






前天完成了家用电脑本地化部署DeepSeek蒸馏小模型的部署,但部署后只能在命令行使用,相当不方便,另外也不能把自己的一些私有知识挂上去额外扩展大模型能力。本文说明如何快速通过AnythingLLM完成一个具备私有知识库能力的智能问答系统的本地化搭建。
AnythingLLM 是一款开箱即用的一体化 AI 应用,支持 RAG(检索增强生成)、AI 代理等功能。它无需编写代码或处理复杂的基础设施问题,适合快速搭建私有知识库和智能问答系统。
**(1)下载安装AnythingLLM desktop**
网址:https://anythingllm.com/desktop
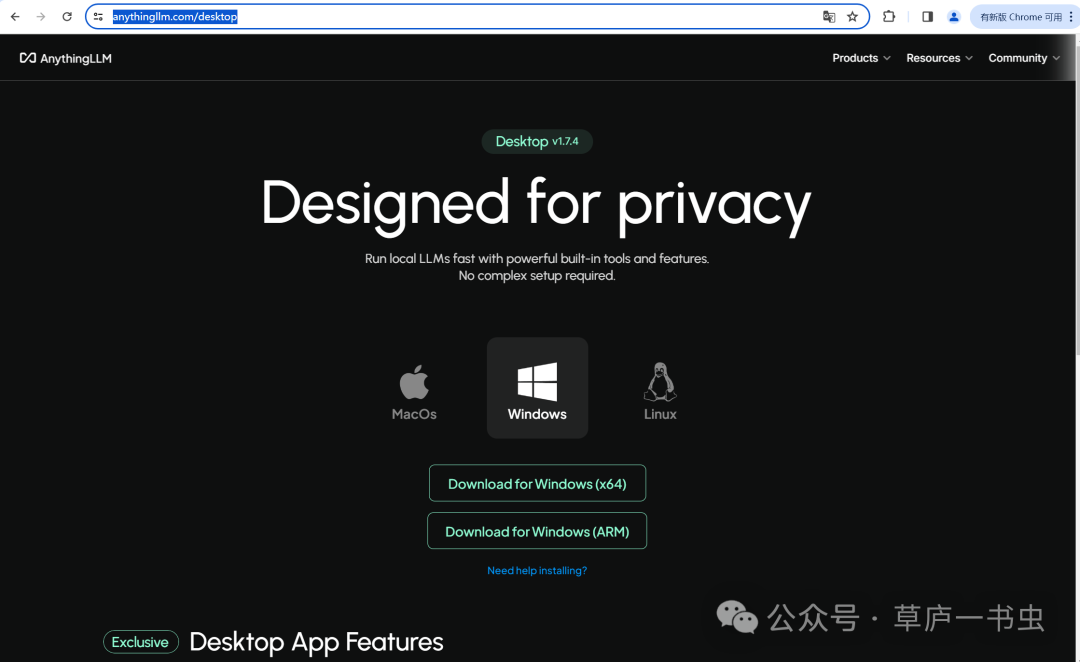
支持mac、windows、linux三种环境部署。
我是在win10环境部署,所以下载了windiow版本。下载后直接点击安装即可
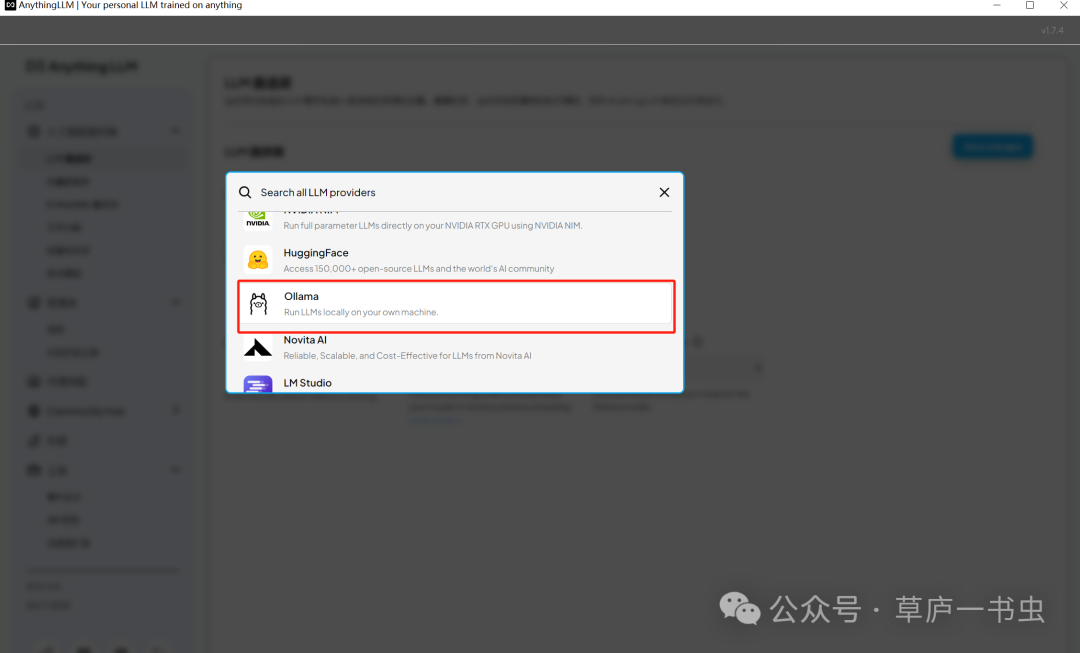
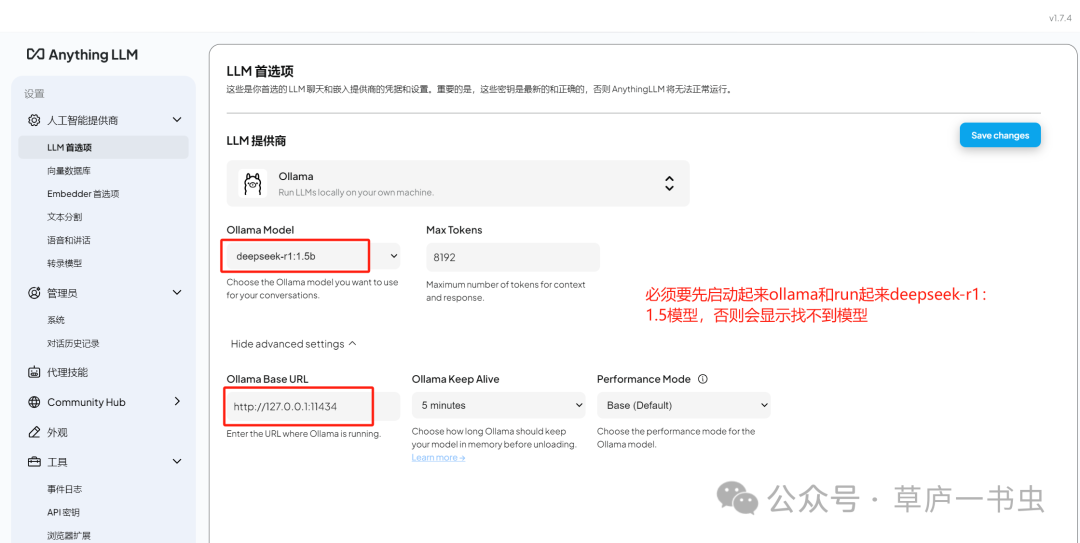
**(2)配置AnythingLLM使用本地部署的DeepSeek模型(具体如何部署参见[5分钟在家用电脑完成DeepSeek