






我将在本文介绍如何通过 unsloth 框架以 LoRA 的方法微调 Qwen3-14B 模型。

到目前还有很多小伙伴还不明白什么时候应该微调?那么请看下图:

接下来我们再看一下本文使用的 LoRA 微调方法的优势:

LoRA(Low-Rank Adaptation of Large Language Models,大型语言模型的低秩自适应)是一种流行的轻量级训练技术,可以显著减少可训练参数的数量。它的工作原理是将少量的新权重插入模型中,并且只训练这些权重。这使得使用 LoRA 进行训练的速度更快、内存效率更高,并且生成的模型权重更小(只有几百 MB),更易于存储和共享。LoRA 还可以与 DreamBooth 等其他训练技术结合使用,以加速训练。
我们将在本文介绍如何微调使模型成为一个"双重人格"的助手,既能进行普通闲聊,又能在需要时切换到更严谨的思考模式来解决复杂问题,特别是数学问题。简而言之,微调后的模型获得的能力:
1. 双模式操作能力:
-
普通对话模式: 适用于日常聊天场景。
-
思考模式( Thinking Mode ): 用于解决需要推理的问题。
2. 数学推理能力: 能够解决数学问题并展示详细的推理过程,如示例中的"解方程(x + 2)^2 = 0"。
3. 对话能力保持: 同时保持了自然对话的能力,能够进行流畅的多轮对话。
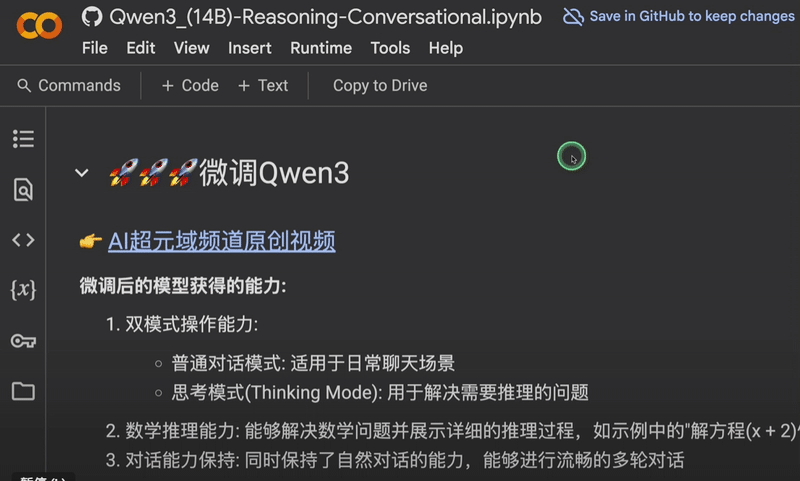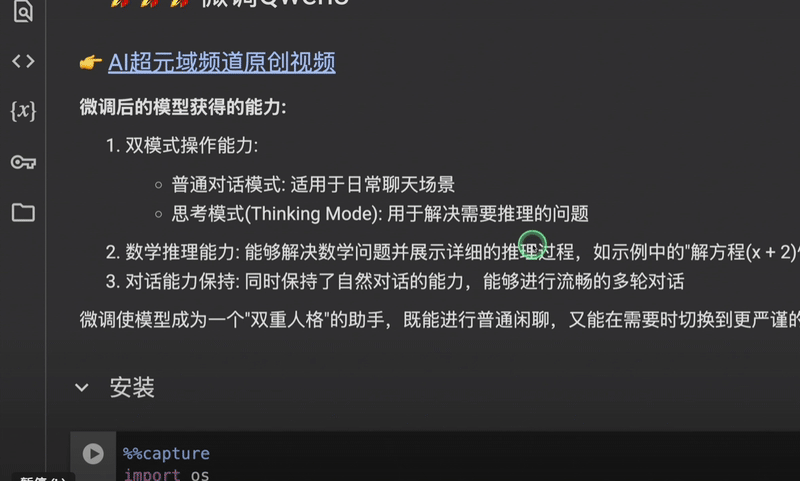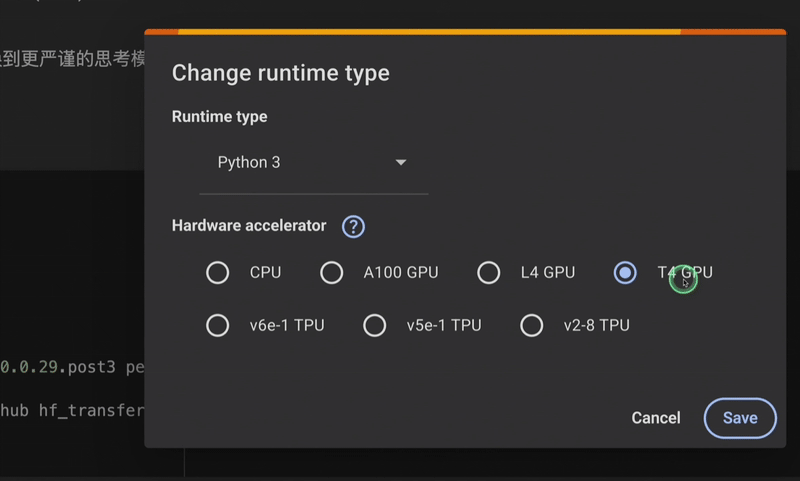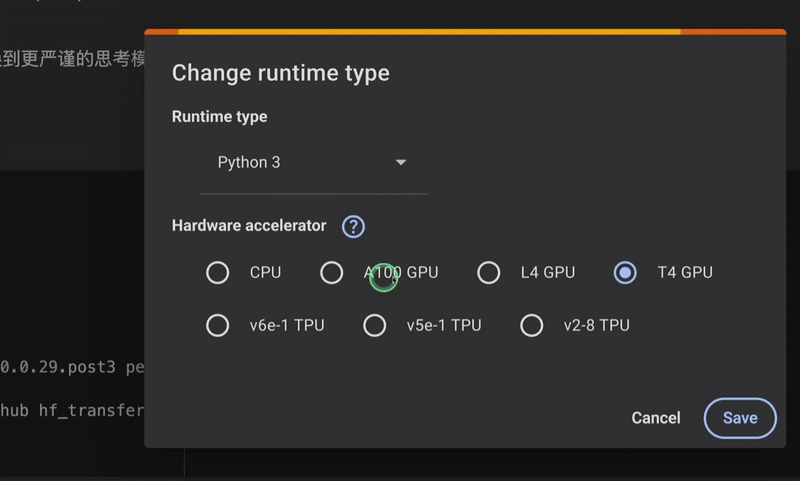
首先我们在谷歌 Colab 上选择算力,推荐使用 T4 GPU 或者 A100 GPU:
现在我们可以加载 14 B模型:
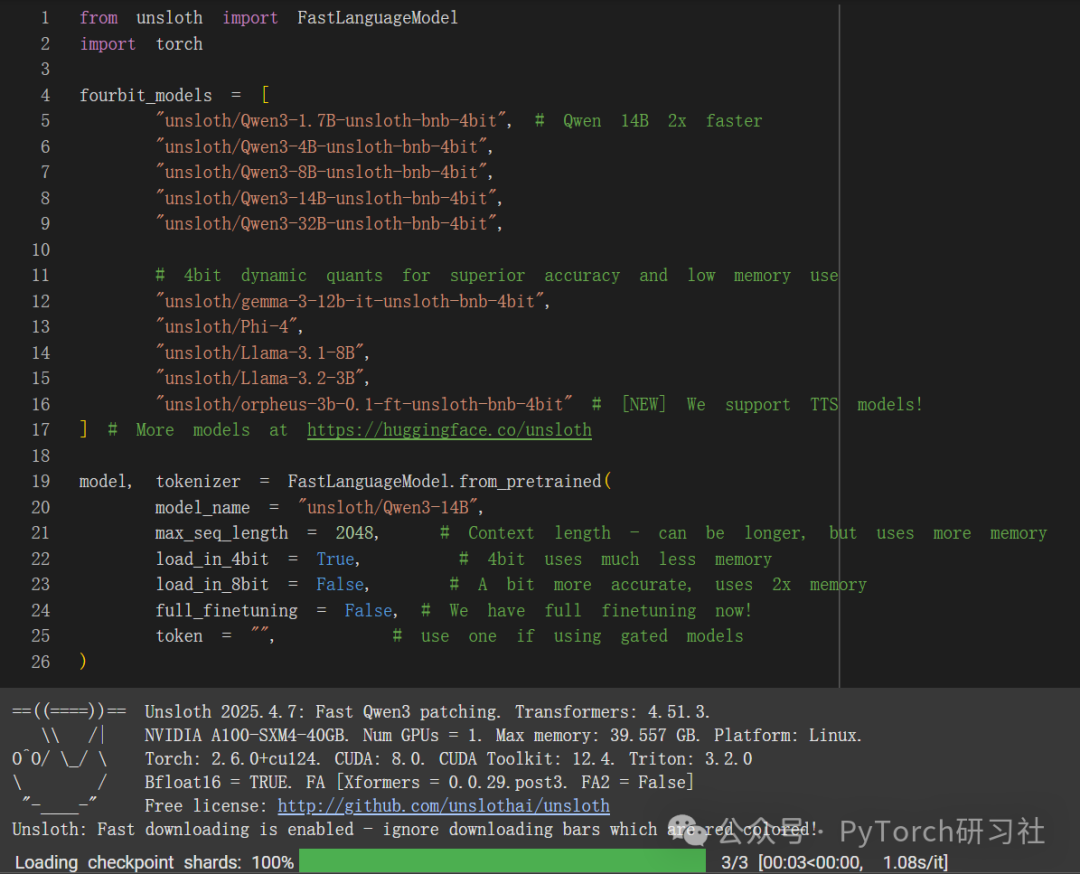
我们现在添加 LoRA 适配器,因此我们只需要更新 1% 到 10% 的参数!

