








上周国内外AI科技圈又发生了啥新鲜事?
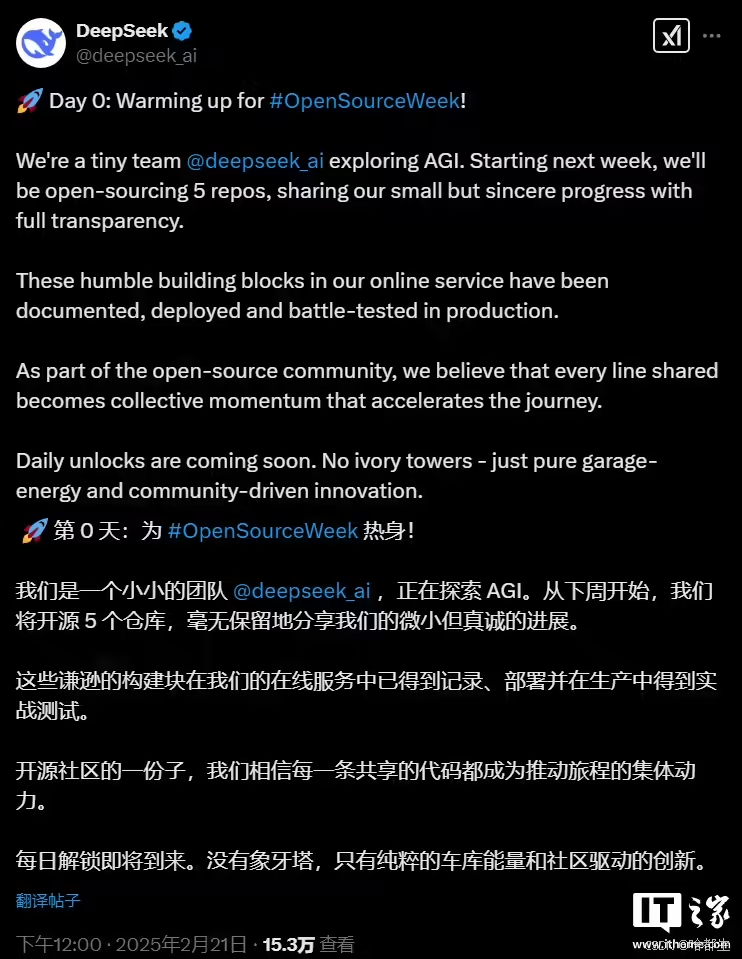
DeepSeek 宣布下周陆续开源 5 个代码库,推翻象牙塔
DeepSeek 宣布将在本周陆续开源 5 个代码库,每日解锁新内容。公司表示,这些代码库已经经过测试和部署,可投入生产环境。DeepSeek 自称为“小小的团队”,强调其车库创业精神和社区共筑的创新理念,致力于打破行业壁垒,推动技术共享与行业发展
https://www.ithome.com/0/832/584.htm
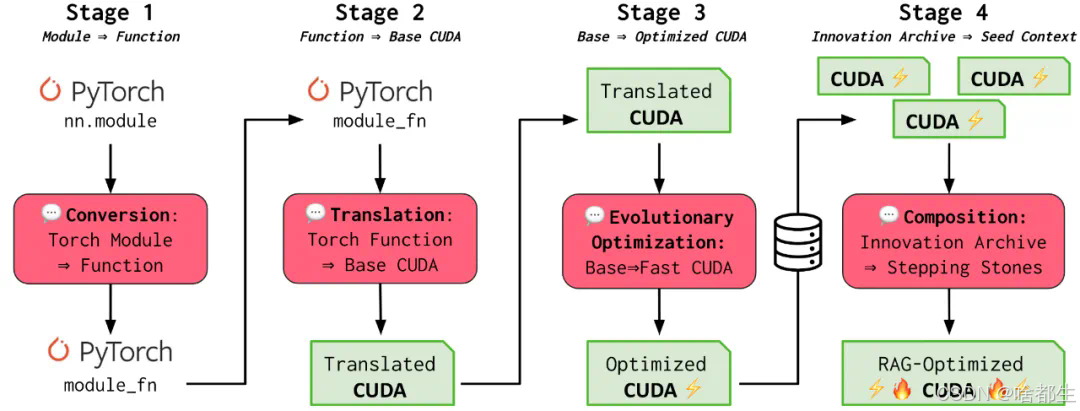
全球首个AI CUDA工程师诞生,将PyTorch原生实现提速10-100倍
日本AI初创公司Sakana AI开发的「AI CUDA工程师」框架,通过将进化计算与大型语言模型结合,实现了从PyTorch代码到高度优化CUDA内核的自动转换,显著提升AI模型在NVIDIA硬件上的运行效率。该框架生成的CUDA内核比PyTorch原生操作提速10-100倍,甚至超越现有生产环境中的优化内核。尽管其技术报告受到一些质疑,但这一创新展示了AI自我优化的巨大潜力,为未来AI的高效运行提供了新思路
https://www.jiqizhixin.com/articles/2025-02-21-7
Spotify 推出 AI 配音有声书服务,支持 29 种语言