R1 (1.5B和7B模型)本地化部署](https://mp.weixin.qq.com/s?__biz=MzkyNjQ0NTE5Mw==&mid=2247483813&idx=1&sn=f0859f13a9843de8da6b6b8b3fd2f5ce&scene=21#wechat_redirect))**
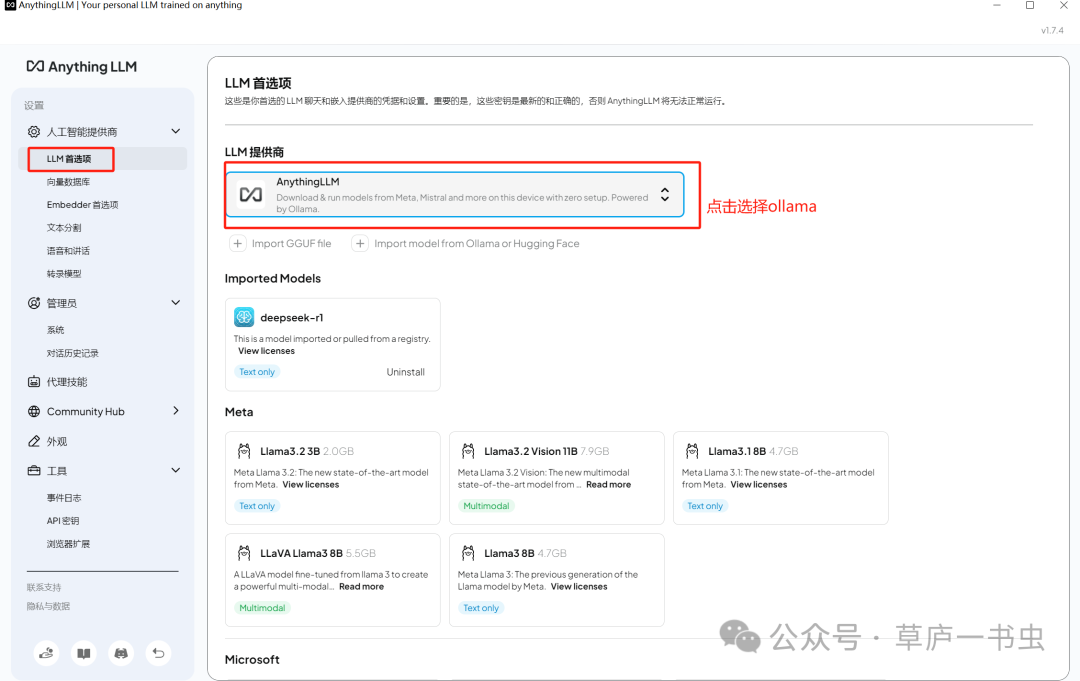
在 **AnythingLLM** 的设置页面,可以通过 **LLM 首选项** 修改 LLM 提供商。