一、Qwen2.5-VL介绍
Qwen2.5-VL是阿里云通义千问旗舰视觉语言模型,专攻复杂视觉-语言任务,基于先进Transformer架构,擅长图像描述、视觉问答及多模态理解。经大规模多模态数据预训练,模型具备强大场景解析与跨模态推理能力,支持文档解析、长视频理解等复杂任务
1.1 Qwen2.5-VL 的主要特点
- 感知更丰富的世界:Qwen2.5-VL 不仅擅长识别常见物体,如花、鸟、鱼和昆虫,还能够分析图像中的文本、图表、图标、图形和布局。
- Agent:Qwen2.5-VL 直接作为一个视觉 Agent,可以推理并动态地使用工具,初步具备了使用电脑和使用手机的能力。
- 理解长视频和捕捉事件:Qwen2.5-VL 能够理解超过 1 小时的视频,并且这次它具备了通过精准定位相关视频片段来捕捉事件的新能力。
- 视觉定位:Qwen2.5-VL 可以通过生成 bounding boxes 或者 points 来准确定位图像中的物体,并能够为坐标和属性提供稳定的 JSON 输出。
- 结构化输出:对于发票、表单、表格等数据,Qwen2.5-VL 支持其内容的结构化输出,惠及金融、商业等领域的应用。

1.2 Qwen2.5-VL模型性能
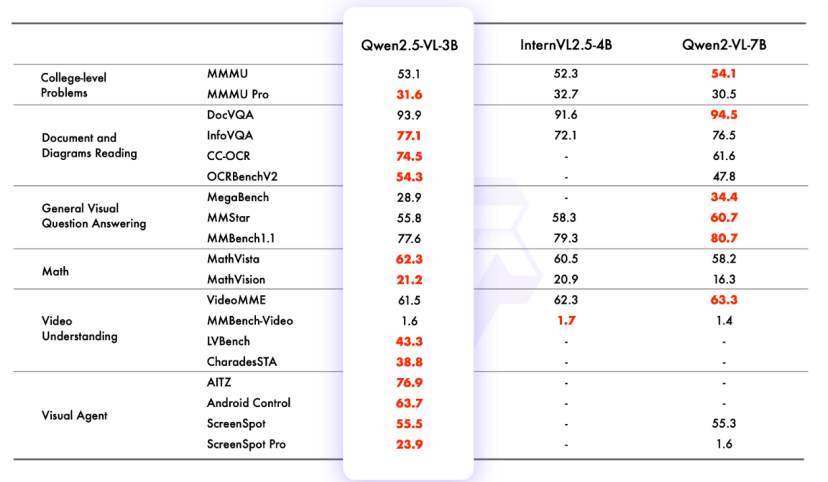
在旗舰模型 Qwen2.5-VL-72B-Instruct 的测试中,它在一系列涵盖多个领域和任务的基准测试中表现出色,包括大学水平的问题、数学、文档理解、视觉问答、视频理解和视觉 Agent。在较小的模型方面,Qwen2.5-VL-7B-Instruct 在多个任务中超越了 GPT-4o-mini,而 Qwen2.5-VL-3B 作为端侧 AI 的潜力股,甚至超越了之前版本 Qwen2-VL 的 7B 模型。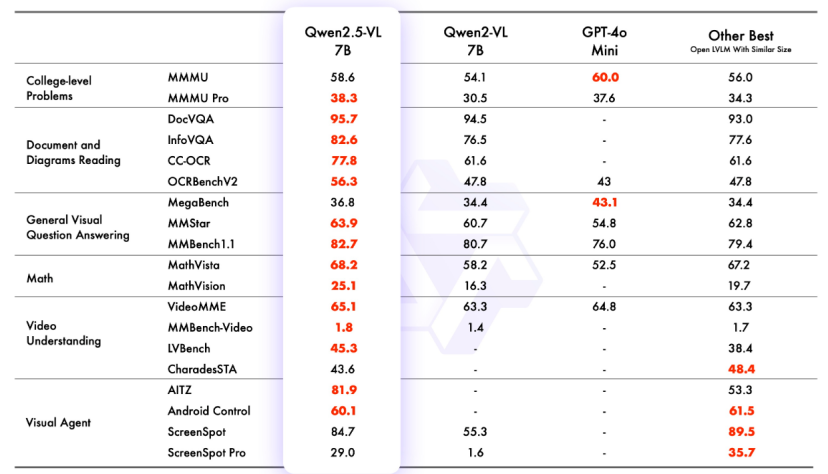
二、Jetson AGX Orin 介绍
Jetson AGX Orin 模组可提供高达 275 TOPS 的 AI 性能,功率可在 15 瓦到 60 瓦之间进行配置。此模组的外形规格与 Jetson AGX Xavier 相同,但其性能可高达后者的 8 倍以上。Jetson AGX Orin 有 64GB、32GB 和工业版三个版本。
- Jetson AGX Orin 64GB 最高算力为 275 TOPS,功率配置范围 15W 至 60W。
- Jetson AGX Orin 32GB 最高算力为 200 TOPS,功率配置范围 15W 至 40W。
2.1 本次部署硬件信息
本次部署采用内存为32GB的jetson AGX Orin,系统版本36.4.3,jetpack版本6.2,cuda版本12.6.68,显卡驱动版本540.4.0。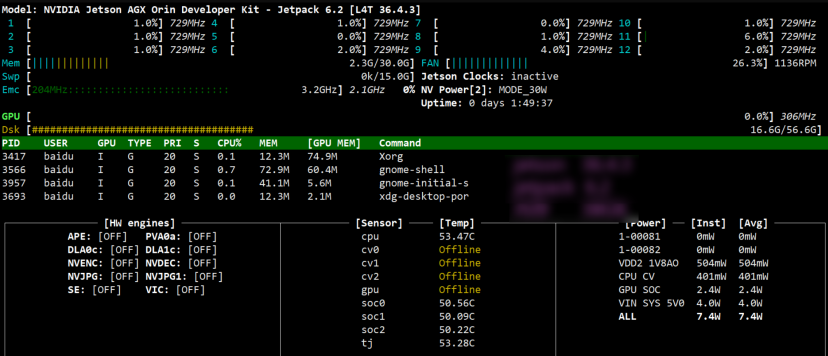
硬件资源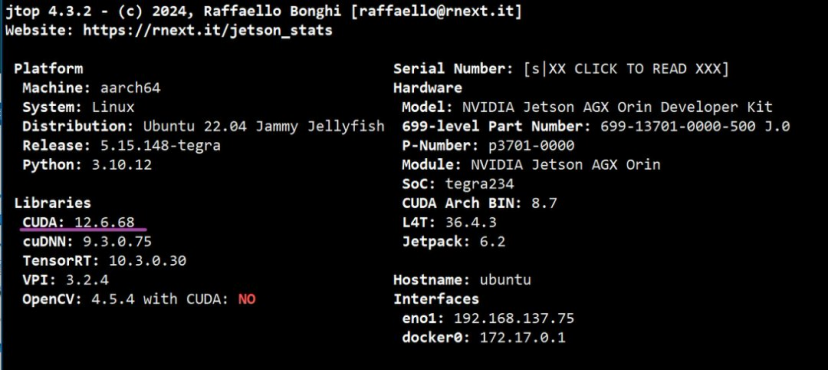
系统软件版本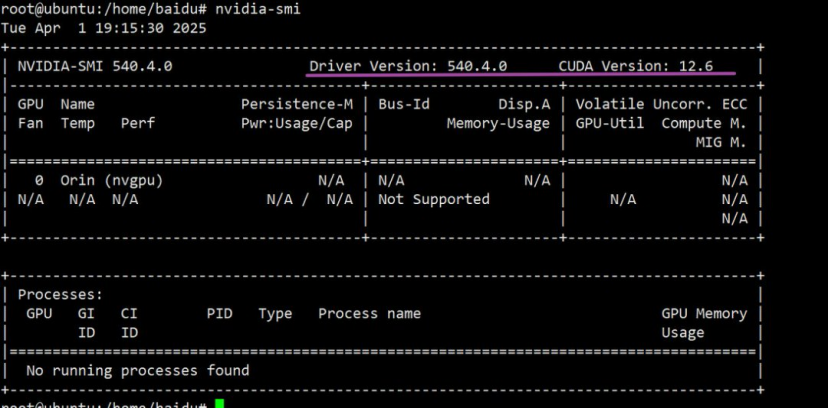
显卡驱动版本
三、部署步骤
(1)连接互联网
Jetson Agx orin开盒既含有最新的操作系统,连接显示器、鼠标、键盘、网线,完成上网。下面的命令通过显示器桌面终端完成。
(2)安装git加速插件
| Plain Text
sudo su
apt install git-lfs
git lfs install |
(3)拉取Qwen2.5-vl-3B/7B模型
| Plain Text
