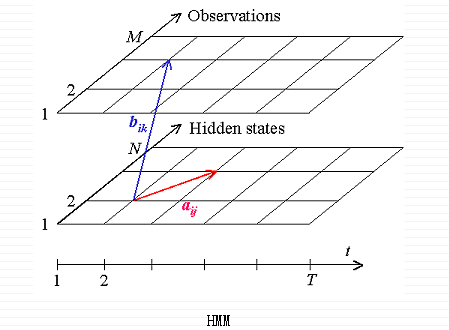
这个数学模型被一系列参数定义Λ = {A,B,pi}.
HMM模型解决的三个问题:
1.给定模型参数,计算特定输出序列的概率。这个问题用前向和后向算法解决。
2.给定模型参数,找到最大可能的隐含状态。用Viterbi算法解决。
3.给定输出序列,找到最大可能状态转移输出矩阵和输出概率。用BaumWelch算法解决。
前向算法:
定义α[t][i] = P(o[1], o[2], … ,o[t] | q[t] = q[i]).
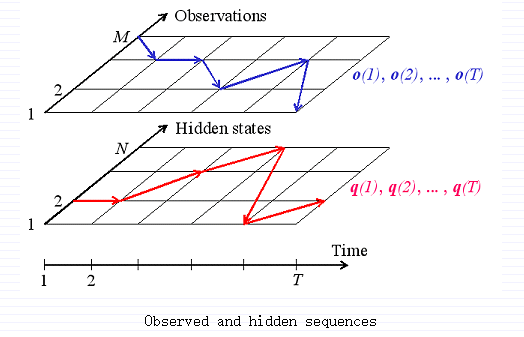
前向算法是一个递归算法,计算随着时间t增长的观察序列α[t][i]。首先,单符号序列的概率为初始第i个状态概率和第i个状态与o[1]的混合概率的乘积。然后递归就形成了。假设我们已经计算t时刻的α[t][i],为了计算α[t+1][j],我们把所有状态i的α[t][i]乘以a[i][j],然后加起来求和,最后乘以b[i][o[t+1]].
迭代这个过程,我们最终计算出α[T][i],然后把所有状态加起来,就得到了要求的概率。
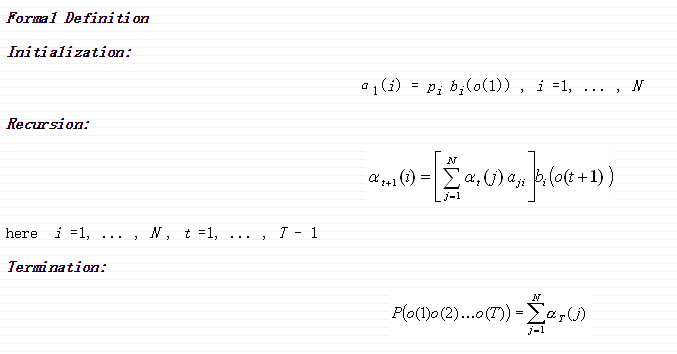
这里写代码片// Forward.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
typedef struct
{
int N;//隐藏状态项目
int M;//观察状态项目
double **A;//状态转移矩阵
double **B;//混淆矩阵
double *pi;//初始向量pi[1...N]
}HMM;
/*前向算法:
*phmm:已知HMM模型 T:观察符号序列长度
*O:观察序列 **alpha:局部概率
*pprob:最终的观察概率
*/
void Forward(HMM *phmm,int T, int *O,double **alpha, double *pprob)
{
int i,j;//状态索引
int t;//时间索引
double sum;//求局部概率的中间值
/*初始化:计算t = 1时刻所有状态的局部概率*/
for (i = 1;i <= phmm->N; i++)
{
alpha[1][i] = phmm->pi[i]*phmm->B[i][O[1]];
}
/*归纳:递归计算每个时间点,t = 2,...,T时的局部概率*/
for (t = 1;t < T; t++)
{
for(j = 1; j <= phmm->N; j++)
{
sum = 0.0;
for(i = 1;i <= phmm->N; i++)
{
sum += alpha[t][i]*(phmm->A[i][j]);
}
alpha[t+1][j] = sum*(phmm->B[j][O[t+1]]);
}
}
/*终止:观察序列的概率等于T时刻所有局部概率之和*/
*pprob = 0.0;
for(i = 1;i <= phmm->N; i++)
*pprob += alpha[T][i];
}
int _tmain(int argc, _TCHAR* argv[])
{
return 0;
}
后向算法:
以同样的方式,我们介绍一种对应的后向变量β[t][i]作为由t时刻状态q[i]所产生的局部观察序列o[t+1]到序列结束的条件概率。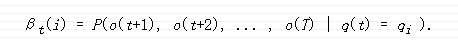
后向算法计算是后向变量沿着观察序列向后递归。后向算法用于计算由HMM模型产生的观察序列的概率,但是后面可以看到,前向-后向算法广泛的用于寻找合适的状态序列和估计HMM模型参数。
初始化: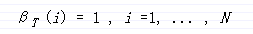
通过上面的定义,β[T][i]不存在,这是一个下面递归算法的关于t = T是的假设。
递归: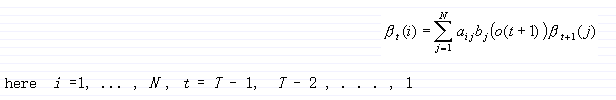
结果:
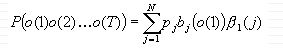
易知,前向算法和后向算法必须得到相同的概率P(O) = P(o(1),o(2),o(3),….,o(T)).
