







如何使用 Ollama 的 API 来执行其他功能
简介
Ollama 提供了一个 RESTful API,允许开发者通过 HTTP 请求与 Ollama 服务进行交互。这个 API 覆盖了所有 Ollama 的核心功能,包括模型管理、运行和监控。在之前介绍 Ollama API 的文章当中已经介绍了生成文本、生成聊天和创建模型的 API 接口的使用,本篇将介绍其他 Ollama 的 RESTful API 接口,分别有列出本地模型、打印模型信息、复制模型、删除模型、从库中拉取模型、推送模型到库中、生成嵌入、列出运行中的模型、查看版本。
列出本地模型
端点:
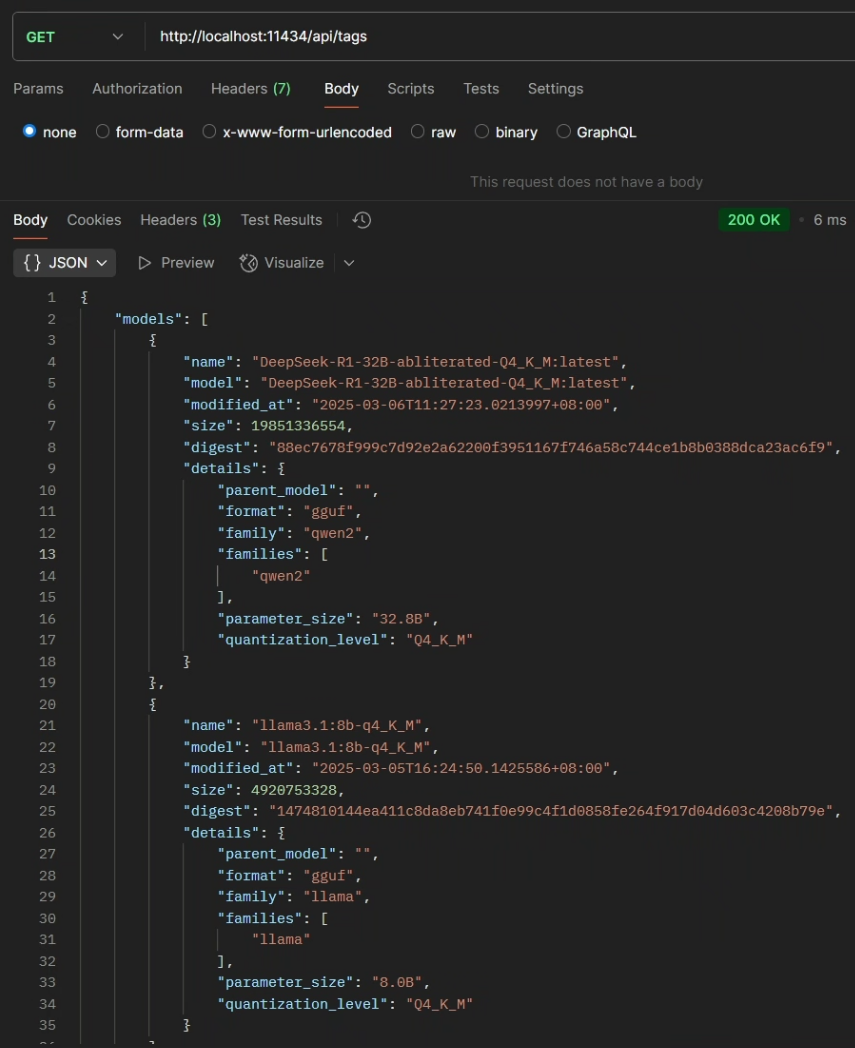
GET /api/tags列出服务器可用的本地模型。
请求:
curl http://localhost:11434/api/tags响应:
{
"models": [
{
"name": "DeepSeek-R1-32B-abliterated-Q4_K_M:latest",
"model": "DeepSeek-R1-32B-abliterated-Q4_K_M:latest",
"modified_at": "2025-03-06T11:27:23.0213997+08:00",
"size": 19851336554,
"digest": "88ec7678f999c7d92e2a62200f3951167f746a58c744ce1b8b0388dca23ac6f9",
"details": {
"parent_model": "",
"format": "gguf",
"family": "qwen2",
"families": [
"qwen2"
],
"parameter_size": "32.8B",
"quantization_level": "Q4_K_M"
}
},
{
"name": "llama3.1:8b-q4_K_M",
"model": "llama3.1:8b-q4_K_M",
"modified_at": "2025-03-05T16:24:50.1425586+08:00",
"size": 4920753328,
"digest": "1474810144ea411c8da8eb741f0e99c4f1d0858fe264f917d04d603c4208b79e",
"details": {
"parent_model": "",
"format": "gguf",
"family": "llama",
"families": [
"llama"
],
"parameter_size": "8.0B",
"quantization_level": "Q4_K_M"
}
},
]
}
打印模型信息
端点:
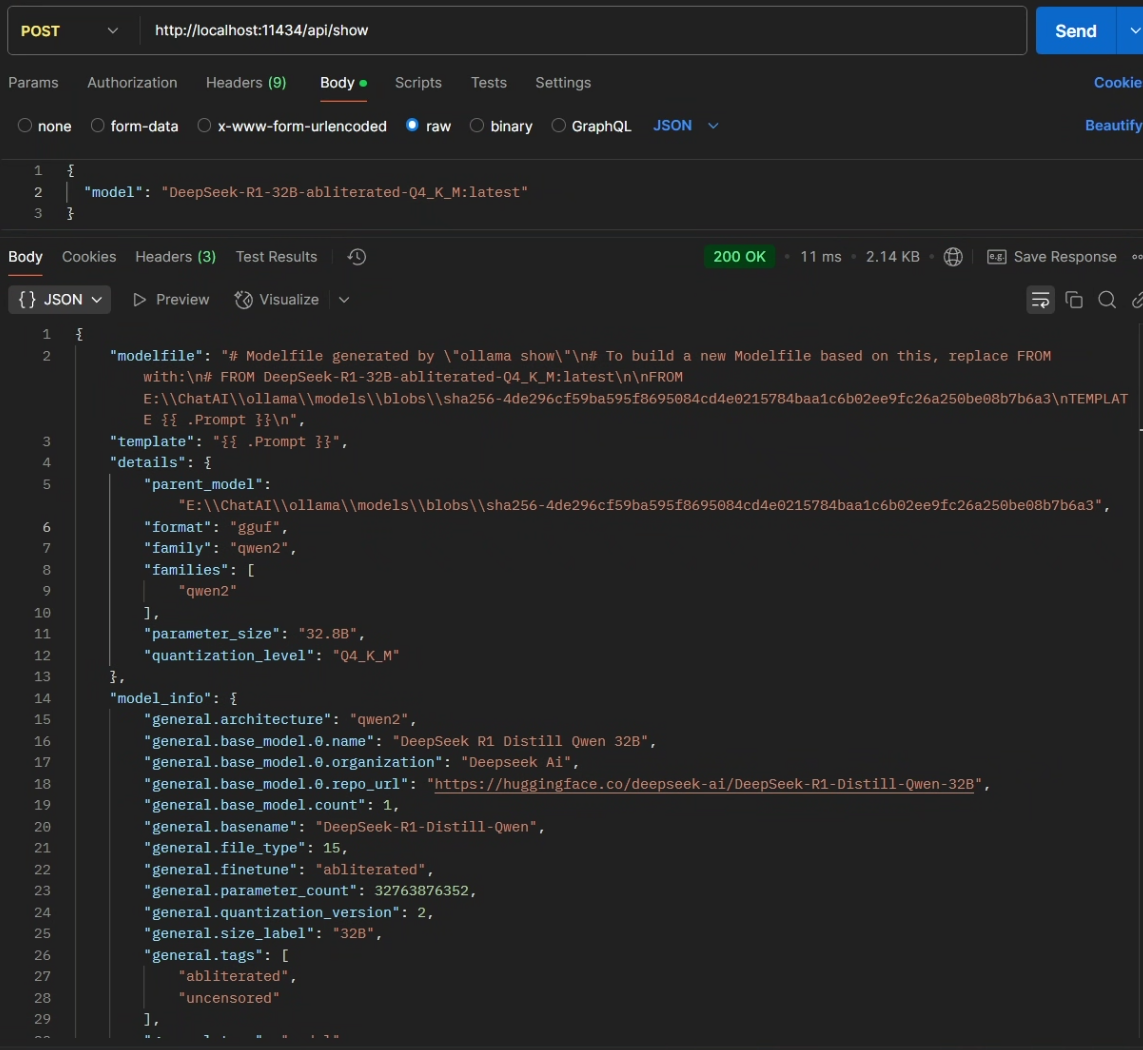