本文使用本地部署的 **Ollama** 和 deepseek-r1:1.5b模型(注意:务必要先启动ollama 和在ollama中运行起来deepseek-r1:1.5b)。配置完成后,务必点击 `Save changes` 按钮保存设置。
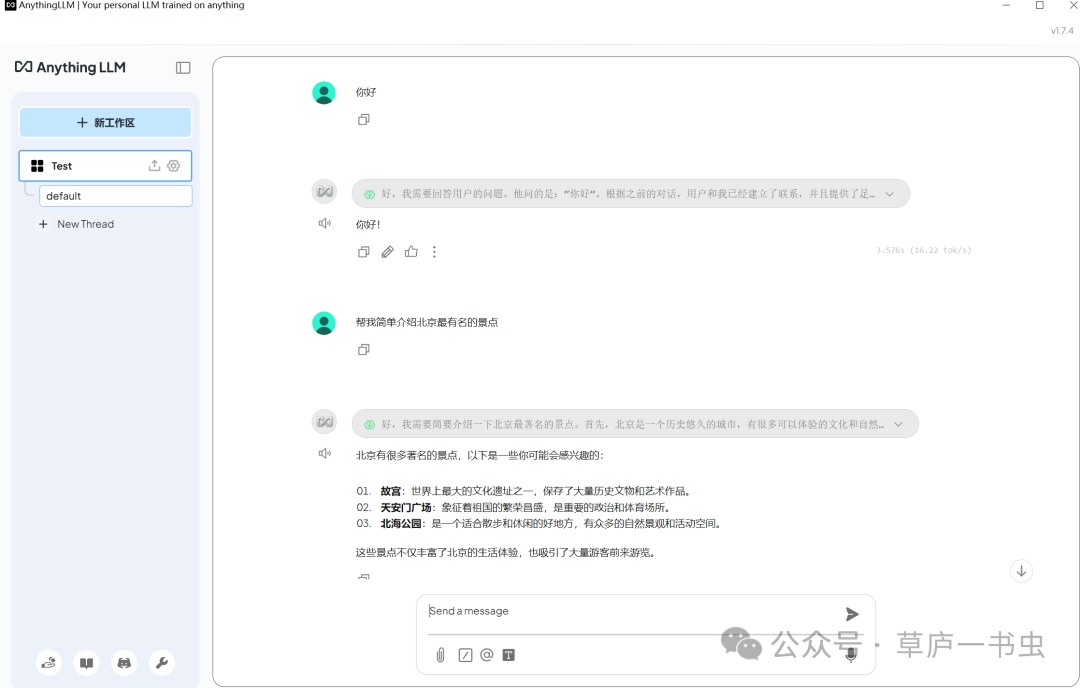
**(3)配置好本地部署的DeepSeek模型后,就可以在AnythingLLM进行问答了(性能比起直接在ollama命令行要慢一些,因为AnythingLLM自身也吃资源,另外是通过API访问模型后也要对用户输入以及模型返回结果进行处理)**
**(4)本地知识库构建(自测效果很不好,下面先就是说明下使用方法。