






目录
1. Data scarcity in downstream tasks
2. The PLM is too big, and they are still getting bigger
(三)The Solutions of Those Problems
1. Labeled Data Scarcity → Data-Efficient Fine-tuning
2. PLMs Are Gigantic → Reducing the Number of Parameters
(一)Background knowledge
Pre-trained Language Models
Neural Language Models: A neural network that defines the probability over sequences of words.
How are these language models trained? Given an incomplete sentence, predict the rest of the sentence.
Training a langauge model is self-supervised learning。
Pre-trained Language Models有两种Model:
① Autoregressive Language Models (ALMs): Complete the sentence given its prefix.
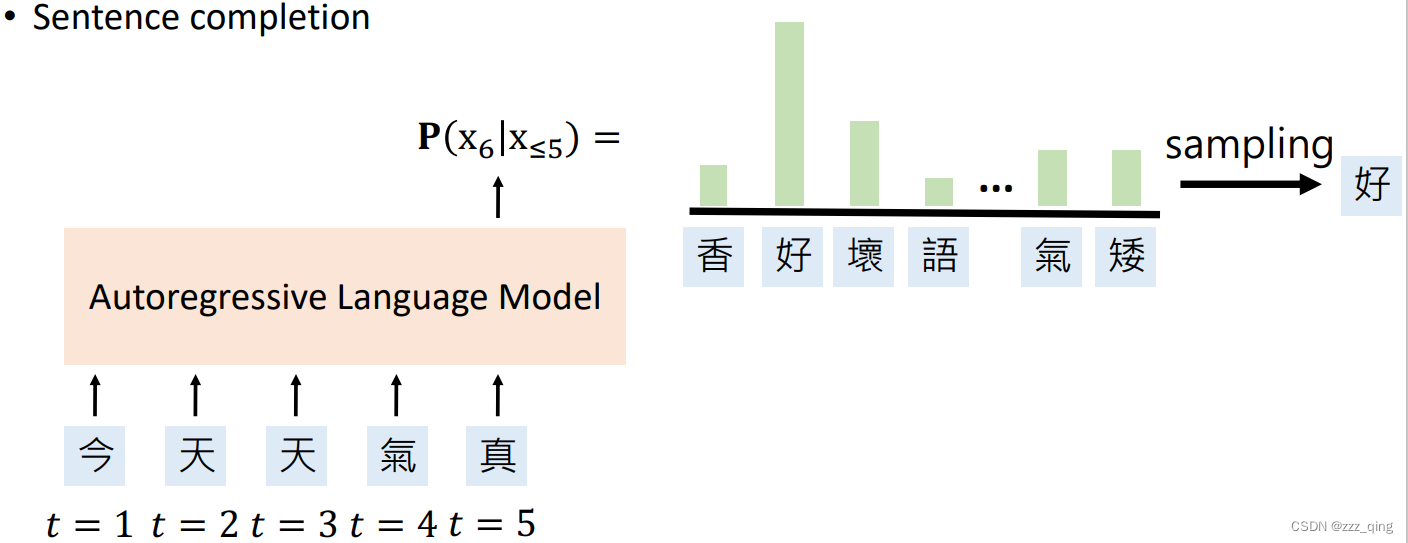
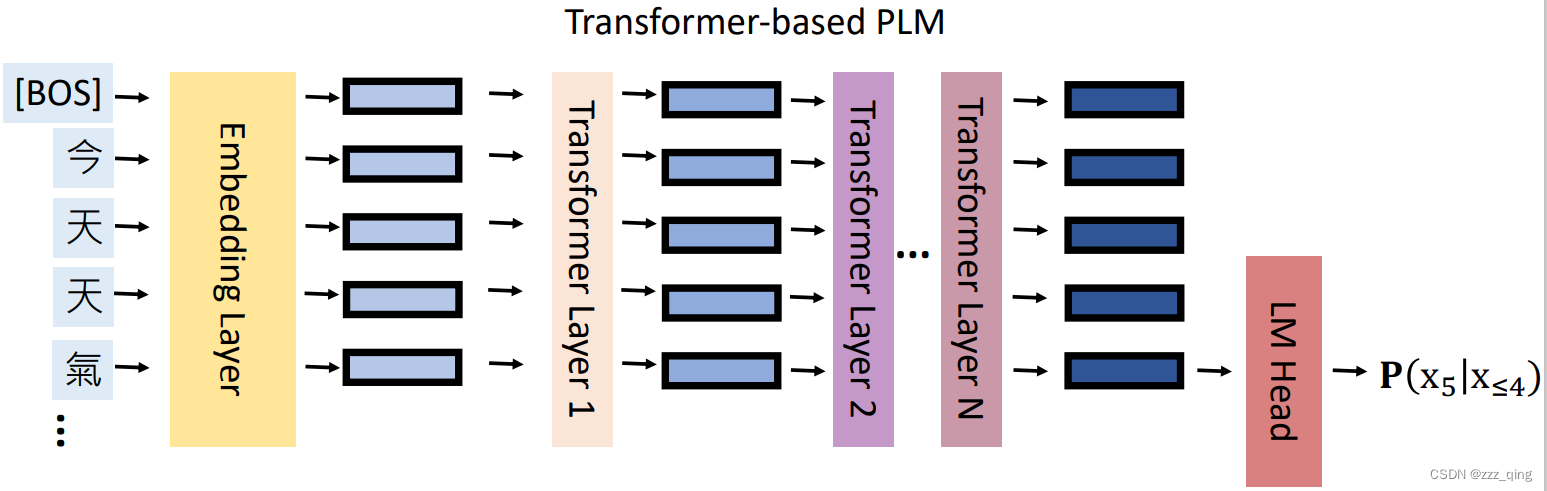
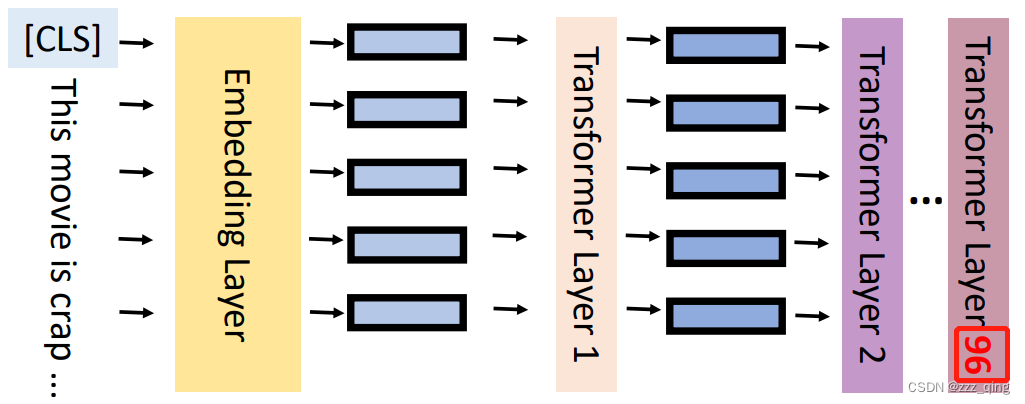
Transformer-based ALMs结构如下图,它由许多堆叠的transformer layer组成:
② Masked Language Models (MLMs): Use the unmasked words to predict the masked word.