POST /api/show该 API 将显示有关模型的信息(详细信息、模板文件、模板、参数、许可、系统提示等)。
参数:
- model:模型名称
- verbose(可选):如果想要获取完整的信息,需要把该项设置为 true
请求:
curl http://localhost:11434/api/show -d '{
"model": "DeepSeek-R1-32B-abliterated-Q4_K_M:latest"
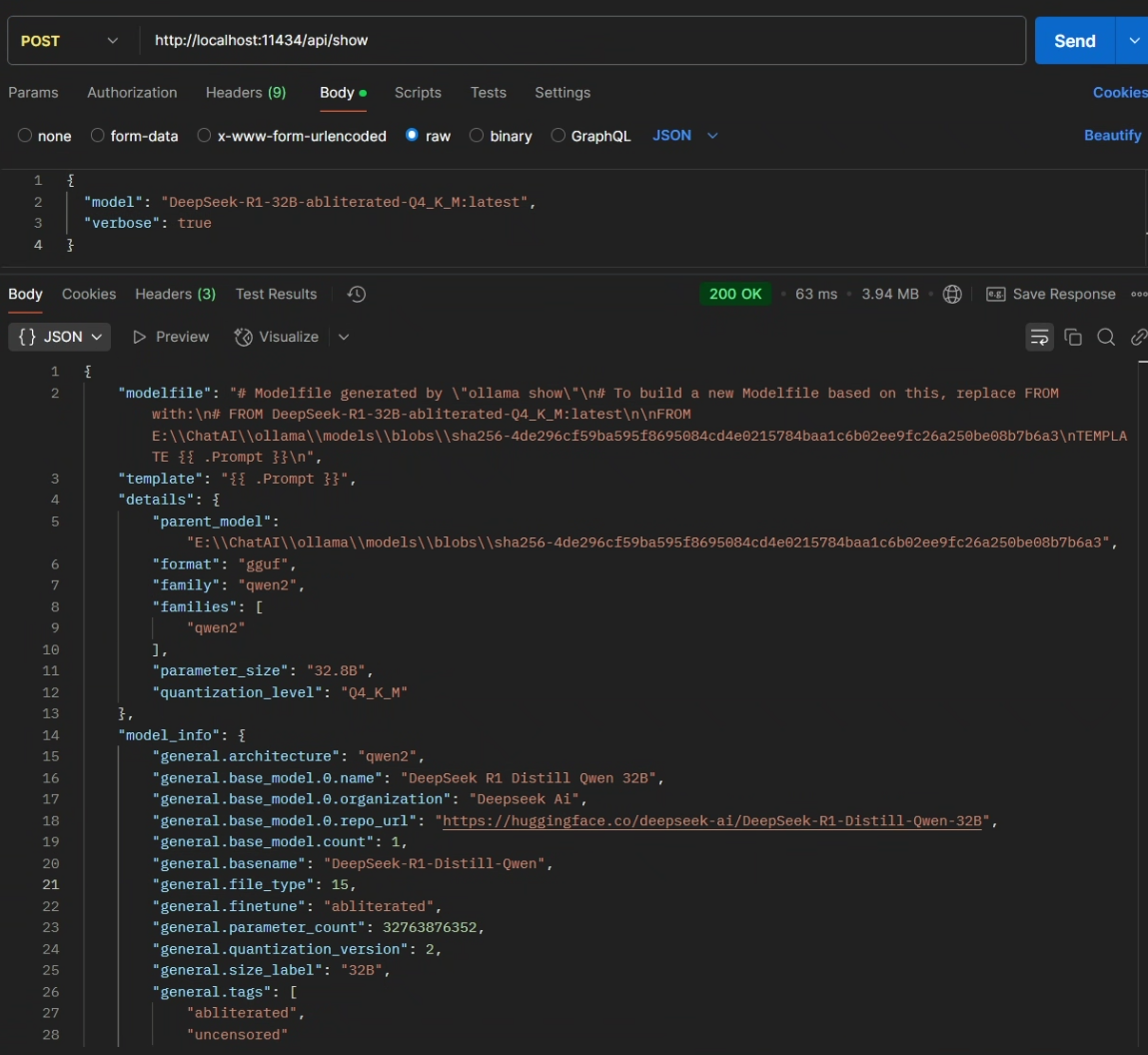
}'curl http://localhost:11434/api/show -d '{
"model": "DeepSeek-R1-32B-abliterated-Q4_K_M:latest",
"verbose": true
}'响应:
{
"modelfile": "# Modelfile generated by \"ollama show\"\n# To build a new Modelfile based on this, replace FROM with:\n# FROM DeepSeek-R1-32B-abliterated-Q4_K_M:latest\n\nFROM E:\\ChatAI\\ollama\\models\\blobs\\sha256-4de296cf59ba595f8695084cd4e0215784baa1c6b02ee9fc26a250be08b7b6a3\nTEMPLATE {{ .Prompt }}\n",
"template": "{{ .Prompt }}",
"details": {
"parent_model": "E:\\ChatAI\\ollama\\models\\blobs\\sha256-4de296cf59ba595f8695084cd4e0215784baa1c6b02ee9fc26a250be08b7b6a3",
"format": "gguf",
"family": "qwen2",
"families": [
"qwen2"
],
"parameter_size": "32.8B",
"quantization_level": "Q4_K_M"
},
"model_info": {
"general.architecture": "qwen2",
"general.base_model.0.name": "DeepSeek R1 Distill Qwen 32B",
"general.base_model.0.organization": "Deepseek Ai",
"general.base_model.0.repo_url": "https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"general.base_model.count": 1,
"general.basename": "DeepSeek-R1-Distill-Qwen",
