






AI市场综述以及英伟达面临的挑战

Nvidia的AI解决方案目前处于世界领先地位,但颠覆性的变化即将到来。Google已经展开了一项前所未有的计划,建设自己的AI基础设施。我们独家详细披露了Google TPUv5和TPUv5e的内部训练/推理以及外部客户使用的容量和金额,这些客户包括苹果、Anthropic、CharacterAI、MidJourney、Assembly、Gridspace等公司。
Google并不是唯一对Nvidia在AI基础设施领域的统治地位构成威胁的公司。在软件方面,Meta的PyTorch 2.0和OpenAI Triton正在迅速发展,使其他硬件供应商也能够参与其中。
AMD的GPU、Intel的Gudi、Meta的MTIA和微软的Athena都在其软件栈的不同阶段成熟,但很明显,软件差距虽然仍然存在,但已不再像过去那样巨大。尽管Nvidia仍然保持着硬件领先地位,但这一优势也将很快被追赶上。在未来几个月内,AMD的MI300和Intel的Gudi 3都将推出技术上优于Nvidia H100的硬件。

即使在谷歌、AMD和英特尔之外,英伟达还面临着来自硬件设计落后的公司的竞争力压力,但这些公司将得到它们背后的巨头的补贴,这些巨头希望尝试摆脱英伟达在HBM上的利润率叠加。亚马逊正在推出他们的Trainium2和Inferentia3,微软也即将推出Athena。我们在7月份讨论了这些公司的供应链和明年的产量,但这些都是多年投资,不会在未来放缓。
Nvidia多年前就意识到了这个问题。科技巨头们一直在试图取代他们所有的硬件需求,并抢夺Nvidia的市场份额。
从这个角度来看,有一个非常合理的论点认为,由于这种竞争威胁,Nvidia将无法保持其市场份额或利润率。
当然,Nvidia并没有袖手旁观。尽管Nvidia非常成功,但他们也是行业中最偏执的公司之一,从管理风格到路线图决策都是如此。黄仁勋体现了安迪·格罗夫的精神-“成功滋生自满。自满滋生失败。只有偏执狂才能生存”(Success breeds complacency. Complacency breeds failure. Only the paranoid survive-Andy Grove)。

因此,Nvidia采取了非常雄心勃勃和冒险性的多管齐下战略,以保持在AI硬件市场的领先地位。Nvidia的计划是超越传统的竞争对手,如Intel和AMD,并提升到科技巨头的行列。他们希望成为与Google、Microsoft、Amazon、Meta和Apple同等级别的公司。Nvidia的DGX Cloud、软件和非半导体收购策略值得密切关注。
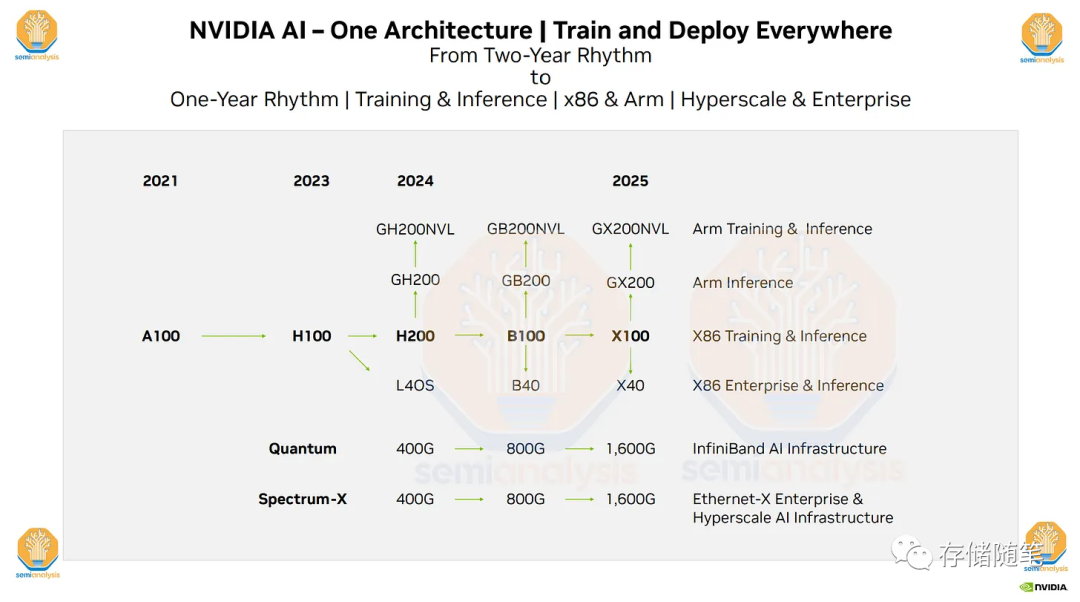
特别是他们未来几年的硬件路线图,包括即将推出的H200、B100和“X100”GPU。Nvidia每年更新AI GPU的举动非常重要,并带来了许多影响。Nvidia的过程技术计划、HBM3E速度/容量、PCIe 6.0、PCIe 7.0以及他们非常雄心勃勃的NVLink和1.6T 224G SerDes计划。如果这个计划成功,Nvidia将超越所有人。
关于Nvidia的商业策略,有一些人甚至认为其销售策略和捆绑销售具有反竞争性。Nvidia的战略采购也非常值得关注,特别是在供应商管理、CoWoS/HBM容量获取以及开发专用技术(如光开关和共封装光学)方面。
3.英伟达对供应链的掌控- Jensen Huang下了大赌注
我们对Nvidia非常尊重的一点是他们是供应链的大师。他们在过去多次展示了在供应短缺时创造性地增加供应的能力。
Nvidia通过愿意承诺不可取消的订单甚至提前支付来确保巨大的供应。Nvidia有111.5亿美元的采购承诺、产能义务和库存义务。此外,Nvidia还有额外的38.1亿美元的预付款供应协议。没有其他供应商能够接近这个数字,因此他们无法参与正在发生的疯狂购买潮。
自从Nvidia早期以来,Jensen一直在积极发展其供应链,以推动Nvidia的巨大增长野心。只需回顾一下Jensen讲述他与TSMC创始人Morris Chang的早期会议即可。
“1997年,当莫里斯和我相遇时,英伟达在那一年完成了2700万美元的收入。我们有 100 个人,然后我们见面了,你们可能不相信这一点,但莫里斯过去常常打销售电话。你以前经常上门拜访,对吧?你会进来拜访客户,我会向莫里斯解释英伟达做了什么,你知道,我会解释我们的芯片尺寸需要有多大,而且每年都会变得越来越大。你会定期回到英伟达,让我把这个故事讲一遍,以确保我需要那么多晶圆,明年,我们开始与台积电合作。英伟达做到了,我认为是 1.27 亿,然后,从那时起,我们每年增长近 100%,直到现在。我的意思是,我们过去10年的复合年增长率是70%左右。”