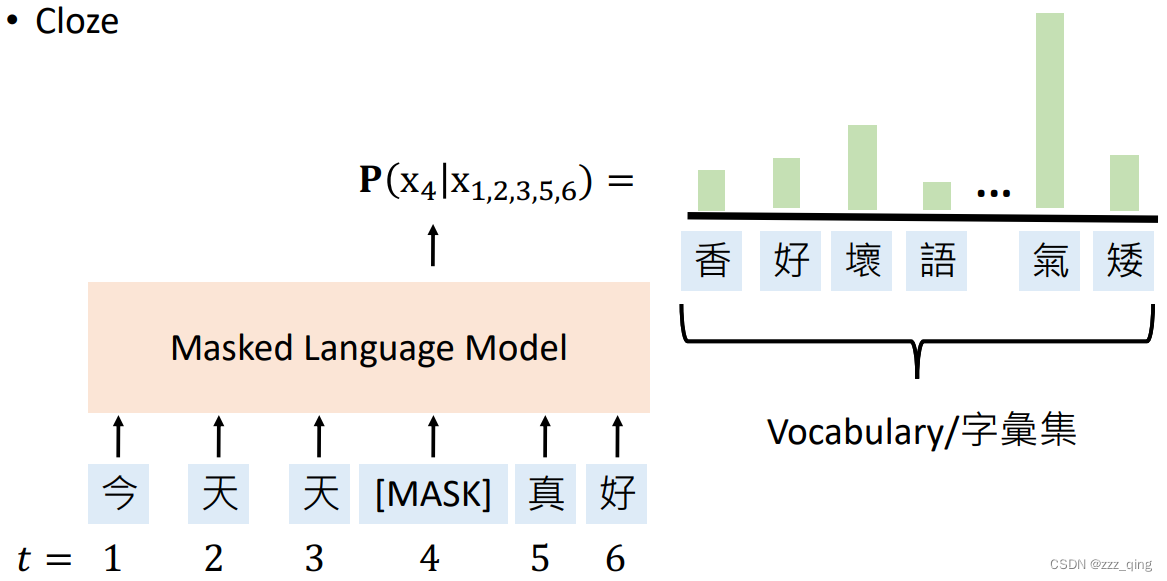
Pre-trained Language Models中的Pre-trained是指使用大型语料库去train一个neural language model。预训练模型有如下两种:
- Autoregressive pre-trained: GPT 系列 (GPT, GPT-2, GPT-3)
- MLM-based pre-trained: BERT 系列 (BERT, RoBERTa, ALBERT)
关于预训练的相关好处、fine-tuning以及GPT和BERT模型均在Self-supervised Learning部分的笔记中有记录,这里不再赘述。
(二)The Problems of PLMs
1. Data scarcity in downstream tasks
A large amount of labeled data is not easy to obtain for each downstream task
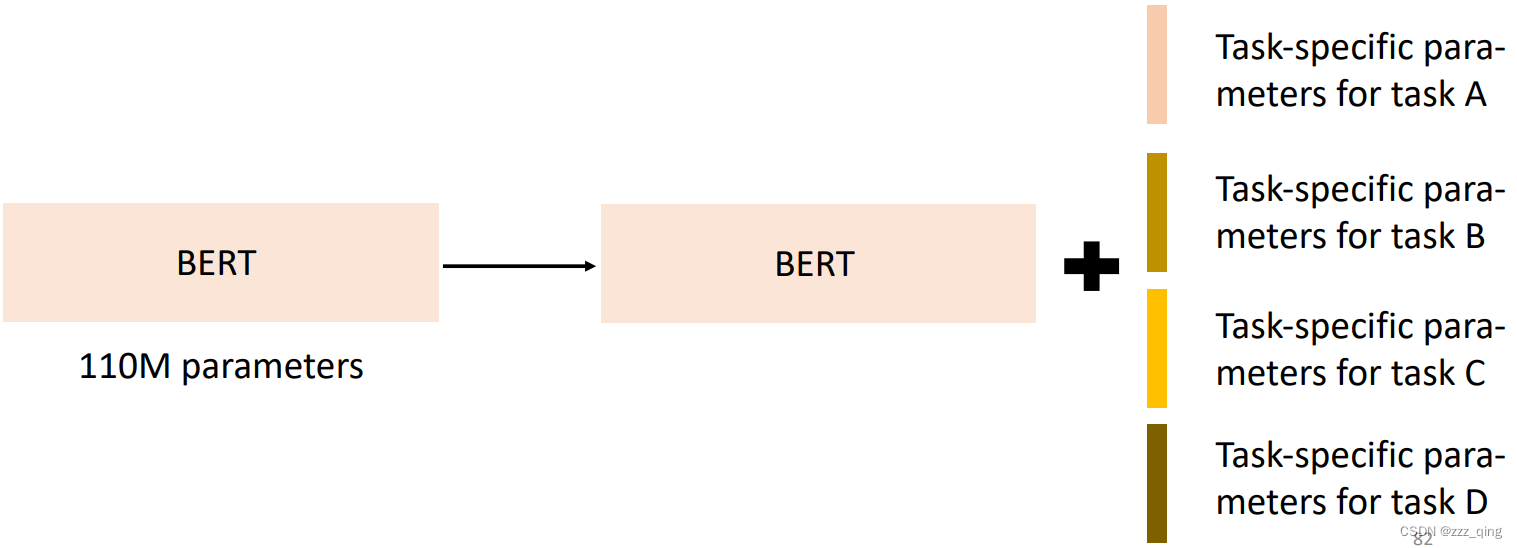