"general.file_type": 15,
"general.finetune": "abliterated",
"general.parameter_count": 32763876352,
"general.quantization_version": 2,
"general.size_label": "32B",
"general.tags": [
"abliterated",
"uncensored"
],
"general.type": "model",
"quantize.imatrix.chunks_count": 128,
"quantize.imatrix.dataset": "/training_dir/calibration_datav3.txt",
"quantize.imatrix.entries_count": 448,
"quantize.imatrix.file": "/models_out/DeepSeek-R1-Distill-Qwen-32B-abliterated-GGUF/DeepSeek-R1-Distill-Qwen-32B-abliterated.imatrix",
"qwen2.attention.head_count": 40,
"qwen2.attention.head_count_kv": 8,
"qwen2.attention.layer_norm_rms_epsilon": 0.00001,
"qwen2.block_count": 64,
"qwen2.context_length": 131072,
"qwen2.embedding_length": 5120,
"qwen2.feed_forward_length": 27648,
"qwen2.rope.freq_base": 1000000,
"tokenizer.ggml.add_bos_token": true,
"tokenizer.ggml.add_eos_token": false,
"tokenizer.ggml.bos_token_id": 151646,
"tokenizer.ggml.eos_token_id": 151643,
"tokenizer.ggml.merges": null,
"tokenizer.ggml.model": "gpt2",
"tokenizer.ggml.padding_token_id": 151643,
"tokenizer.ggml.pre": "deepseek-r1-qwen",
"tokenizer.ggml.token_type": null,
"tokenizer.ggml.tokens": null
},
"modified_at": "2025-03-06T11:27:23.0213997+08:00"
}
{