准备数据
Qwen3 既有推理模式,也有非推理模式。因此,我们应该使用两个数据集:
-
Open Math Reasoning 数据集,该数据集曾用于赢得 AIMO(AI Mathematical Olympiad,AI 数学奥林匹克 - 进步奖 2)挑战赛!我们从使用 DeepSeek R1 的可验证推理轨迹中抽取了 10%,其准确率超过 95%。
-
我们还利用了 Maxime Labonne 的 FineTome-100k 数据集(ShareGPT 格式)。但我们还需要将其转换为 HuggingFace 的常规多轮对话格式。
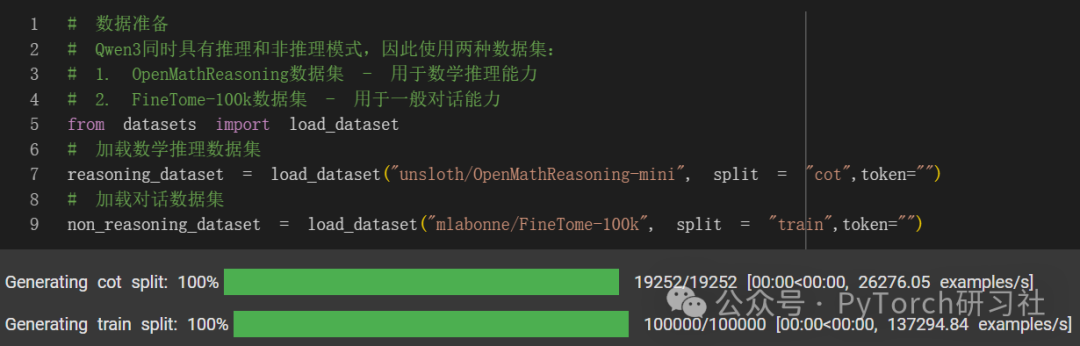
我们现在将推理数据集转换为对话格式:
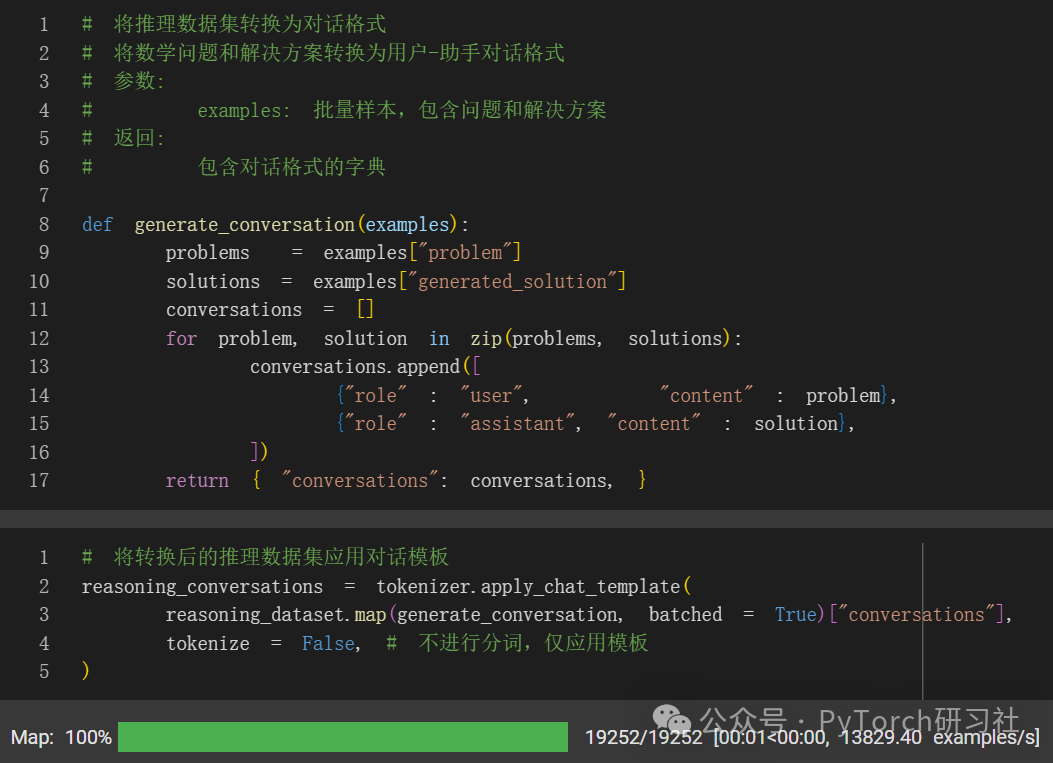
接下来,我们将非推理数据集也转换为对话格式。