2. The PLM is too big, and they are still getting bigger
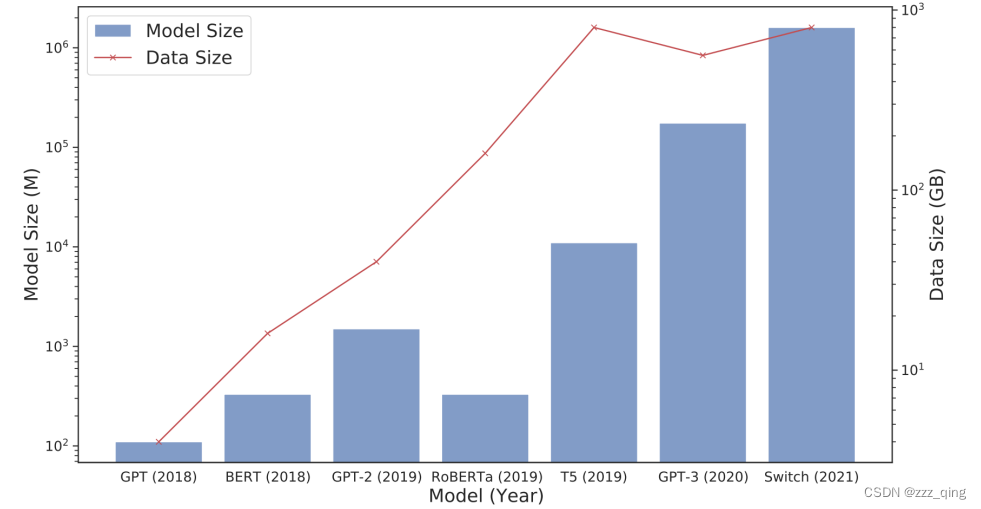
Need a copy for each downstream task:
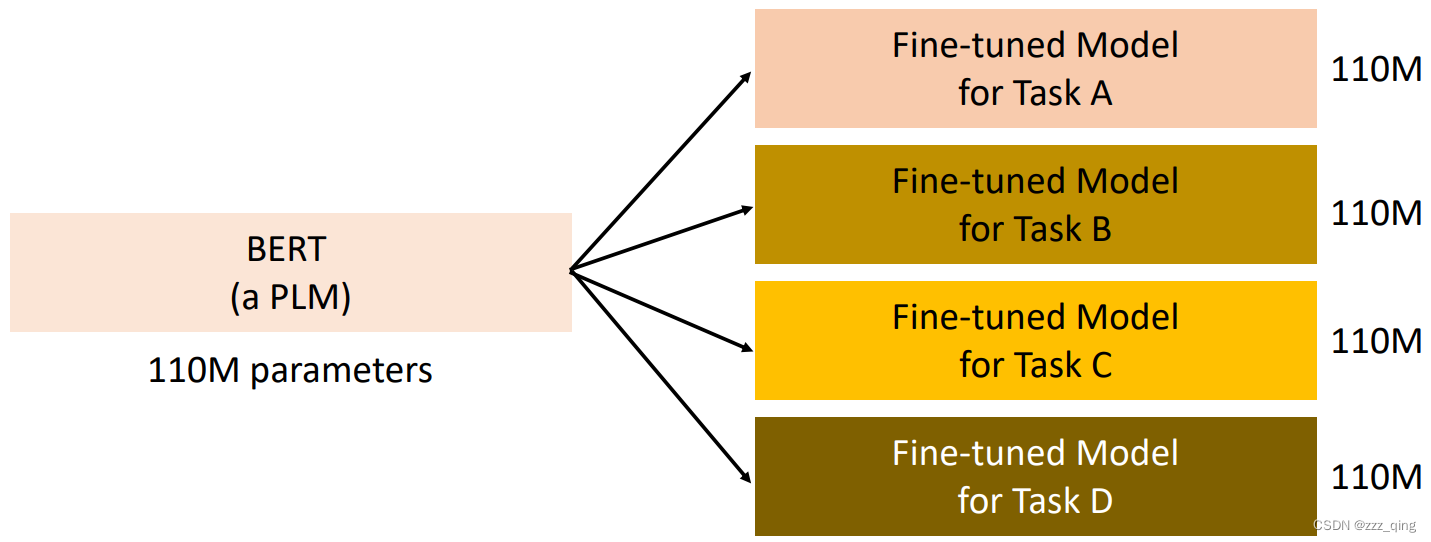
Inference takes too long and Consume too much space:
(三)The Solutions of Those Problems
1. Labeled Data Scarcity → Data-Efficient Fine-tuning
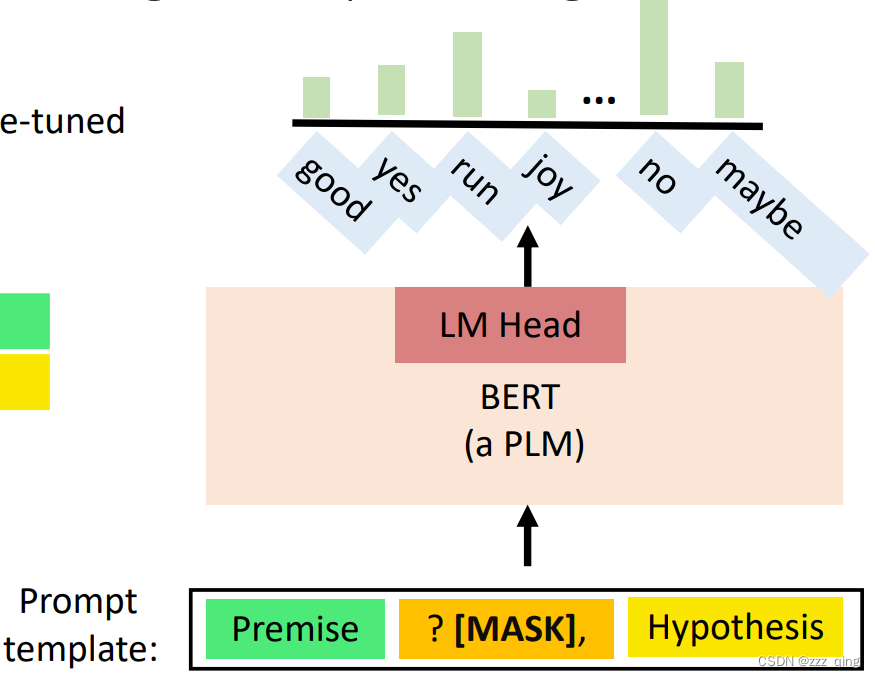
Prompt Tuning——By converting the data points in the dataset into natural language prompts, the model may be easier to know what it should do.
