







第二章第二节(中) 参考线算法

如上图,上一节学的平滑算法只是一种(Fem smoother)
他的优点也是因为缺点;也有其他算法他可以保证曲率连续,是因为他还考虑的每个点的一阶导数,甚至二阶导数,但这个计算量就很大

上一节说的是找投影点,其实也可以找匹配点,因为这个只是为了再往前150m,往后30m,这样就可以,差的不多,没啥影响
上一节已经做了(3)Fem Smooth,现在做(1-2),目标是快

快的方法1)减少规划频率;

快的方法2)快速找到算法的匹配点;

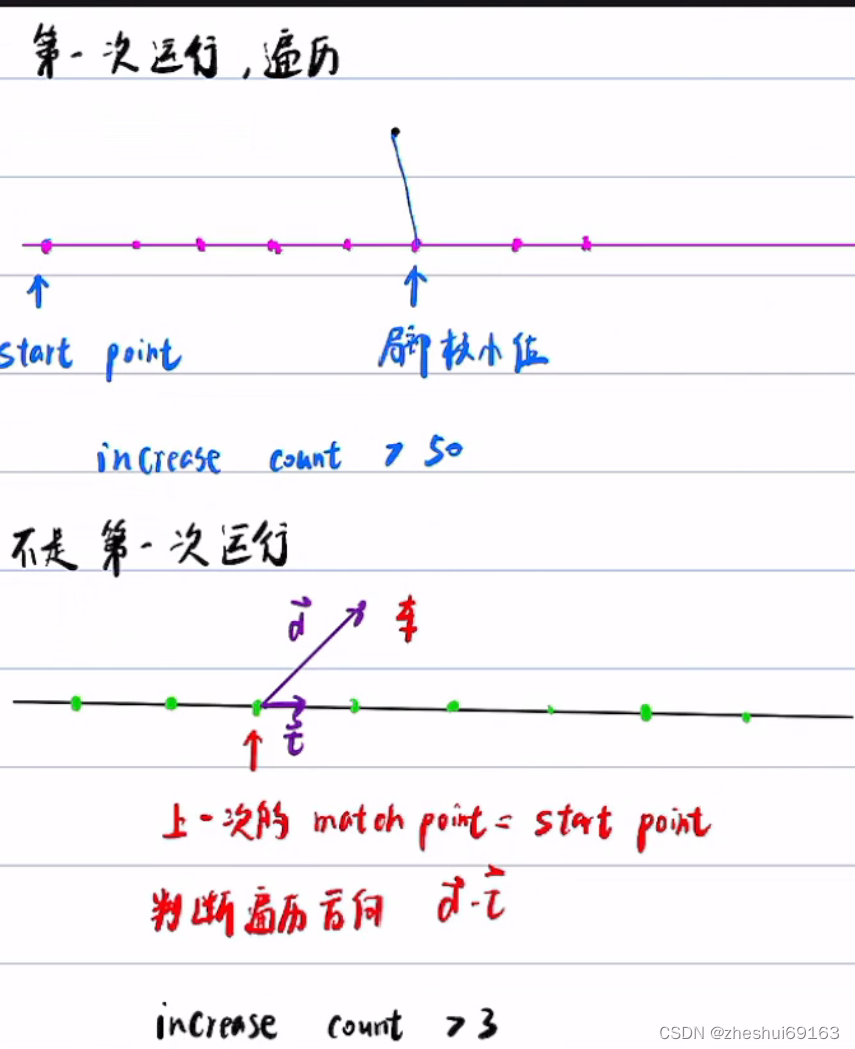
在这个过程中还需要判断车的运动方向(因为优化后的遍历方向要和车速度方向一致)设向量d是当前周期下的车与上个周期匹配点组成的向量;tau是上个匹配点的方向向量(匹配点还有方向向量??是根据原始全局轨迹规划来的吗,全局轨迹规划出的路线还有方向?????这个方向是啥???有啥含义,能反映什么 按照第三节的说法,tau就是参考轨迹的运动方向,那车肯定向前啊,还能向后不成?? 回答:tau就是参考轨迹的运动方向,理论上车运动的方向一定和tau一致,所以车匹配点的查找直接向前就行了,这里应该是为严谨???不对啊,如果是这样车往左走,车确定匹配点之后再参考点和之前做的重复啦,全部重复。。。。。 补充:参考轨迹的坐标系就是车辆在当前规划周期内初始位置的x-y方向,所以这个轨迹一点过坐标系原点,且原点处轨迹的导数为0,哇塞,每个周期下坐标系都不一样,对于一开始的global轨迹,每个周期下都要坐标系转换 啧啧
如下若点乘之后值特小,就相当于垂直了,那么就可以直接用
==经过和张老师的讨论:老王讲错啦,老王这个情况除非车倒车了,并且倒车这个行为不在全局规划路径点的考虑范围内! 就算车掉头,会导致以下的点乘为负值,仍然应该向前搜索,毕竟路径向前啊!! ==