解码:
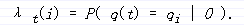
容易得出
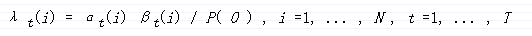
在每个时刻,我们选出q(t),使得λ[t][i]取最大值。
q(t) = arg max{λ[t][i]}
Viterbi算法:
Viterbi算法选择最好的状态序列使得由观察序列到状态序列的可能性最大。
令δ[t][i]为长度为t,以q[i]结束的状态序列,并且产生给定的观察序列的所有状态序列组合中概率最大序列的概率。
即: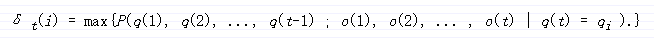
Viterbi算法是一个动态算法,和前向算法相近,但有两点不同:
1.Viterbi算法采用了递归以及最终一步的最大值
2.Viterbi算法保持跟踪使δ[t][i]最大的t 和 i,并保存他们到一个N*T的矩阵中,这个矩阵被用于在backtracking环节取回合适的状态序列。
初始化:
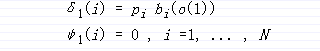
递归:
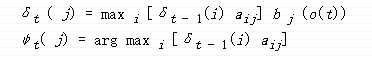
最终:
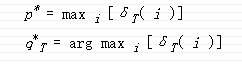
路径追溯:
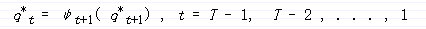
// Viterbi.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
typedef struct
{
int N;//隐藏状态项目
int M;//观察状态项目
double **A;//状态转移矩阵
double **B;//混淆矩阵
double *pi;//初始向量pi[1...N]
}HMM;
void Viterbi(HMM *phmm, int T, int *O, double **delta, int **psi,int *q, double *pprob)
{
int i,j;
int t;
int maxvalind;
double maxval,val;
//初始化
for (i = 1;i <= phmm->N; i++)
{
delta[1][i] = phmm->pi[i]*(phmm->B[i][O[1]]);
psi[1][i] = 0;
}
//递归
for(t = 2;t <= T;t++)
{
for(j = 1;j <= phmm->N; j++)
{
maxval = 0.0;
maxvalind = 1;
for (i = 1;i <= phmm->N; i++)
{
val = delta[t-1][i]*(phmm->A[i][j]);
if(val > maxval)
{
maxval = val;
maxvalind = i;
}
}
delta[t][j] = maxval*(phmm->B[j][O[t]]);
psi[t][j] = maxvalind;
}
}
//终结
*pprob = 0.0;
q[T] = 1;
for(i = 1;i <= phmm->N; i++)
{
if(delta[T][i] > *pprob)
{
*pprob = delta[T][i];
q[T] = i;
}
}
//路径回溯
for(t = T-1;t >= 1;t--)
q[t] = psi[t+1][q[t+1]];
}
int _tmain(int argc, _TCHAR* argv[])
{
return 0;
}
EM算法(Expectation-Maximization):
直观的理解EM算法,它可以被看做一个逐次逼近算法:事先并不知道模型的参数,可以随机的选择一套参数或者事先粗略的给定某个初始参数λ0,确定出对应于这组参数的可能的状态,计算每个训练样本的可能结果的概率,在当前的状态下再由样本对参数修正,循环直至某个收敛条件满足为止,就可以使得模型的参数逐渐逼近真实参数。
前向-后向算法(Forward-backward algorithm)
又称Baum-Welch算法
首先定义两个变量。给定观察序列O及隐马尔科夫模型Λ,定义t时刻位于隐藏状态Q[i]的概率变量为:
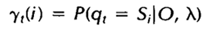
根据前向变量和后向变量的定义,我们可以很容易将上式表示为: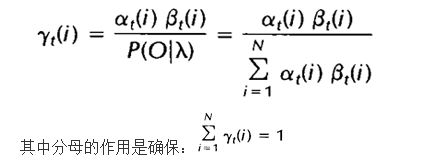
给定观察序列O及隐马尔科夫模型Λ,定义t时刻隐藏状态q[i]及t+1时刻隐藏状态q[j]的概率变量为:
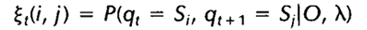
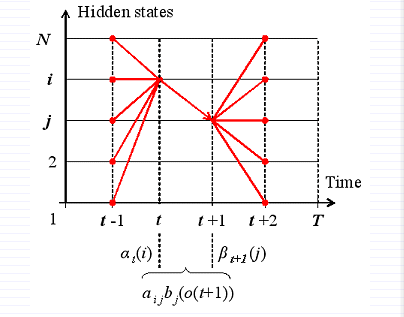
该变量可以由前向、后向变量表示:

如果对于时间轴t上的所有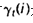
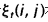

利用这两个变量及其期望值来重新估计隐马尔科夫模型参数pi,A,B:

在上面式子中,选取t时刻状态为q[i],观察值为o[k]的λ值相加。如果我们定义当前的HMM模型为fb13,那么可以利用该模型计算上面三个式子的右端;我们再定义重新估计的HMM模型为fb14,那么上面三个式子的左端就是重估的HMM模型参数。Baum及他的同事在70年代证明了fb15因此如果我们迭代地的计算上面三个式子,由此不断地重新估计HMM的参数,那么在多次迭代后可以得到的HMM模型的一个最大似然估计。不过需要注意的是,前向-后向算法所得的这个结果(最大似然估计)是一个局部最优解。