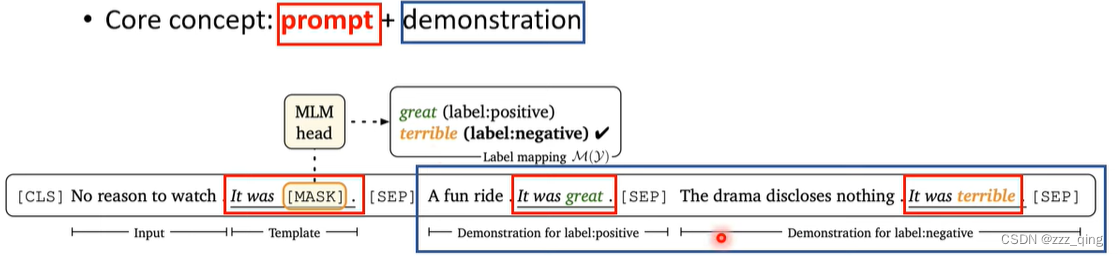
核心概念:设置一些东西让model知道我们在做什么。Format the downstream task as a language modelling task with pre-defined templates into natural language prompt.
In prompt tuning, we need:
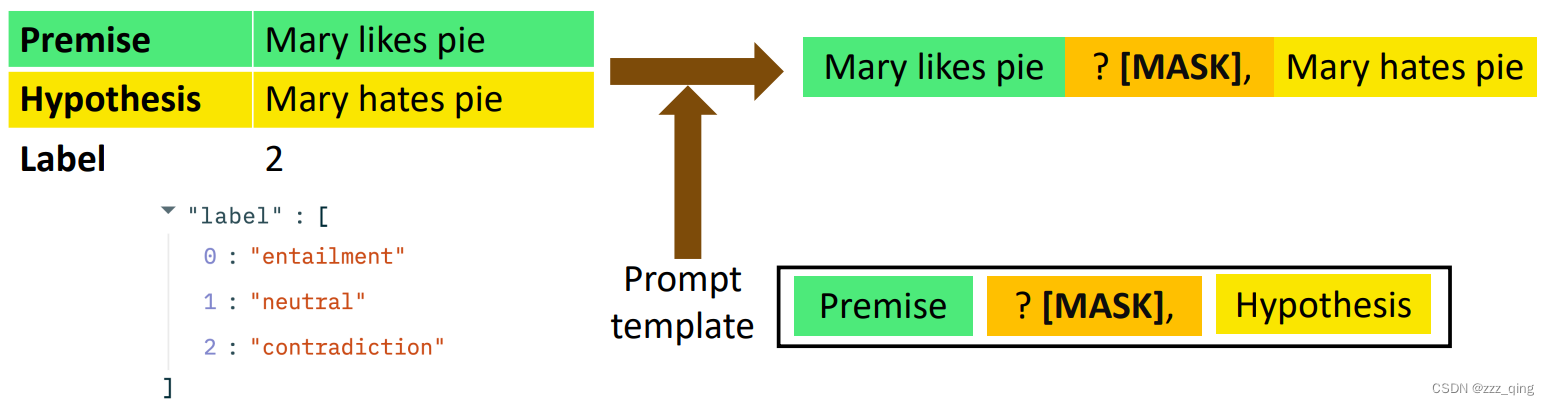
- A prompt template: convert data points into a natural language prompt.
- A PLM: perform language modeling.
- A verbalizer: A mapping between the label and the vocabulary.

Prompt tuning v.s. Standard fine-tuning
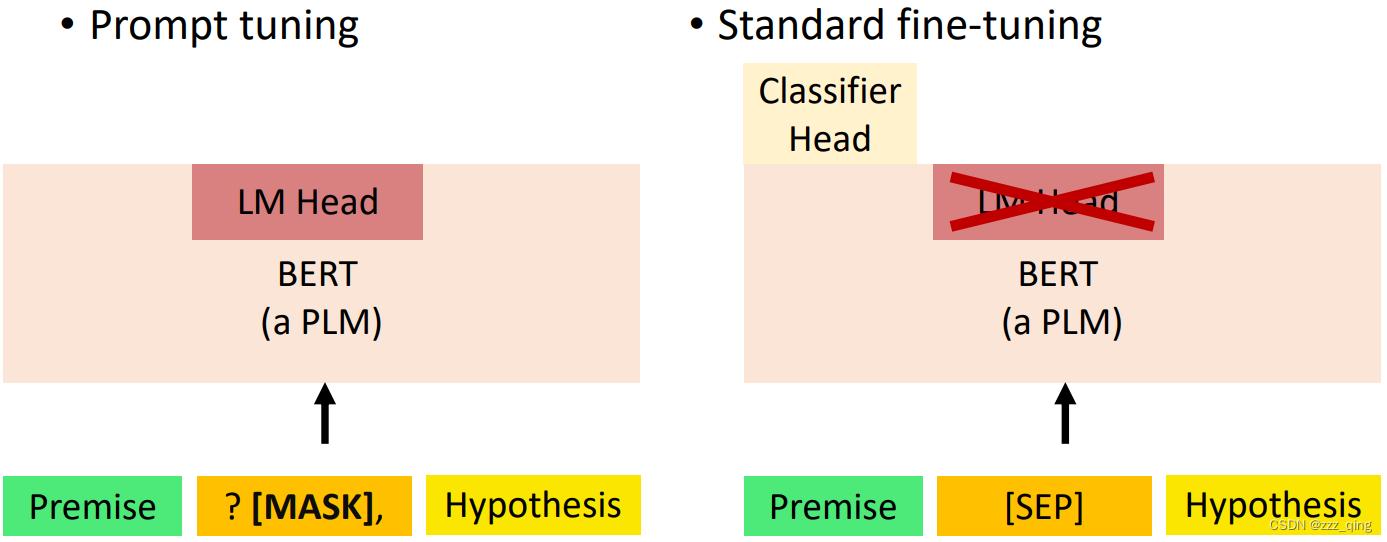
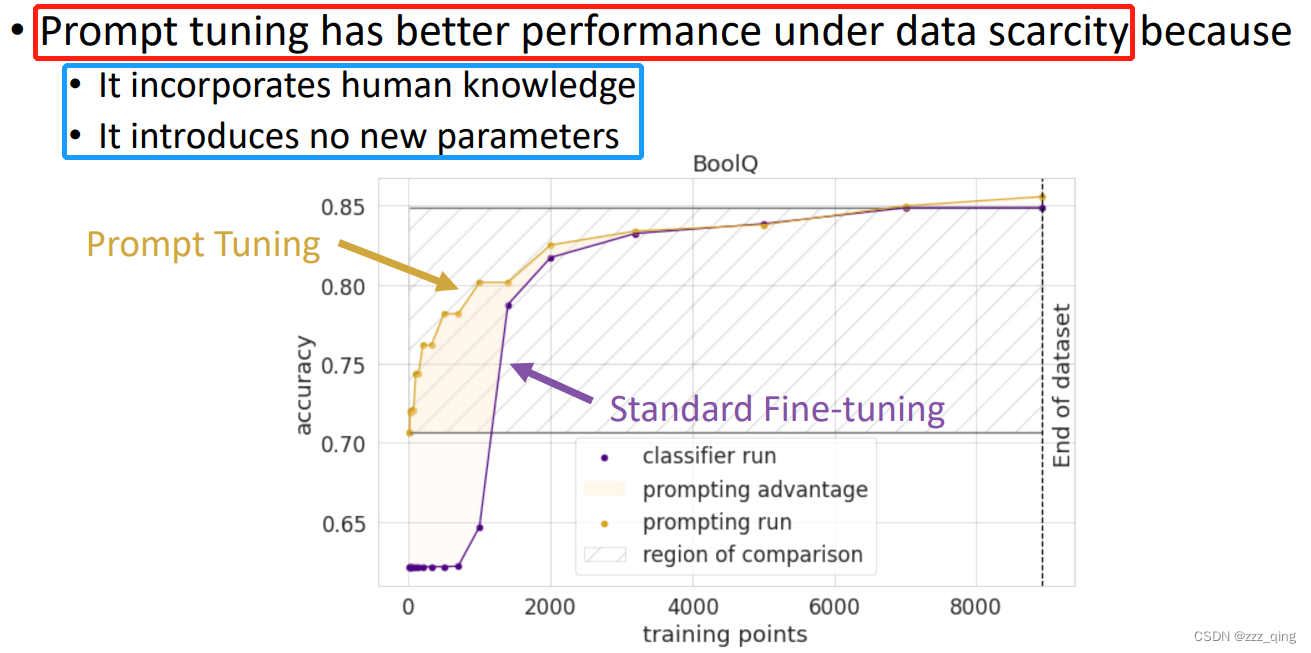
下面介绍数据在不同程度的稀缺下,prompts是如何帮助训练的。
- Few-shot learning: We have some labeled training data.
- Semi-Supervised learning: We have some labeled training data and a large amount of unlabeled data