Spotify 与 AI 语音提供商 ElevenLabs 合作,正式推出 AI 配音有声书服务。作者可以使用 29 种语言为有声书配音,并选择多种合成语音选项。免费版软件每月提供 10 分钟文本转语音服务,而 Pro 订阅(99 美元/月)可生成 500 分钟配音,相当于一本普通有声书的长度。Spotify 表示,AI 配音将帮助小型作者以更低的成本制作有声书,并推动旧书有声书的制作。所有 AI 配音的有声书将在描述中标注,明确告知听众
https://www.ithome.com/0/832/529.htm
何恺明新作:扩散模型无需噪声条件,实验结果颠覆传统认知
何恺明团队的最新研究发现,去噪扩散模型在无噪声条件的情况下依然可以良好运行,甚至在某些情况下表现更优。研究通过理论分析和实验验证,提出了一个无需训练的误差边界,并设计了无噪声条件的模型变体uEDM,在CIFAR10数据集上实现2.23的FID得分,接近噪声条件模型的最佳表现(FID为1.97)。这一成果有望为去噪生成模型的发展开辟新方向

https://mp.weixin.qq.com/s/zLqWlKVpK8tM_x9uuPx4wg
xAI宣布Grok 3免费开放,直至服务器不堪重负
xAI宣布其“世界最智能AI”系统Grok 3现在免费向公众开放,直至服务器不堪重负。此前,Grok 3仅对X Premium+或SuperGrok订阅用户开放。Grok 3在数学、科学和编码等复杂任务上的表现优于竞争对手,如ChatGPT和DeepSeek。xAI还透露,开发者将很快可以通过API访问Grok 3的标准版和推理版,并使用深度搜索功能
https://x.ai/blog/grok-3
