






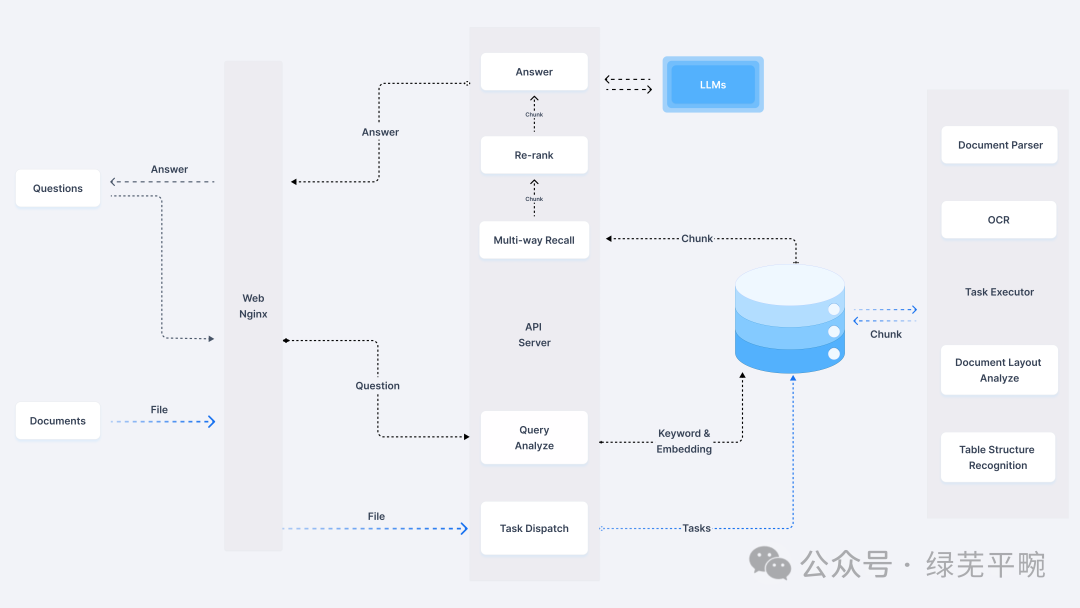
将开源的大语言预训练模型部署到用户设备上进行推理应用,特别是结合用户专业领域知识库构建AI应用,让AI在回答时更具有专业性,目前已经有很多成熟的应用方案。其中,支持大模型本地化部署的平台及工具很多,比较出名的有ollama、vLLM、LangChain、Ray Serve等,大大简化了模型的部署工作,并提供模型全生命周期管理。
对应地,需要知识库构建的相应工具,能处理各种格式(doc/pdf/txt/xls等)的各种文档,能够直接读取文档并处理大量信息资源,包括文档上传、自动抓取在线文档,然后进行文本的自动分割、向量化处理,来实现本地检索增强生成(RAG)等功能。这类工具主要有RAGFlow、MaxKB、AnythingLLM、FastGPT、Dify 、Open WebUI 等。本文将采用ollama + RAGFlow方式进行搭建,系统架构如下:
1 安装ollama
ollama是一个开源的大型语言模型服务工具,旨在帮助用户在本地环境中部署和运行大型语言模型,其核心功能是提供一个简单、灵活的方式,将这些复杂的AI模型从云端迁移到本地机器上,简化大型语言模型在本地环境中的运行和管理。它不仅为开发者提供了一个强大的平台来部署和定制AI模型,而且也让终端用户能够更加私密和安全地与这些智能系统进行交互。
(1)执行如下命令安装
curl -fsSL https://ollama.com/install.sh | sh
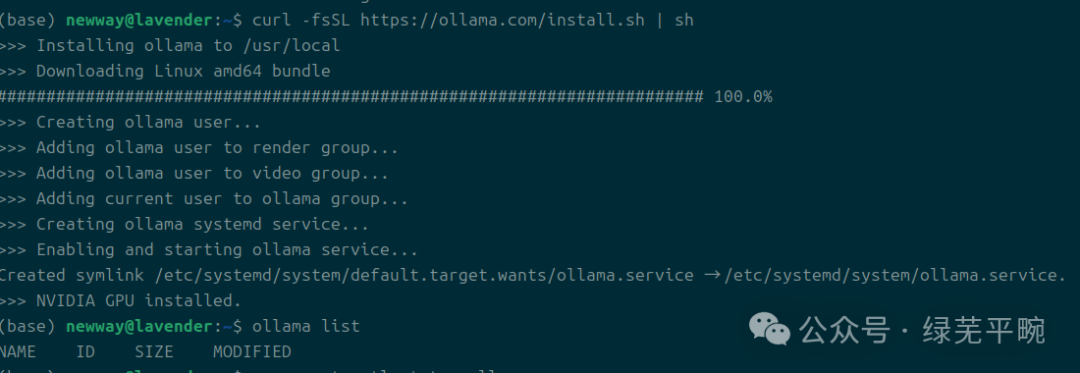
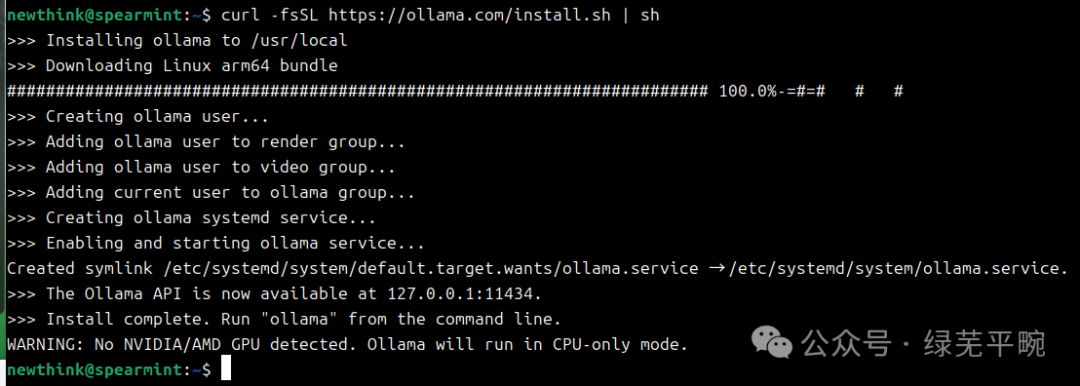
在安装过程中,ollama会识别相应的GPU加速卡,若未识别相应设备,则使用CPU模式
GPU模式“NVIDIA GPU installed”
CPU模式“No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode”
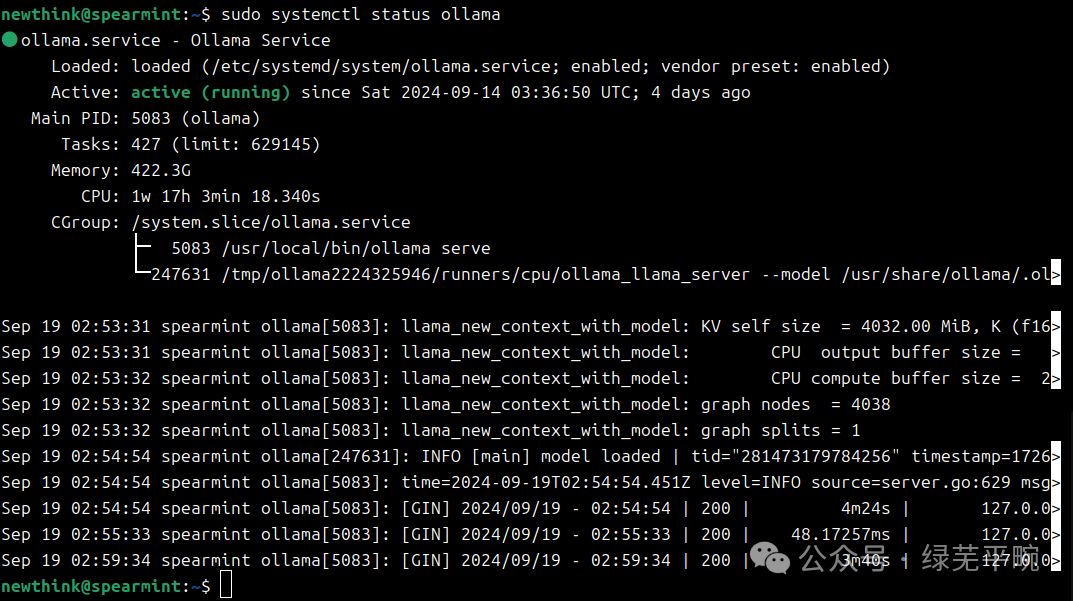
(2)安装后查看ollama状态
sudo systemctl status ollama
(3)设置ollama环境变量
sudo vi /etc/systemd/system/ollama.service
增加Environment=”OLLAMA_HOST=0.0.0.0:11434”,否则后面在RAGFlow容器环境下配置连接时,无法连接ollama.
