







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的智慧交通电动车佩戴头盔识别检测算法系统
设计思路
一、课题背景与意义
随着电动车的普及,交通安全问题日益突出。电动车骑行者在城市交通中占据了重要位置,但由于缺乏安全防护,许多骑行者在发生交通事故时容易受到严重伤害。佩戴头盔可以有效降低头部受伤的风险,然而,许多骑行者不规范佩戴或根本不佩戴头盔,这引发了对交通安全的关注。因此,开发一种高效的电动车佩戴头盔识别检测算法系统,不仅能够实时监测骑行者的安全行为,还可以为交通管理部门提供数据支持,推动交通安全政策的实施。
二、算法理论原理
2.1 YOLOv5算法
YOLOv5s是YOLOv5系列中最小的网络,其改进算法的网络结构在设计上旨在优化检测性能。该模型在数据输入阶段采用了Mosaic-9数据增强方法,以丰富数据集并提高模型的泛化能力。同时,通过设定初始锚框并自动计算最佳锚框值,将输入图像调整为固定尺寸,以便于模型训练。在训练过程中,模型通过与真实框的对比,计算出它们之间的差异,并利用反向传播算法进行迭代优化。这种方法不仅提升了模型在训练时的准确性,还有效提高了推理速度,从而确保在实际应用中能够快速且准确地进行目标检测。
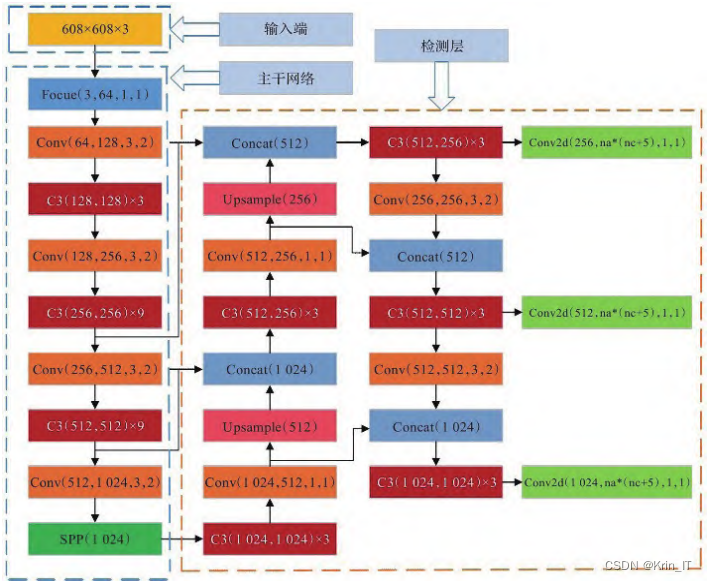
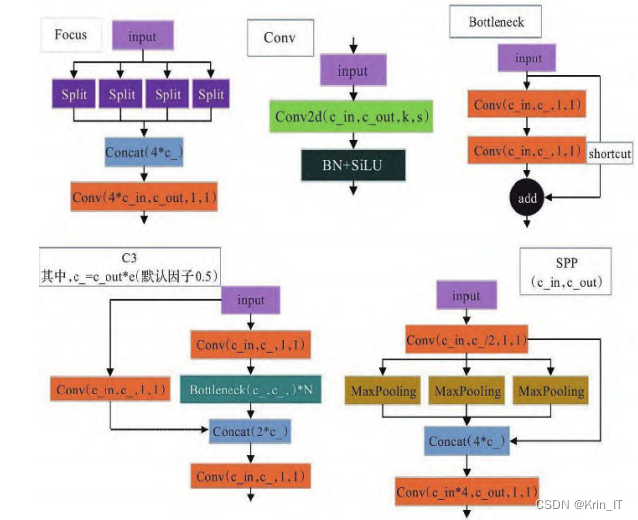
在YOLOv5s模型中,经过Focus模块进行切片和卷积操作后,能够有效保留完整的图像信息,以便于特征提取。随后,利用空间金字塔池化(SPP)方法融合多尺度信息,从而增强特征表示,并在Neck部分保留重要的空间信息。在损失函数的选择上,模型采用CIoU损失函数来提高定位精度,该损失函数不仅考虑了目标框与检测框的重叠部分,还引入了惩罚项,以有效缓解IOU框不相交的问题,更准确地反映预测框与真实框之间的相交情况。此外,训练过程中采用动态调整策略,以进一步优化模型的学习过程和性能,从而实现更高效的目标检测。
2.2 跨领域网格匹配策略
跨领域网格匹配策略是一种在目标检测任务中具有重要应用的技术,旨在提升模型的准确性和鲁棒性。其核心思想是将目标检测网络的特征图划分为多个不同尺度的网格,通过将每个目标与最匹配的网格进行关联,增强模型对不同尺度目标的识别能力。这种策略不仅提高了检测的准确性和鲁棒性,还增强了模型的上下文感知能力,有效降低了误检率。由于其在多样化场景中的适应性,跨领域网格匹配策略展现了广泛的应用前景和潜力,能够为目标检测领域的进一步发展提供强有力的支持。
相关代码:
if __name__ == "__main__":
# 假设特征图和目标
feature_map = torch.randn(1, 256, 64, 64) # 输入特征图 (batch_size, channels, height, width)
targets = [[0.5, 0.5, 0.1, 0.1]] # 示例目标 (x_center, y_center, width, height)
# 初始化跨领域网格匹配策略
grid_matching = CrossDomainGridMatching(grid_sizes=[4, 8, 16])
# 执行匹配
matched_features = grid_matching(feature_map, targets)
# 输出匹配结果
for i, features in enumerate(matched_features):
print(f"Matched features for grid size {grid_sizes[i]}: {features.shape}")三、检测的实现
3.1 数据集
数据集通过多种自主收集方式获得,包括实际拍照和使用Python网络爬虫进行互联网搜索。这些方法确保了数据的多样性和丰富性,所收集到的图片涵盖了不同环境条件下的场景,如城市道路、乡村公路以及不同的天气状态,从而提高了模型在实际应用中的泛化能力。此外,这些图片的分辨率各异,进一步增添了数据集的复杂性和挑战性。在数据标注方面,所有收集到的图片均采用LabelImg软件进行逐一标注,确保每张图片中的目标(如佩戴的头盔)都得到了准确的识别和标记。这种细致的标注过程为后续模型训练提供了高质量的基础数据。