首先,我们必须使用 Unsloth 的 standardize_sharegpt 函数来修复数据集的格式。
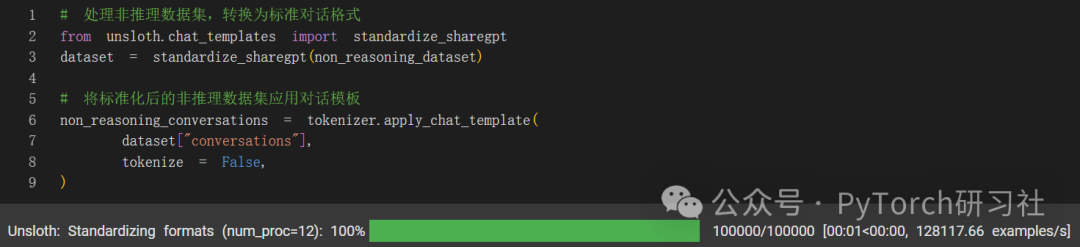

非推理数据集要长得多。假设我们希望模型保留一些推理能力,但我们特别想要一个聊天模型。
让我们定义一个纯聊天数据的比例。目标是定义两种数据集的某种混合。让我们选择 25% 的推理数据和 75% 的聊天数据:
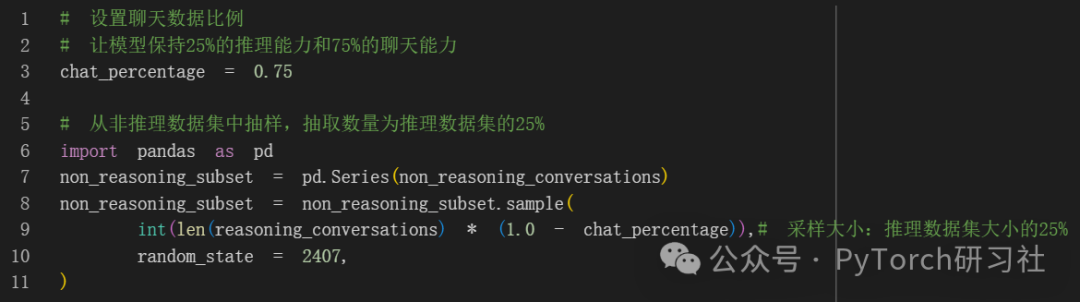
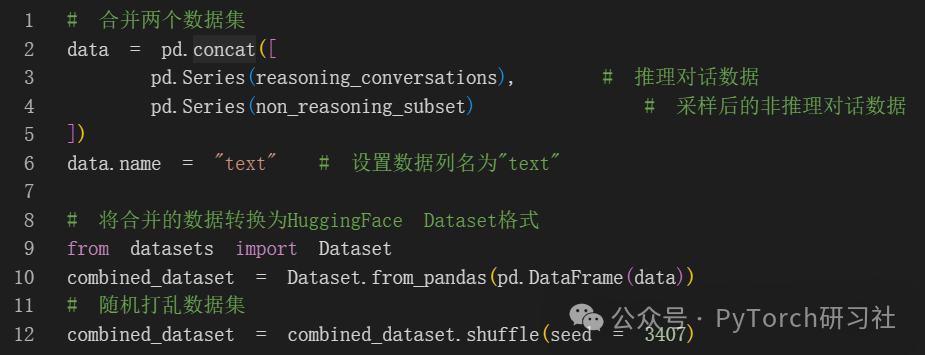
最后合并数据集:
训练模型
现在让我们使用 Huggingface TRL 的 SFTTrainer!我们执行 60 步来加快速度,但你可以设置 num_train_epochs=1 进行完整运行,并关闭 max_steps=None。