硅基流动完成亿元人民币Pre-A轮融资
北京硅基流动科技有限公司于2024年底完成了亿元人民币的Pre-A轮融资,由华创资本领投,普华资本跟投,老股东耀途资本超额跟投。硅基流动成立于2023年,致力于打造AI基础设施平台,通过算法、系统与硬件的协同创新,降低AI应用的开发和使用门槛。其大模型云服务平台SiliconCloud上线不到一年,用户数超300万,日均调用上千亿Token,支持上百款主流模型,并提供全链路服务。本轮融资后,公司将加速技术创新,助力开发者实现“Token自由”,并推动AGI技术普及
https://mp.weixin.qq.com/s/NyStkbw_JgTulQ-RiA2V4A
Kimi 智能助手推出最新模型 kimi-latest
Kimi 智能助手开放平台近日上线了新模型 kimi-latest,以满足开发者对最新模型能力的需求。该模型将始终对标 Kimi 智能助手当前使用的最新模型,支持上下文长度达 128k,并具备视觉理解能力。开发者可通过 API 调用体验其最新特性,同时保持原有模型的稳定性。kimi-latest 适用于构建聊天应用、智能助手或客服场景,而结构化数据提取等任务仍推荐使用 moonshot-v1 系列模型
https://mp.weixin.qq.com/s/cS0DGGqUP1JOFSnzFWiqJQ
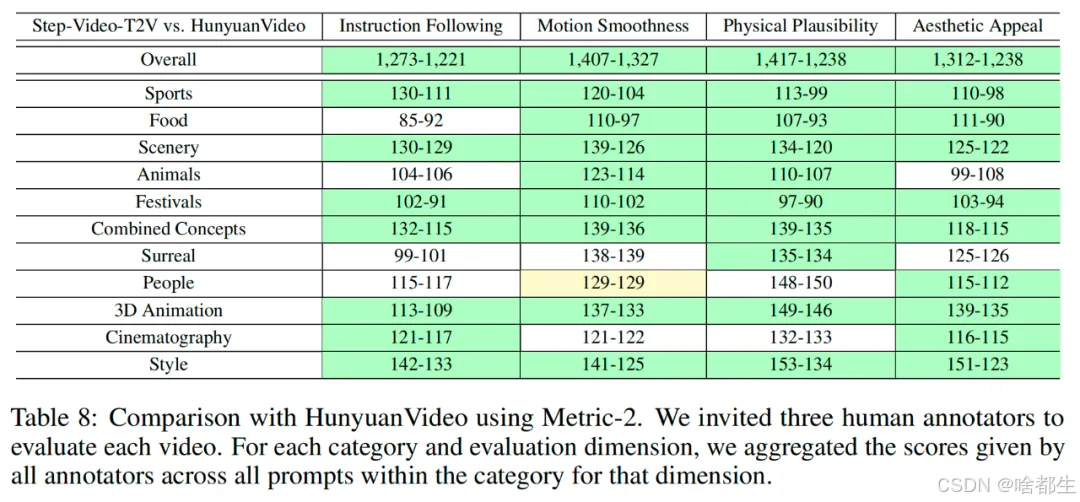
阶跃星辰联合吉利开源多模态大模型