git clone https://hf-mirror.com/Qwen/Qwen2.5-VL-3B-Instruct
git clone https://hf-mirror.com/Qwen/Qwen2.5-VL-7B-Instruct |
(4)安装虚拟环境
| bash
wget https://repo.anaconda.com/archive/Anaconda3-2024.10-1-Linux-aarch64.sh
bash Anaconda3-2024.10-1-Linux-aarch64.sh
source ~/.bashrc
conda create -n vllm_qwen2_5_vl_p310 python=3.10 -y
conda activate vllm_qwen2_5_vl_p310
export PATH=/usr/local/cuda-12.6/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.6/lib64:$LD_LIBRARY_PATH |
(5)下载torch、torchaudio等软件
| Plain Text
wget https://pypi.jetson-ai-lab.dev/jp6/cu126/+f/6cc/6ecfe8a5994fd/torch-2.6.0-cp310-cp310-linux_aarch64.whl
wget https://pypi.jetson-ai-lab.dev/jp6/cu126/+f/dda/ce98dc7d89263/torchaudio-2.6.0-cp310-cp310-linux_aarch64.whl
wget https://pypi.jetson-ai-lab.dev/jp6/cu126/+f/aa2/2da8dcf4c4c8d/torchvision-0.21.0-cp310-cp310-linux_aarch64.whl
wget https://pypi.jetson-ai-lab.dev/jp6/cu126/+f/652/25e6674790fda/vllm-0.7.4+cu126-cp310-cp310-linux_aarch64.whl
wget https://pypi.jetson-ai-lab.dev/jp6/cu126/+f/15d/c12c4bbdf0380/triton-3.3.0-cp310-cp310-linux_aarch64.whl
wget https://pypi.jetson-ai-lab.dev/jp6/cu126/+f/0c4/2995b499445fe/xformers-0.0.30+56be3b5.d20250310-cp310-cp310-linux_aarch64.whl
pip install torch-2.6.0-cp310-cp310-linux_aarch64.whl
pip install torchaudio-2.6.0-cp310-cp310-linux_aarch64.whl
pip install torchvision-0.21.0-cp310-cp310-linux_aarch64.whl
pip install "numpy<2"
pip install vllm-0.7.4+cu126-cp310-cp310-linux_aarch64.whl
pip install triton-3.3.0-cp310-cp310-linux_aarch64.whl