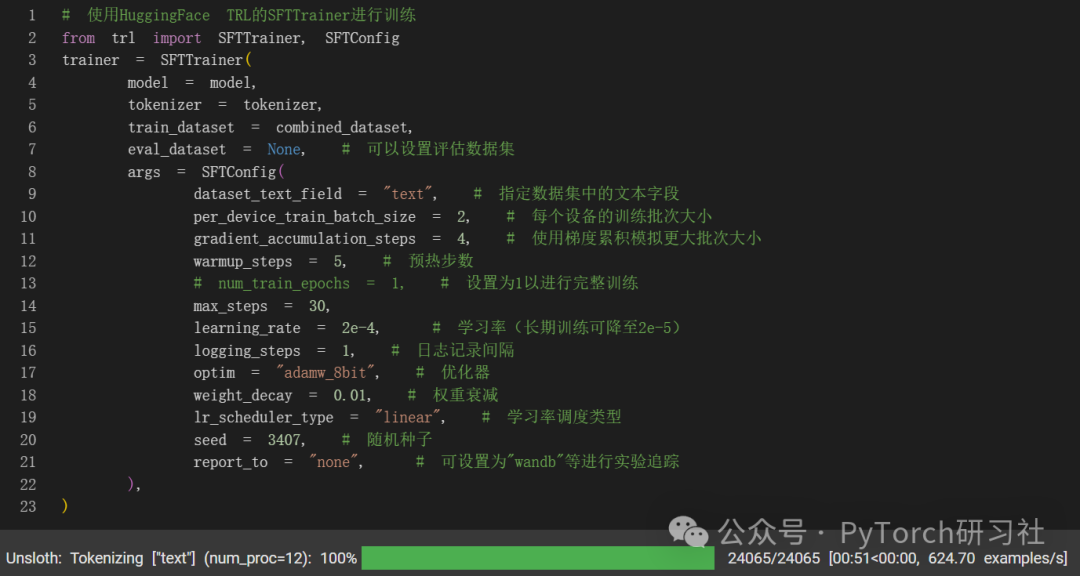
让我们开始训练模型吧!要恢复训练,请设置 trainer.train(resume_from_checkpoint = True)
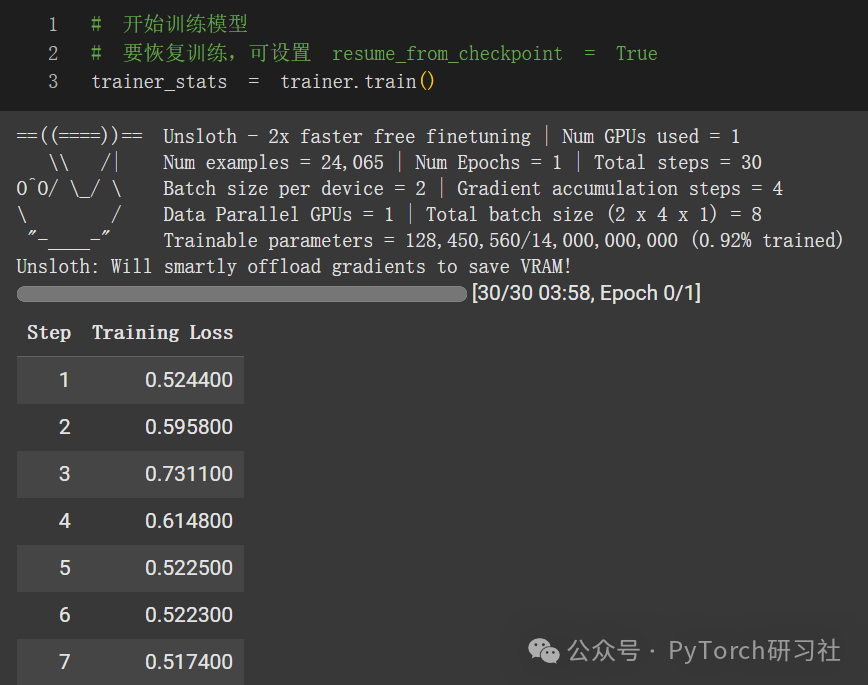
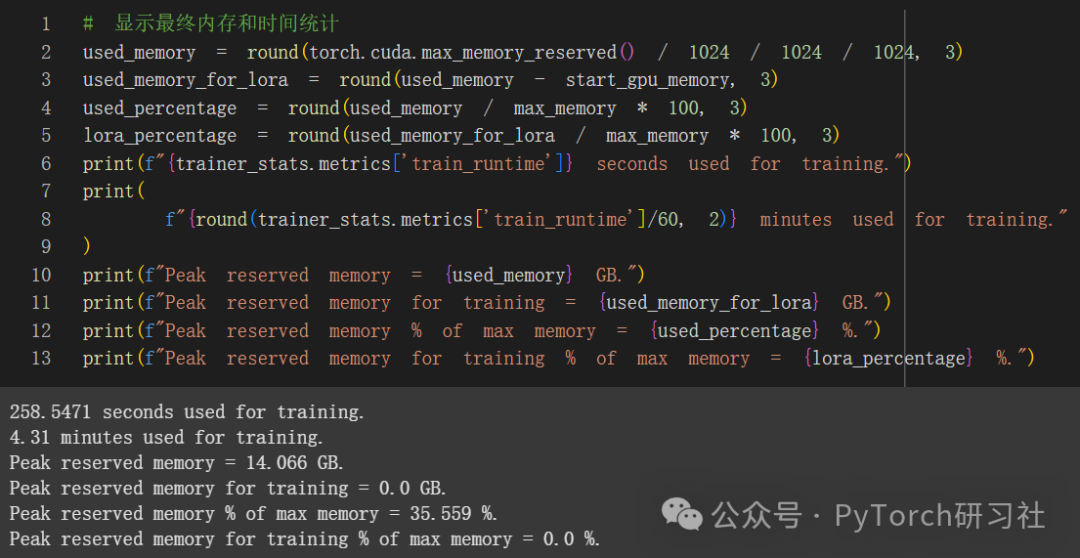
推理
让我们通过 Unsloth 原生推理来运行模型!根据 Qwen-3 团队的说法,
-
推理的推荐设置是:temperature = 0.6、top_p = 0.95、top_k = 20。
-
对于基于普通聊天的推理,temperature = 0.7、top_p = 0.8、top_k = 20。