阶跃星辰与吉利汽车集团联合开源了两款多模态大模型——Step-Video-T2V 视频生成模型和 Step-Audio 语音模型。其中,Step-Video-T2V 参数量达 300 亿,可生成高质量视频,性能在全球开源视频生成领域领先;Step-Audio 是业内首款产品级开源语音交互模型,支持多种语言风格和音色克隆。此次开源旨在推动 AGI 发展,为全球开源社区贡献中国力量
https://mp.weixin.qq.com/s/_mmwfiA7L3UQMflPFevVGg
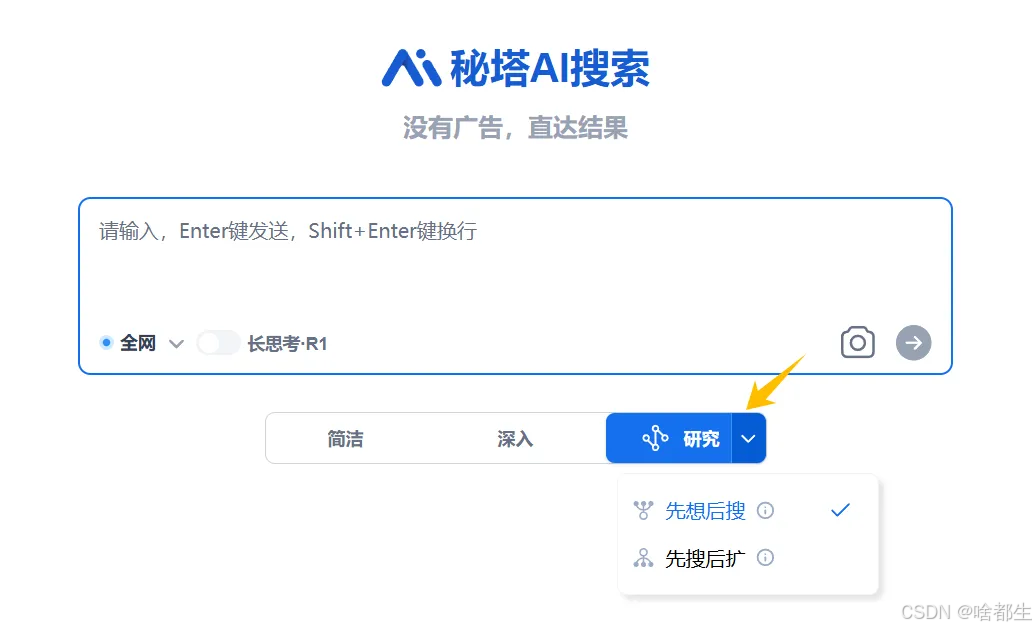
秘塔AI推出“浅度研究”模式,可在 2-3 分钟内完成数百网页分析
秘塔AI搜索上线了“浅度研究”模式,采用“小模型+大模型”协同架构,通过 DeepSeek R1 完成推理任务,结合秘塔自研模型完成快速信息搜索与整合。该模式可在 2-3 分钟内完成数百个网页的搜索与分析,帮助用户快速收集信息并完成初步分析,未来还将加入代码执行和数值分析能力,进一步提升研究效率
https://mp.weixin.qq.com/s/L9lUlYJglyp9iMsr9DcJAw
昆仑万维开源AI短剧创作模型SkyReels-V1
昆仑万维开源了中国首个面向AI短剧创作的视频生成模型 SkyReels-V1 和表情动作可控算法 SkyReels-A1。SkyReels-V1 支持影视级人物微表情表演和电影级光影美学,能够生成高质量的短剧视频;SkyReels-A1 则可实现高保真微表情还原和人物动作驱动。此次开源旨在降低AI短剧创作成本,推动行业生态繁荣发展