"modelfile": "# Modelfile generated by \"ollama show\"\n# To build a new Modelfile based on this, replace FROM with:\n# FROM DeepSeek-R1-32B-abliterated-Q4_K_M:latest\n\nFROM E:\\ChatAI\\ollama\\models\\blobs\\sha256-4de296cf59ba595f8695084cd4e0215784baa1c6b02ee9fc26a250be08b7b6a3\nTEMPLATE {{ .Prompt }}\n",
"template": "{{ .Prompt }}",
"details": {
"parent_model": "E:\\ChatAI\\ollama\\models\\blobs\\sha256-4de296cf59ba595f8695084cd4e0215784baa1c6b02ee9fc26a250be08b7b6a3",
"format": "gguf",
"family": "qwen2",
"families": [
"qwen2"
],
"parameter_size": "32.8B",
"quantization_level": "Q4_K_M"
},
"model_info": {
"general.architecture": "qwen2",
"general.base_model.0.name": "DeepSeek R1 Distill Qwen 32B",
"general.base_model.0.organization": "Deepseek Ai",
"general.base_model.0.repo_url": "https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"general.base_model.count": 1,
"general.basename": "DeepSeek-R1-Distill-Qwen",
"general.file_type": 15,
"general.finetune": "abliterated",
"general.parameter_count": 32763876352,
"general.quantization_version": 2,
"general.size_label": "32B",
"general.tags": [
"abliterated",
"uncensored"
],
"general.type": "model",
"quantize.imatrix.chunks_count": 128,
"quantize.imatrix.dataset": "/training_dir/calibration_datav3.txt",
"quantize.imatrix.entries_count": 448,
