







近期大家都知道阿里推出了自己的开源的大模型千问72B,据说对于中文非常友好,在开源模型里面,可谓是名列前茅。

千问拥有有强大的基础语言模型,已经针对多达 3 万亿个 token 的多语言数据进行了稳定的预训练,覆盖领域、语言(重点是中文和英文)。
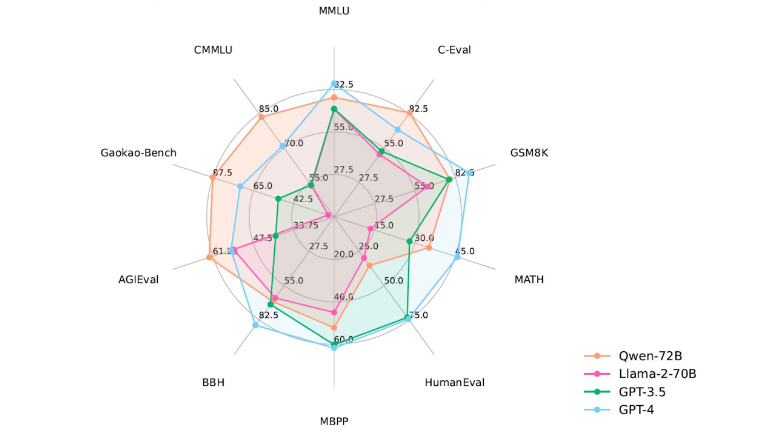
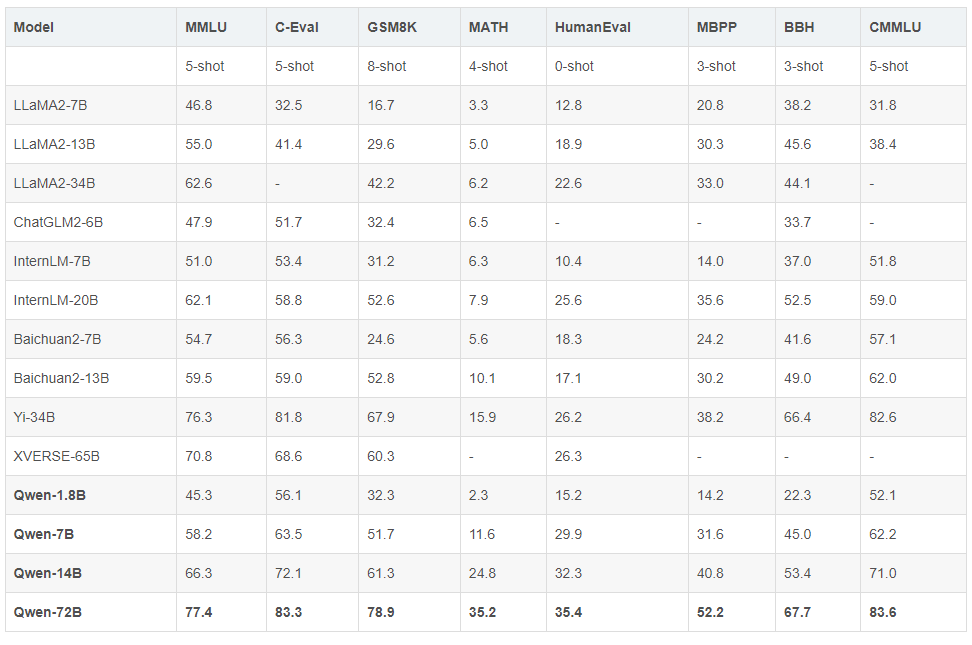
Qwen 模型在一系列基准数据集(例如 MMLU、C-Eval、GSM8K、MATH、HumanEval、MBPP、等)上优于类似模型大小的基线模型,这些数据集评估了模型在自然语言理解、数学方面的能力Qwen-72B 在所有任务上都比 LLaMA2-70B 取得了更好的性能,并且在 10 任务中的 7 个上优于 GPT-3.5。
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
建了技术交流群&星球!想要本文源码、进交流群的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司,即可。然后就可以拉你进群了。
方式①、添加微信号:mlc2060,备注:技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:技术交流


部署
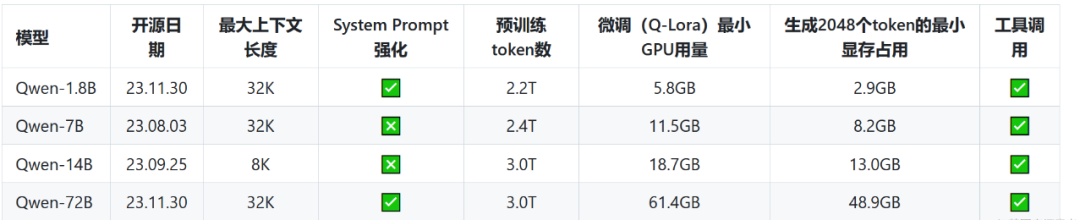
从下图我们可以看到,千问大模型的版本逐渐升级,对于显卡的要求也是逐渐变高,一张4090恐怕已经难以支持,想要省钱的小伙伴可以选择共享算力平台。
算力共享平台
环境和硬件准备
-
python 3.8及以上版本
-
pytorch 1.12及以上版本,推荐2.0及以上版本
-
建议使用CUDA 11.4及以上(GPU用户、flash-attention用户等需考虑此选项)
-
运行BF16或FP16模型需要多卡至少144GB显存(例如2xA100-80G或5xV100-32G)
-
运行Int4模型至少需要48GB显存(例如1xA100-80G或2xV100-32G)
部署
下载项目或者用git命令下去项目,解压后。
项目地址:https://github.com/QwenLM/Qwen
如果不用 docker,满足上述要求,安装依赖。
pip install -r requirements.txt
如果您的设备支持fp16或bf16,我们建议安装flash-attention(我们现在支持flash Attention 2。)以获得更高的效率和更低的内存占用。(flash-attention是可选的,项目无需安装即可正常运行)
git clone https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .# Below are optional. Installing them might be slow.# pip install csrc/layer_norm# If the version of flash-attn is higher than 2.1.1, the following is not needed.# pip install csrc/rotary
Transformers
from transformers import AutoModelForCausalLM, AutoTokenizerfrom transformers.generation import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-1_8B-Chat", trust_remote_code=True)
# Only Qwen-72B-Chat and Qwen-1_8B-Chat has system prompt enhancement now.model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-1_8B-Chat", device_map="auto", trust_remote_code=True).eval()# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-72B-Chat", device_map="auto", trust_remote_code=True).eval()
response, _ = model.chat(tokenizer, "你好呀", history=None, system="请用二次元可爱语气和我说话")print(response)# 你好啊!我是一只可爱的二次元猫咪哦,不知道你有什么问题需要我帮忙解答吗?
response, _ = model.chat(tokenizer, "My colleague works diligently", history=None, system="You will write beautiful compliments according to needs")print(response)# Your colleague is an outstanding worker! Their dedication and hard work are truly inspiring. They always go above and beyond to ensure that their tasks are completed on time and to the highest standard. I am lucky to have them as a colleague, and I know I can count on them to handle any challenge that comes their way.
Web UI
pip install -r requirements_web_demo.txt
python web_demo.py


















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