Pattern-Exploiting Training (PET):
Step 1: Use different prompts and verbalizer to prompt-tune different PLMs on the labeled dataset.
Step 2: Predict the unlabeled dataset and combine the predictions from different models.
Step 3: Use a PLM with classifier head to train on the soft-labeled data set.
- Zero-shot inference: inference on the downstream task without any training data.
如果没有training data,则需要一个可以对downstream tasks进行zero-shot inference的模型。
GPT-3证明在模型足够大的条件下,zero-shot (with task description)是可行的。GPT-3仅根据任务的自然语言描述来预测答案。不执行梯度更新。
2. PLMs Are Gigantic → Reducing the Number of Parameters
- Pre-train a large model, but use a smaller model for the downstream tasks

- Share the parameters among the transformer layers
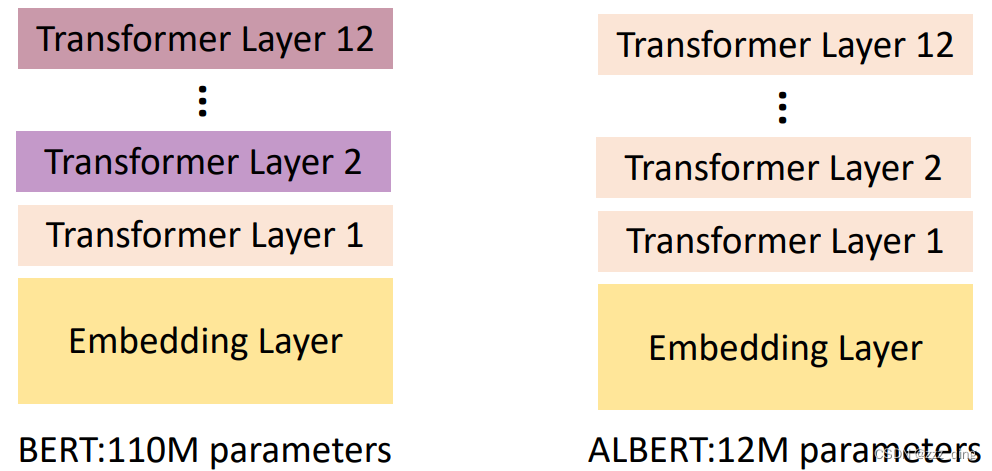
- Parameter-Efficient Fine-tuning: Use a small amount of parameters for each downstream task
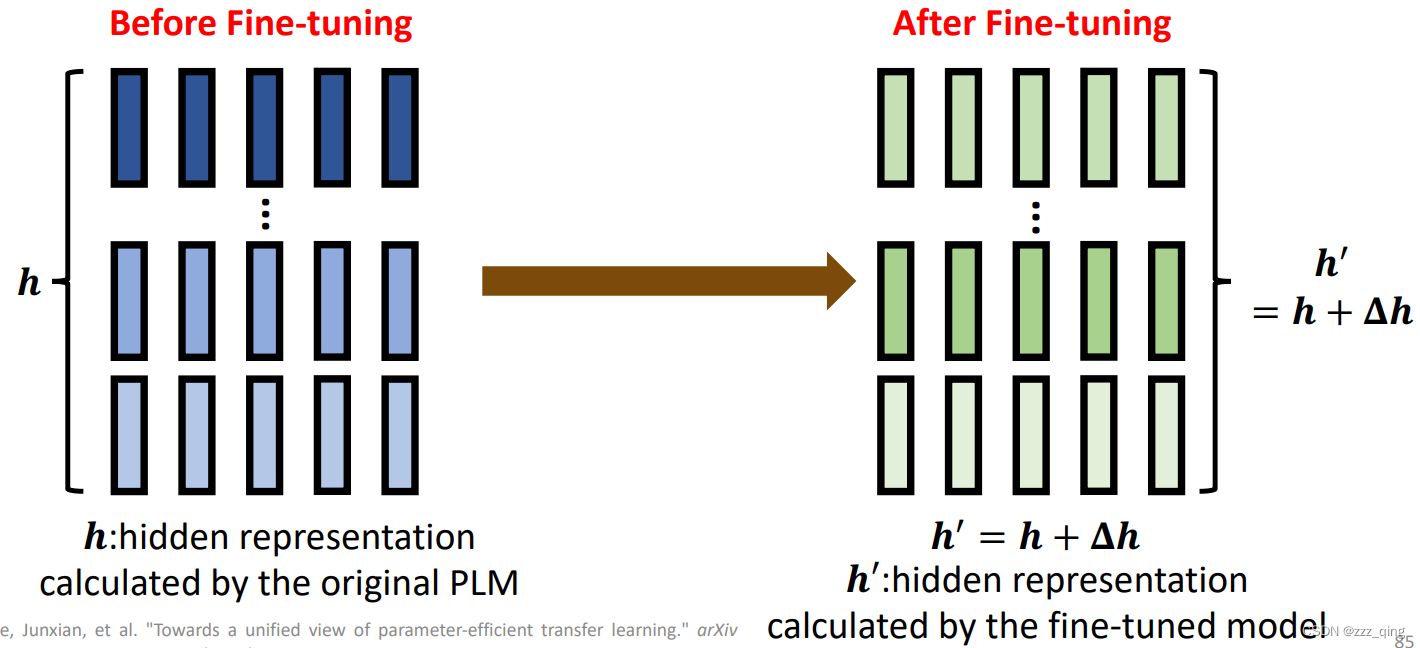
Fine-tuning = modifying the hidden representation based on a PLM
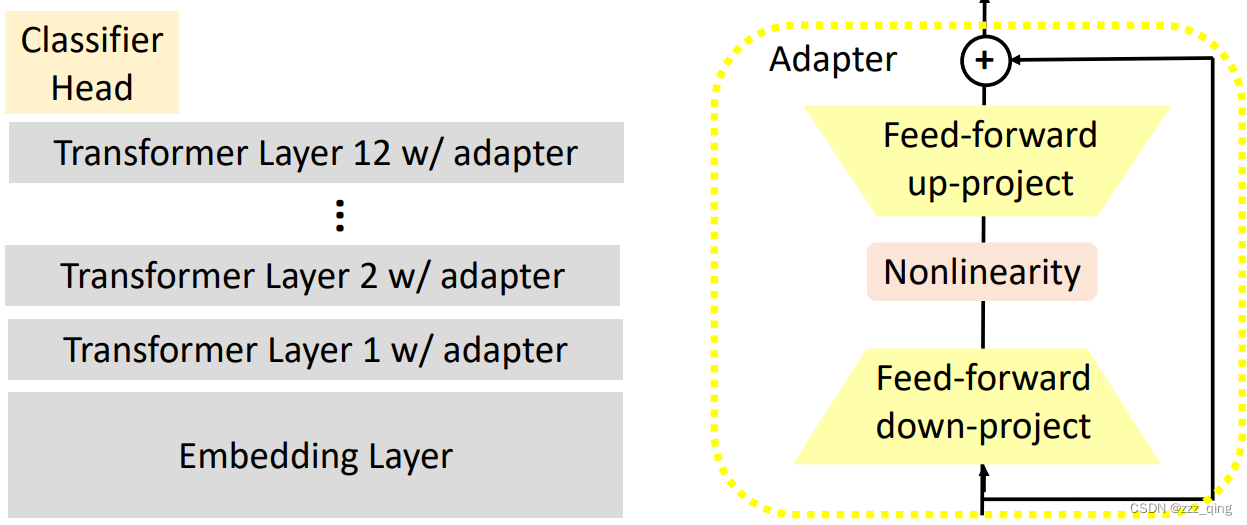
① Adapter: Use special submodules to modify hidden representations
Adapters: small trainable submodules inserted in transformers.
All downstream tasks share the PLM; the adapters in each layer and the classifier heads are the task-specific modules.
During fine-tuning, only update the adpaters and theclassifier head.
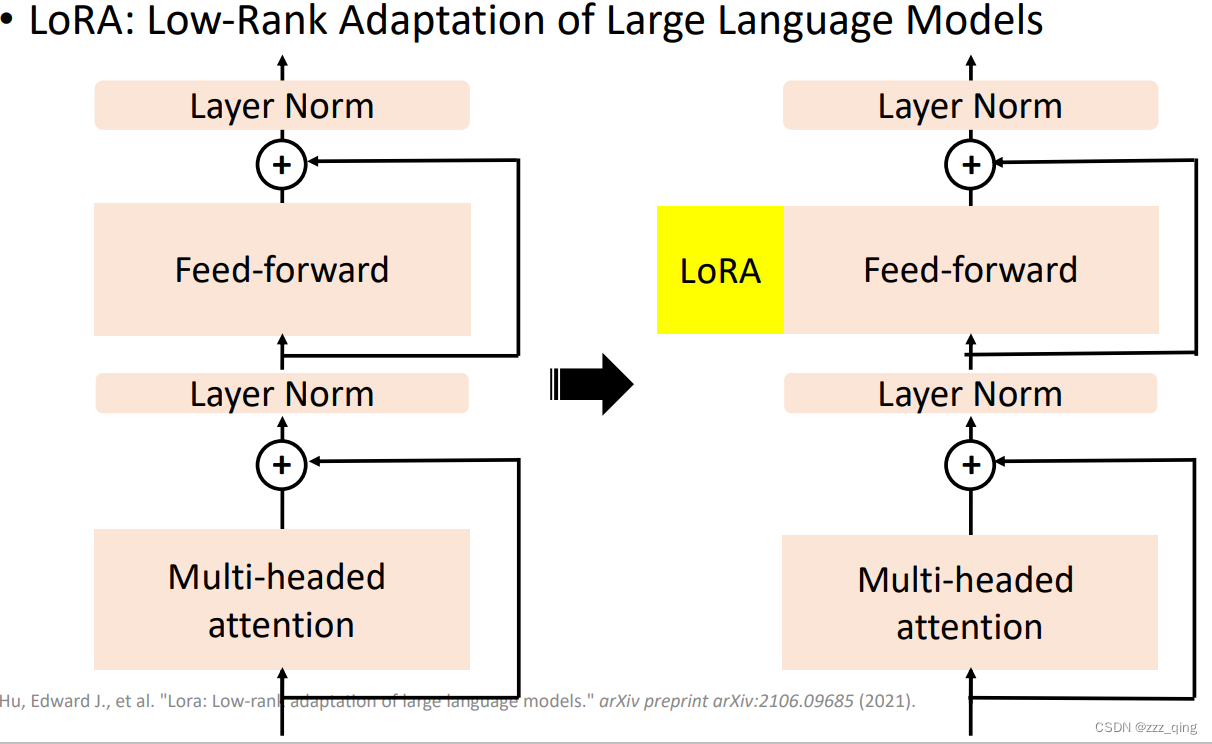
② LoRA: Use special submodules to modify hidden representations!