尚需继续研究,猜测是向量化时候的嵌入引擎和和文本分割都用了默认的缘故,等待下一篇细致实验一些嵌入引擎的效果)**
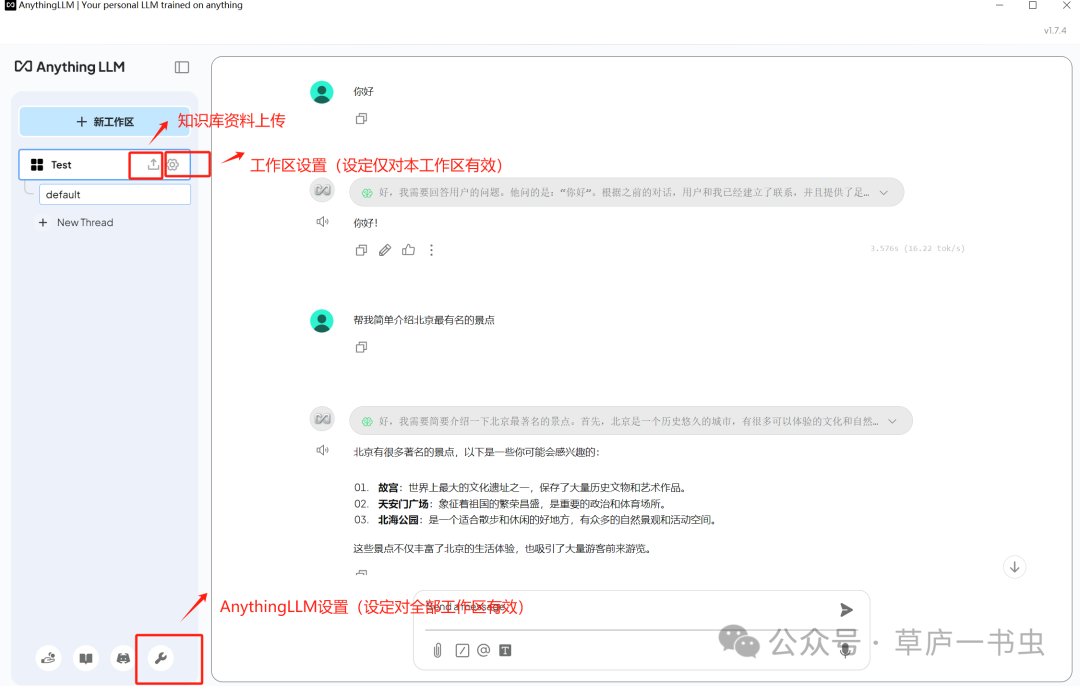
点击资料库上传按钮进入工作区知识库构建页面,AnythingLLM 支持以下三种方式上传文档:
-
本地文档上传
:直接上传本地文件。
-
Web 链接
:通过 URL 上传网页内容。
-
数据链接
:从 GitHub、GitLab 等平台导入数据。
