







记忆+反馈 >规划?
©作者|格林
来源|神州问学
引言
去年6月份,Lilian发布了关于LLM驱动的Agent的结构和组件,其中包括规划、行动、工具还有记忆,这四个模块。这几个模块其实也很好地概括了ReAct式Agent的工作流程:Question – Thought_1 – Action – Action_Input – Observation – Thought_2 - …… - Thought_X – Final_Answer;
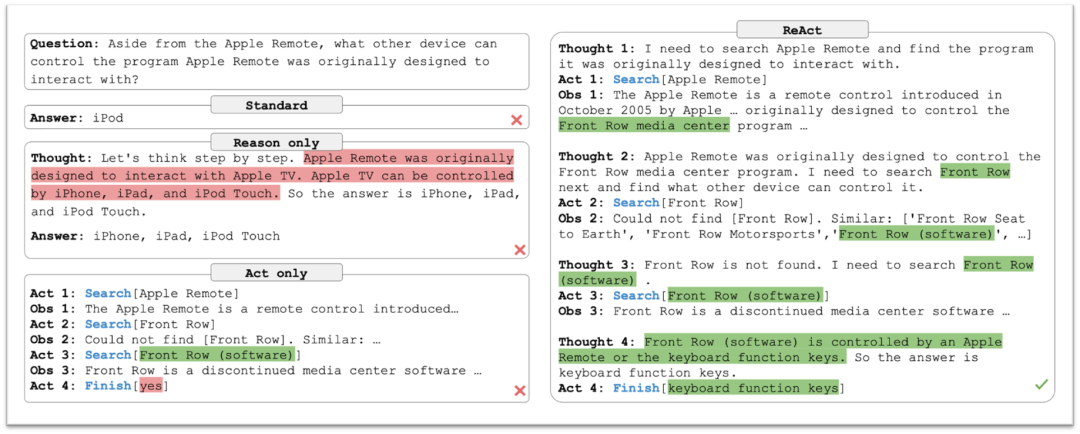
{ReAct式的Agent任务解决流程}
在其中,记忆也是Agent的组件之一,在Agent类应用中,记忆可以记住事实和偏好,例如:问题答案、工具调用结果、格式偏好、语言偏好、表达偏好、图表绘制偏好、任务下工具选择偏好;对于事实和偏好的记忆能够让Agent应用提升回答准确率、稳定性以及速度,那么,记忆有哪些种类的分类,Agent的记忆是呼和实现的,记忆又有什么用途,接下来让我们来研究一下:
1. Agent什么东西可以存入记忆中?
Agent不同于Chat类或者RAG类的单纯知识型应用,其中还涉及到规划与决策、工具调用等内容,因此对于能够把什么东西存入记忆中则是我们需要思考的
1.1. 对话交互历史
对话交互历史是记忆的一部分,也是Agent多轮对话的基础。用户所输入的Query和模型最终返回的自然语言输出形成了对话的交互历史。
1.2. 工作流(规划)与工具调用结果
自然语言规划和工具调用在工作流上的区别,也会让其在工作流记忆的储存上有所区别
在ReAct为基础架构的Agent结构中,规划或Thought是以自然语言的形式呈现的,有长期规划的Agent会在行动开始之前将任务拆解成一系列的子任务,这一系列的子任务就可以作为本次任务生成的工作流储存至记忆中。
以Function Calling(FC)模型为核心驱动的Agent结构中,模型会接收用户Query以及结构化的Function List,输出的是Function调用的JSON文件,接着在外部执行这个函数并返回函数执行结果。函数调用的JSON文件以及执行结果都是可以被记忆所存储的内容,在未来遇到相似条件的时候可以直接召回相关的执行结果,节省函数执行所消耗的资源与时间。
1.3. Reflection的反馈
Reflection是对Agent每步子任务的反馈,把反馈放入记忆中,就像Agent的错题集一样,能够在未来遇到类似的任务时,能够提供的对应的Reflection改进建议,从而提高准确率。将Reflection的结果加入到记忆中从长远来看,能够对Agent的思维能力有极大的提升,在专业场景下相比纯粹去提升模型原生的推理性能要更加高效。但目前主要受限于自动化的Reflection流程还难以提供给模型高质量的改进建议,通常会导致模型“钻牛角尖”,陷入到错误步骤的循环中。因此短期内可能Reflection步骤仍然需要人工的介入,以类似强化学习的方法提升agent在专业场景的表现性能
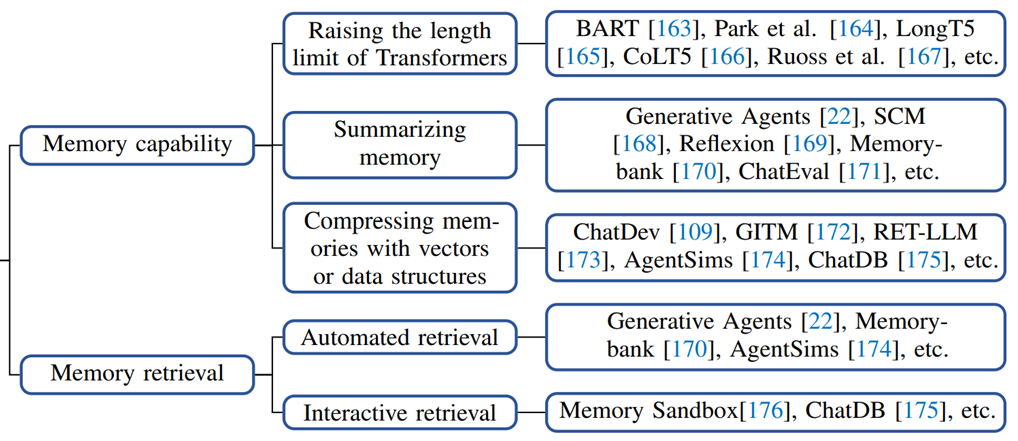
2. 记忆的提炼方式
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 402
402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









