







0.1 plink的文件格式
0.1.1 text plink 文件
.ped
.ped文件包含有关样本的信息(即,基因型的个体列表)。行对应一个个体,前六列提供关于这个个体的信息。
- 前两列包含一个族family标识符(FID)和个体惟一标识符(ID)。
- 第3-4列,有关于父(F)和母(M)标识符的信息,这些信息可以用来重建家族谱系。
- 第5-6列包含有关性别(S)和感兴趣的表型(P)信息。
- 其余的列包含遗传信息。每个SNP由两列组成,分别表示个体的基因型。

.map
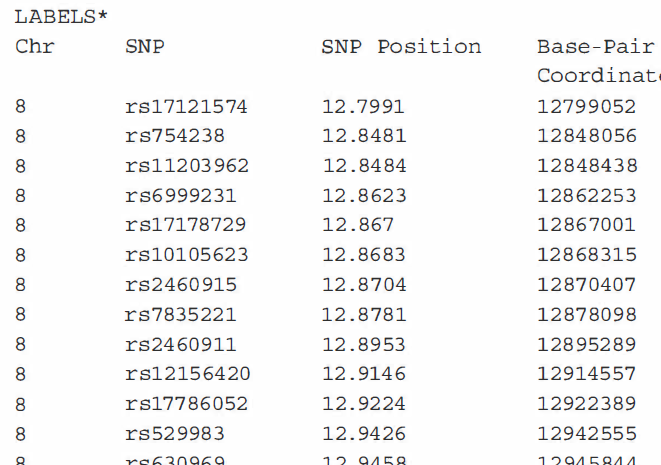
map文件提供了哪些snp已被基因分型的信息,以及如何在基因组中定位它们。
-
第一列表示染色体(Chr)号,第二列表示SNP标识符(通常为rs号)。
-
第三列和第四列表示SNP的位置。第三列是用厘摩来衡量的,是基于重组概率的遗传距离的衡量,因此在整个基因组中不是恒定的。厘摩(centimorgan,简写为cM),或称为图距单位(map unit),是遗传连锁中的距离单位,以现代遗传学之父托马斯·亨特·摩尔根的名字命名。1厘摩的定义为两个位点间平均100次减数分裂发生1次遗传重组。连锁位点之间的距离不超过50厘摩,两个位点间距50厘摩即意味着两者完全不连锁。对于人类来说,1厘摩平均相当于100万个碱基对。第四列测量碱基对坐标或碱基对的遗传距离,即变体之间的分子数(字母)。
snp的位置因使用的参考基因组不同而发生改变。
0.1.2 二进制plink文件
.bed、.fam、.bim
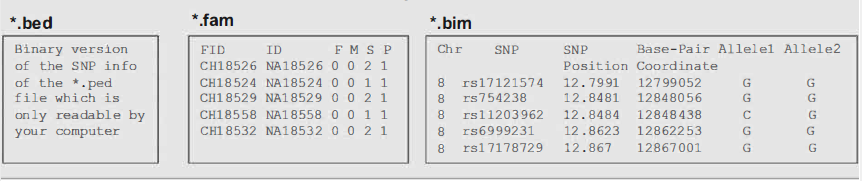
- .bed文件,在文本编辑器中是不可读的,它以压缩的方式包含关于基因型的信息。
- .fam文件,表示关于个人的信息(相当于.ped文件的前六列
- .bim文件表示关于snp的信息(实际上相当于.map文件,但有等位基因!和Allele2列;
plink2.0二进制文件
.pvar、.psam、.pgen
- .pvar文件表示关于基因标记的信息(类似于.bim文件)
- .psam文件,表示样本中个人的信息(类似于.fam样本文件)
- .pgen文件(在文本编辑器中不可读)以压缩的方式包含关于基因型概率的信息。
0.1.3 Oxford文件类型
有两个文件,基因型文件和一个样本文件
基因型文件
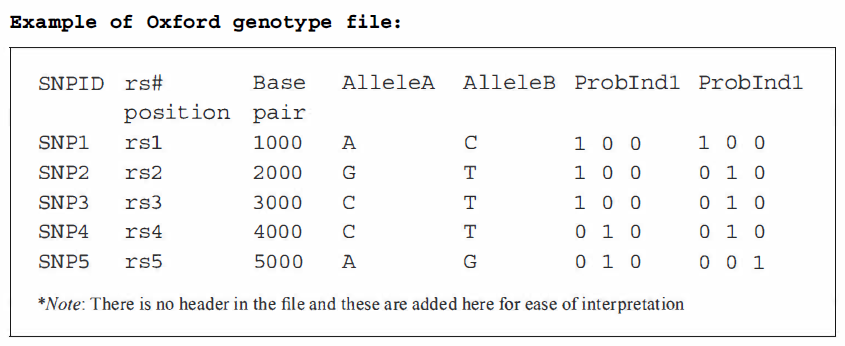
