






每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

2025年4月28日,阿里巴巴旗下的Qwen团队正式发布其最新一代大型语言模型——Qwen3系列,标志着Qwen家族在大模型研发路径上的重要升级。面对当前大语言模型(LLM)在多语种理解、复杂推理能力与推理效率方面存在的关键痛点,Qwen3致力于通过体系化创新解决这些限制,尤其是在灵活推理、多语言泛化以及长上下文处理方面提出了新解法,为真实环境下的多样化应用场景提供更具适配性的模型支持。
Qwen3发布:针对性回应LLM当前短板
Qwen3系列是对前代Qwen模型架构与能力的全面拓展,其目标是打造兼具高效能推理能力、多语言适配性与可扩展架构的全能型语言模型家族。该系列集成了稠密模型与专家混合架构(MoE),并面向研究与生产环境同步优化,适用于自然语言理解、代码生成、数学推理及多模态任务等多个场景。
核心技术创新与架构提升
1. 混合推理模式(Hybrid Reasoning)
Qwen3引入了一项独特的能力:模型可在“思考模式”与“非思考模式”之间动态切换。在“思考模式”中,模型采用逐步逻辑推理方式处理问题,适用于数学证明、复杂编程、科研分析等任务;而在“非思考模式”下,模型则快速输出结果,优化响应速度,确保轻量查询处理效率与准确性之间的平衡。
2. 多语言能力显著扩展
Qwen3支持超过100种语言及方言,覆盖面远超前代版本,在多语种翻译、生成与语境理解任务中展现出更高的准确性与适应性,满足全球化应用需求。
3. 多尺寸、多架构模型阵列
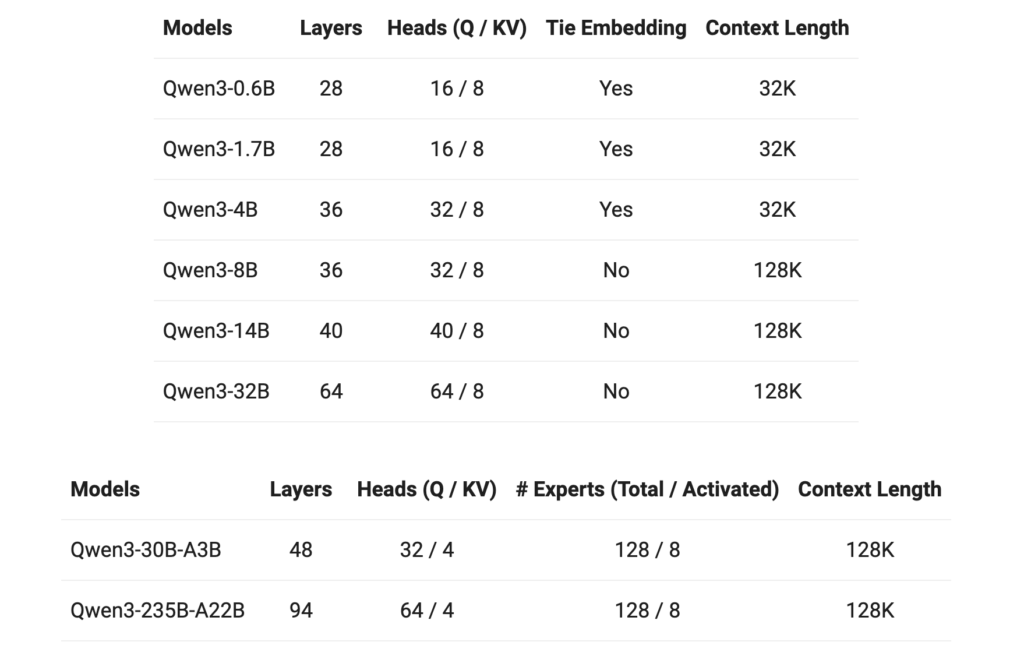
Qwen3系列从0.5B参数(稠密模型)到235B参数(MoE模型)不等。其中旗舰版本Qwen3-235B-A22B在每次推理时仅激活22B参数,实现高性能与计算成本之间的优化平衡。更小型号如Qwen3-30B-A3B也展现出卓越的效率表现。
4. 长上下文支持能力增强
部分Qwen3模型支持最长128K tokens的上下文窗口,使其能够高效处理超长文档、庞大代码文件或多轮对话,解决当前模型在长文本语境下性能衰减的问题。
