






智谱AI&清华KEG 7月14日公告,为了更好地支持国产大模型开源生态的繁荣发展,经智谱AI及清华KEG实验室决定,自即日起ChatGLM-6B和ChatGLM2-6B权重对学术研究完全开放,并且在完成企业登记获得授权后,允许免费商业使用。
然后我在huggingface上看到清华开源大语言模型chatglm2-6b下载量已经突破了120万次,确实挺火的。今天跟大家分享一下我私有化部署这个大模型的一些实践经验。
首先说一下我为什么要私有化部署清华开源的大语言模型,核心原因就是一个,目前市面上的大语言模型太贵了,根本用不起。我之前测算使用OpenAI最便宜的模型gpt-3.5-turbo来做一些事情,一个月也得好几千,另外gpt-3.5-turbo对token长度有限制,这个会影响业务的效果,所以一般会用gpt-3.5-turbo-16k,这个价格就会翻倍。如果你还想用效果更好的gpt-4,对不起,价格是gpt-3.5-turbo的20倍,如果还觉得token不够长,用gpt-4-32k,价格是gpt-3.5-turbo的40倍。私有化部署一个开源的大语言模型能够极大程度降低这部分的成本,当然效果也会有一些差异,不过体验之后普遍反馈chatglm2-6b效果还不错。
私有化部署前期准备
1.清华开源大语言模型的github开源代码
https://github.com/THUDM/ChatGLM-6B
2.huggingface上大语言模型的下载地址
https://huggingface.co/THUDM/chatglm2-6b``https://huggingface.co/THUDM/chatglm-6b
3.硬件准备
同事提前帮我准备了32GB的GPU,英伟达V100,这样才能带动清华大语言模型。当然硬件不够也有解决方案,我是想充分测试大模型的效果,所以硬件尽可能满足大模型的需求。
其他配置要求不高,内存32GB,硬盘200GB,CentOS8系统。
通过lspci这个命令可以查看显卡GPU信息,果然是V100 32GB。
3D controller: NVIDIA Corporation GV100GL [Tesla V100 SXM2 32GB] (rev a1)
部署过程
1.本机下载github代码库
先ssh到服务器上面,发现git都没有装,马上装git,各种yum install,发现比较慢就用清华大学开源软件镜像站,yum带上-i https://pypi.tuna.tsinghua.edu.cn/simple即可。之后执行
git clone git@github.com:THUDM/ChatGLM-6B.git
发现没有权限,还得配置github的SSH key,本机ssh-keygen可以生成秘钥串,将公钥贴到github的Authentication Keys即可,这样git clone就可以成功了。
2.下载huggingface上的大语言模型
得智能上网才能访问huggingface的网站,并且还得是特殊的线路,大语言模型基本都是10GB起步,下载速度也非常慢,这部分是比较头疼的。最开始我想自己在服务器挂代理下载大模型。之后执行
git clone https://huggingface.co/THUDM/chatglm-6b
发现需要安装git-lfs,让git能够下载大文件。
这是下载地址
https://github.com/git-lfs/git-lfs/blob/main/INSTALLING.md
执行安装命令
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.rpm.sh | sudo bash
通过命令git lfs install可以验证是否安装成功
接着给git配置代理信息
git config --global http.proxy 'socks5://IP:PORT'``git config --global https.proxy 'socks5://IP:PORT’
然后就可以git clone https://huggingface.co/THUDM/chatglm-6b,发现下载很慢,另外我自己的线路一个月才50GB,下几个大模型就没法智能上网了。
我最后是让同事找了一条快的线路帮我下载的,本机下载好之后再scp上去,大模型文件放在ChatGLM-6B/THUDM这个目录下。
3.python运行大模型
这个时候就迫不及待的想把大模型跑起来了,发现有一些前置要求,比如先要安装requirements.txt中的一些依赖库
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
这个时候遇到了很多问题,一个个来说吧。
首先是python版本不够,需要升级,果断安装了python3.11,需要通过源码安装。
果断本机wget源码,然后scp到服务器。
sudo wget https://www.python.org/ftp/python/3.11.4/Python-3.11.4.tgz``scp Python-3.11.4.tgz root@内网IP:/opt/
这个时候系统有多个python版本,设置python3.11为默认的命令如下
alternatives --install /usr/bin/pip pip /usr/local/bin/pip3.11 1 && alternatives --set pip /usr/local/bin/pip3.11``/usr/local/bin/python3.11 -m pip install --upgrade pip
然后就可以执行清华大语言模型的依赖安装了
pip3.11 install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
这个还比较顺利,然后我就想在终端跑一下大模型了。
然后就想执行python3.11 cli_demo.py,发现需要安装readline,下面是安装命令
pip3.11 install -i https://pypi.tuna.tsinghua.edu.cn/simple readline
结果报错
ERROR: Failed building wheel for readline
这个地方各种找解决方案,后来发现是依赖的问题,果断执行如下命令
先安装这个yum install ncurses,好像不行
再安装这个yum install ncurses-devel,好像就可以了
vim cli_demo.py的时候发现有中文乱码的问题,解决方法如下:
执行这个命令vim ~/.vimrc
加上这一行即可set encoding=utf-8
然后执行python3.11 cli_demo.py可以跑起来了,但是会出现报错
double free or corruption (out)``Aborted (core dumped)
但是我自己写的一个测试代码执行就是ok,这个地方折腾了半天没弄明白。
此路不通走彼路,我又换web的demo测试。
python3.11 web_demo.py
也跑起来了,但是因为是服务器我没法直接打开浏览器localhost体验,于是curl试了一下,确认是跑起来了。
然后看到一句提示
To create a public link, set `share=True` in `launch()`.