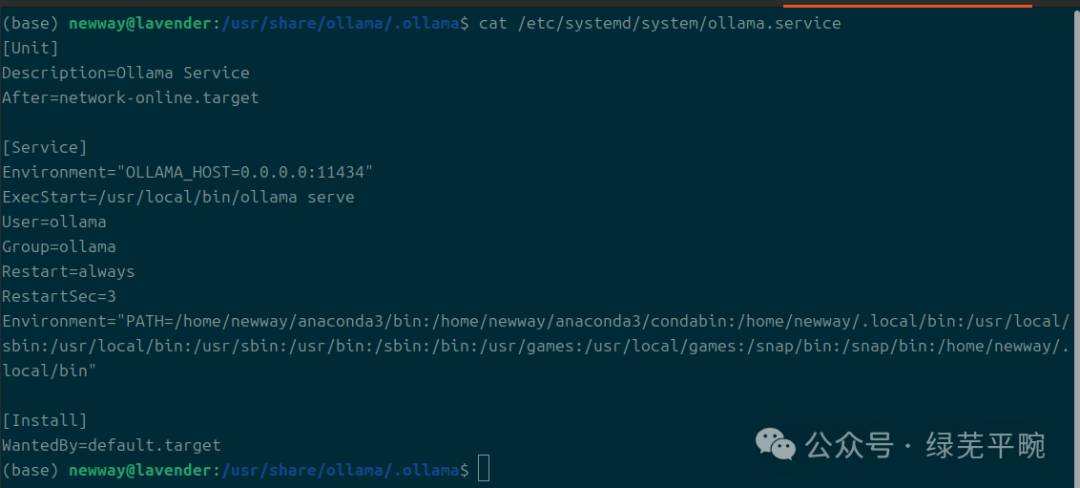
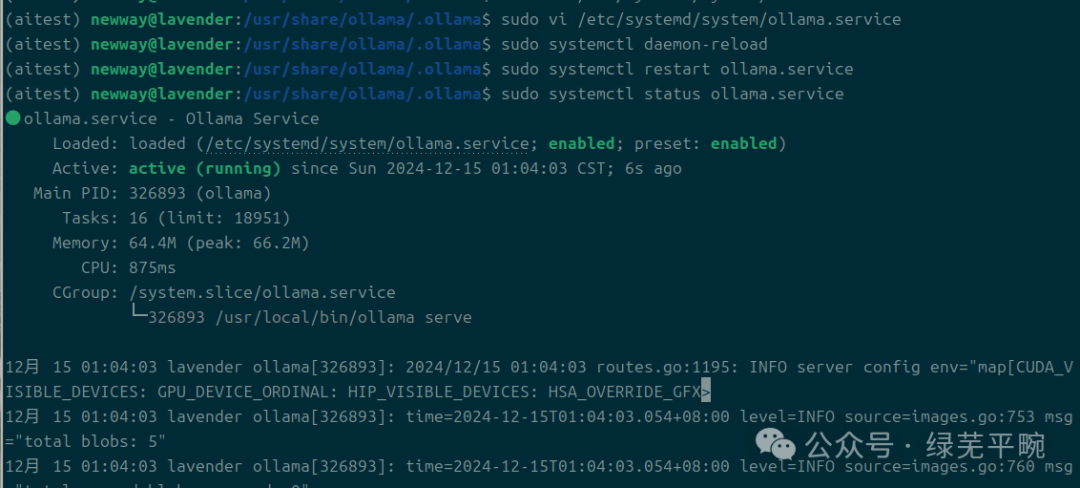
# 修改并重启服务``sudo systemctl daemon-reload``sudo systemctl restart ollama.service``sudo systemctl status ollama.service
2 部署千问大模型
(1) 模型下载
与docker类似,可以通过ollama pull 命令进行预训练模型下载,目前ollama已支持许多大模型,可以通过访问https://ollama.com/library获取相关信息。
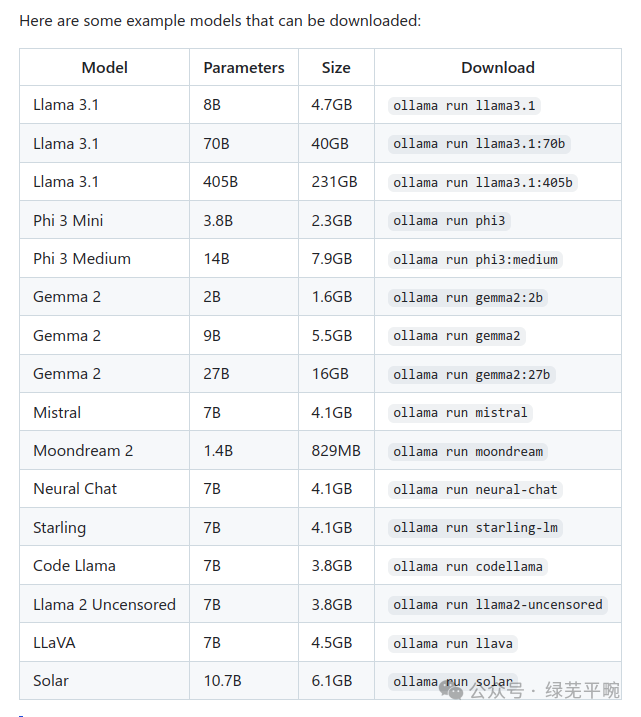
这里使用ollama run qwen2.5:7b,当本地没有qwen2.5:7b预训练模型时,ollama将先下载模型到本地,然后运行该模型。

测试运行正常,可进行问答测试。基于ollama的千问7b大模型部署完毕。
3 安装RAGFlow