Jensen Huang 与 Morris Chang 的对话,计算机历史博物馆,2007
Morris Chang 不太相信 Nvidia 需要这么多晶圆,但 Jensen 坚持并利用了当时游戏行业的大规模增长。英伟达通过大胆的供应取得了巨大的成功,而且通常都是为他们解决的。当然,他们必须不时地减记价值数十亿美元的库存,但他们仍然从过度订购事务中获得了积极的收益。
英伟达已经抢占了SK海力士、三星和美光HBM等GPU上游组件的大部分供应。他们已经向所有 3 家 HBM 供应商下了非常大的订单,并且正在挤占除 Broadcom/Google 之外的其他所有人的供应。我们将在路线图部分讨论更多关于 HBM3E 的信息。
英伟达已经收购了台积电的大部分CoWoS供应。他们并没有就此止步,他们还走出去调查并收购了 Amkor 的产能。
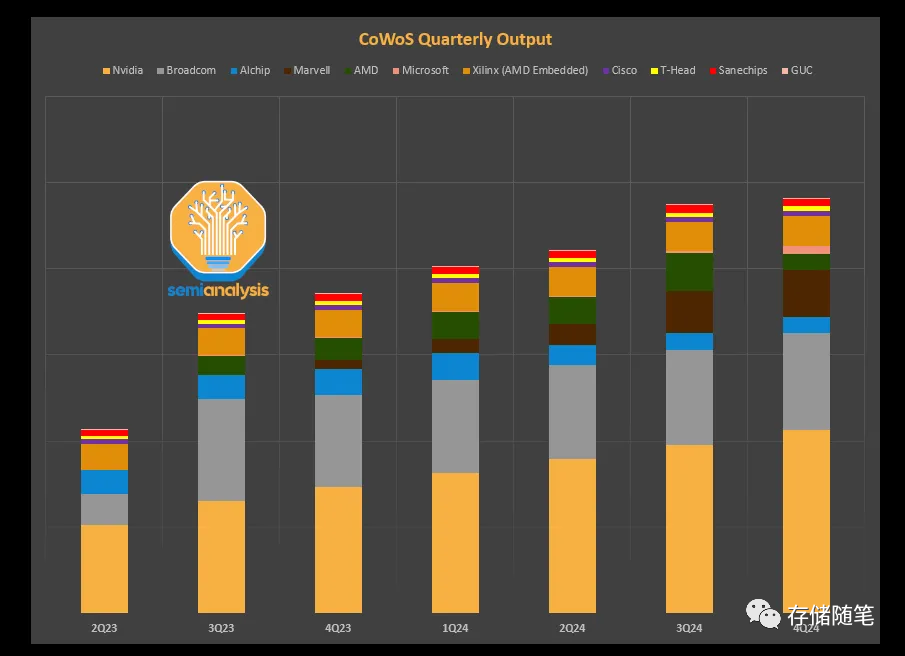
Nvidia 还利用了其 HGX 板或服务器所需的许多下游组件,例如重定时器、DSP、光学器件等。对英伟达的要求犹豫不决的供应商通常会得到胡萝卜加大棒的对待。一方面,他们可以从英伟达获得看似难以想象的订单,另一方面,他们面临着被设计出英伟达现有供应链的问题。他们只在供应商至关重要且无法设计或多源时使用提交且不可取消。
每个供应商似乎都认为自己是人工智能赢家的部分原因是因为英伟达从他们那里订购了很多产品,他们都认为他们赢得了大部分业务,但实际上,英伟达的发展速度如此之快。
回到上述市场中的动态,尽管Nvidia的目标是明年数据中心销售额超过700亿美元,但只有谷歌拥有足够的上游产能,才能在超过100万台的规模上实现有意义的单位。即使AMD最近修订了其容量计划,其在AI方面的总容量仍然非常有限,最多也只有数十万个单位。
4.商业策略 – 潜在的反竞争
众所周知,英伟达正在利用对 GPU 的巨大需求,使用它来追加销售和交叉销售客户。供应链中的许多消息来源告诉我们,英伟达正在根据多种因素向公司提供优先分配,包括但不限于:多源计划、制造自己的 AI 芯片的计划、购买英伟达的 DGX、NIC、交换机和/或光学器件。我们在 3 月份的 Amazon Cloud Crisis 报告中详细介绍了这一点。
CoreWeave、Equinix、Oracle、AppliedDigital、Lambda Labs、Omniva、Foundry、Crusoe Cloud 和 Cirrascale 等基础设施提供商被指为分配大户,其数量远远接近其潜在需求,而不是像亚马逊这样的大型科技公司。
事实上,英伟达的捆绑非常成功,尽管以前是一家非常小的光收发器供应商,但他们在 1 个季度的业务增长了两倍,并有望在明年出货价值超过 10 亿美元的产品。这远远超过了其GPU或网络芯片业务的增长率。
这些策略是经过深思熟虑的,例如,目前,在 Nvidia 系统上通过可靠的 RDMA/RoCE 实现 3.2T 网络的唯一方法是使用 Nvidia 的 NIC。这主要是由于英特尔、AMD和博通缺乏竞争力,它们仍然停留在200G。