这个方法的本质有点像梯度下降法
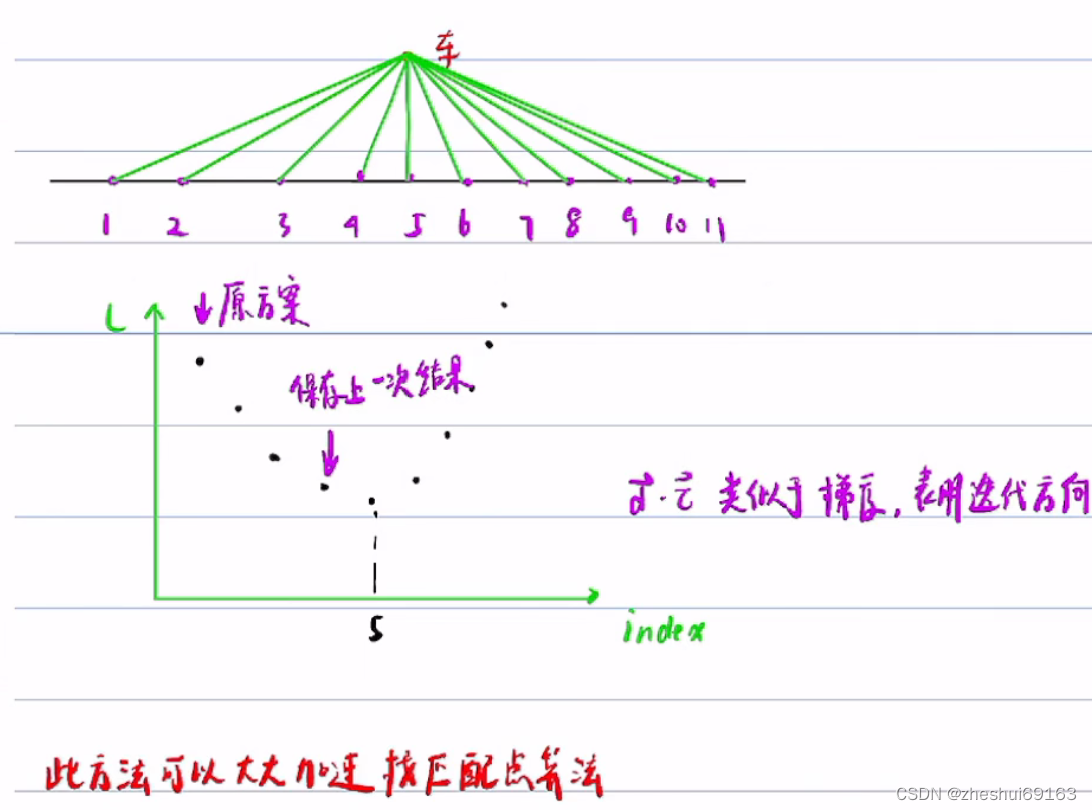
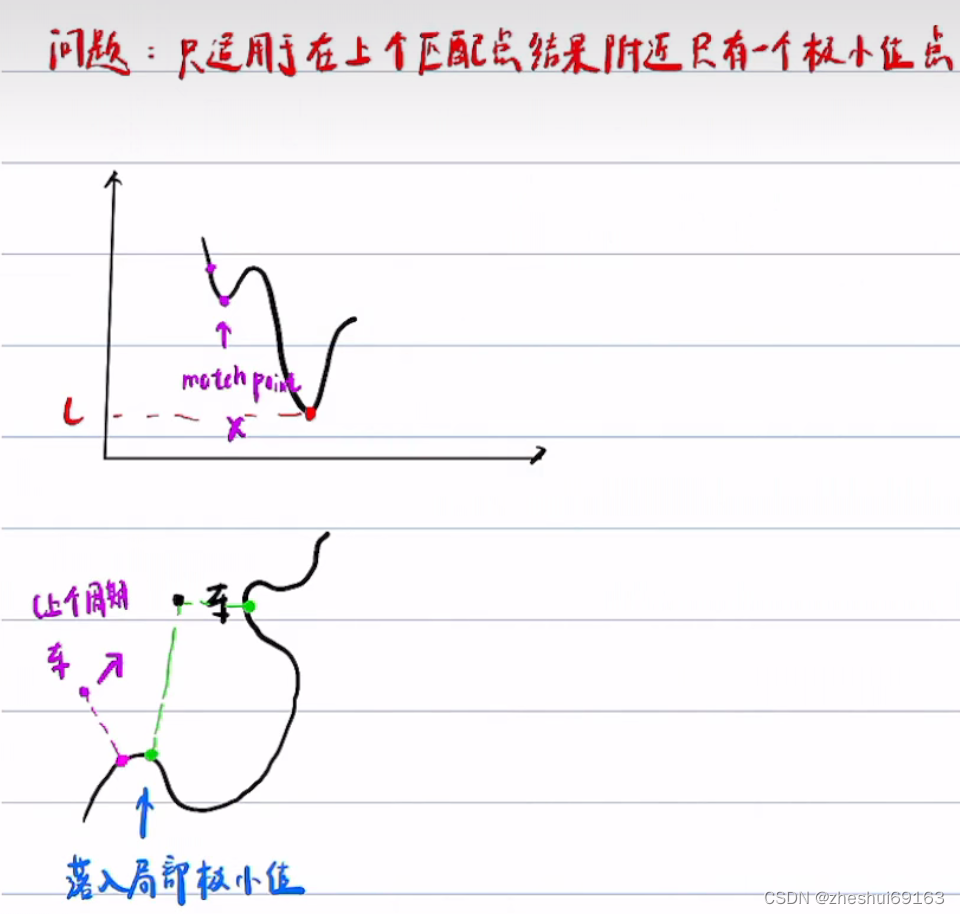