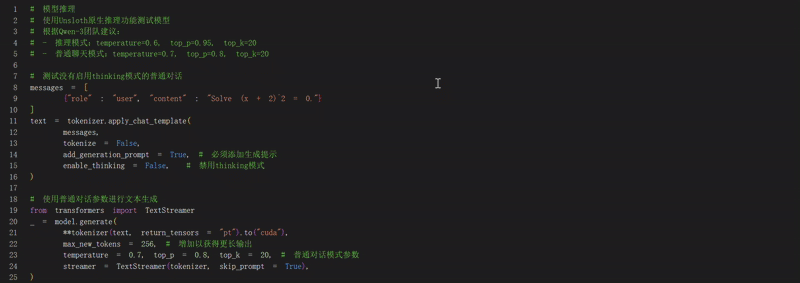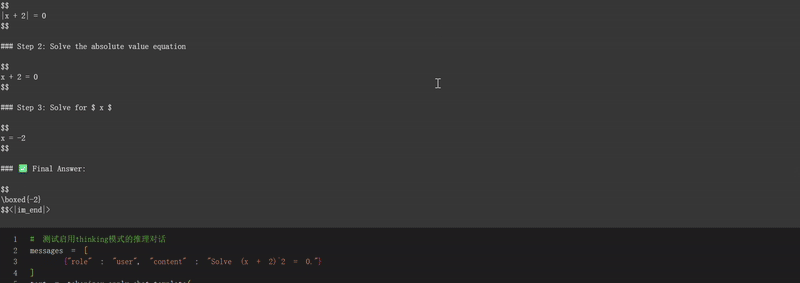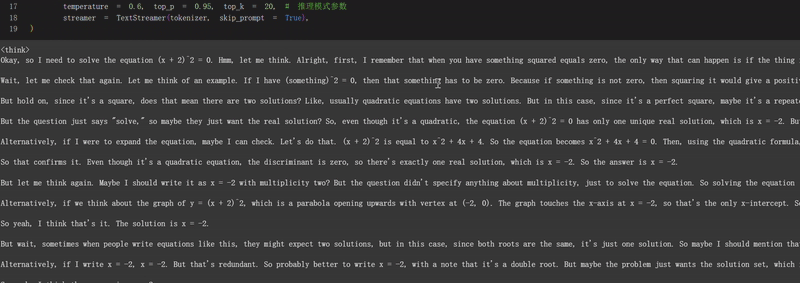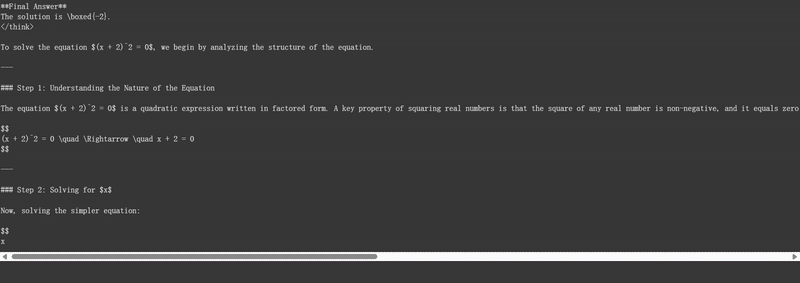
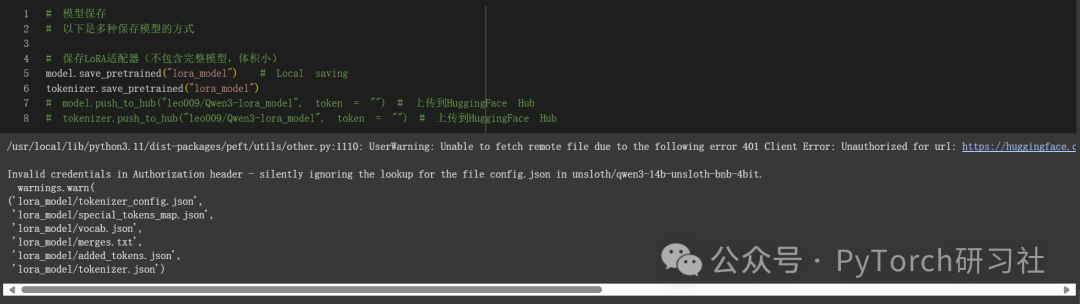
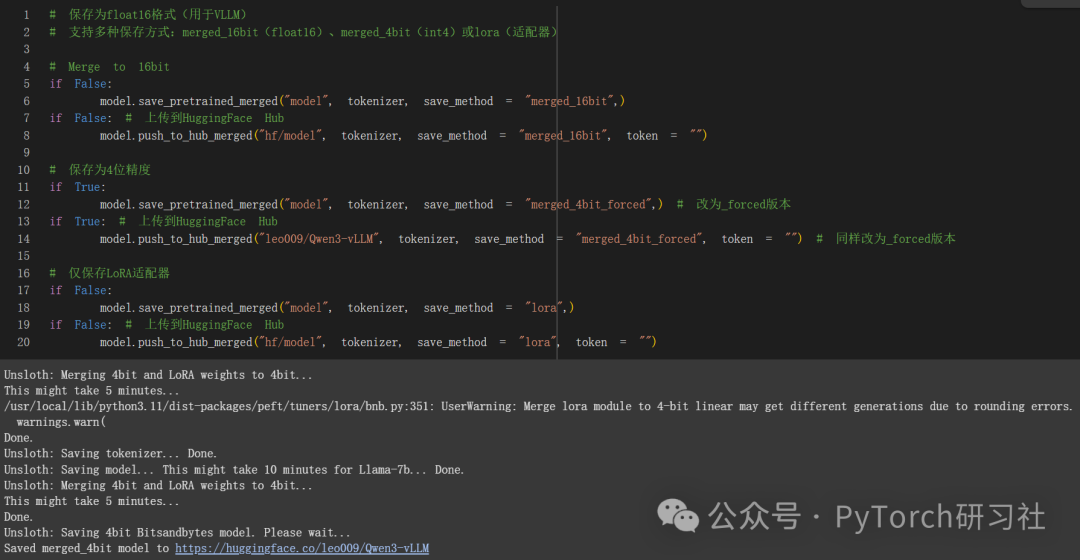
保存、加载微调模型
要将最终模型保存为 LoRA 适配器,请使用 Huggingface 的 push_to_hub 进行在线保存,或使用 save_pretrained 进行本地保存。
[注意] 这仅保存 LoRA 适配器,而不是完整模型。后面我来介绍如何保存为 16 位或 GGUF 格式。
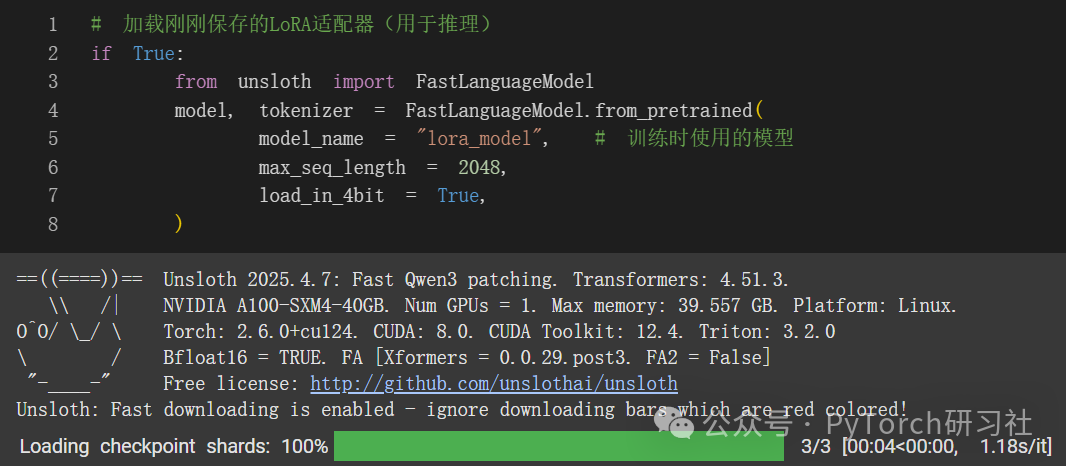