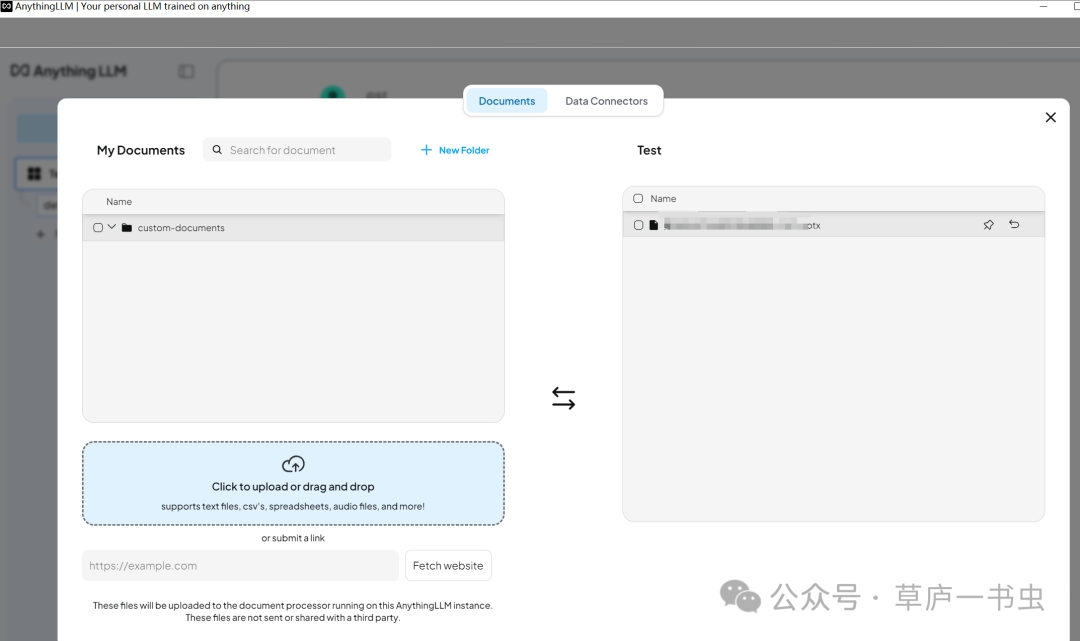
Documents Tab
在 Documents Tab,用户可以管理已上传的文档,并通过下方的上传按钮或拖拽方式上传新文档。见上图
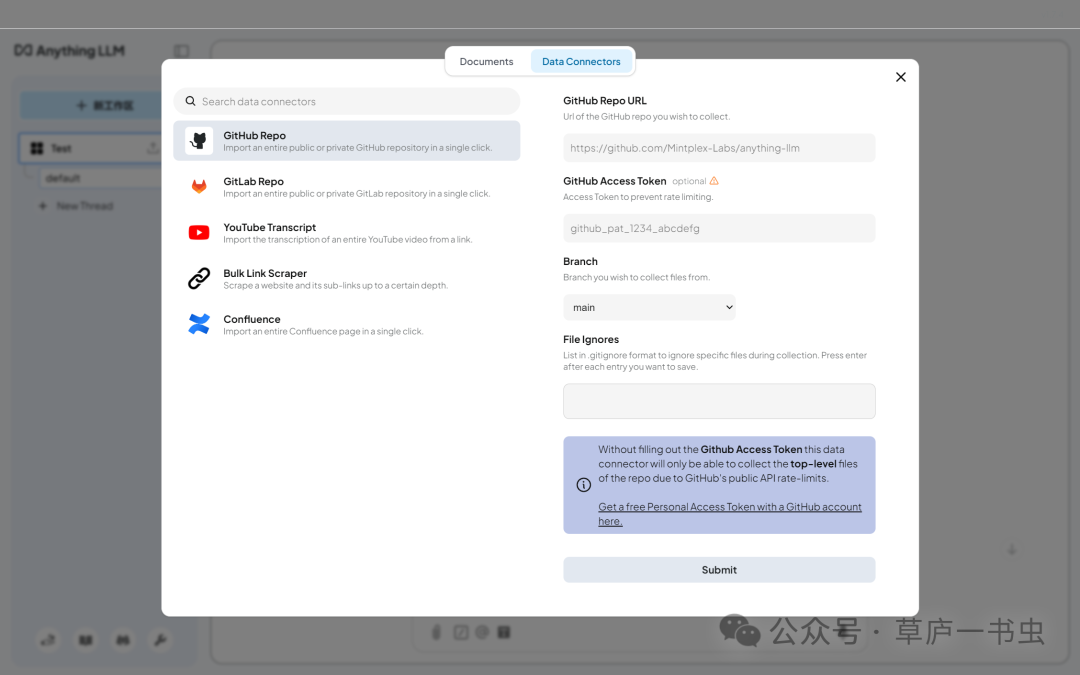
Data Connectors
Tab
Data Connectors 功能支持从 GitHub、GitLab 仓库或网站爬取数据。用户只需输入仓库地址和 Token,即可导入指定目录或网页内容。
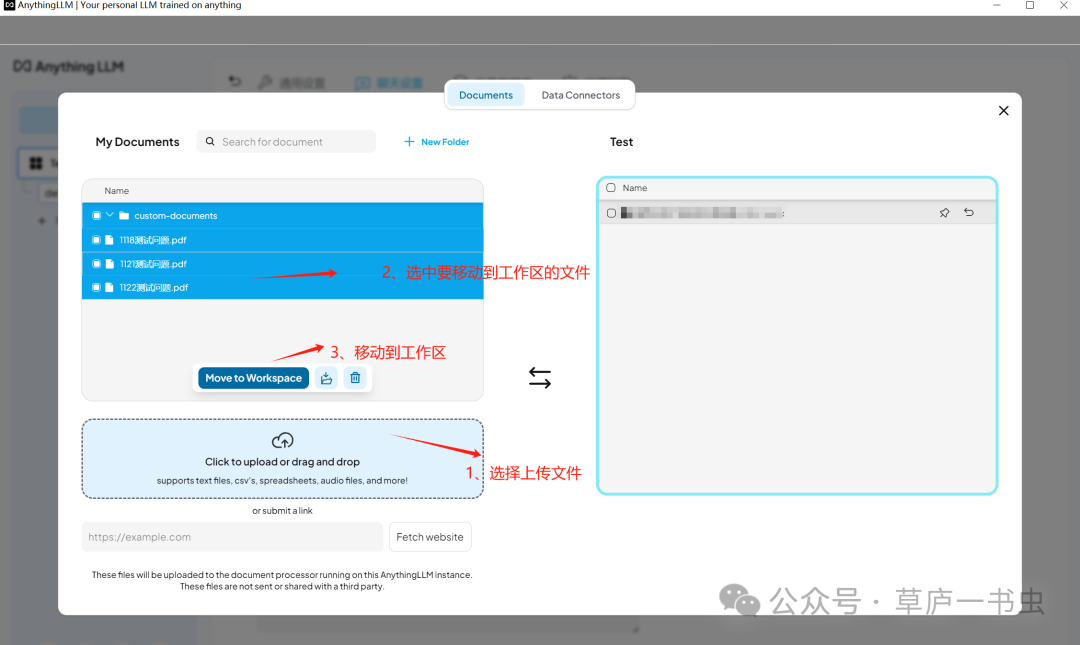