RAGFlow 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。RAGFlow部署采用的是docker容器化部署,因组件较多使用了多个容器,需要通过docker compose进行多容器部署方式。
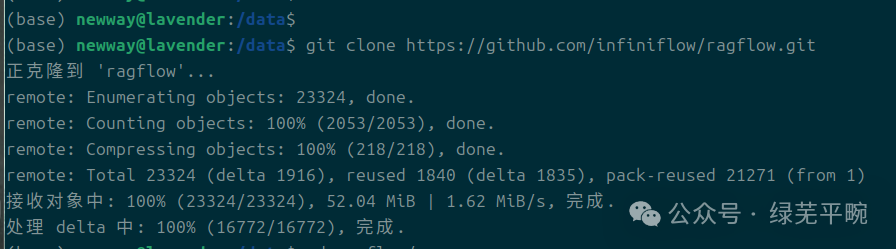
(1)执行如下命令克隆RAGFlow仓库
#参考官方手册https://ragflow.io/docs/dev/进行操作即可:` `git clone https://github.com/infiniflow/ragflow.git` `cd ragflow` `git checkout -f v0.14.1
(2)修改docker子目录下的.env文件,进行初始化配置
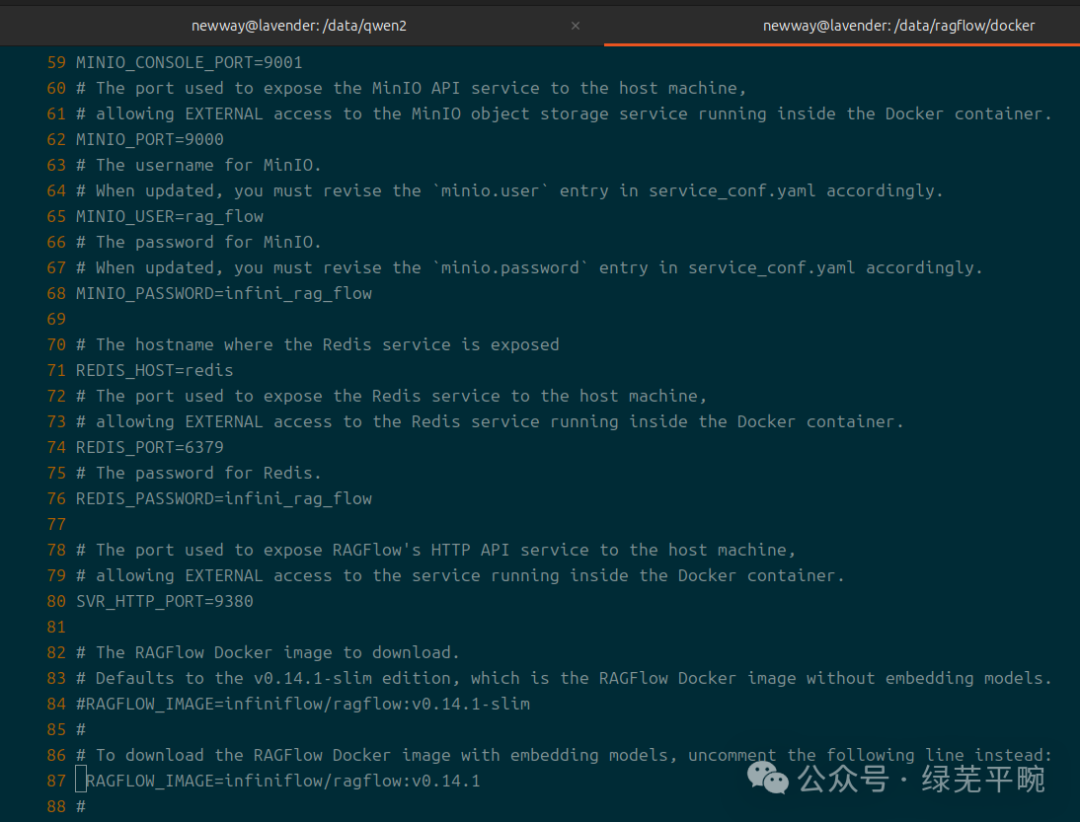
这里特别要注意的是,在初始化环境变量里RAGFLOW_IMAGE环境变量指向的是标签为v0.14.1-slim镜像文件,该镜像未打包embedding models,我这里修改为v0.14.1。
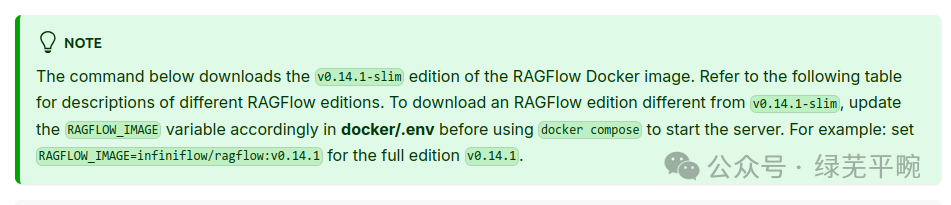
