






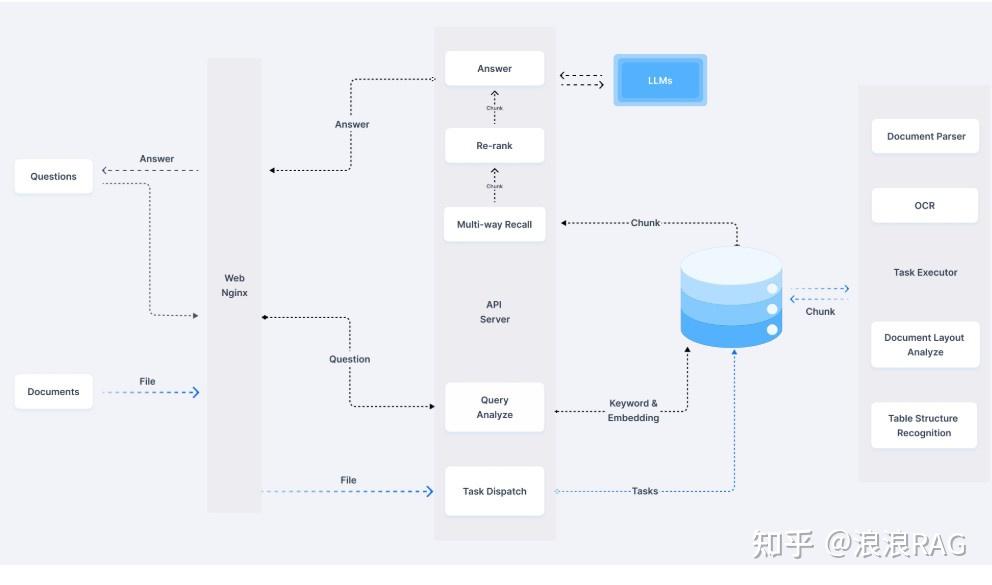
1、文档解析
1.1 、可以使用mineru 使用版面分析,解析复杂文档。
1.2、 可以使用多模态大模型,比如qwen-vlm,可以本地化部署和直接使用线上模型。
2、文档切分
按照原始的语义段落对文档进行切分,形成chunk,注意chunk可以大点,对短的段落可以进行合并形成新的chunk,生产实践,chunk可以在4000字以内,从而保障完整的语义。
3、向量化
使用embedding模型对文档进行向量化,可以使用线上模型和使用xinference部署线下模型,下面是可以选择的模型
3.1、Jina AI发布的jina-embeddings-v2模型支持高达8K tokens的输入长度,这对于处理较长文本非常有用3。这个模型可以在Hugging Face上找到(不会魔法的去魔搭社区),并且是一个开源的选择。
3.2、BAAI提供了多种版本的Embedding模型,包括同时支持中文和英文的版本、仅支持中文的版本以及仅支持英文的版本。例如,“BAAI/bge-small-zh-v1.5”大小仅为95M,非常适合资源有限的环境2。此外,BAAI的模型还因为其开源免费的特点而受到欢迎。
4、问题重写
目的是为了让问题尽可能的匹配知识库查询到更多的知识
4.1、多重查询:
这是指为了确保一个问题的回答尽可能全面和准确,使用大模型将一个问题分解成多个相关的小问题,并对每个小问题分别进行检索。这种方法试图从多个角度补充原来的问题,以细化查询,使其与主题更加相关,从而从数据库中检索更多相关的文档13。
4.2、RAG融合(RAG-Fusion):
在多重查询的基础上,该方法进一步对检索到的结果进行评分,优先展示出现频率最高的资料给大模型处理。利用倒数排序融合(RRF)和自定义向量评分加权,可以生成全面准确的结果13。
4.3、查询分解:
这是一种通过将复杂问题分解为若干子问题来改善问答效果的策略。有两种实现路径:一是序列求解,即将上一个子问题的答案与当前问题一并交给LLM生成答案,再把当前生成的答案与下一个子问题一起给LLM生成最终答案;二是并行独立回答问题,然后合并多路答案为最终答案13。
4.4、Step Back:
这种策略旨在让问题变得更抽象,以便提供更大范围的检索。虽然看起来似乎会使问题变得更加模糊,但实际上,抽象化的过程是对问题进行了总结,有助于扩大搜索范围,增加检索的相关性13。
HyDE(Hypothetical Document Embeddings):这种方法首先用大模型对问题生成一个假设答案,基于假设答案与索引文档之间的相似度来进行检索。HyDE适用于原始问题较短的情况,因为生成的假设文档可能会更好地与索引文档对齐13。
5、向量和bm25融合检索
在Elasticsearch中,向量检索(基于嵌入的相似度搜索)和BM25检索(基于词频-逆文档频率的文本相似度评分算法)的融合检索是一种常见的做法,特别是在构建高效的检索增强生成(RAG)系统时。这种混合方法旨在结合语义理解和关键词匹配的优势,从而提供更精确的检索结果。
以下是几种实现向量检索与BM25检索融合的方法:
5.1. 使用 script_score 查询
一种直接的方式是通过使用 script_score 查询来结合两种得分。在这种情况下,你可以先用BM25进行初步过滤,然后对这些结果应用向量相似度得分作为二次排序依据。这种方法可以灵活地调整两者之间的权重。
POST test-index/_search
{
"query": {
"script_score": {
"query": {
"match": { "title": "mountain lake" }
},
"script": {
"source": "cosineSimilarity(params.query_vector, 'title-vector') + 1.0",
"params": {
"query_vector": [54, 10, -2]
}
}
}
}
}
5.2使用 bool 查询结合 function_score
另一种策略是利用 bool 查询结合 function_score 来组合不同的得分。你可以将BM25得分作为一个基础得分,并添加一个函数分数来反映向量相似度的影响。
POST test-index/_search
{
"query": {
"bool": {
"must": [
{ "match": { "title": "mountain lake" } }
],
"should": [
{
"function_score": {
"boost_mode": "replace",
"functions": [
{
"script_score": {
"script": {
"source": "cosineSimilarity(params.query_vector, 'title-vector') + 1.0",
"params": {
"query_vector": [54, 10, -2]
}
}
}
}
]
}
}
]
}
}
}
6、重排模型
在RAG系统中扮演着至关重要的角色。它的主要功能是对从大规模语料库中检索出的文档或段落进行重新排序,以便提高最终生成内容的相关性和准确性。
推荐的模型 big-reranker-base和big-reranker-large
7、召回
把向量匹配的文档chunk合并,作为提示词输入给大模型。
8、开源项目参考
RAGFlow
简介:RAGFlow 是一款基于深度文档理解构建的开源RAG引擎,适用于各种规模的企业和个人用户。
特性:OCR、内置多种文档切分模板、文档切分可视化并且可修改、兼容多种文档数据类型1。
2. QAnything
简介:由网易出品的支持任何格式文件或数据库的本地知识库问答系统,支持离线安装使用。
特性:跨语种问答、粗排和精排的二阶段召回1。
简介:一个可以实现完全本地化推理的知识库增强方案,重点解决数据安全保护和私域化部署的企业痛点。
特性:支持市面上主流的本地大语言模型和Embedding模型,支持开源的本地向量数据库1。
4. FastGPT
简介:提供开箱即用的数据处理、模型调用等能力,并可以通过Flow进行工作流编排。
特性:支持应用编排、免登录分享、支持接入飞书、企业微信等应用1。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 1267
1267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









