






 本文介绍了时间注意力机制在深度学习中如何处理时序数据,特别是在视频处理中的应用。通过权重分配,模型能聚焦于关键帧,提高对任务重要信息的理解。文章还提供了基于PyTorch的示例代码来实现这一机制。
本文介绍了时间注意力机制在深度学习中如何处理时序数据,特别是在视频处理中的应用。通过权重分配,模型能聚焦于关键帧,提高对任务重要信息的理解。文章还提供了基于PyTorch的示例代码来实现这一机制。
时间注意力机制是什么
时间注意力机制是深度学习中用于处理时序数据的一种技术。它允许模型在处理序列数据时,对不同时间步的信息赋予不同的重要性或关注度。这个机制使得模型能够更有效地学习序列中不同部分的依赖关系和重要性,并根据需要调整其关注的焦点。
描述时间注意力机制的一种常见方法是使用基于注意力机制的循环神经网络(RNN)或者变种(比如长短期记忆网络 LSTM、门控循环单元 GRU 等)。在这些模型中,时间注意力机制通过学习权重来确定每个时间步上的输入的重要性,从而产生对应时间步的加权表示。
示例代码
这里提供一个简单的基于 Python 和 PyTorch 的时间注意力机制的示例代码。假设有一个输入序列 input_sequence,我们将利用注意力机制给每个时间步分配不同的权重,然后根据这些权重对输入序列进行加权求和,生成具有注意力加权的输出。
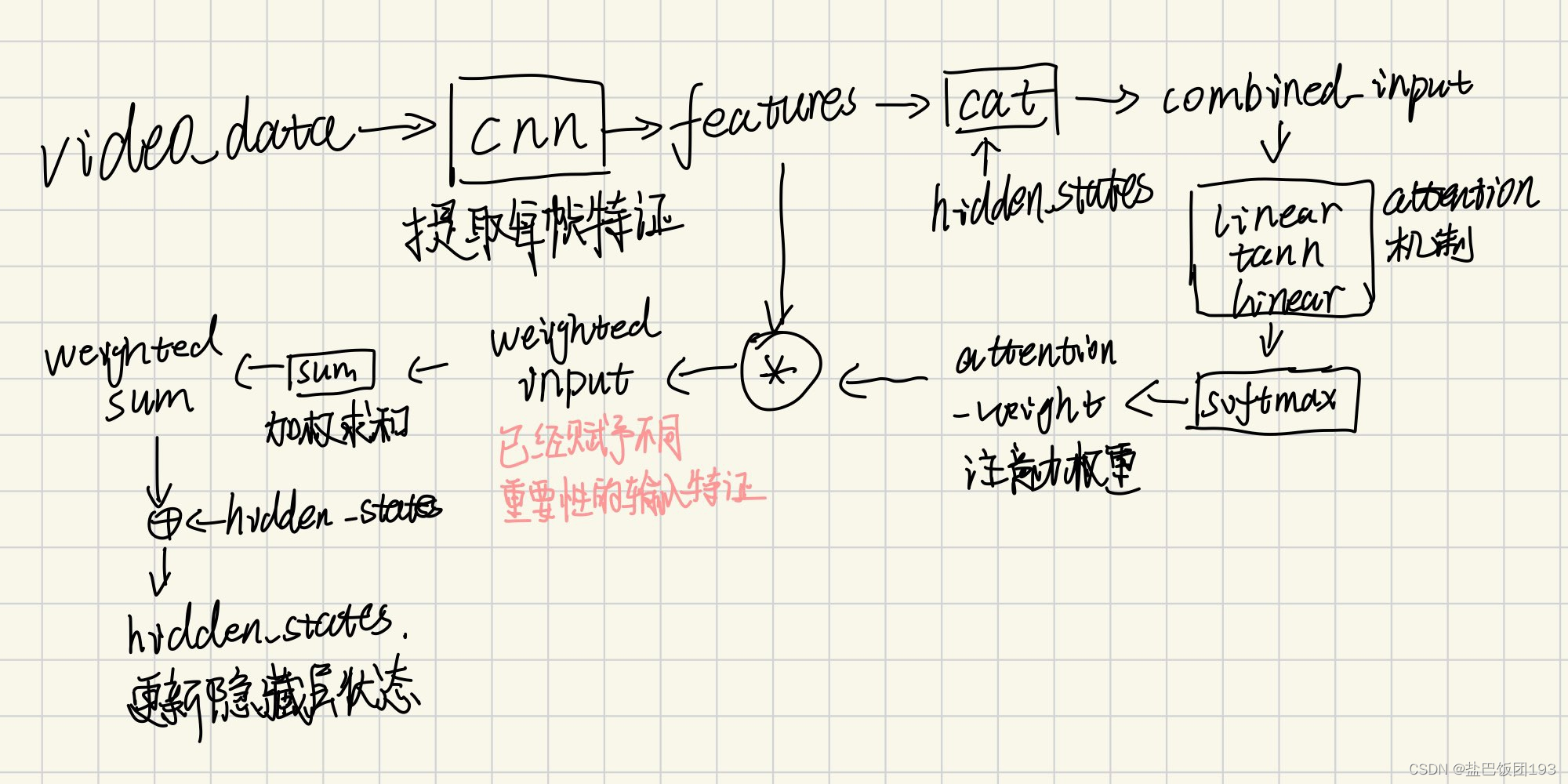
请注意,视频数据通常以帧序列的形式表示,每一帧都是图像。一个常见的方法是使用卷积神经网络(CNN)提取每个帧的特征,然后将这些特征序列输入到时间注意力机制中。
import torch
import torch.nn as nn
# 假设有一个视频数据集,每个视频由帧序列组成
# video_data 是一个形状为 (batch_size, num_frames, channels, height, width) 的张量
# 这里只是一个示例,实际应用中需要加载和准备真实的视频数据
class TimeAttentionVideo(nn.Module):
def __init__(self, input_channels, hidden_size):
super(TimeAttentionVideo, self).__init__()
self.input_channels = input_channels
self.hidden_size = hidden_size
# CNN 提取视频帧特征
self.cnn = nn.Sequential(
nn.Conv2d(input_channels, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
# 可根据需要添加更多的卷积层或其他层
)
# 时间注意力机制
self.attention = nn.Sequential(
nn.Linear(64 + hidden_size, hidden_size),
nn.Tanh(),
nn.Linear(hidden_size, 1)
)
self.softmax = nn.Softmax(dim=1) # 在时间维度上进行 softmax 操作
def forward(self, video_data):
batch_size, num_frames, channels, height, width = video_data.size()
video_data = video_data.view(batch_size * num_frames, channels, height, width)
# 提取每帧特征
features = self.cnn(video_data)