于是改了下代码share=True,发现还是不行,应该是端口的问题,于是开启防火墙的配置。
systemctl start firewalld``sudo firewall-cmd --zone=public --add-port=7860/tcp —permanent
再执行python3.11 web_demo.py,果然出现了一条临时的公网gradio链接可以访问了。
后来我想在内网通过ip直接访问,有安全考量,也有费用考量,毕竟GPU也挺贵的,就不用什么临时链接了,于是搭了一个nginx服务器。
yum install nginx
然后进行nginx的配置,核心是把80端口转发到本机的7860端口
server {` `listen 80;` `server_name localhost;` `location / {` `proxy_pass http://localhost:7860;` `proxy_set_header Host $host;` `proxy_set_header X-Real-IP $remote_addr;` `proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;` `proxy_set_header X-Client-Verify SUCCESS;` `proxy_set_header X-Client-DN $ssl_client_s_dn;` `proxy_set_header X-SSL-Subject $ssl_client_s_dn;` `proxy_set_header X-SSL-Issuer $ssl_client_i_dn;` `proxy_set_header X-Forwarded-Proto http;` `proxy_read_timeout 1800;` `proxy_connect_timeout 1800;` `}` `}
然后启动nginx
sudo systemctl start nginx
查看nginx状态
sudo systemctl status nginx
另外需要把web_demo.py里面的代码改成share=False
执行python3.11 web_demo.py
http://内网IP 就可以访问了
这个时候通过本机浏览器访问内网服务器IP就可以直接打开demo的页面了。
但是进行功能体验的时候发现websocket相关的报错,发现是nginx转发针对websocket还需要做一些配置,主要是下面三个配置
proxy_http_version 1.1``This directive converts the incoming connection to HTTP 1.1, which is required to support WebSockets. The older HTTP 1.0 spec does not provide support for WebSockets, and any requests using HTTP 1.0 will fail.``proxy_set_header Upgrade $http_upgrade``Converts the proxied connection to type Upgrade. WebSockets only communicate on Upgraded connections.``proxy_set_header Connection “upgrade”;``Ensure the Connection header value is upgrade
把这三个配到nginx的conf里面就可以了。
然后重启nginx
sudo systemctl restart nginx
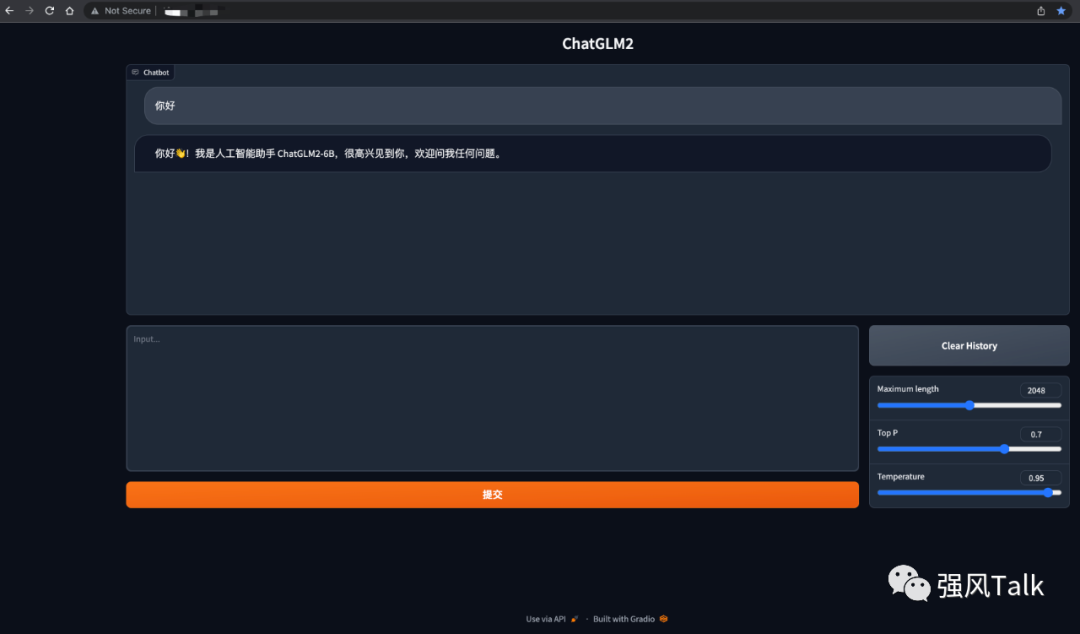
这个时候就算大功告成了,来个截图吧。
偶尔想看服务器gpu使用情况,执行如下命令即可
nvidia-smi
今天就分享这么多吧。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
-END-
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