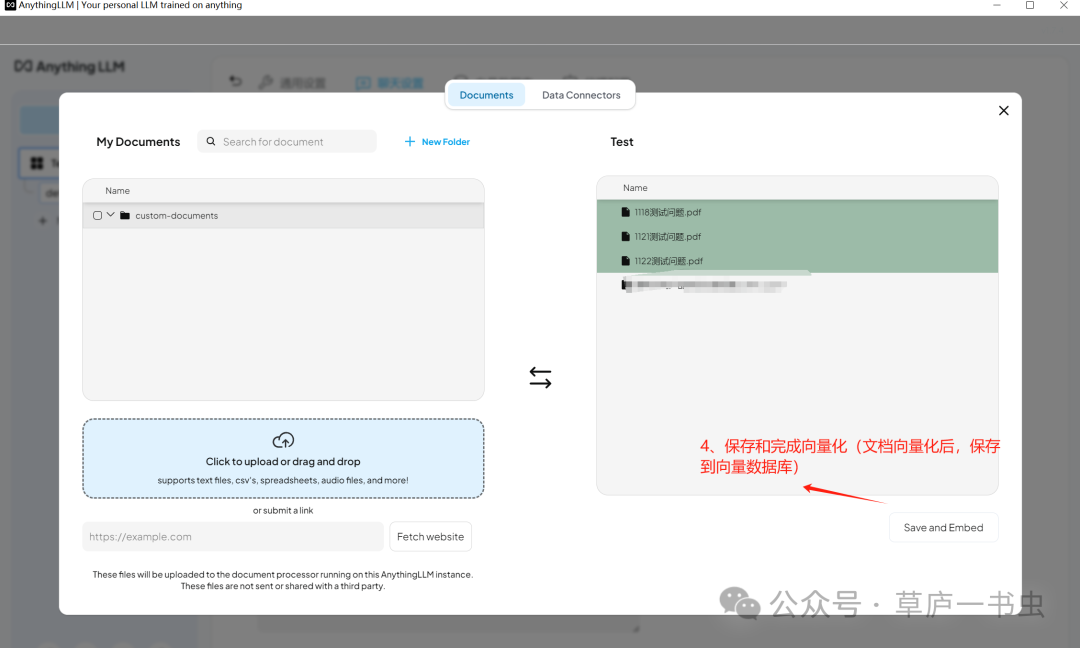
**(5)上传示例**
**(6)查询知识库**
将文档添加到工作区后,用户可以通过设置聊天模式调整大模型的回复方式:
-
聊天模式
:结合 LLM 的通用知识和上传文档的上下文生成答案。
-
查询模式
:仅基于上传文档的上下文生成答案。
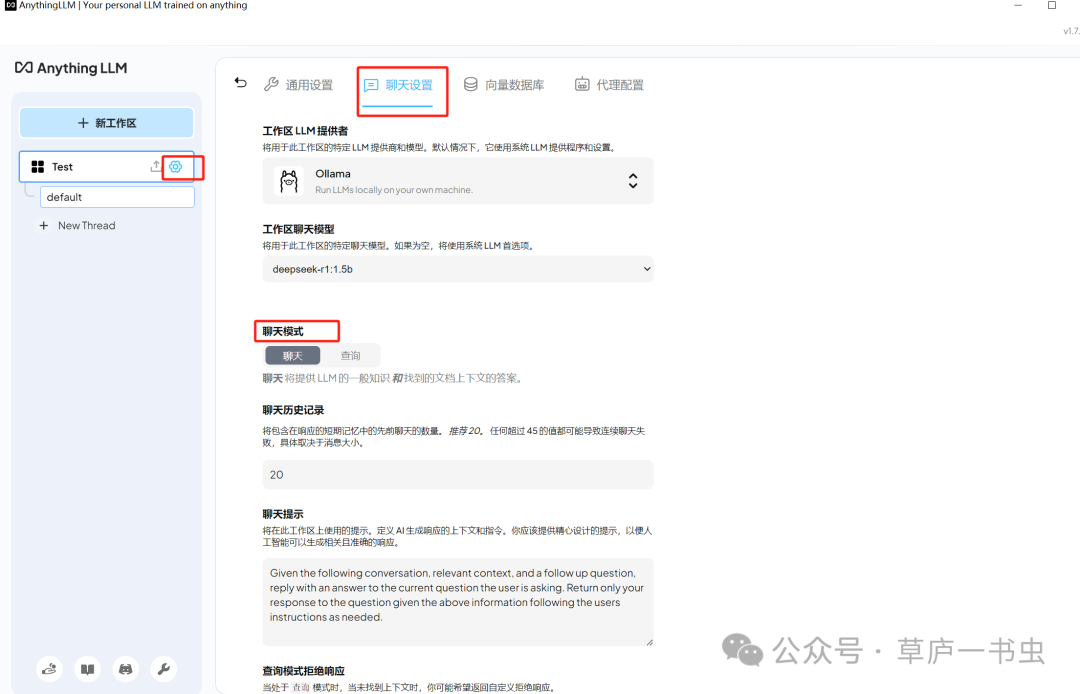
修改配置后记得拉到最后点击更新按钮
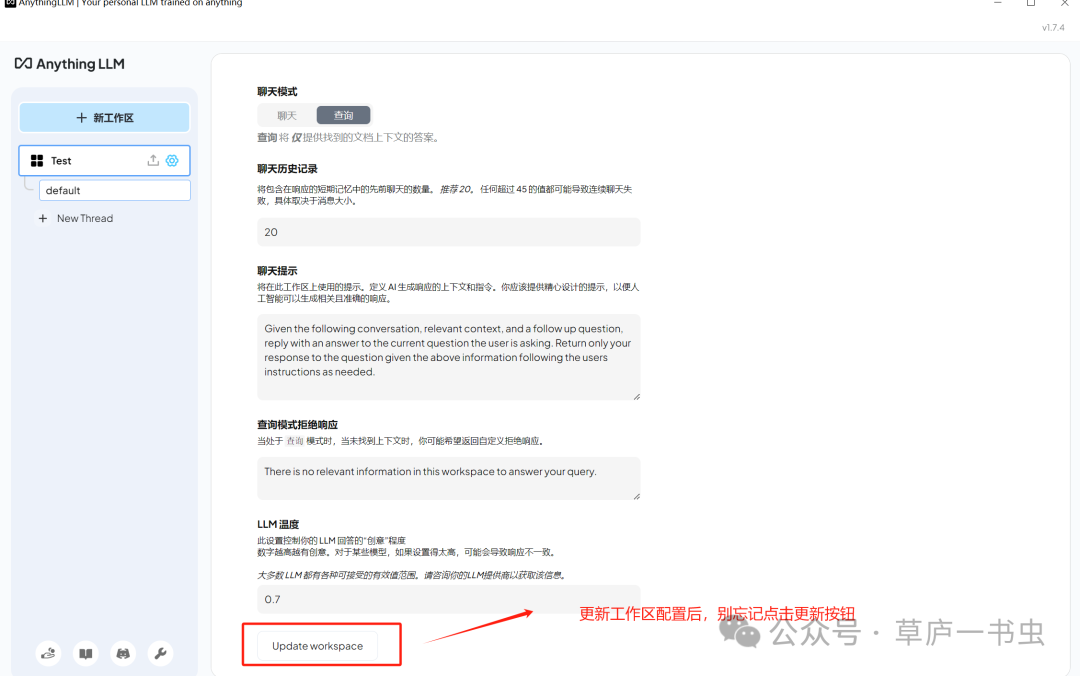