#include "stdafx.h"
#include <stdlib.h>
#include "nrutil.h"
#include <math.h>
#define DELTA 0.001
typedef struct {
int N; /* number of states; Q={1,2,...,N} */
int M; /* number of observation symbols; V={1,2,...,M}*/
double **A; /* A[1..N][1..N]. a[i][j] is the transition prob
of going from state i at time t to state j
at time t+1 */
double **B; /* B[1..N][1..M]. b[j][k] is the probability of
of observing symbol k in state j */
double *pi; /* pi[1..N] pi[i] is the initial state distribution. */
} HMM;
double *** AllocXi(int T, int N)
{
int t;
double ***xi;
xi = (double ***)malloc(T*sizeof(double **));
xi--;
for (t = 1; t <= T; t++)
xi[t] = dmatrix(1, N, 1, N);
return xi;
}
void ForwardWithScale(HMM *phmm, int T, int *O, double **alpha,
double *scale, double *pprob)
{
int i, j; /* state indices */
int t; /* time index */
double sum; /* partial sum */
/* 1. Initialization */
scale[1] = 0.0;
for (i = 1; i <= phmm->N; i++) {
alpha[1][i] = phmm->pi[i]* (phmm->B[i][O[1]]);
scale[1] += alpha[1][i];
}
for (i = 1; i <= phmm->N; i++)
alpha[1][i] /= scale[1];
/* 2. Induction */
for (t = 1; t <= T - 1; t++) {
scale[t+1] = 0.0;
for (j = 1; j <= phmm->N; j++) {
sum = 0.0;
for (i = 1; i <= phmm->N; i++)
sum += alpha[t][i]* (phmm->A[i][j]);
alpha[t+1][j] = sum*(phmm->B[j][O[t+1]]);
scale[t+1] += alpha[t+1][j];
}
for (j = 1; j <= phmm->N; j++)
alpha[t+1][j] /= scale[t+1];
}
/* 3. Termination */
*pprob = 0.0;
for (t = 1; t <= T; t++)
*pprob += log(scale[t]);
}
void BackwardWithScale(HMM *phmm, int T, int *O, double **beta,
double *scale, double *pprob)
{
int i, j; /* state indices */
int t; /* time index */
double sum;
/* 1. Initialization */
for (i = 1; i <= phmm->N; i++)
beta[T][i] = 1.0/scale[T];
/* 2. Induction */
for (t = T - 1; t >= 1; t--) {
for (i = 1; i <= phmm->N; i++) {
sum = 0.0;
for (j = 1; j <= phmm->N; j++)
sum += phmm->A[i][j] *
(phmm->B[j][O[t+1]])*beta[t+1][j];
beta[t][i] = sum/scale[t];
}
}
}
void ComputeGamma(HMM *phmm, int T, double **alpha, double **beta,
double **gamma)
{
int i,j;
int t;
double denominator;
for(t = 1;t <= T;t++)
{
denominator = 0.0;
for(j = 1;j <= phmm->N; j++)
{
gamma[t][j] = alpha[t][j]*beta[t][j];
denominator += gamma[t][j];
}
for (i = 1; i <= phmm->N; i++)
gamma[t][i] = gamma[t][i]/denominator;
}
}
void ComputeXi(HMM* phmm, int T, int *O, double **alpha, double **beta,
double ***xi)
{
int i, j;
int t;
double sum;
for (t = 1; t <= T - 1; t++) {
sum = 0.0;
for (i = 1; i <= phmm->N; i++)
for (j = 1; j <= phmm->N; j++) {