"quantize.imatrix.file": "/models_out/DeepSeek-R1-Distill-Qwen-32B-abliterated-GGUF/DeepSeek-R1-Distill-Qwen-32B-abliterated.imatrix",
"qwen2.attention.head_count": 40,
"qwen2.attention.head_count_kv": 8,
"qwen2.attention.layer_norm_rms_epsilon": 0.00001,
"qwen2.block_count": 64,
"qwen2.context_length": 131072,
"qwen2.embedding_length": 5120,
"qwen2.feed_forward_length": 27648,
"qwen2.rope.freq_base": 1000000,
"tokenizer.ggml.add_bos_token": true,
"tokenizer.ggml.add_eos_token": false,
"tokenizer.ggml.bos_token_id": 151646,
"tokenizer.ggml.eos_token_id": 151643,
"tokenizer.ggml.merges": [...], # verbose 为 true 才会出现,但这里数据太多了所以省略了
"tokenizer.ggml.model": "gpt2",
"tokenizer.ggml.padding_token_id": 151643,
"tokenizer.ggml.pre": "deepseek-r1-qwen",
"tokenizer.ggml.token_type": [...], # verbose 为 true 才会出现,但这里数据太多了所以省略了
"tokenizer.ggml.tokens": [...], # verbose 为 true 才会出现,但这里数据太多了所以省略了
},
"modified_at": "2025-03-06T11:27:23.0213997+08:00"
}
复制模型
端点:
POST /api/copy对已在服务器中的模型进行复制,并命名为其他名字。配合删除功能可以实现模型的重命名。
参数:
- source:被复制的模型名称
- destination: 复制后新模型的名称
请求:
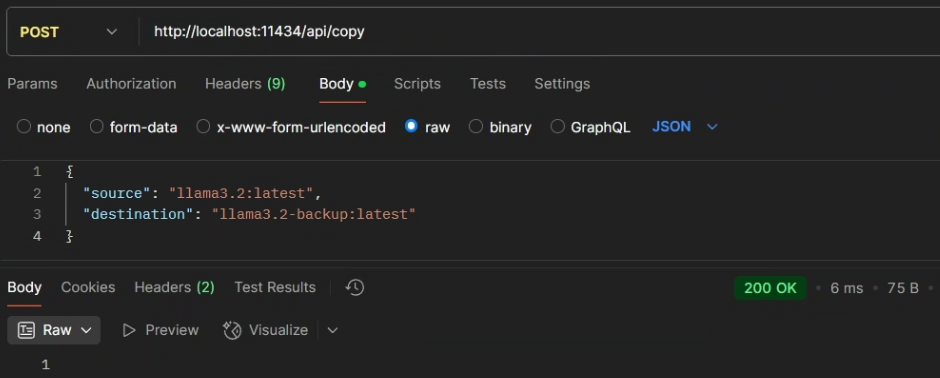
curl http://localhost:11434/api/copy -d '{
"source": "llama3.2:latest",
"destination": "llama3.2-backup:latest"
}'响应:
复制成功会返回200 OK,如果源模型不存在导致失败将返回404 Not Found
删除模型
端点:
DELETE /api/delete删除模型(包括本地模型 blob)及其数据
参数:
- model:需要删除模型的名称
请求:
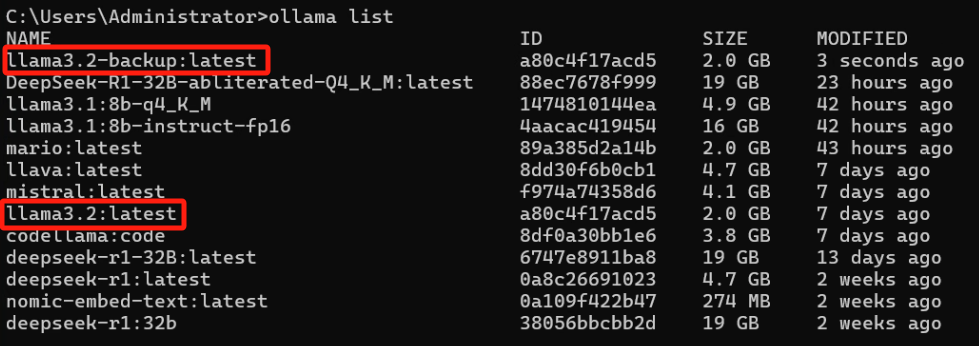
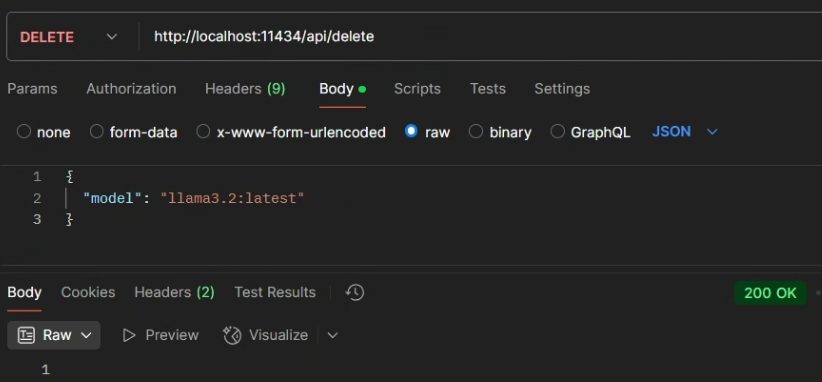
curl -X DELETE http://localhost:11434/api/delete -d '{
"model": "llama3.2:latest"
}'响应:
成功删除将返回200 OK,如果要删除的模型不存在则返回404 Not Found
从官方库下载模型
端点:
POST /api/pull将会从官方仓库下载一个 模型,这个下载有断点续传功能,也可以同时下载多个模型。
参数:
- model:要下载的模型名称
- insecure(可选):允许与官方库的不安全链接,开发过程中才会用到
- stream(可选):设置为 false 则不使用流式传输,默认为流式传输
请求:
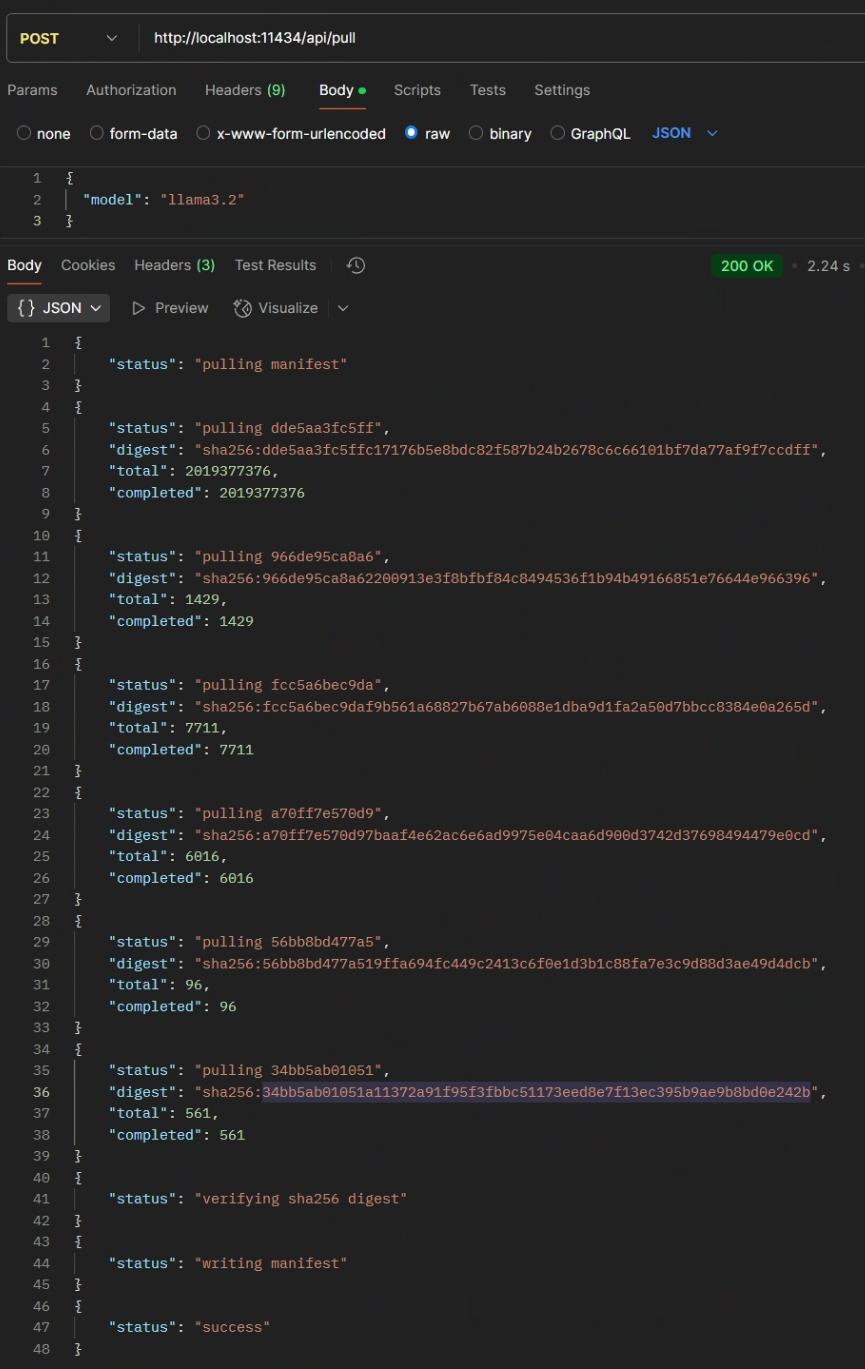
curl http://localhost:11434/api/pull -d '{
"model": "llama3.2"
}'响应:
流式传输时返回的第一个包的 status 为 pulling manifest
{
"status": "pulling manifest"
}第一个包过后就是一系列的下载响应 ,在下载过程返回的包有可能会不包含 completed 字段
{
"status": "pulling dde5aa3fc5ff",
"digest": "sha256:dde5aa3fc5ffc17176b5e8bdc82f587b24b2678c6c66101bf7da77af9f7ccdff",
"total": 2019377376,
"completed": 2019377376
}当所有文件都下载完成后,最后的响应如下
{
"status": "verifying sha256 digest"
}
{
"status": "writing manifest"
}
{
"status": "success"
}
上传模型到官方库中
端点:
POST /api/push把自己本地的训练好的模型上传到官方模型库当中,但在推送之前需要先前往 ollama.com 上注册,并添加上公钥。
参数:
model:要上传的模型名称,格式为 <namespace>/<model>:<tag>
insecure(可选):允许与官方库的不安全链接,开发过程中才会用到
stream(可选):设置为 false 则不使用流式传输,默认为流式传输
请求:
curl http://localhost:11434/api/push -d '{
"model": "mattw/pygmalion:latest"
}'响应:
流式传输时返回的第一个包的 status 为 retrieving manifest