Nvidia 巧妙地管理了他们的供应链,因此他们的 400G InfiniBand NIC 的交货时间明显低于他们的 400G 以太网 NIC。请记住,两个 NIC (ConnectX-7) 的芯片和电路板设计是相同的。这主要归因于 Nvidia 的 SKU 配置,而不是实际的供应链瓶颈。这迫使公司购买 Nvidia 更昂贵的 InfiniBand 交换机,而不是使用标准以太网交换机。当你购买带有 Bluefield-3 DPU 的 Spectrum-X 以太网网络时,Nvidia 会例外。
它也不止于此,看看供应链对 L40 和 L40S GPU 的陶醉程度。我们在这里写过这个,但从那时起,我们听到了更多关于 Nvidia 的分配恶作剧。
为了让这些原始设备制造商赢得更大的H100配额,英伟达正在推动L40S。这些原始设备制造商面临着购买更多 L40 的压力,从而获得更好的 H100 分配。这与英伟达在PC领域玩的游戏相同,笔记本电脑制造商和AIB合作伙伴不得不购买大量G106 / G107(中端和低端GPU),以便为更稀缺,利润率更高的G102 / G104(高端和旗舰GPU)获得良好的分配。
台湾供应链中的许多人都认为 L40S 比 A100 更好,因为它的 FLOPS 更高。需要明确的是,这些 GPU 不适合 LLM 推理,因为它们的内存带宽不到 A100 的一半,而且没有 NVLink。这意味着除了非常小的模型外,以良好的 TCO 在它们上运行 LLM 几乎是不可能的。高批量具有不可接受的令牌/秒/用户,使理论上的 FLOPS 在实践中对 LLM 毫无用处。
原始设备制造商也面临着支持英伟达MGX模块化服务器设计平台的压力。这有效地消除了设计服务器的所有艰苦工作,但同时将其商品化,创造了更多的竞争并降低了 OEM 的利润率。戴尔(Dell)、惠普(HPE)和联想(Lenovo)等公司显然对MGX持抵制态度,但台湾的低成本公司,如SuperMicro、广达、华硕、技嘉、和硕和华擎等,正在争先恐后地填补这一空白,将低成本的“企业AI”商品化。
这些参与 L40S 和 MGX 炒作游戏的 OEM/ODM 也顺利获得了 Nvidia 主线 GPU 产品的更好分配。
由于来自谷歌、亚马逊、微软、AMD和英特尔的竞争压力,我们相信Nvidia加速了他们B100和“X100”的计划。针对Nvidia的加速时间表,我们听说AMD完全取消了他们的MI350X计划。回到MI300配置的技术规格上。
模块化的XCD构建块是40CUs,采用台积电的5nm工艺技术。 AMD曾经拥有MI350X,它具有相同的AIDs但不同的XCDs,采用台积电的3nm工艺技术。由于各种原因,该部件已被取消,主要是,与B100相比在纸面规格上完全缺乏竞争力。

















 1411
1411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