xi[t][i][j] = alpha[t][i]*beta[t+1][j]
*(phmm->A[i][j])
*(phmm->B[j][O[t+1]]);
sum += xi[t][i][j];
}
for (i = 1; i <= phmm->N; i++)
for (j = 1; j <= phmm->N; j++)
xi[t][i][j] /= sum;
}
}
void FreeXi(double *** xi, int T, int N)
{
int t;
for (t = 1; t <= T; t++)
free_dmatrix(xi[t], 1, N, 1, N);
xi ++;
free(xi);
}
void BaumWelch(HMM *phmm, int T, int *O,double **alpha, double **beta,
double **gamma, int *pniter,
double *plogprobinit, double *plogprobfinal)
{
int i, j, k;
int t, l = 0;
double logprobf, logprobb, threshold;
double numeratorA, denominatorA;
double numeratorB, denominatorB;
double ***xi, *scale;
double delta, deltaprev, logprobprev;
deltaprev = 10e-70;
xi = AllocXi(T,phmm->N);
scale = dvector(1,T);
ForwardWithScale(phmm, T, O, alpha, scale, &logprobf);
*plogprobinit = logprobf; /* log P(O |intial model) */
ComputeGamma(phmm, T, alpha, beta, gamma);
ComputeXi(phmm, T, O, alpha, beta, xi);
logprobprev = logprobf;
do {
/* reestimate frequency of state i in time t=1 */
for (i = 1; i <= phmm->N; i++)
phmm->pi[i] = .001 + .999*gamma[1][i];
/* reestimate transition matrix and symbol prob in
each state */
for (i = 1; i <= phmm->N; i++) {
denominatorA = 0.0;
for (t = 1; t <= T - 1; t++)
denominatorA += gamma[t][i];
for (j = 1; j <= phmm->N; j++) {
numeratorA = 0.0;
for (t = 1; t <= T - 1; t++)
numeratorA += xi[t][i][j];
phmm->A[i][j] = .001 +
.999*numeratorA/denominatorA;
}
denominatorB = denominatorA + gamma[T][i];
for (k = 1; k <= phmm->M; k++) {
numeratorB = 0.0;
for (t = 1; t <= T; t++) {
if (O[t] == k)
numeratorB += gamma[t][i];
}
phmm->B[i][k] = .001 +
.999*numeratorB/denominatorB;
}
}
ForwardWithScale(phmm, T, O, alpha, scale, &logprobf);
BackwardWithScale(phmm, T, O, beta, scale, &logprobb);
ComputeGamma(phmm, T, alpha, beta, gamma);
ComputeXi(phmm, T, O, alpha, beta, xi);
/* compute difference between log probability of
two iterations */
delta = logprobf - logprobprev;
logprobprev = logprobf;
l++;
}
while (delta > DELTA);/*if log probability does nit change much,exit*/
*pniter = l;
*plogprobfinal = logprobf; /* log P(O|estimated model) */
FreeXi(xi, T, phmm->N);
free_dvector(scale, 1, T);
}
int _tmain(int argc, _TCHAR* argv[])
{
return 0;
}
引用链接
(http://www.52nlp.cn/hmm-learn-best-practices-seven-forward-backward-algorithm-4)
(http://www.shokhirev.com/nikolai/abc/alg/hmm/hmm.html(http://www.shokhirev.com/nikolai/abc/alg/hmm/hmm.html)















 2612
2612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