以防万一:用increase count变量记录 l 增加的次数,设定阈值如10,若在找到极小值点之后往后再10个点的l一直是增加的,那就基本可以说明之前找到极小值点就是全局最优的

如果另外找到了极小值,同样存储起来,继续找,直到连续检查10个点l都在增大,最后把存储的极值点比较下,找最小的:

具体在github算法里面,第一次从起始点遍历找匹配点的时候,谨慎一点,阈值取50;后面阈值就可以取3
快的方法3)处理点不够的情况;
因为要往后找30m,往前150m,如果前/后点不够,则反向取,保证总距离一致=180m就行:这是为了保证优化变量的个数不变(n个xi yi),则矩阵的大小不变,二次规划更好计算

快的方法4)轨迹拼接;
因为每次根据导航生成参考线,都有180m,规划周期又很小,在一个周期之后车的位置变化不大,这样再180m,和之前的180m重复就很多,我们只需要考虑没有算过的参考线,然后拼接上去。(我不太能理解哈,干嘛要算这么长,搭配着速度和规划周期算不香吗,甚至如果车是匀速,都可以不拼接了。 这里的拼接应该也需要考虑拼接处的车速方向
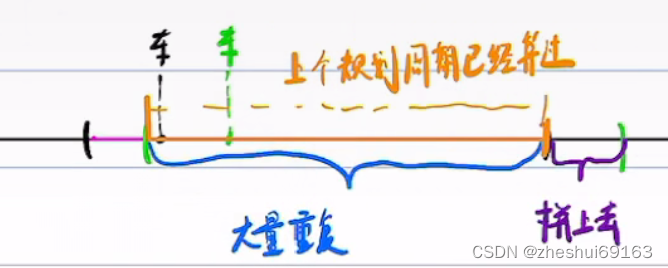
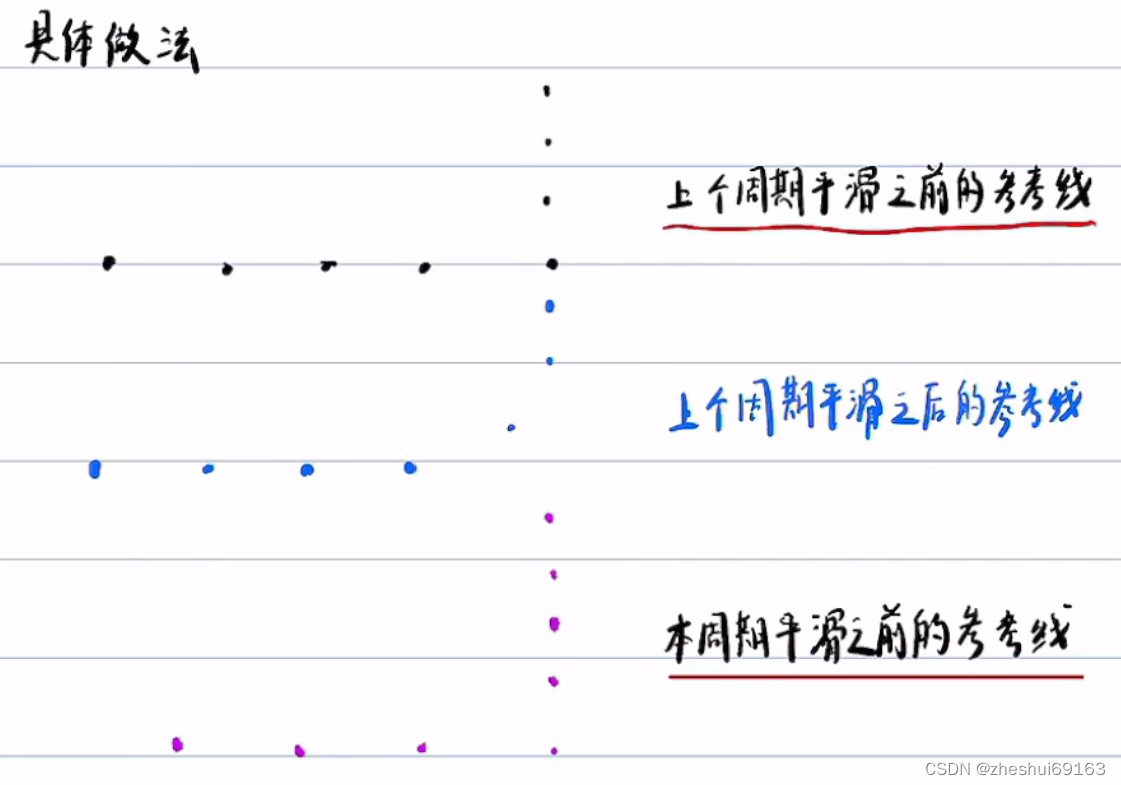
注意比较的是两个周期内的未平滑的点,这样可以省略一些点不用平滑(因为要对比是否一致,所以前一个周期的点也要用未平滑时的点,即紫色和黑色
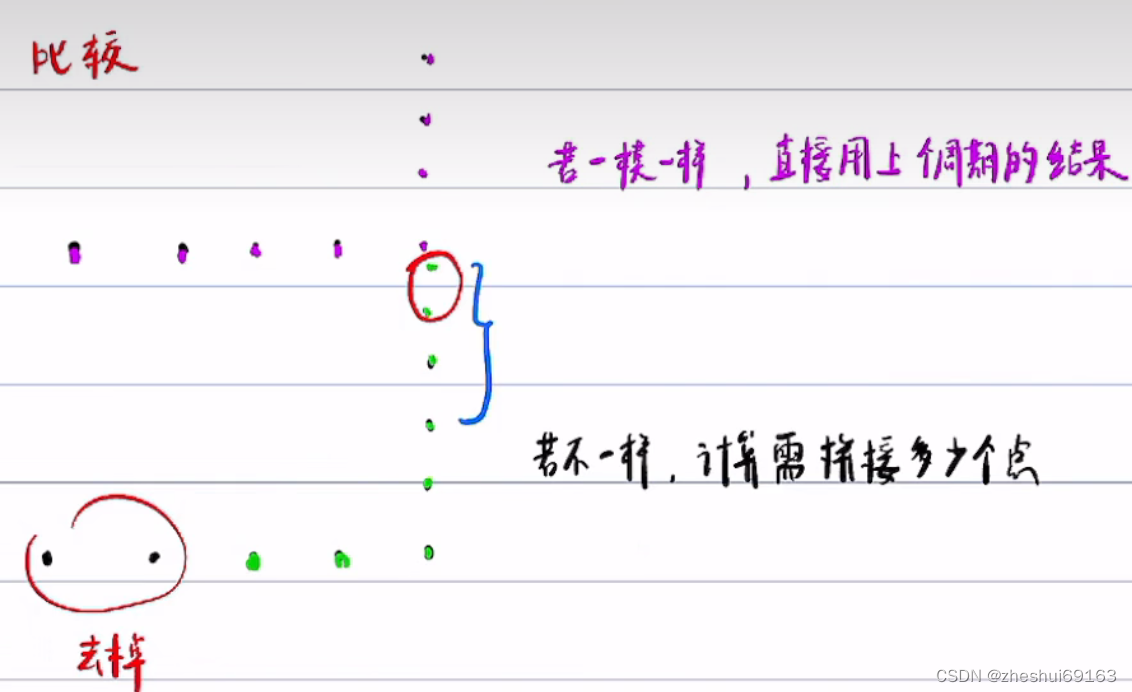
如上图,如果不一样,新规划的点前面多了2个,后面少了两个,则把上一次的后两个点去掉再拼接前面多的2个点。但是要注意前面两个点在二次规划的时候要借助往后延的两个点,因为Fem Smooth二次规划需要三个点!延的两个点只是作为辅助,并不是真的要改变他们的值
这里的二次规划的函数和之前的差异
1.规模上小一点,不再是n
2.约束上如下















 1258
1258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