pip install xformers-0.0.30+56be3b5.d20250310-cp310-cp310-linux_aarch64.whl
# 安装完成后,读取对应版本号如下
python3 -c "import torch; print(torch.__version__)"
# 获得torch版本为2.6.0
python3 -c "import torchvision; print(torchvision.__version__)"
# 获得torchvision版本为0.21.0
python3 -c "import torch; print(torch.version.cuda)"
# 获得cuda版本为12.6
python -c "import vllm; print(vllm.__version__)"
# 获得vllm版本为0.7.4 |
(6)使能剩余4核CPU和最高性能(可选)
| bash
echo 1 > /sys/devices/system/cpu/cpu8/online
echo 1 > /sys/devices/system/cpu/cpu9/online
echo 1 > /sys/devices/system/cpu/cpu10/online
echo 1 > /sys/devices/system/cpu/cpu11/online
mv /var/lib/nvpmodel/status /var/lib/nvpmodel/status_bak
vim /etc/nvpmodel.conf
#将< PM_CONFIG DEFAULT=N >中的N修改为0并保存,系统会进行重启操作
jetson_clocks |
(7)测试模型
修改测试代码demo.py中模型绝对路径MODEL_PATH(选择3B或7B的模型)。该demo是提供了一张互联网图片,让Qwen2.5-vl-3B描述一下图片。图片链接如下:https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg
| python
demo.py
#从 transformers 库中导入的用于条件生成任务的模型类Qwen2_5_VLForConditionalGeneration,专门针对 Qwen2.5-VL 模型。
#AutoProcessor类可以自动根据模型名称或路径加载对应的处理器,用于对输入数据进行预处理和后处理。
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
#process_vision_info类用于处理视觉信息,例如提取图像或视频的相关特征。
from qwen_vl_utils import process_vision_info
MODEL_PATH="/home/nvidia/qwen/Qwen2.5-VL-3B-Instruct"
#from_pretrained用于从预训练的模型权重文件中加载模型。
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
MODEL_PATH, #指定了本地模型文件所在的路径。
torch_dtype="auto", #自动选择合适的张量数据类型,以优化内存使用和计算效率。
device_map="auto", #自动将模型分配到可用的设备(如 GPU 或 CPU)上。
local_files_only=True #示只从本地加载模型文件,不尝试从远程仓库下载。
)
# 加载处理器,根据指定的模型路径加载对应的处理器。
processor = AutoProcessor.from_pretrained(MODEL_PATH)