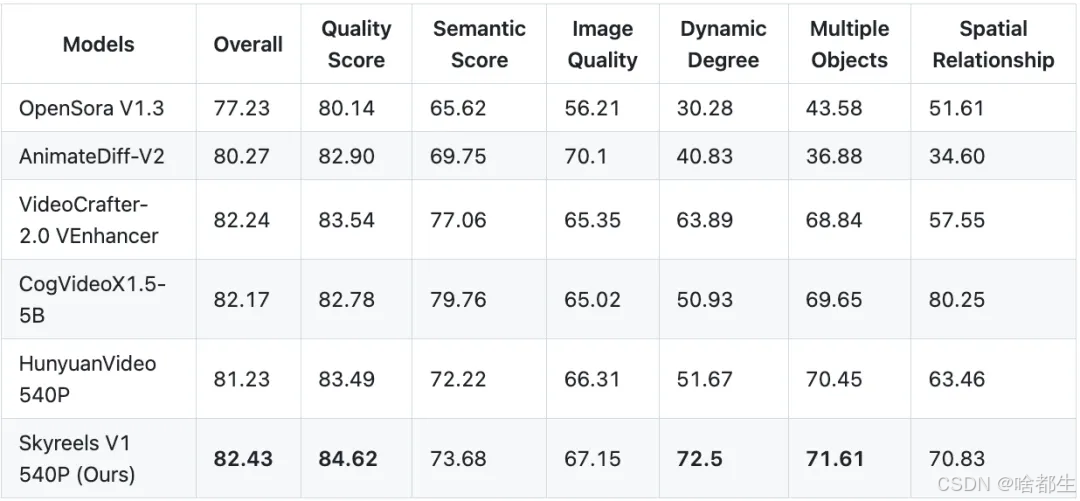
https://mp.weixin.qq.com/s/ZIYC_tr7dZ3kmUrrajpXjg
YOLOv12震撼发布,首个以Attention为核心的YOLO框架
YOLOv12正式发布,作为首个以Attention为核心的YOLO框架,它通过创新的区域注意力模块(Area Attention)和残差高效层聚合网络(R-ELAN),解决了传统Attention机制在计算效率和优化稳定性上的难题。实验表明,YOLOv12在多个尺度模型上均展现出显著性能提升,例如N-scale模型的mAP提升3.6%,同时保持了极高的推理速度(1.64ms/图像)。此外,它在参数量和CPU推理速度上也实现了优化,进一步提升了实时目标检测的效率
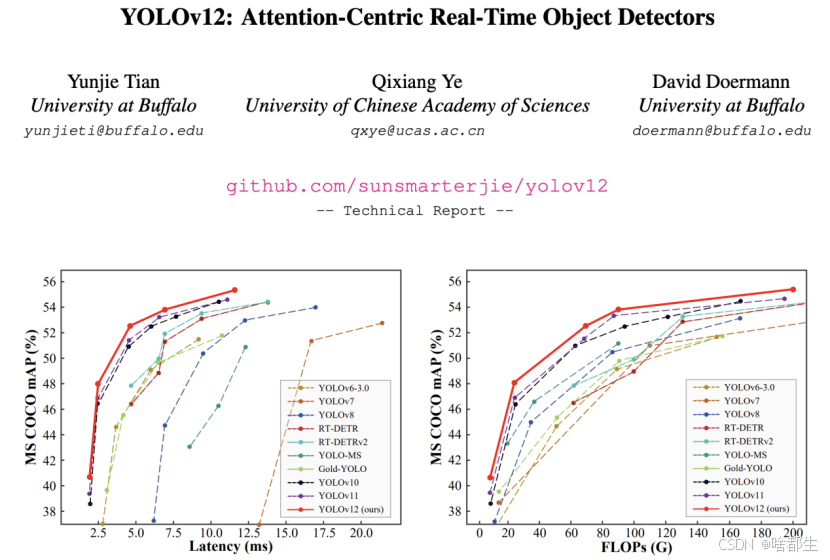
https://mp.weixin.qq.com/s/Ns6f1TDxoeuveYDqTKrXPg
DeepSeek R1方法成功迁移到视觉领域,多模态AI迎来新突破
DeepSeek 的 R1 方法被成功迁移到视觉语言领域,推出了开源项目 VLM-R1。该项目在 Qwen2.5-VL 基础上验证了 R1 方法的稳定性、泛化能力和易用性,表现出色。VLM-R1 不仅能准确理解视觉内容,还能进行专业推理和清晰的文本表达,为多模态模型训练提供了新思路,有望引领视觉语言模型训练新潮流
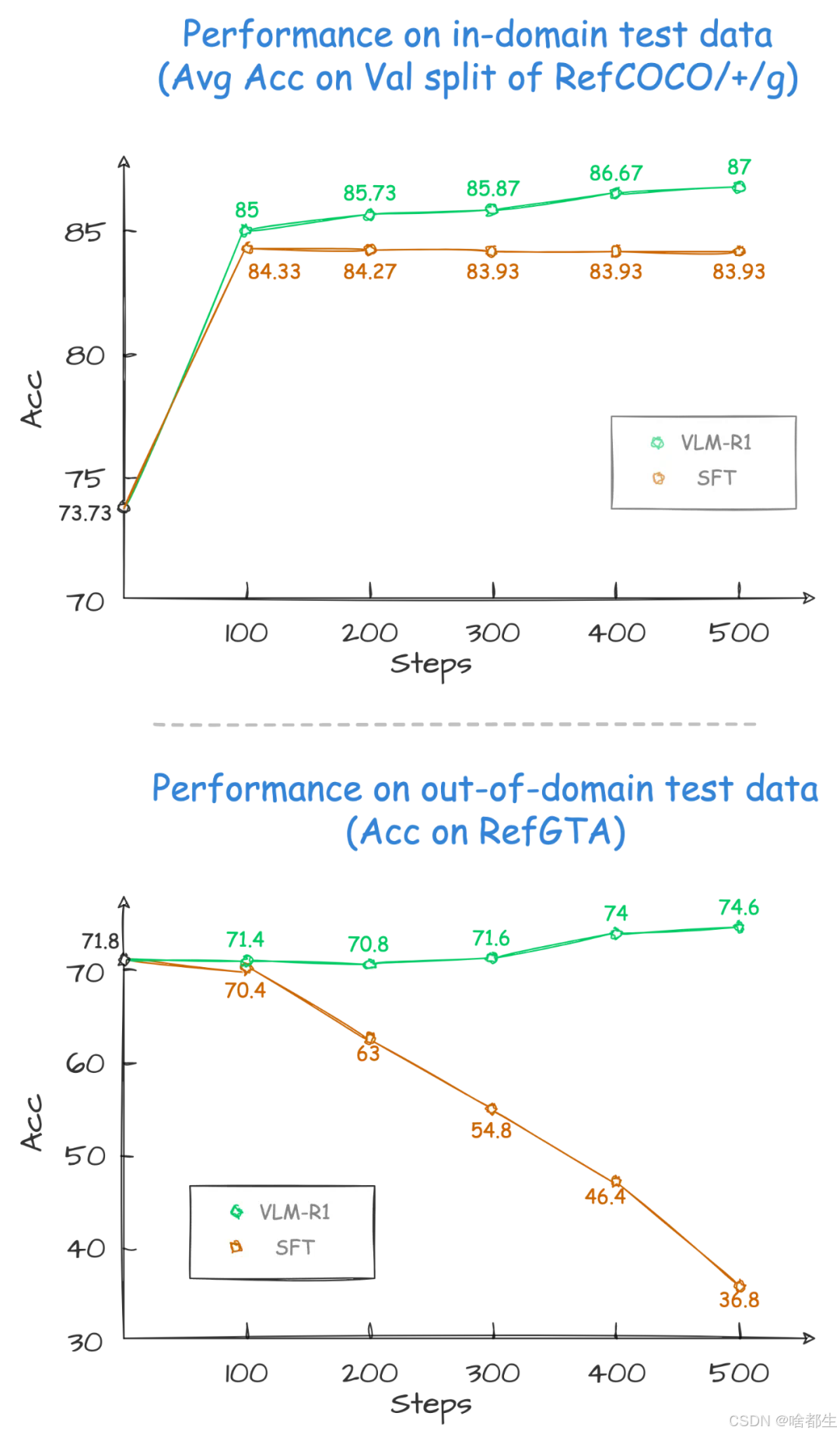