现在,如果你想加载我们刚刚保存用于推理的 LoRA 适配器,请将 False 设置为 True:
保存为 VLLM 的 float16
选择 merged_16bit 保存 float16,或选择 merged_4bit 保存 int4。使用 push_to_hub_merged 上传到你个人的 Hugging Face 账户!
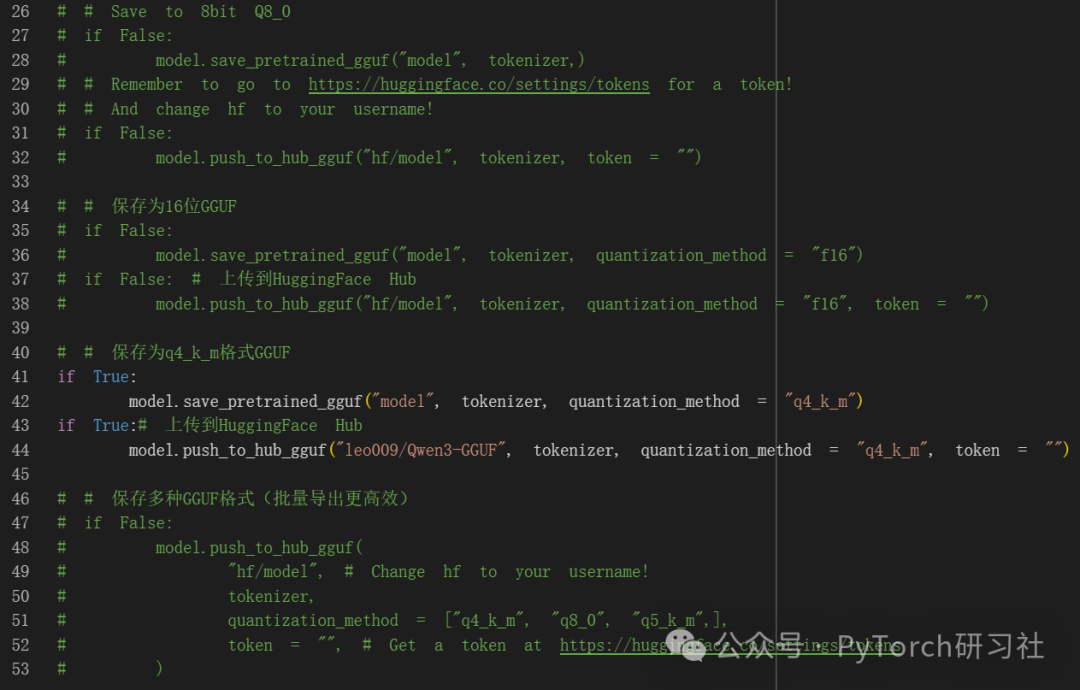
GGUF / llama.cpp 转换
使用 save_pretrained_gguf 进行本地保存,使用 push_to_hub_gguf 上传到 HF。
-
q8_0 - 快速转换。资源占用较高,但通常可以接受。
-
q4_k_m - 推荐。使用 Q6_K 处理 attention.wv 和 feed_forward.w2 张量的一半,否则使用 Q4_K。