{ "status": "retrieving manifest" }第一个包过后就是一系列的上传响应
{
"status": "starting upload",
"digest": "sha256:bc07c81de745696fdf5afca05e065818a8149fb0c77266fb584d9b2cba3711ab",
"total": 1928429856
}最后上传上传完成后,最后的响应如下
{"status":"pushing manifest"}
{"status":"success"}生成嵌入向量
端点:
POST /api/embed可以让模型生成嵌入向量,嵌入向量是一种将文本转换为数值向量表示的方式,这些向量在机器学习和自然语言处理中非常有用,例如用于文本相似性计算、聚类、分类等任务。
基本参数:
- model:用于生成嵌入向量的模型名称
- input:需要生成嵌入向量的文本,这可以是一个列表,可以输入多个文本
高级参数:
- truncate:根据设定的上下文长度从每个输入的尾部截断,可能会造成输入的部分缺失,默认为 true,如果设定为 false,当超过上下文长度后将返回 error
- options:模型参数,即 Modelfile 中填写的参数,例如 temperature 之类的
- keep_alive:请求后模型存在于内存中的时间,默认为5分钟
一、单个文本输入
请求:
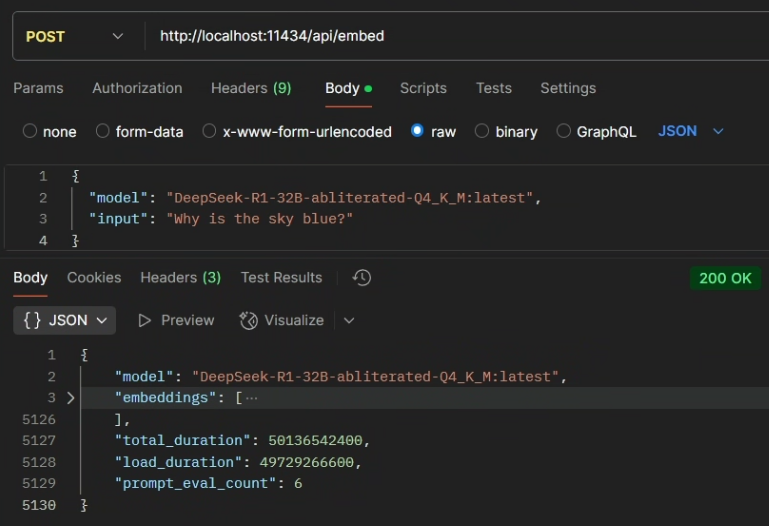
curl http://localhost:11434/api/embed -d '{
"model": "DeepSeek-R1-32B-abliterated-Q4_K_M:latest",
"input": "Why is the sky blue?"
}'响应:
{
"model": "DeepSeek-R1-32B-abliterated-Q4_K_M:latest",
"embeddings": [[0.00080057175,0.0028768708,-0.001027889,0.0038258387,...,0.008404303,0.008198861,0.009408009]],
"total_duration": 50136542400,
"load_duration": 49729266600,
"prompt_eval_count": 6
}
二、多个文本输入
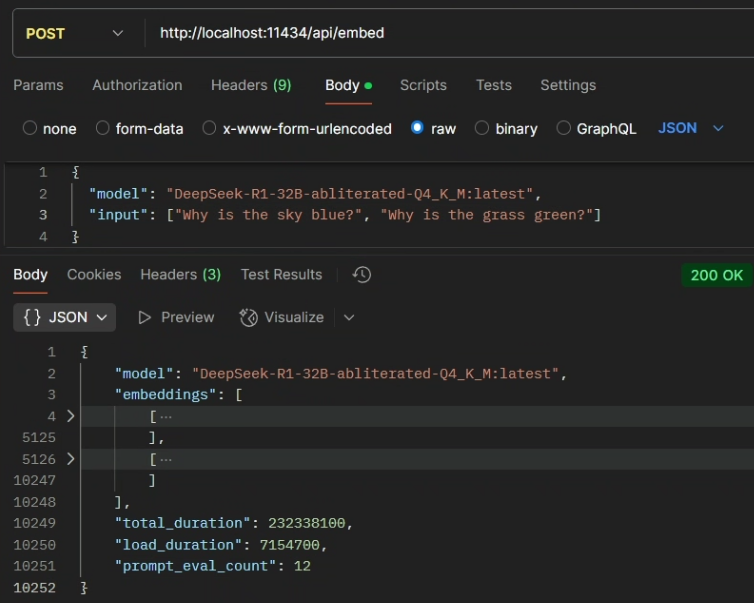
请求:
curl http://localhost:11434/api/embed -d '{
"model": "DeepSeek-R1-32B-abliterated-Q4_K_M:latest",
"input": ["Why is the sky blue?", "Why is the grass green?"]