5. 高质量训练语料构建
Qwen3基于全新优化的数据集构建流程,提升数据来源的多样性与质量控制,显著降低模型幻觉率,并增强跨领域泛化能力。
值得一提的是,Qwen3基础模型以开放许可证发布(适用于特定用途),为研究者与开源社区提供了更多实验与二次开发空间。
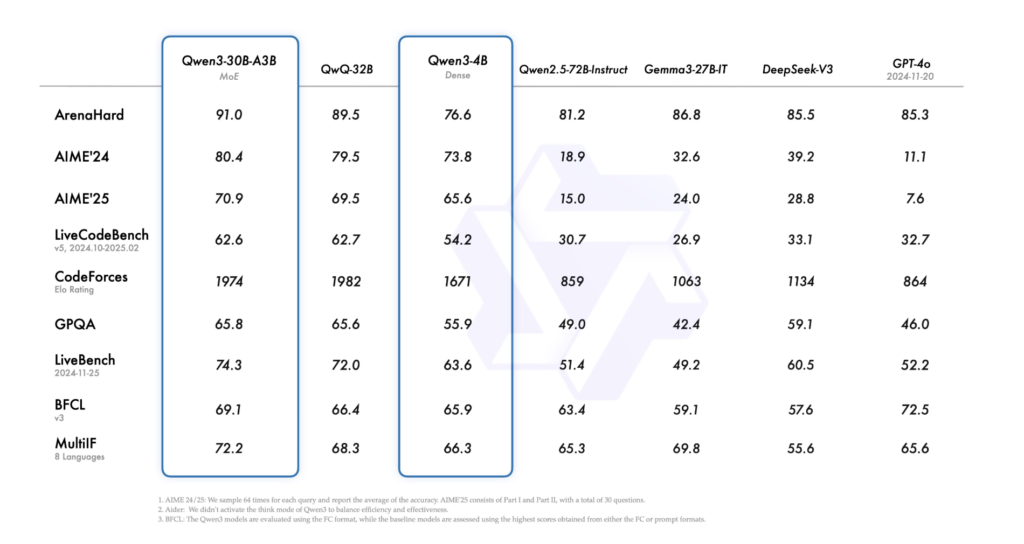
基准测试与评估表现
初步基准测试结果显示,Qwen3系列在多个任务中表现出强劲竞争力:
- Qwen3-235B-A22B在代码生成(HumanEval、MBPP)、数学推理(GSM8K、MATH)与通用知识类任务中成绩优异,性能与DeepSeek-R1、Gemini 2.5 Pro系列相当;
- Qwen3-72B与Qwen3-72B-Chat展现出卓越的指令跟随与对话能力,相较Qwen1.5与Qwen2有显著提升;
- 尤其值得关注的是,Qwen3-30B-A3B(激活参数3B的MoE模型)在多个基准任务中超越Qwen2-32B,在效率与准确性之间达成更优平衡。
此外,评估数据显示,Qwen3系列在多轮对话连贯性、事实一致性及幻觉率控制方面均优于前代模型,显示其在实际交互中的可靠性提升。
结语:推动LLM发展模式的转变
Qwen3并非对前代模型的简单升级,而是在模型设计理念上实现了关键突破。通过融合混合推理能力、弹性扩展架构、多语言支持与计算效率优化,Qwen3在多个关键维度为大型语言模型的研发与落地设定了新基准。
该系列强调模型的“适应性”,不仅适用于学术研究,也可广泛应用于企业解决方案与未来多模态系统中。在LLM迈向实用化、多样化与可持续发展的过程中,Qwen3为模型的性能、成本与灵活性三者之间的平衡提供了参考范式。未来,Qwen3有望进一步引领开源大模型生态的发展趋势,成为多任务、跨语言AI应用的重要技术支撑

















 1057
1057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