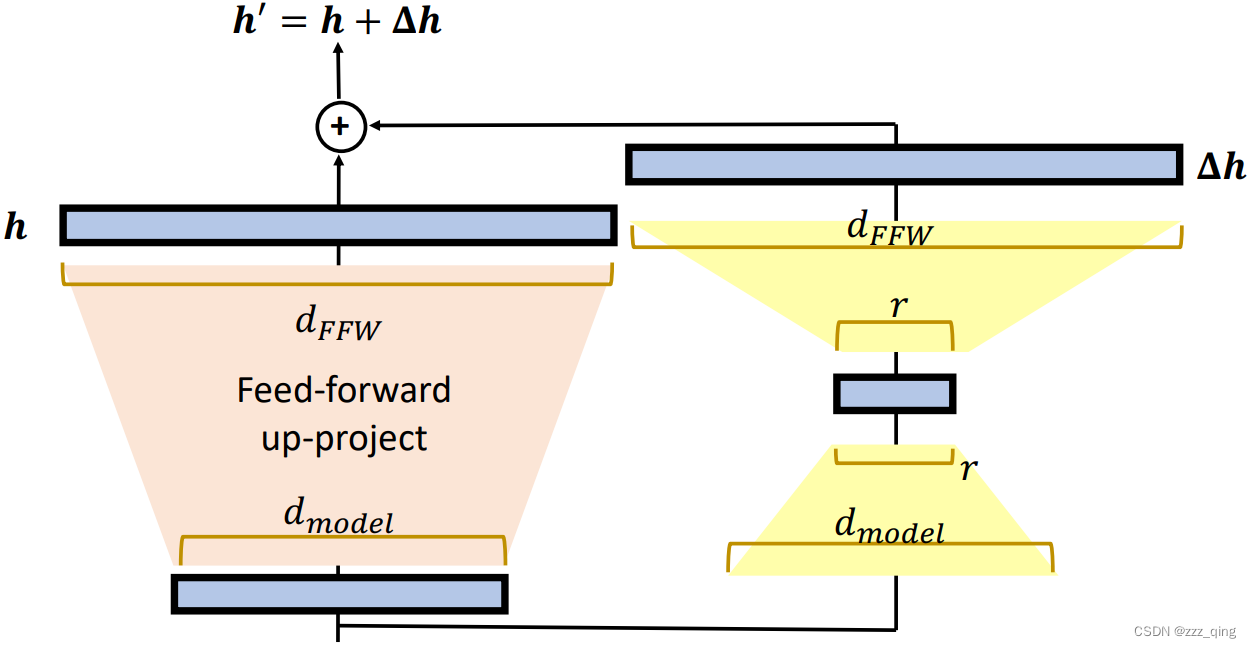
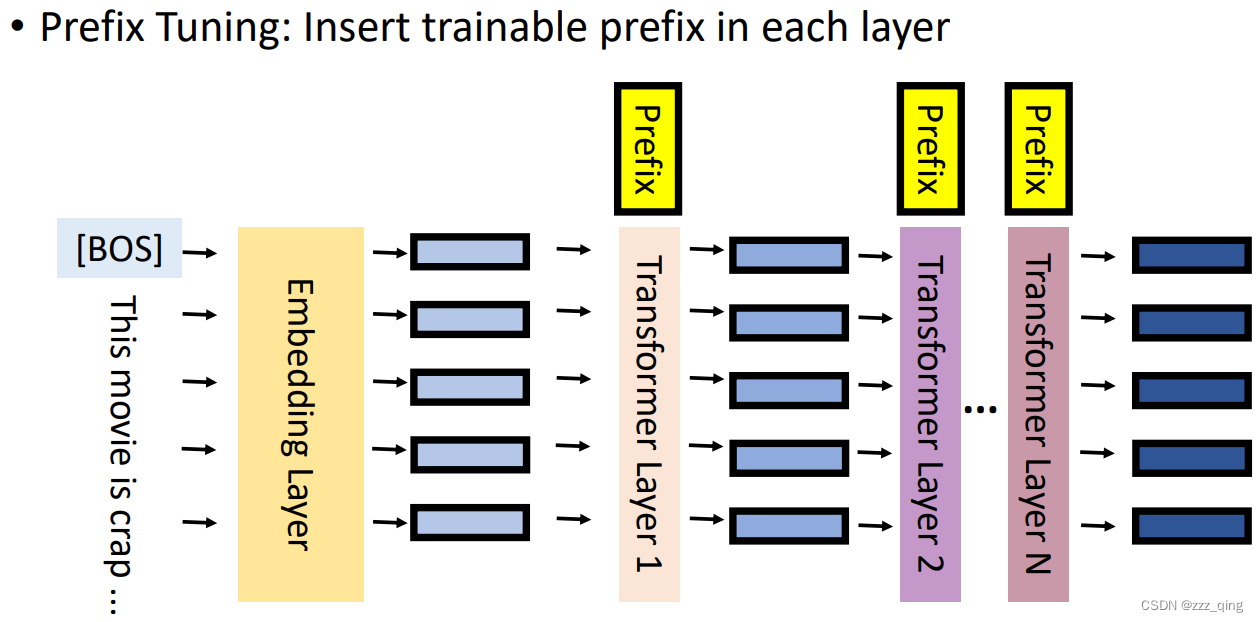
③ Prefix(前缀) Tuning: Use special submodules to modify hidden representations!