为了进一步增强数据集的有效性和多样性,本项目还改进了数据增强策略,采用了Mosaic-9方法。这一方法将原来的4张图片拼接扩展至9张,能够生成更为丰富的训练样本,增强了模型对不同场景的适应能力。Mosaic-9不仅提高了数据集的图片数量,还通过多样化的拼接方式增加了图像的复杂性,使得模型在训练时能够更好地学习到不同目标之间的关系和背景信息。

3.2 实验环境搭建
深度学习框架为构建、训练、优化和推理深度神经网络提供了必要的基础工具,使开发者能够更高效地进行相关工作。这些框架不仅简化了复杂的计算过程,还提供了丰富的功能和灵活的接口,帮助开发者快速实现各种深度学习算法。在众多深度学习框架中,PyTorch因其高度的扩展性和可移植性而受到广泛欢迎,尤其在学术研究和工业应用中表现出色。它的动态计算图特性使得模型的调试和修改变得更加直观和方便,同时,PyTorch拥有一个活跃的开发者社区,提供了大量的资源和支持,极大地推动了深度学习的研究和应用。

3.3 实验及结果分析
1.环境准备:
在开始模型训练之前,首先需要确保所有的环境配置都已正确设置。安装必要的深度学习框架,如PyTorch或TensorFlow,以及相关的库和工具。通常建议在具备GPU加速的机器上进行训练,以提高训练效率和模型的响应速度。确保所有依赖项都已安装,并验证环境是否正常运行。
2. 数据集准备:
数据集的准备是关键的一步,本项目的数据集通过多种方式收集,包括实际拍照和使用Python网络爬虫进行在线搜索。这些数据涵盖了不同环境和条件下的骑行者图像,确保了数据的多样性。所有图像经过LabelImg等工具进行逐一标注,以准确识别骑行者及其佩戴的头盔。同时,采用了Mosaic-9等数据增强方法,丰富数据集的样本,提高模型的泛化能力。
# 假设数据集结构为
# /dataset
# ├── images
# │ ├── train
# │ ├── val
# └── labels
# ├── train
# └── val
3. 数据加载与预处理:
在训练过程中,需要将数据集加载到模型中。通常使用数据加载器将数据分为训练集和验证集,并进行必要的预处理。预处理步骤包括图像的缩放、归一化和数据增强,以确保输入图像符合模型的要求。这些操作有助于提高模型的训练效率与效果,确保模型能够处理各种不同的输入数据。
# 在YOLOv5中,数据集配置文件通常是一个YAML文件
data_yaml = {
'train': 'dataset/images/train',
'val': 'dataset/images/val',
'nc': 2, # 类别数量,头盔和无头盔
'names': ['no_helmet', 'helmet'] # 类别名称
}
# 保存数据集配置文件
with open('data/helmet_detection.yaml', 'w') as f:
yaml.dump(data_yaml, f)4. 模型选择与构建:
选择合适的深度学习模型架构是确保检测性能的基础。对于佩戴头盔识别任务,通常使用YOLO系列模型,如YOLOv5s,因为其在目标检测任务中表现优异。通过加载预训练模型,可以利用已有的知识加速训练过程,同时也为后续的微调提供了良好的起点。根据具体任务的需求,可以对模型结构进行适当修改,以增强其性能。
# 使用YOLOv5s模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
5. 模型训练:
模型训练是整个流程的核心环节。在这一阶段,设定损失函数、优化器以及训练参数如批处理大小和训练轮次等。通过将处理后的数据输入模型,计算损失,并使用反向传播算法更新模型权重。这一过程会持续多个训练轮次,期间需要监控模型在验证集上的表现,以确保模型的学习效果不断改善。
# 设置训练参数
train_params = {
'data': 'data/helmet_detection.yaml', # 数据集配置
'epochs': 50, # 训练轮数
'batch_size': 16, # 批处理大小
'img_size': 640, # 输入图片尺寸
'weights': 'yolov5s.pt', # 初始权重
'device': '0' # 选择GPU
}
# 开始训练
model.train(**train_params)6. 模型评估与调优:
在训练完成后,需要对模型进行评估,以验证其在未见数据上的表现。使用独立的验证集,计算模型的准确率、召回率和F1值等指标。这些评估结果可以帮助识别模型的不足之处,并进行相应的参数调优和结构优化,以进一步提升模型的性能和稳定性。
# 训练完成后,可使用验证集进行评估
results = model.val()7. 模型保存与部署:
在模型达到预期的性能后,保存训练好的模型权重,以便后续的推理和应用。这一阶段通常涉及将模型部署到实际应用环境中,进行实时佩戴头盔检测。确保模型在不同环境和条件下的有效性是关键,可能需要进行额外的测试和调整,以确保其在实际场景中的可靠性和准确性。
相关代码如下:
# 保存训练好的模型权重
model.save('trained_helmet_detection.pt')
print("训练完成,模型已保存。")实现效果图样例
创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 6752
6752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