其他变量参数包括相关组件的端口,应用的用户初始化密码、镜像下载地址等,按需进行调整和设置。
vi docker/.env
注释掉84行,使用第87行。
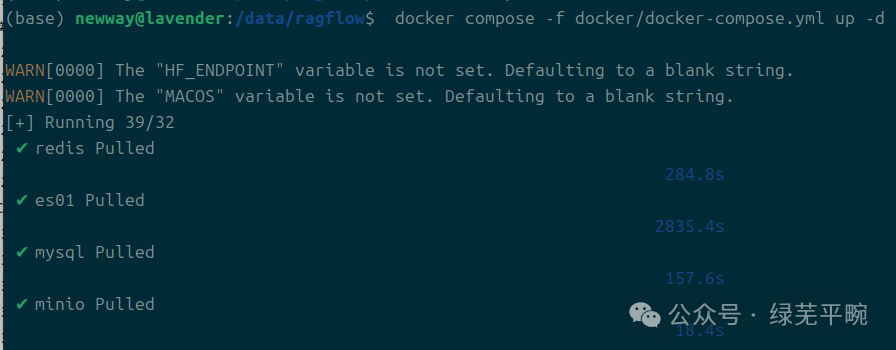
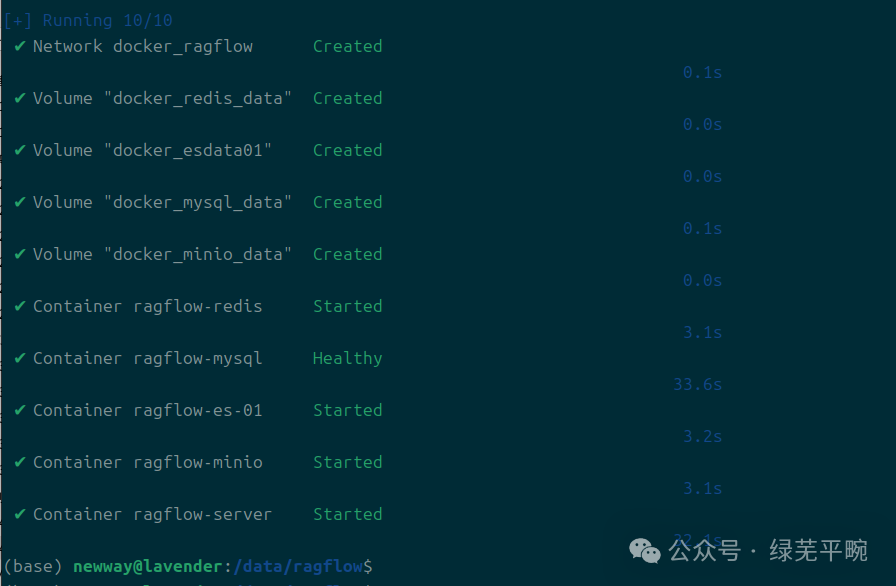
(3)进入ragflow目录,使用docker compose启动应用
进入 docker 文件夹,利用编译好的 Docker 镜像启动服务器,将开始将镜像下载到本地并完成启动:
cd ragflow``docker compose -f docker/docker-compose.yml up -d
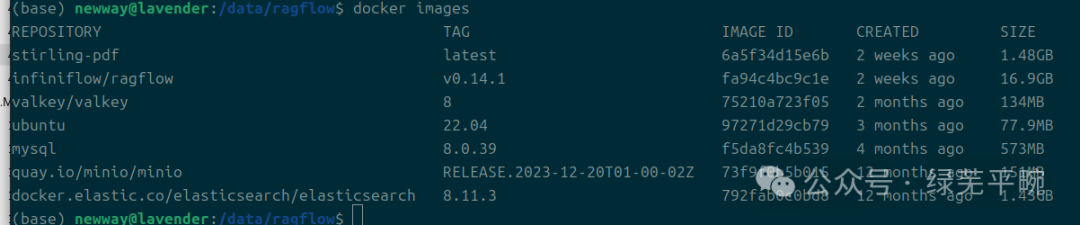
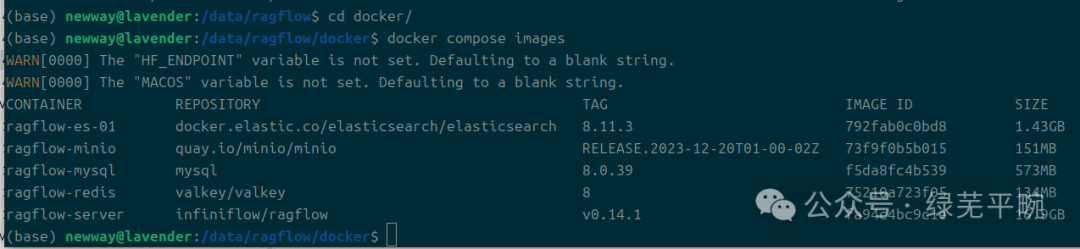
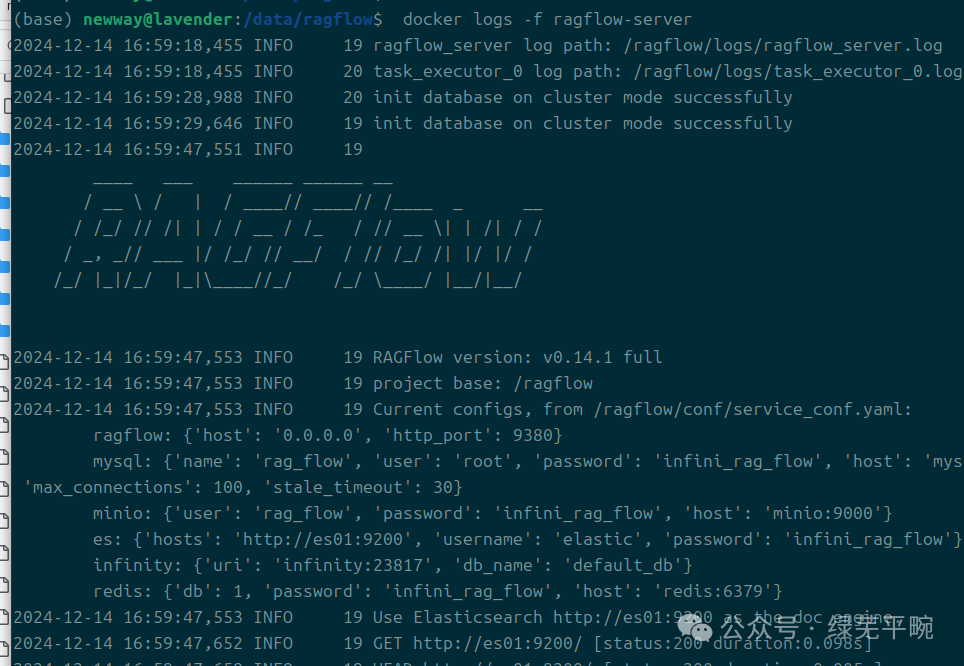
(4)查看ragflow相关组件及启动情况