features = features.view(batch_size, num_frames, -1)
# 初始化隐藏状态
hidden_states = torch.zeros(batch_size, self.hidden_size).to(video_data.device)
# 对视频帧序列应用时间注意力机制
for t in range(num_frames):
combined_input = torch.cat((features[:, t, :], hidden_states), dim=1)
attention_weights = self.attention(combined_input)
attention_weights = self.softmax(attention_weights)
weighted_input = attention_weights * features[:, t, :]
weighted_sum = torch.sum(weighted_input, dim=1)
hidden_states = weighted_sum + hidden_states
return hidden_states
# 使用示例
input_channels = 3 # 输入数据的通道数(比如 RGB 图像)
hidden_size = 128 # 隐藏状态的维度
# 创建时间注意力模型
attention_model = TimeAttentionVideo(input_channels, hidden_size)
# 假设有一个视频数据 video_data,形状为 (batch_size, num_frames, channels, height, width)
video_data = torch.randn(2, 10, 3, 224, 224) # 示例视频数据
# 使用时间注意力机制处理视频数据
output = attention_model(video_data)
print("输出形状:", output.shape) # 输出形状为 (batch_size, hidden_size)
时间注意力机制的意义
时间注意力机制的意义在于允许模型在处理序列数据时更加关注其中某些时间步的信息,而忽略其他时间步。这对于处理长序列或者包含重要时刻的序列数据是很有帮助的。在视频处理中,时间注意力机制可以使模型集中注意力于某些关键帧,从而更有效地捕捉视频中的重要动态。
时间注意力的内在机理
内在机理是基于权重分配的原理。在时间注意力机制中,模型学会为每个时间步分配一个权重,这些权重反映了该时间步对于当前任务的重要性。这些权重通常通过学习得到,可以通过训练数据来调整。权重分配的机制可以是多样化的,包括使用神经网络的注意力模型。
给时间步赋予权重,是不是就是给帧赋予权重
给时间步赋予权重确实可以被看作是给帧赋予权重,尤其是在处理视频等序列数据时。每个时间步对应于视频序列中的一帧。通过学习得到的权重,模型可以在处理视频时集中注意力于对任务更重要的帧,从而更好地捕捉视频的内容。
相对于权重低的帧,模型会对于高权重的帧做什么特别的处理
对于权重较低的帧,模型在处理时可能会更少地考虑它们的信息。这并不意味着完全忽略这些帧,而是降低其在最终输出中的贡献。相对于权重低的帧,模型对于权重高的帧会更加关注,因为这些帧在任务中被认为是更为关键的。这种方式允许模型更灵活地处理不同时间步的输入,更好地适应不同任务的要求。

















 992
992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