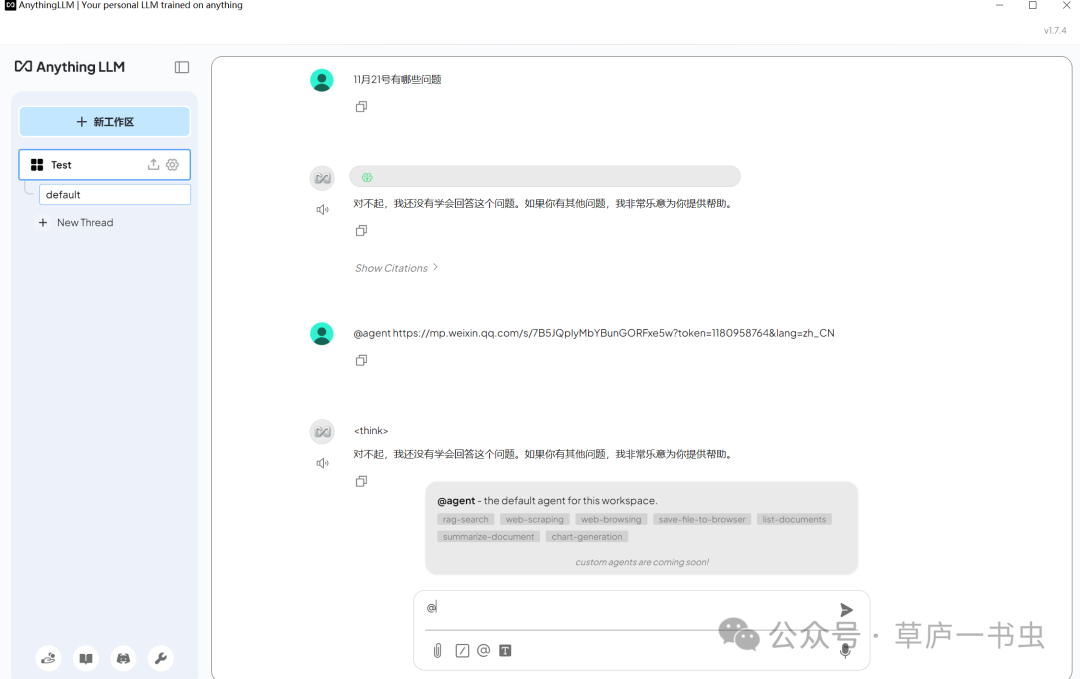
**(7)Agent功能(尚在研究中)**
在设置页面的 代理技能 中,用户可以管理 Agent。默认开启的 Agent 无法关闭,其他 Agent 需要手动启用。
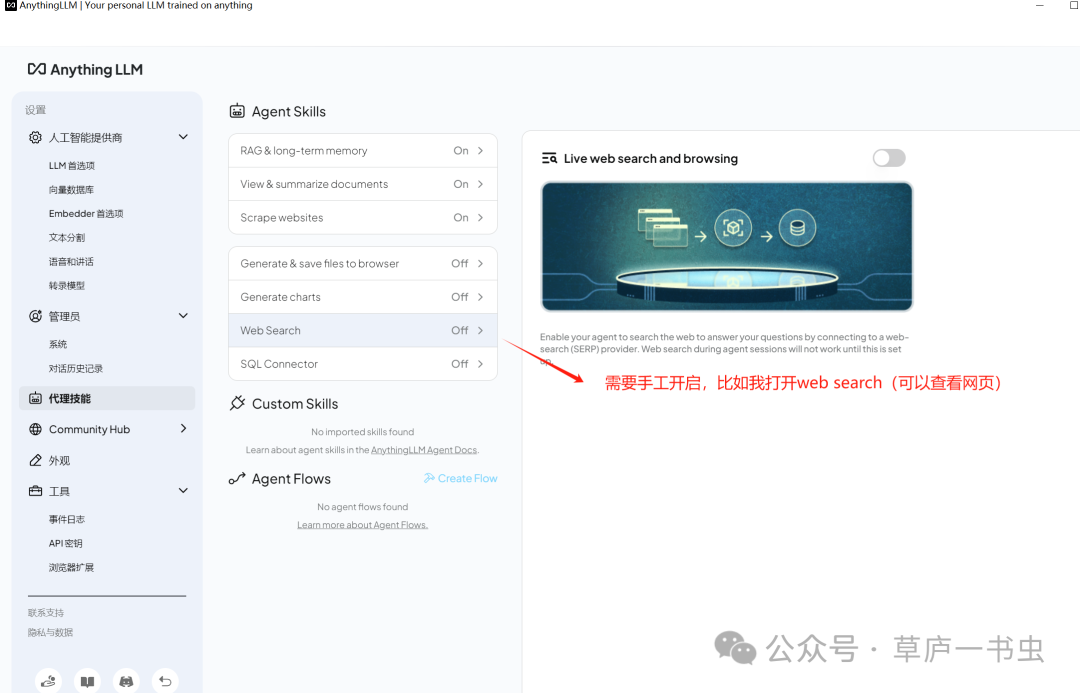
agent功能查询
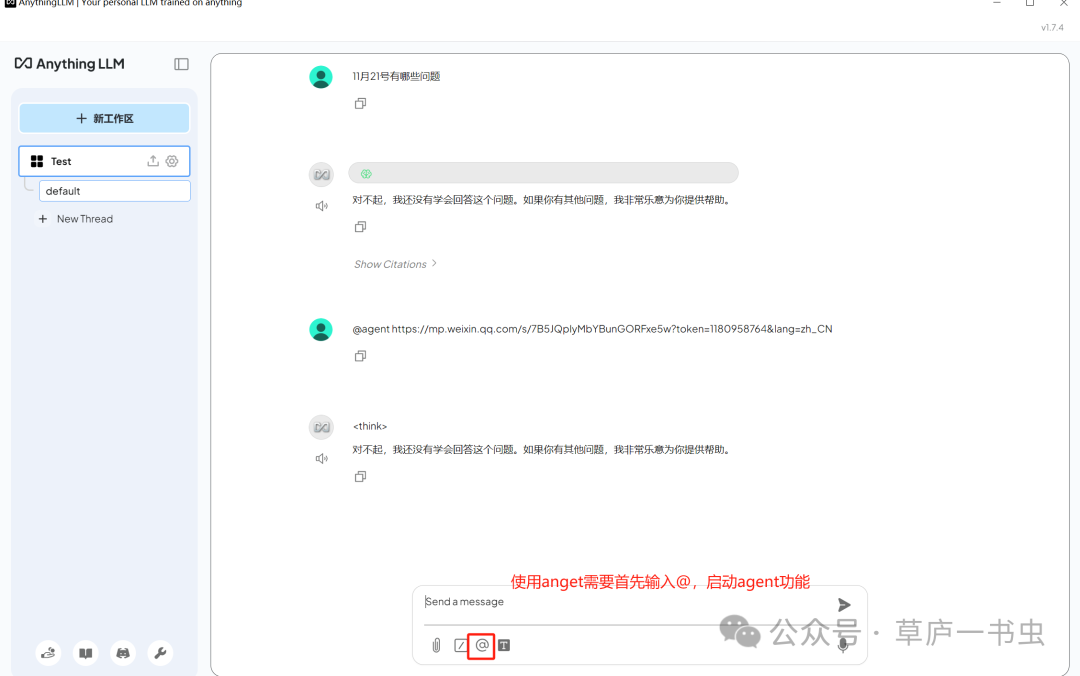
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