docker images``docker compose images``docker logs -f ragflow-server
4 配置RAGFlow-接入本地大模型
In your web browser, enter the IP address of your server and log in to RAGFlow.With the default settings, you only need to enter http://IP_OF_YOUR_MACHINE (sans port number) as the default HTTP serving port 80 can be omitted when using the default configurations.
在这里输入本机地址,因没更改默认端口即80,进入如下界面,第一次需要进行注册并登录。
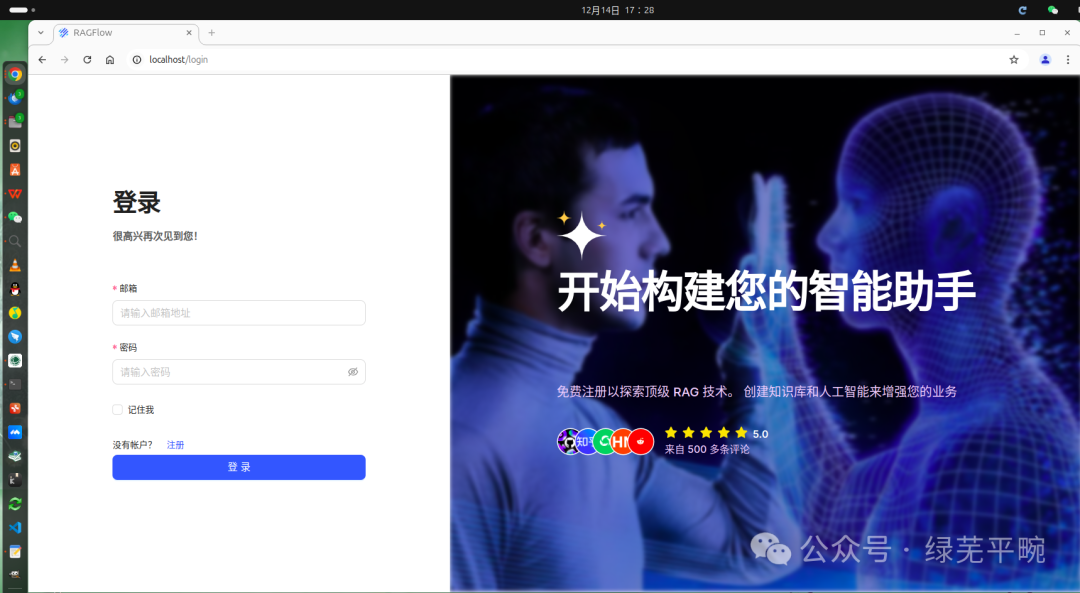
完成注册登录后,进入如下页面,将页面调整为中文。
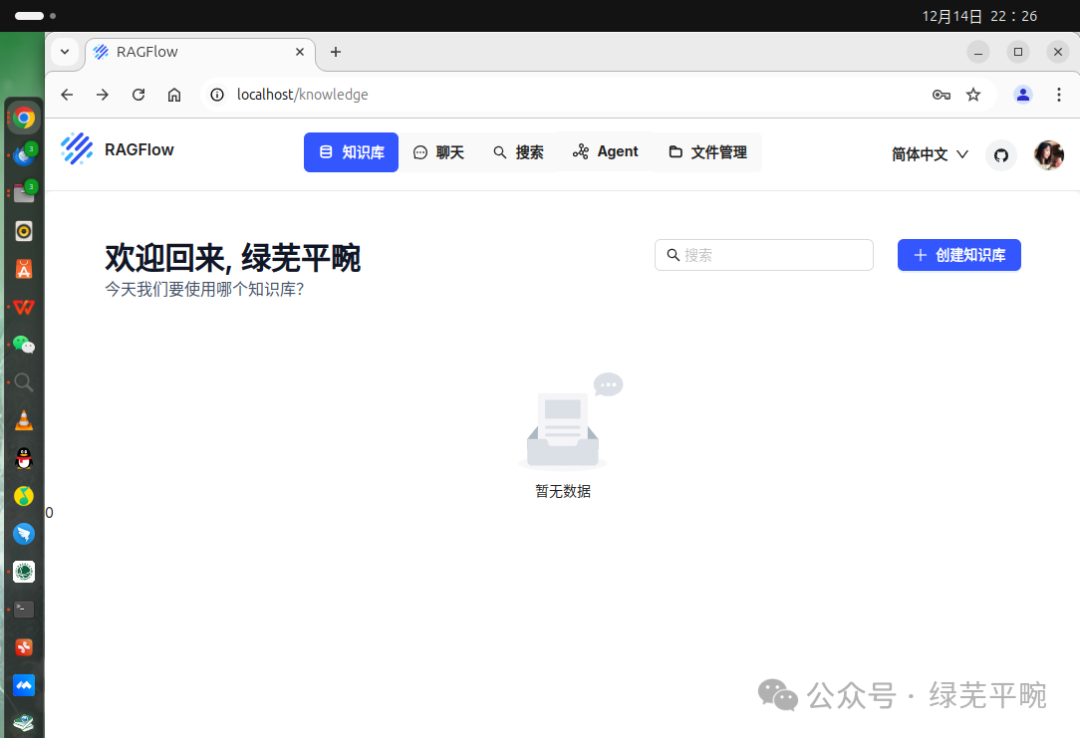