-
q5_k_m - 推荐。使用 Q6_K 处理 attention.wv 和 feed_forward.w2 张量的一半,否则使用 Q5_K。
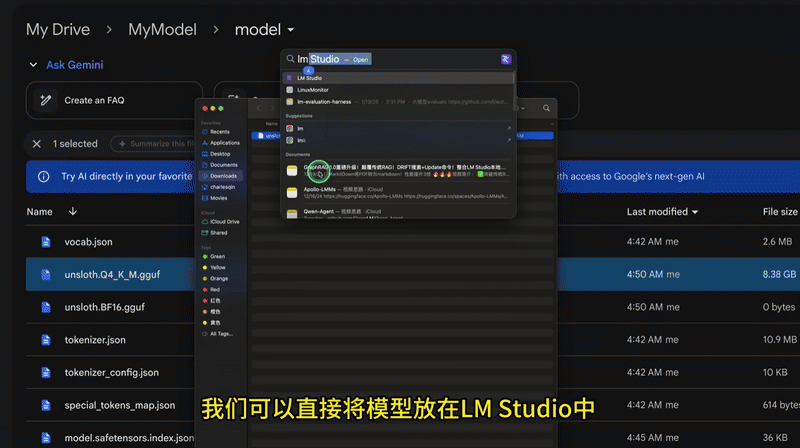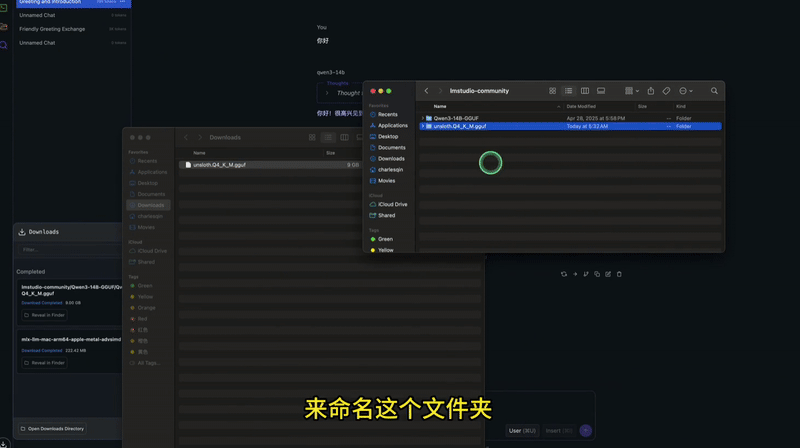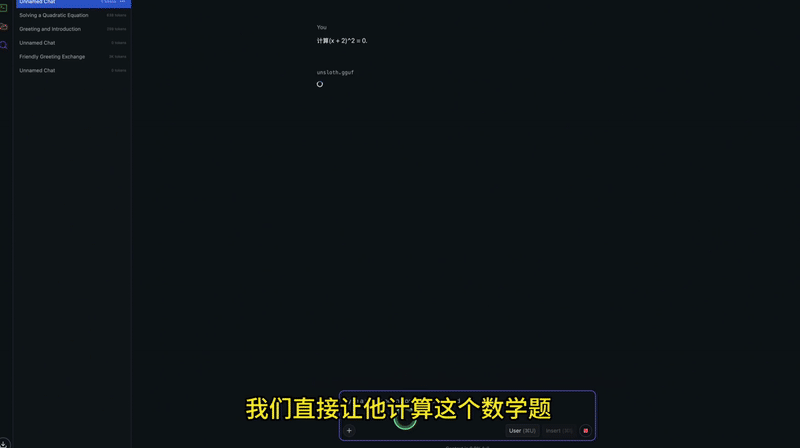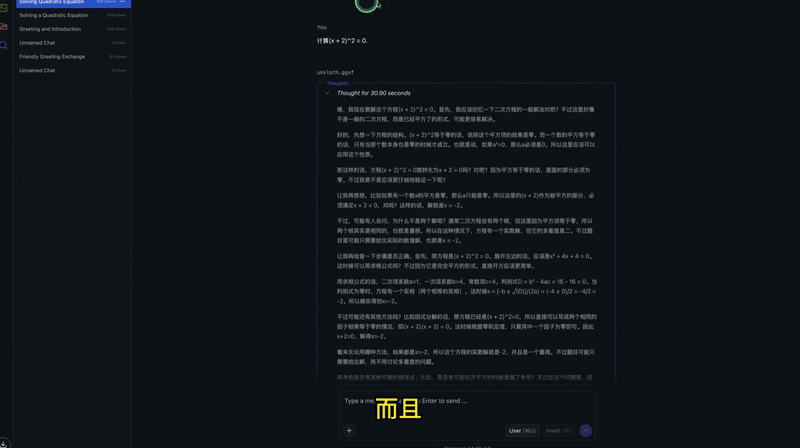
本地部署
接下来就是将 GGUF 文件下载到本地,以便本地部署运行。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 533
533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