基因型文件以每snp一行的格式包含关于基因型数据的信息,而列表示个体。
- 前5列,每个文件的前五列包含SNP标识符、SNP的碱基对位置、编码A的等位基因和编码B的等位基因的信息。
- 接下来的三个数字给出了队列中第一个个体SNP的三种基因型AA, AB和BB的概率。接下来的三个数字是第二个个体。
- 如下图所示,2个个体的5个SNP,第一个个体的前5个SNP是AA/GG/CC/CT/AG。
基因型文件的维度取决于受试者的数量N和snp的数量K,因为该文件有K行和(N x 3) + 5列。
样本文件
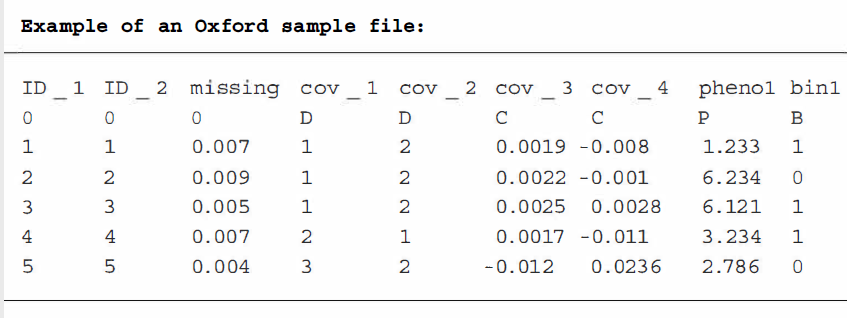
- 标题行详细描述文件中列的名称,行详细描述存储在每一列中的变量类型,以及每个个体详细描述该个体信息的行。
- 文件的第二行详细说明了每一列中包含的变量的类型。前三列是零,如果变量是离散的,其他列取D,如果变量是连续的,取C。连续变量的表型如果是二元的,用P或B表示(病例对照研究)
0.1.4 VCF
这种格式可以存储基因分型、imputed(预测、插补)数据甚至测序数据的基因组信息。
该文件有一个大的元信息行序言(以一个双##符号作为前缀),标题行(以一个#符号作为前缀),以及数据行,每个数据行包含关于每个位置的基因组中的位置和样本的基因型信息
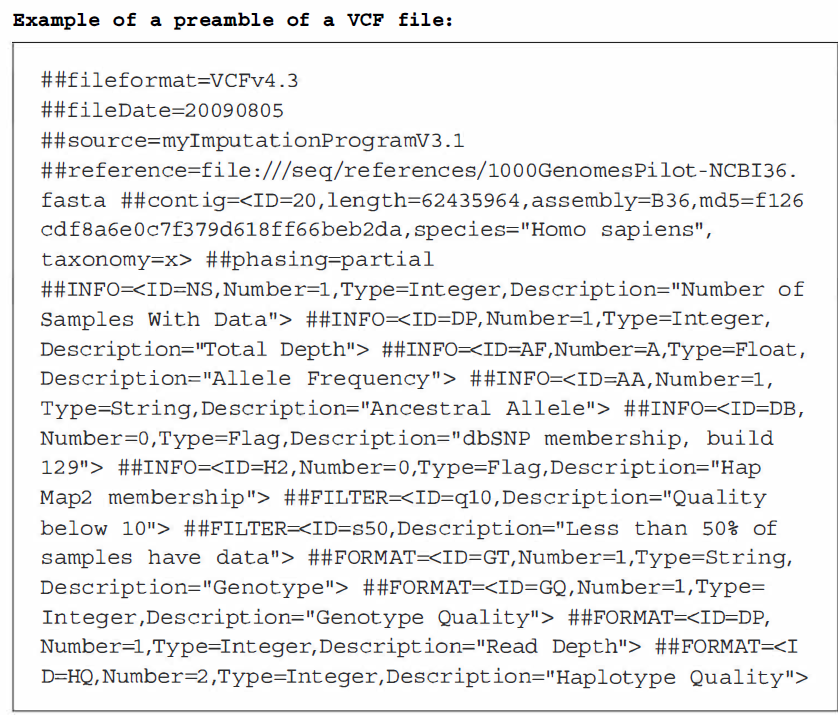
- CHROM,变异的序列(通常是染色体)的名称。这个序列通常被称为参考序列
- POS,给定序列上以1为基础的变异的位置
- ID,变异的标识符。多个标识符应该用不带空格的分号分隔。
- REF,在给定的参考序列上给定位置的参考碱基
- ALT,位于这个位置的可选等位基因的列表
- QUAL,给定等位基因推断相关的质量分数。
- FILTER,一种标志,表示变异通过了给定筛选集合的哪一个。
- INFO,描述变化的可扩展键值对
- FORMAT,用于描述示例的可扩展字段列表
- SAMPLEs,对于文件中描述的每个(可选)示例,给出了中列出的字段的值格式。
参考:
An Introduction to Statistical Genetic Data Analysis.


















 6849
6849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