点击图像进入如下界面,配置模型提供商,这里默认为各种在线大模型供应商模型接入,但需要你去相应的模型供应商申请API key填入。
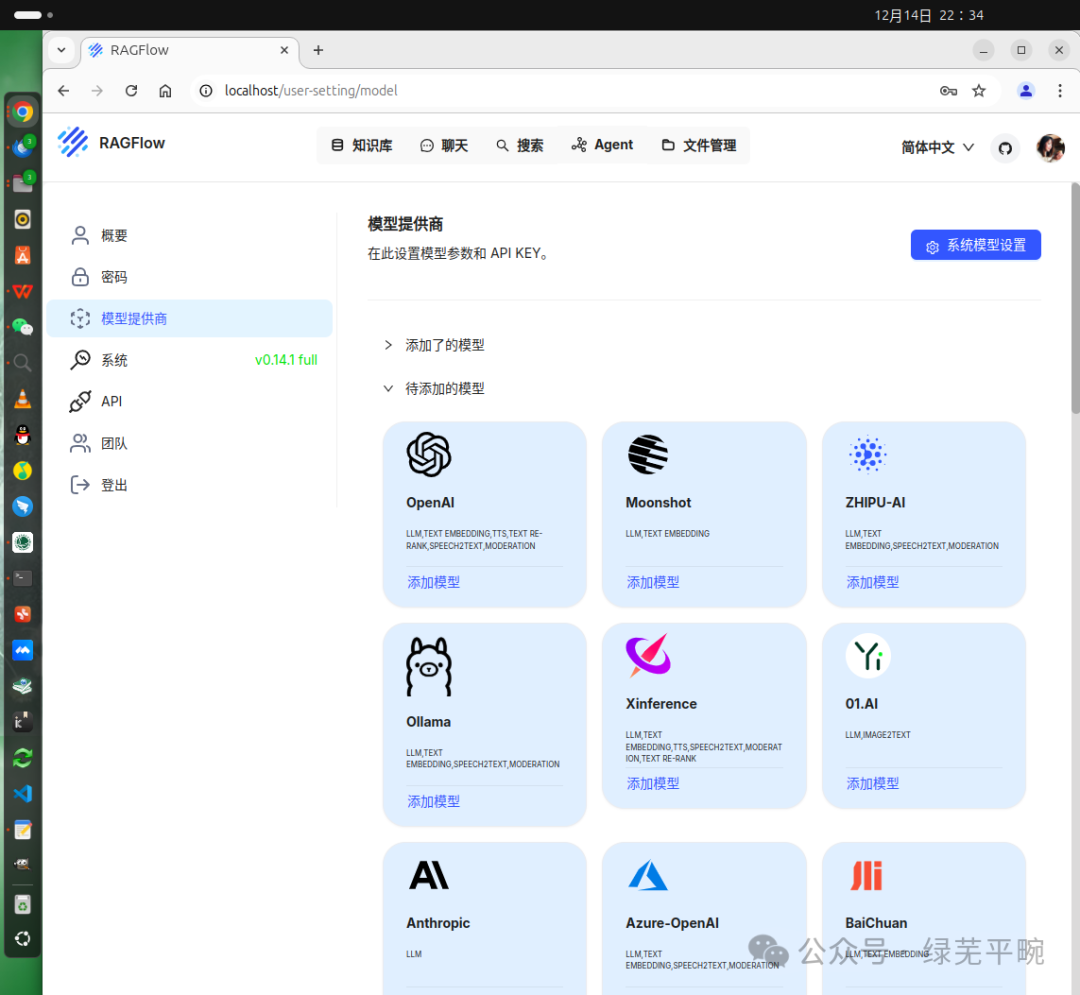
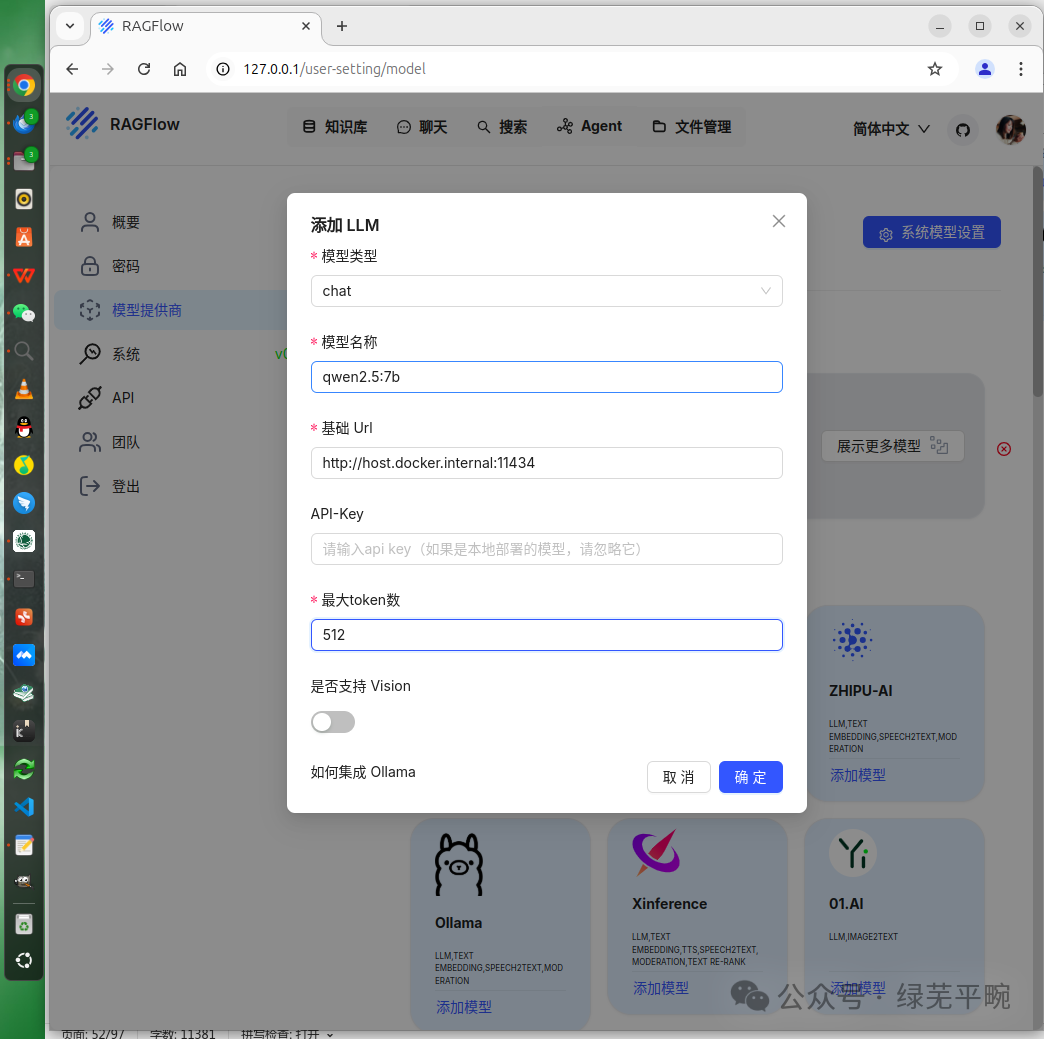
这里,我们配置接入本地部署的ollama管理的大模型
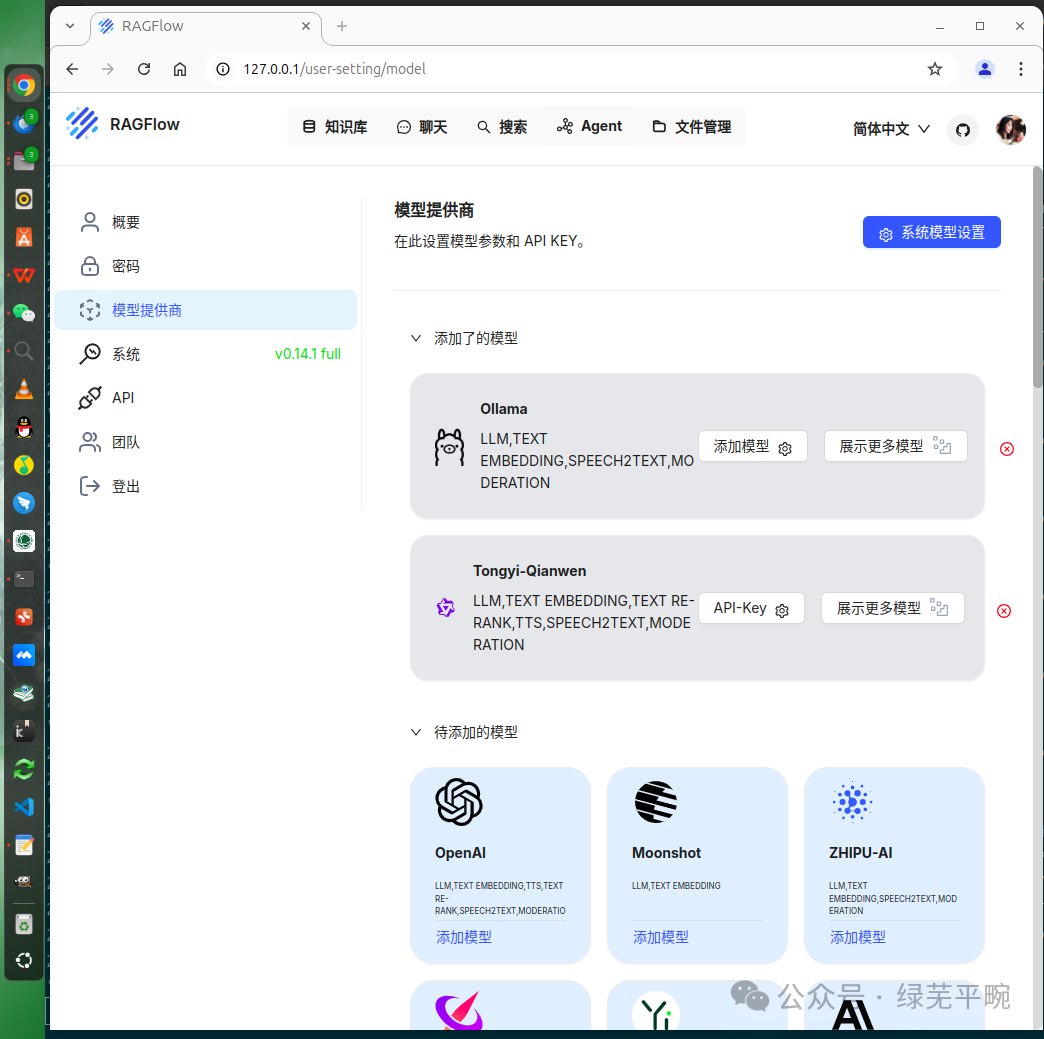
添加成功后,显示如下:
5 配置RAGFlow-创建知识库
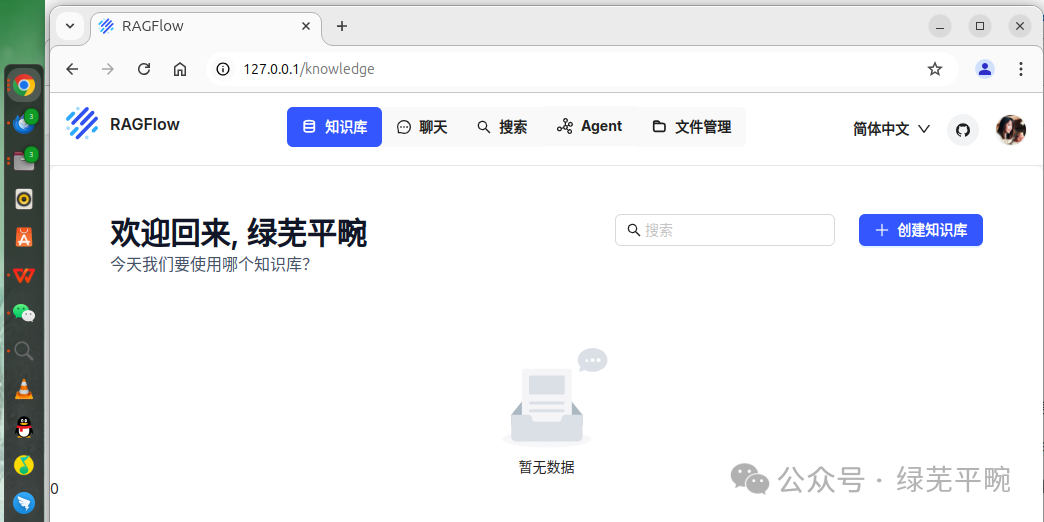
进行初始化配置后,点击保存。
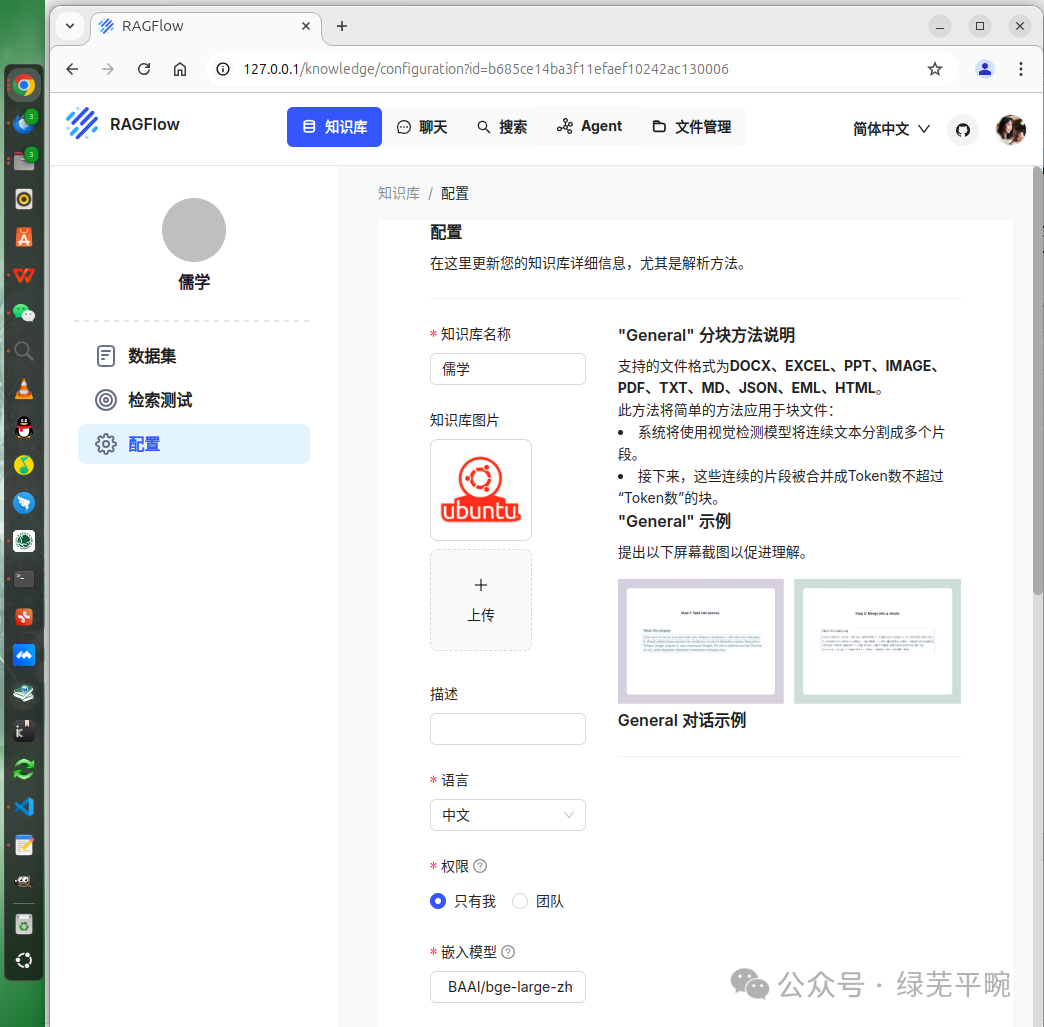
上传个人相关知识文档等,由系统进行解析处理。
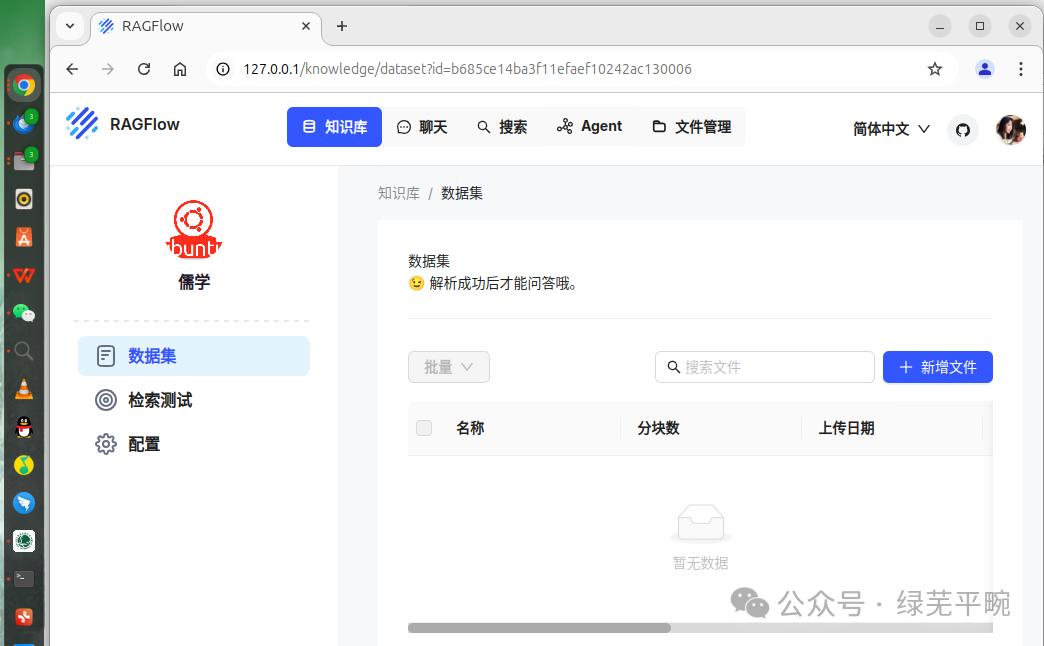
点击新增文件,上传相关文档。可以当前选择,也可以拖拽文件夹
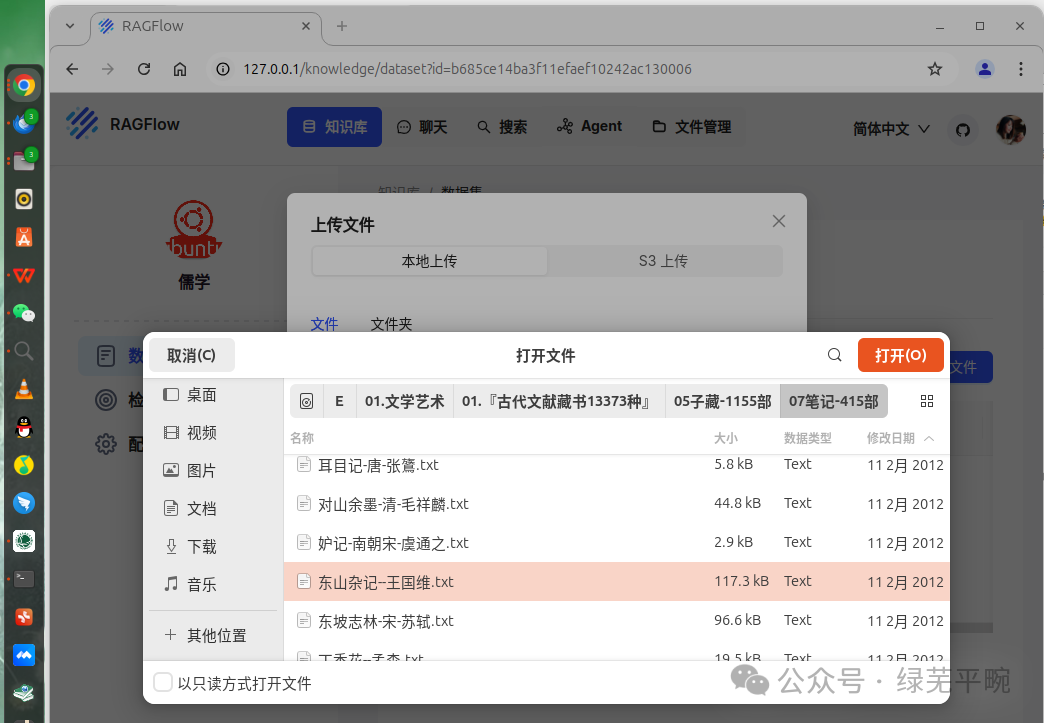
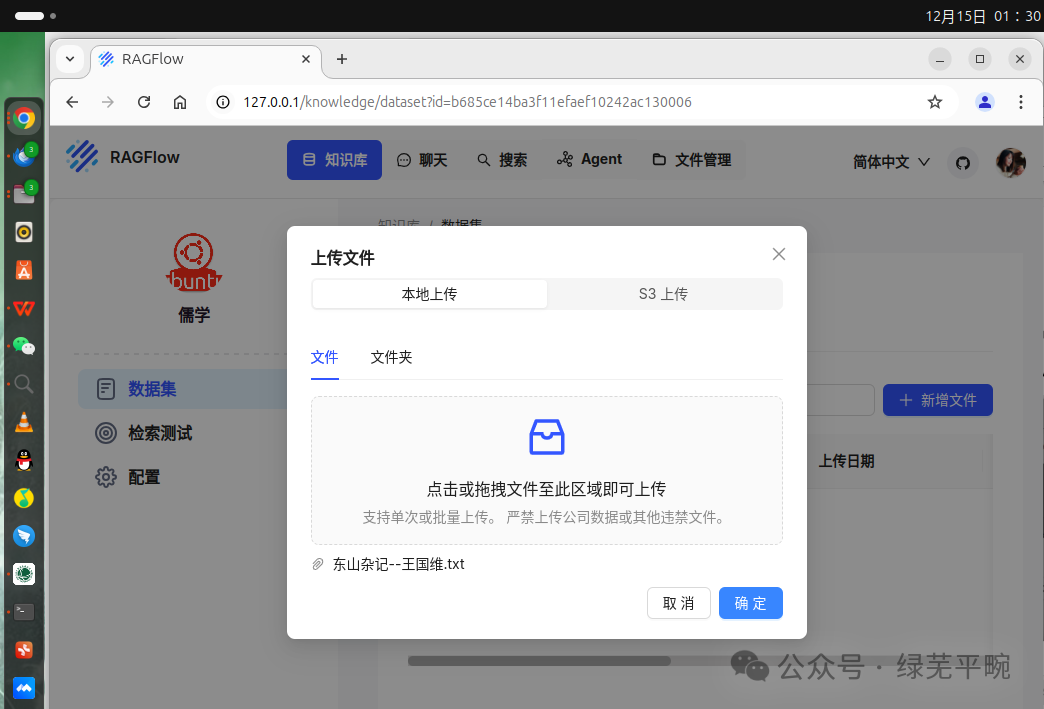