messages = [
{
"role": "user", #表示消息的发送者是用户。
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{
"type": "text",
"text": "请描述一下图片."
},
],
}
]
# 预处理输入:预处理是指在将原始数据输入到模型之前对其进行的一系列处理操作。其目的是将原始数据转换为模型能够理解和处理的格式,同时提高数据的质量和可用性,从而提升模型的性能和效率。
#第一步:应用对话模板
# apply_chat_template根据对话模板对输入的消息进行处理,生成适合模型输入的文本。
text = processor.apply_chat_template(
messages,
tokenize=False, #表示不进行分词操作
add_generation_prompt=True #表示添加生成提示
)
#第二步:处理视觉信息
#process_vision_info处理消息中的视觉信息,返回图像和视频的输入数据。
image_inputs, video_inputs = process_vision_info(messages)
#第三步:分词和填充
#processor调用处理器对文本、图像和视频输入进行进一步处理,包括分词、填充等操作。
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True, #表示对输入进行填充,使所有输入序列长度一致。
return_tensors="pt", #表示返回 PyTorch 张量。
)
#将输入数据移动到与模型相同的设备上,确保计算可以正常进行。
inputs = inputs.to(model.device)
#模型推理,调用模型的生成方法,根据输入数据生成输出序列。
#**inputs 表示将输入数据作为关键字参数传递给 generate 方法。
#max_new_tokens=128 限制了生成的最大新令牌数。
generated_ids = model.generate(**inputs, max_new_tokens=128)
#后处理输出:后处理是指在模型输出结果之后对其进行的一系列处理操作。其目的是将模型输出的原始结果转换为人类可读的格式,同时对结果进行优化和调整,使其更符合实际需求。
#第一步:去除输入部分
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
#第二步:解码为文本
#batch_decode,将生成的 ID 序列解码为文本。
output_text = processor.batch_decode(
generated_ids_trimmed, #将生成的 ID 序列中输入部分的 ID 去除,只保留模型生成的部分。
skip_special_tokens=True, #表示跳过特殊令牌
clean_up_tokenization_spaces=False #表示不清理分词产生的空格。
)
#打印输出结果
print(output_text) |
| Plain Text
# 运行demo
python demp.py |
输出:
智宇辰科技:15652860510
























 1000
1000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









