







最近已有不少大厂已停止秋招宣讲了。节前,我们邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对新手如何入门算法岗、该如何准备面试攻略、面试常考点、大模型技术趋势、算法项目落地经验分享等热门话题进行了深入的讨论。
总结链接如下:
喜欢本文记得收藏、关注、点赞
01 引言
近期,Meta开源了Llama 3.3 多语言大型语言模型(LLM),Llama 3.3 是一个预训练并经过指令调优的生成模型,参数量为70B(文本输入/文本输出)。Llama 3.3 指令调优的纯文本模型针对多语言对话用例进行了优化,并在常见的行业基准测试中优于许多可用的开源和闭源聊天模型。
Llama 3.3 是一个使用优化后的Transformer架构的自回归语言模型。调优版本使用监督微调(SFT)和基于人类反馈的强化学习(RLHF)来与人类对有用性和安全性的偏好保持一致。
-
训练数据:新的公开在线数据混合集
-
参数量:70B
-
输入模态:多语言文本
-
输出模态:多语言文本和代码
-
上下文长度:128K
-
GQA:是
-
训练tokens:15T+(仅指预训练数据)
-
知识截止日期:2023年12月
-
支持的语言: 英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语
02 模型推理
transformers推理
import transformers
import torch
from modelscope import snapshot_download
model_id = snapshot_download("LLM-Research/Llama-3.3-70B-Instruct")
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
outputs = pipeline(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
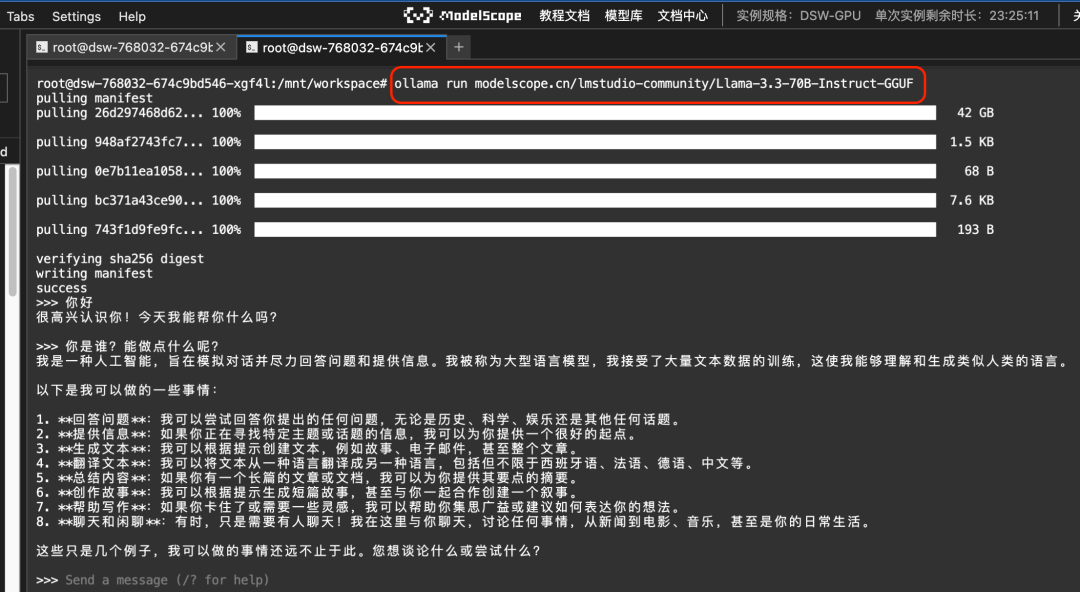
Ollama:一行命令运行魔搭上的 Llama-3.3-70B-Instruct GGUF模型
- 设置ollama下启用
ollama serve
- ollama run ModelScope任意GGUF模型,指定model id即可:
ollama run modelscope.cn/lmstudio-community/Llama-3.3-70B-Instruct-GGUF
03 模型推理
这里我们介绍使用ms-swift 3.0对Llama3.3进行自我认知微调。
在开始微调之前,请确保您的环境已正确安装
# 安装ms-swift
pip install git+https://github.com/modelscope/ms-swift.git
微调脚本如下:
CUDA_VISIBLE_DEVICES=0,1 swift sft \
--model LLM-Research/Llama-3.3-70B-Instruct \
--dataset AI-ModelScope/alpaca-gpt4-data-zh#500 \
AI-ModelScope/alpaca-gpt4-data-en#500 \
swift/self-cognition#500 \
--train_type lora \
--lora_rank 8 \
--lora_alpha 32 \
--num_train_epochs 1 \
--logging_steps 5 \
--torch_dtype bfloat16 \
--max_length 2048 \
--learning_rate 1e-4 \
--output_dir output \
--target_modules all-linear \
--model_name 小黄 'Xiao Huang' \
--model_author 魔搭 ModelScope \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 16
训练显存占用:

推理脚本:
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/vx-xxx/checkpoint-xxx \
--stream true
推理效果:


















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