点击解析,系统将对上传文档进行文本识别(图片类文档)、分割、向量化处理。
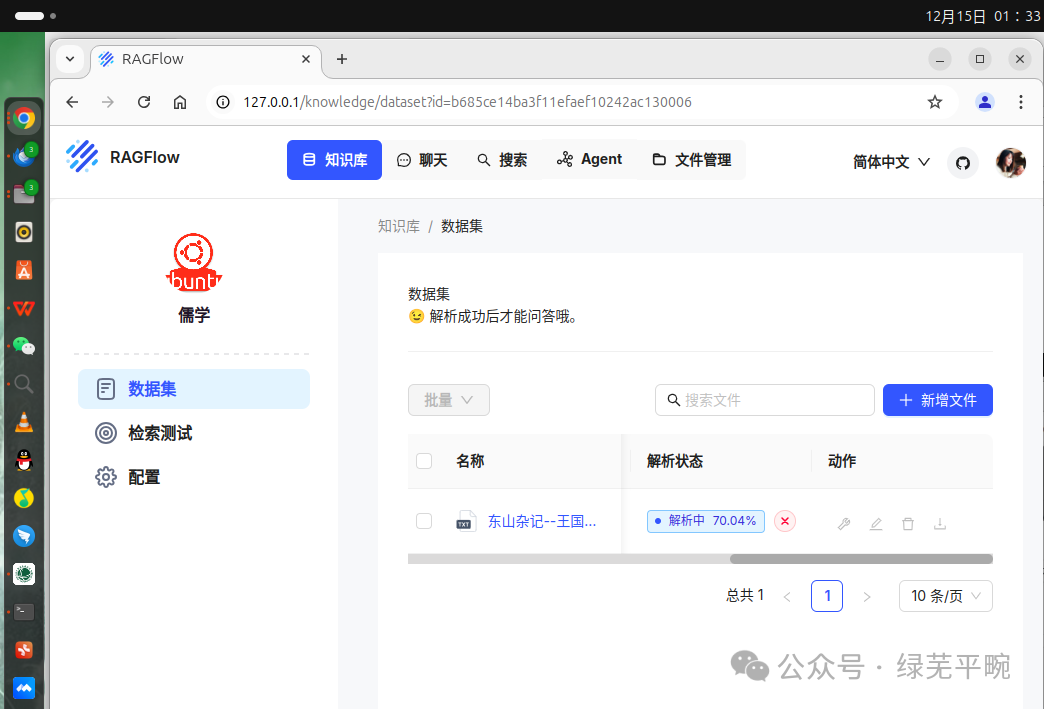
由于个人笔记本性能问题,这里只做简单测试,不做大规模文档入库。解析完成后,进行检索测试。这里从王国维的东山杂记里,尝试检索柳如是的信息。
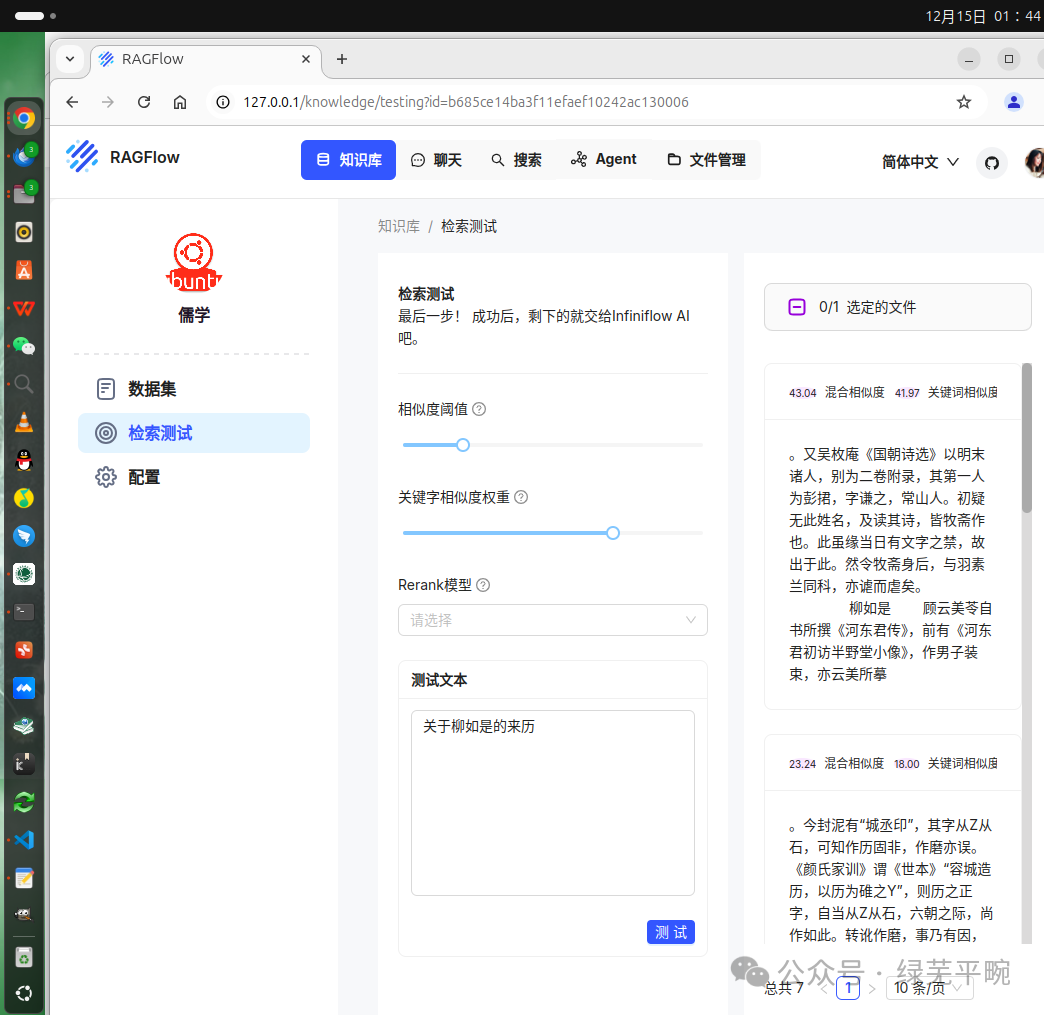
可以看到,向量化后的资料库里已经有了柳如是的信息,但切片不完整。由此可见,在进行资料入库时需要有针对性的辅助切片标注等。另外,也可能跟文言文有关系。
6 智能体应用测试
建立一个特定专业的智能体(Agent),相当于你的一个数字健身,赋于它一个角色(role),制定提示词(Prompt),设置自由度,温度等。
(1)新建助理
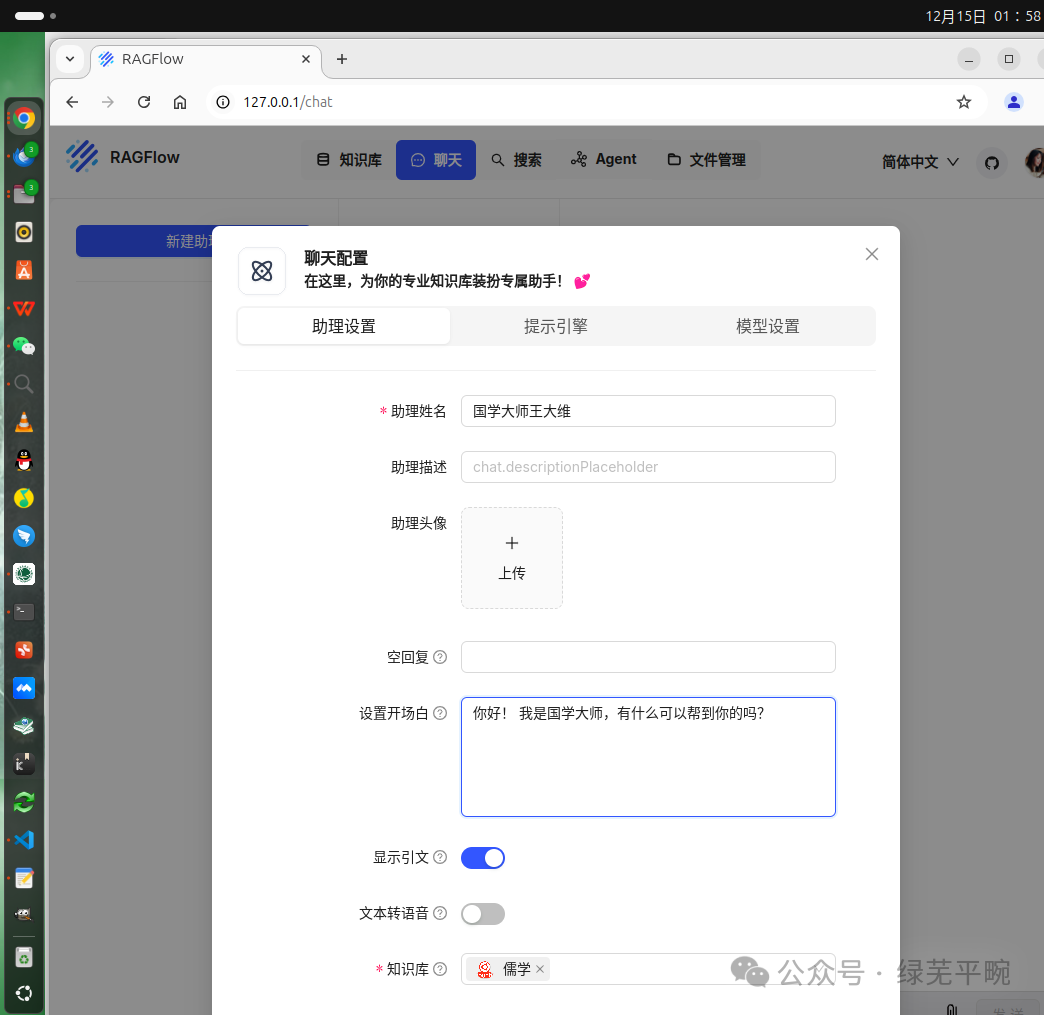
角色设定及提示词
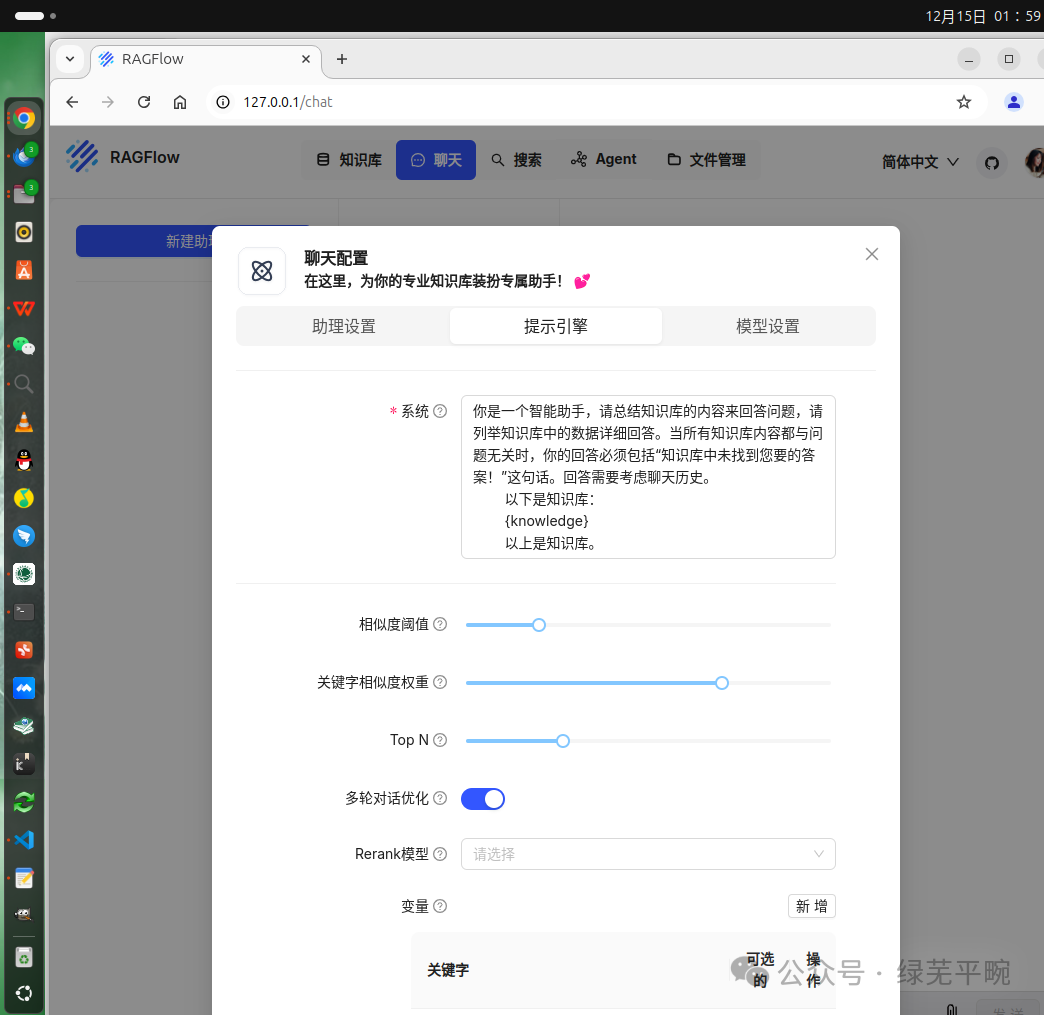
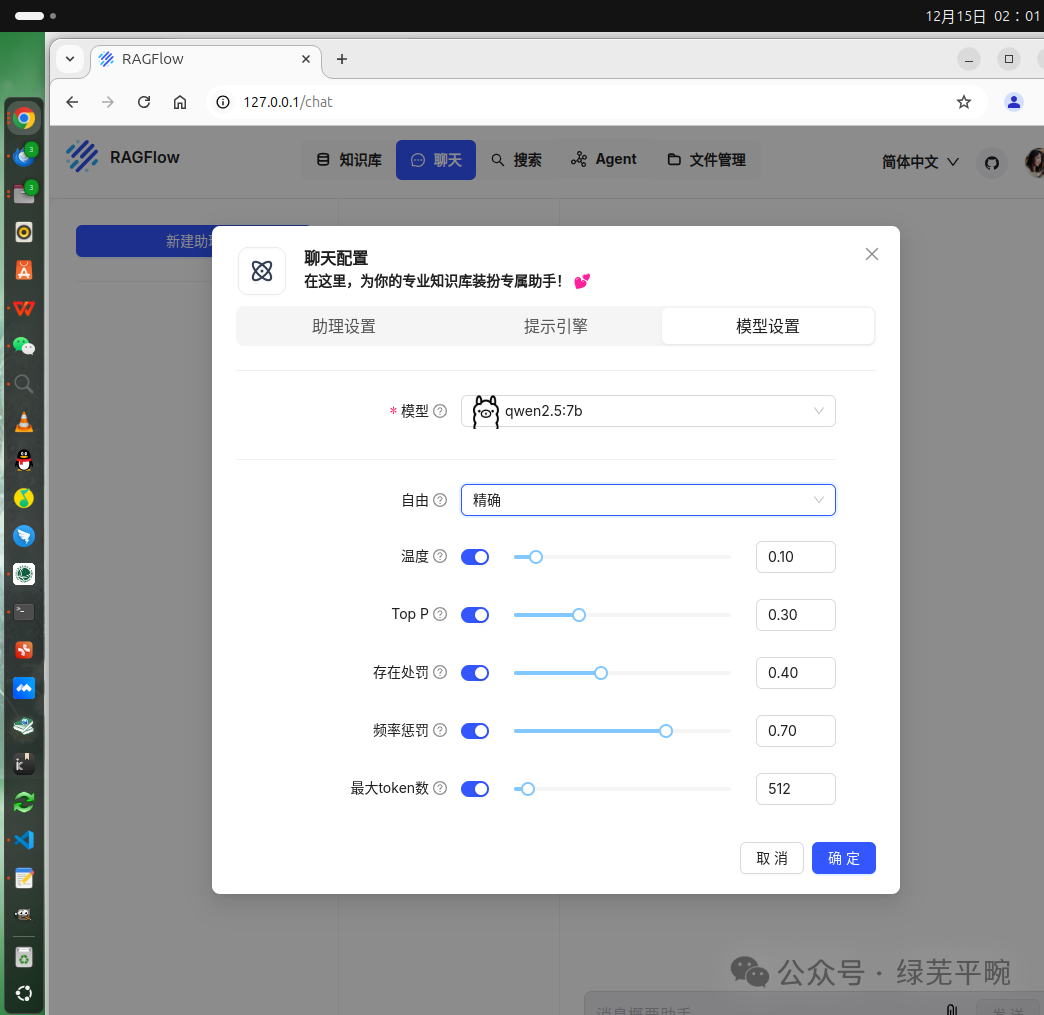
设置使用本地千问大模型并结合知识库内容进行回答,设定自由度为“精确”