④ Soft Prompting: Prepend the prefix embedding at the input layer
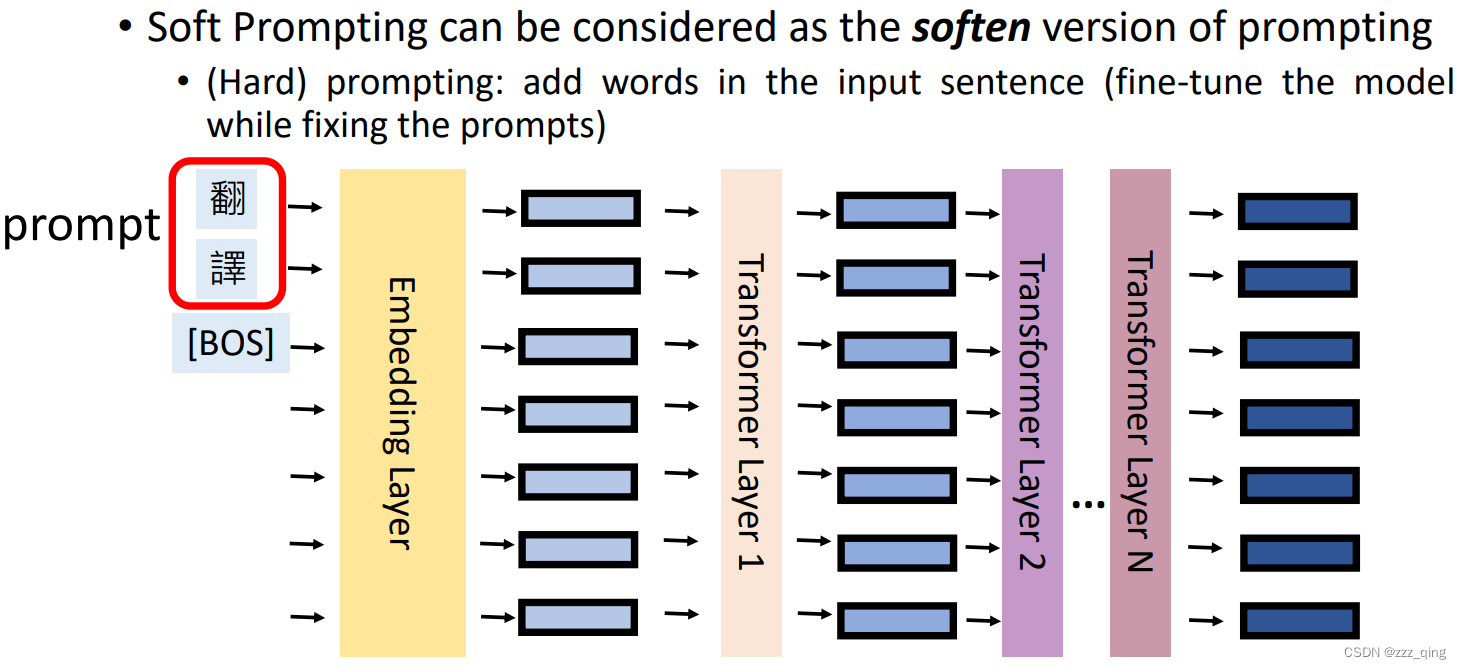
Soft Prompts: vectors (can be initialized from some word embeddings)
Hard Prompts: words (that are originally in the vocabulary
Parameter-Efficient Fine-tuning的benifit有如下三点:
① 极大地减少了用于特定任务的参数
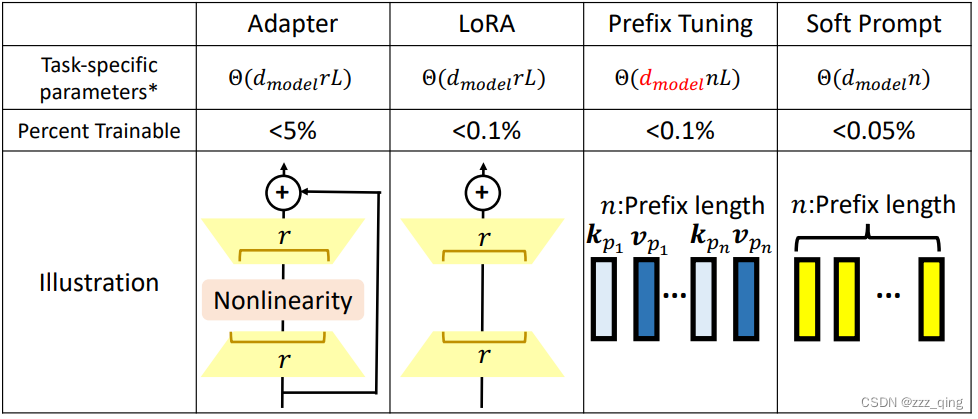
② 训练数据不容易过拟合,更好的better out-of-domain performance
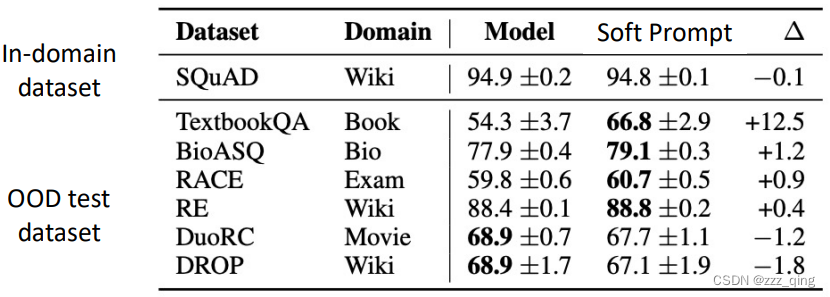
③ fine-tune更少的parameters,小数据集训练时的一个很好的候选















 1708
1708











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