}'响应:
{
"model": "DeepSeek-R1-32B-abliterated-Q4_K_M:latest",
"embeddings": [[0.00080057175,0.0028768708,-0.001027889,0.0038258387,...,0.008404303,0.008198861,0.009408009],[0.0024882958,0.0042897887,0.00031655197,0.0008690393,0.0022822758,...,0.007627705,0.009500079,0.008125986]],
"total_duration": 232338100,
"load_duration": 7154700,
"prompt_eval_count": 12
}
列出已加载的模型
端点:
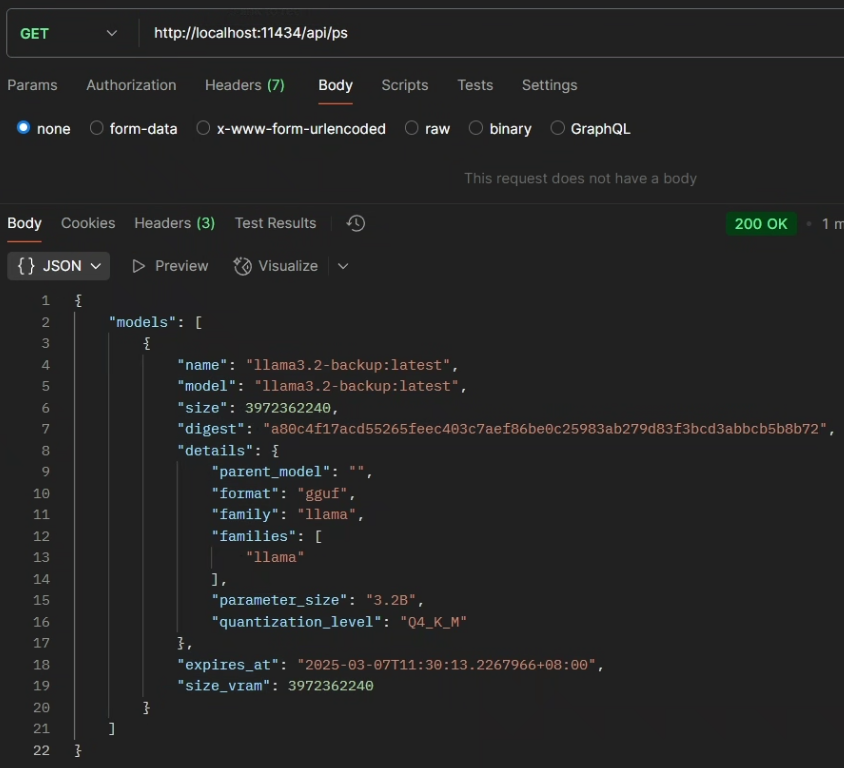
GET /api/ps请求:
curl http://localhost:11434/api/ps响应:
{
"models": [
{
"name": "llama3.2-backup:latest",
"model": "llama3.2-backup:latest",
"size": 3972362240,
"digest": "a80c4f17acd55265feec403c7aef86be0c25983ab279d83f3bcd3abbcb5b8b72",
"details": {
"parent_model": "",
"format": "gguf",
"family": "llama",
"families": [
"llama"
],
"parameter_size": "3.2B",
"quantization_level": "Q4_K_M"
},
"expires_at": "2025-03-07T11:30:13.2267966+08:00",
"size_vram": 3972362240
}
]
}
查看 Ollama 的版本
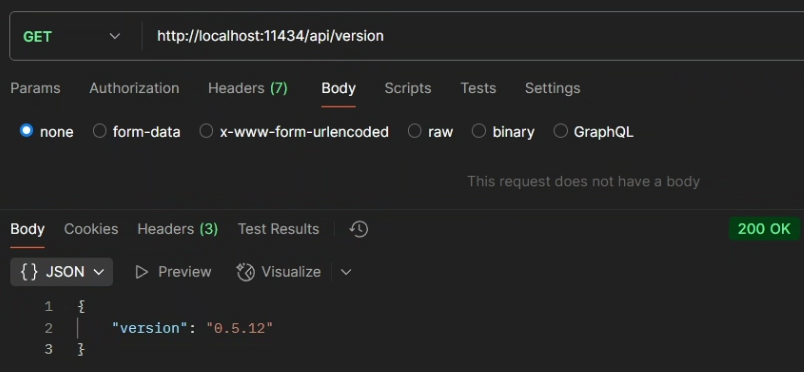
端点:
GET /api/version请求:
curl http://localhost:11434/api/version响应:
{
"version": "0.5.12"
}


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