下面开始问题测试:先只用本地千问大模型进行问答测试,我问他灶神是谁,千问没有正面回答我的问题。
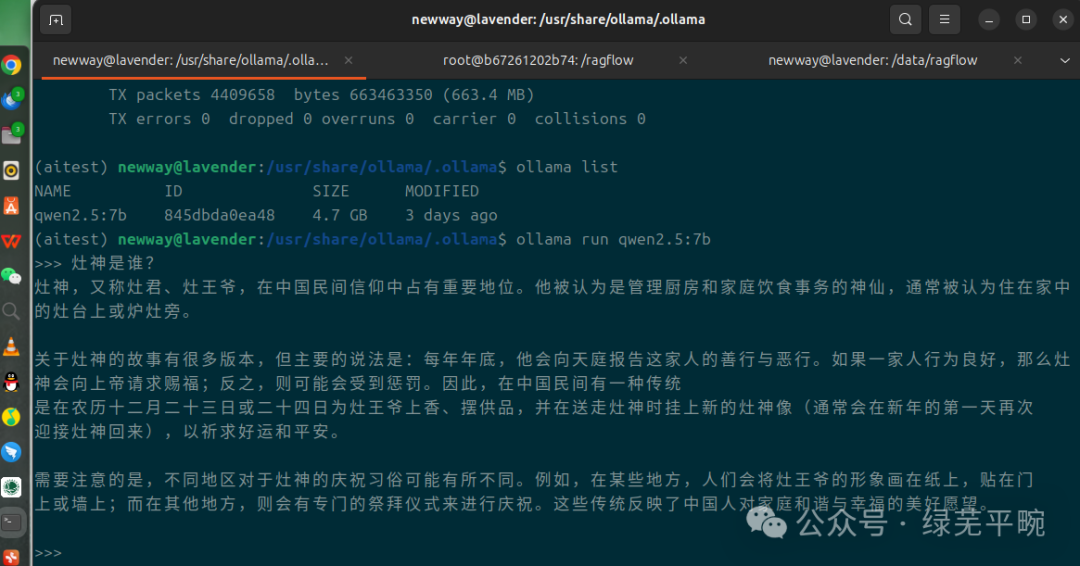
尝试追问灶神具体是谁?我让千问从王国维的《东山杂记》里找答案,AI开始胡说八道了,大模型幻觉病发作。
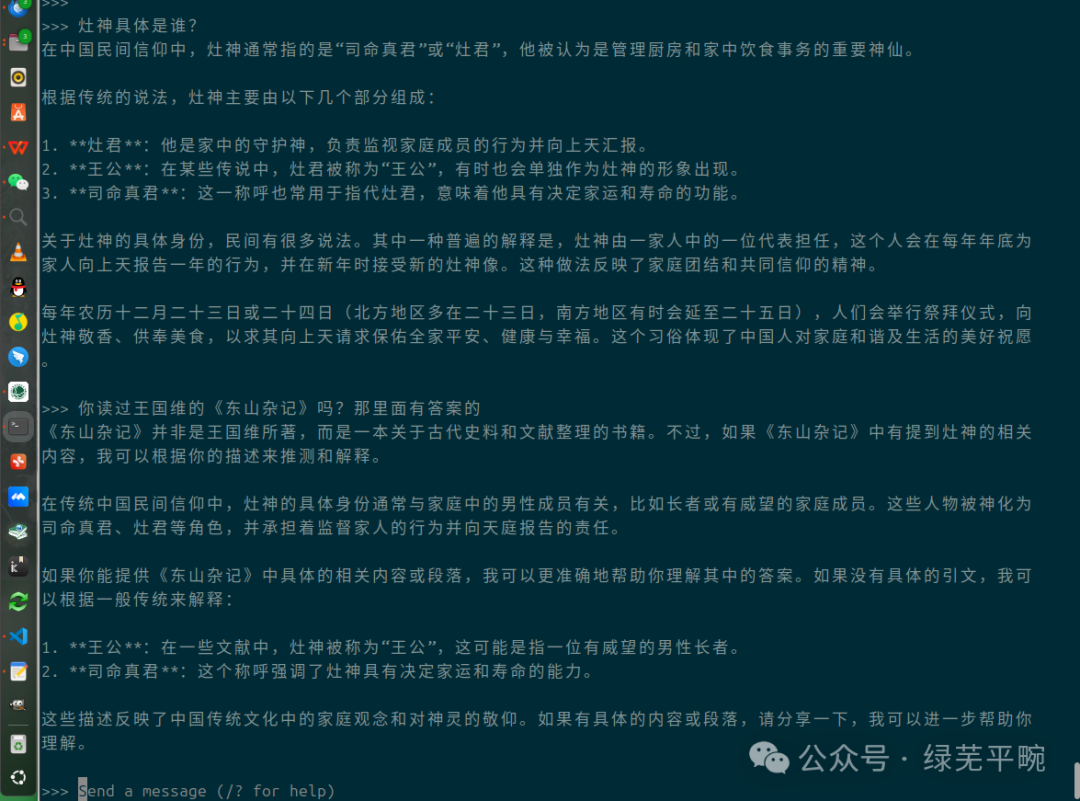
再通过本地千问大模型结合本地知识库进行问答测试,该智能助理很快从本地知识库中找到了准确的答案。
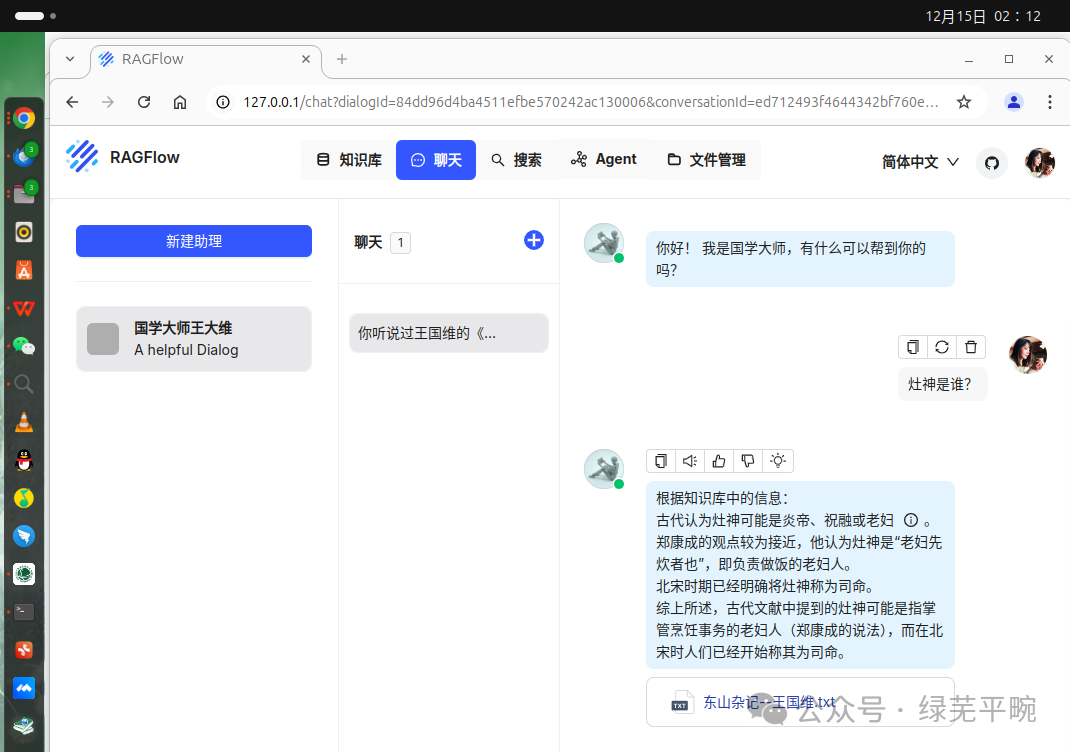
可以看到,在专业知识库下回答的问题更有特定性。但总的来看,人工智能对文言文的理解还是较白话文差一些。通过RAGFlow可以建立不同领域的个人知识库及智能体,本文演示了如何结合AI大模型和知识库进行RAG。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 8753
8753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