https://www.jiqizhixin.com/articles/2025-02-20-10
DeepSeek发布新注意力架构NSA,提升长上下文建模效率
DeepSeek 发布了一种新的注意力机制 NSA(Native Sparse Attention),旨在提升长上下文建模的效率。NSA 通过分层 token 建模和硬件对齐设计,显著降低了计算成本,同时保持了与全注意力机制相当的性能。实验表明,NSA 在长上下文任务中表现出色,推理速度和训练速度均大幅提升,为大语言模型的长序列处理提供了新解决方案

https://www.jiqizhixin.com/articles/2025-02-18-11
月之暗面发布新注意力架构MoBA,与DeepSeek NSA同日亮相
月之暗面发布了一种名为 MoBA(Mixture of Block Attention)的注意力机制,将混合专家(MoE)原理应用于注意力机制,实现对长序列的高效处理。MoBA 通过动态选择关键块进行计算,降低了计算复杂度,同时保持了与全注意力机制相当的性能。实验表明,MoBA 在处理长上下文任务时表现出色,且训练成本更低,代码已公开并经过实际部署验证
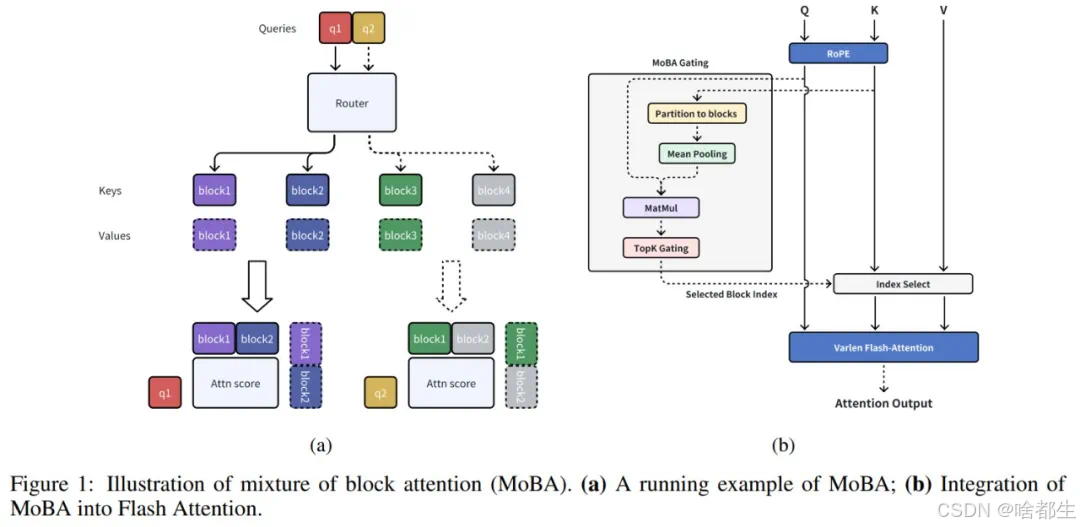
https://www.jiqizhixin.com/articles/2025-02-19-11


















 490
490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











